NHANES 数据库简介
NHANES(National Health and Nutrition Examination Survey,美国国家健康与营养调查)是由美国疾病控制与预防中心(CDC)下属的国家健康统计中心(NCHS)持续开展的一项具有全国代表性的人群调查。该数据库采用分层、多阶段、复杂抽样设计,通过入户访谈、体格检查及实验室检测,系统收集美国居民在健康状况、营养摄入、生活方式及慢性疾病等方面的综合信息。连续 NHANES 数据自1999年起,每两年开展一次,目前已到2025年。
Nhanes 数据库整理时面临的难点
- 变量命名不一致:同一变量在不同调查周期中可能更名,或不同变量在不同周期中使用了相同名称,若未加以识别和统一,容易造成数据遗漏或变量混淆。
- 计量单位变更:部分连续变量在不同时期采用了不同的计量单位,且差异可能达到数量级水平,忽略单位转换会导致对时间趋势或效应大小的严重误判。
- 分类标签调整:分类变量中同一类别的编码或标签在不同周期发生变化,若未重新映射,可能引入系统性的分类错误。
- 跨周期整合复杂:上述不一致性使得跨周期、长期趋势分析和暴露组学研究面临较高的数据清理与标准化成本。
目前网络公开整理的 NHANES 数据集或工具缺陷
- nhanesA 包的 nhanesTables 函数查看 2021 年的 table 时报错
- nhanesA 包的 nhanes 函数下载数据集时,translated 参数默认为 TRUE,由于代码对变量类型判断不是那么完善,会导致错误
- 公开并以论文形式发表的 harmonized NHANES 数据存在问题且提取数据时可操作性不强,数据只到 nhanes 2019。最重要的就是吸烟相关变量只有 1988-1994年的数据,连续 NHANES 数据完全没有
- 相关公开数据库网站下载的数据多为 csv 数据,不能包含变量的 label;如果是分类变量, 每个数字代表什么意思也需要再返回网站查,十分的麻烦(如数据库 https://db.iaccepted.online/dashboard)

图1. harmonized NHANES 的文章
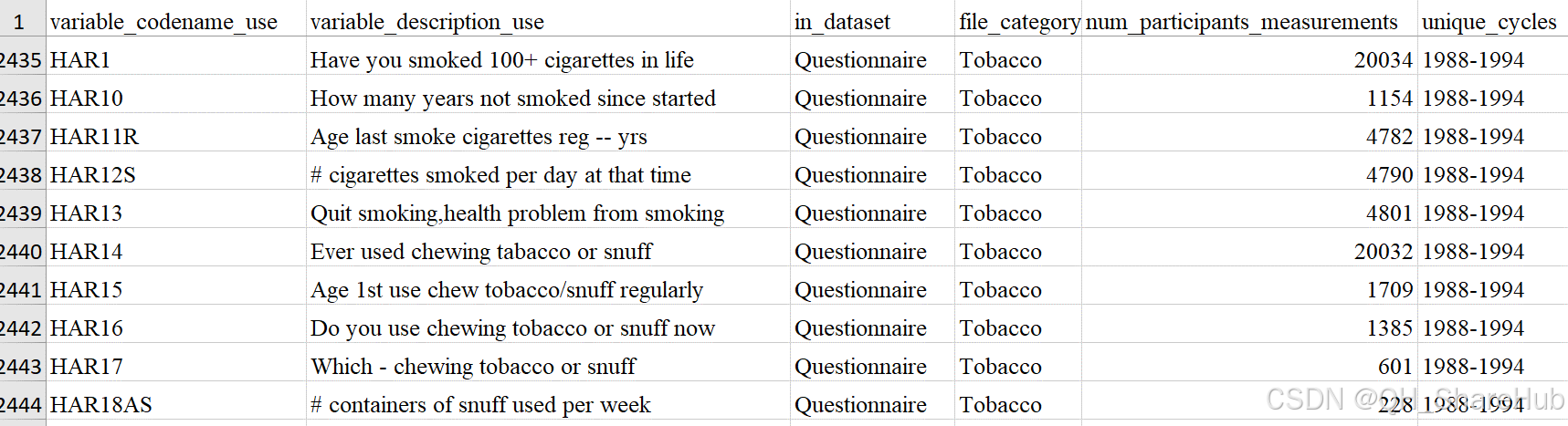
图2. harmonized NHANES 包含的变量信息 dataframe
根据目前数据库和相关工具的缺陷,我们推出nhanes数据库及相关工具,帮助用户方便快捷地得到真实可靠且易于使用的数据。
该数据库包含内容
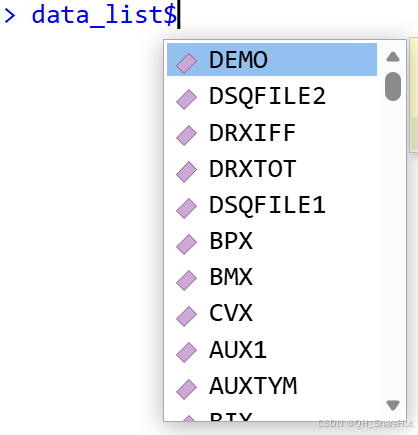
**1. data_list:**包含 1999-2023 年所有的数据集(原始数据集,与从官网下载的 xpt 文件一模一样,完全可靠,用户可验证)。此外,为方便结合不同次调查的数据,为每个数据框增加 cycle 变量(每次调查的开始年份)以及id变量(cycle与SEQN变量的连接,如 2001_9628)
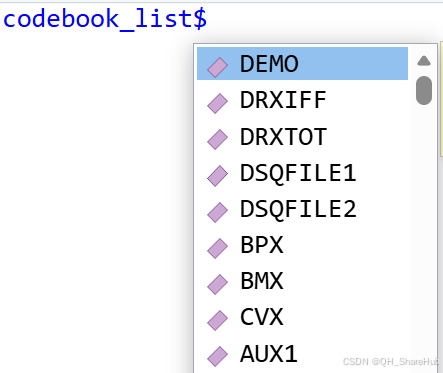
2. **codebook_list:**每个数据集的 codebook包含每个变量的信息(与官网的 codebook 一模一样,不用总在个个网页间来回切换等待网络加载)
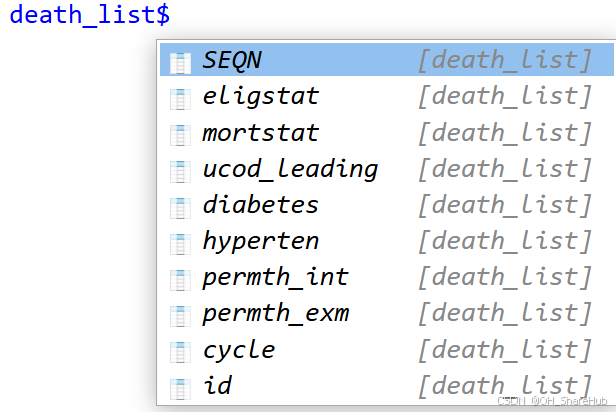
3. **death_list:**死亡相关变量的数据集(nhanes链接NDI 的死亡相关数据)。同样增加 cycle 与 id变量
4. **nhanes_data_showcase_zh.xlsx:**包含每个变量的所有信息,用户可直接在其中查找所需的变量。提供相关中文,方便查找

该数据库使用方法(工具函数的使用):
- 去nhanes_data_showcase_zh.xlsx 中查找自己所需变量的 field_id,这里以性别为例

这里有三条性别的变量,毫无疑问,变量 field_id 11267 和 11269是我们需要的变量。 为什么有这两条呢?因为这两个变量的 english_text 并不完全一致。在合并不同时期的变量时,为了保证我们用的数据是完全可靠的,我们只将该变量的变量名、sas_label、english_text 完全一样才视为同一变量。后面那些年份的哪些数据框包含这个变量也说明了这一点

- 那为了进一步查看每个调查时期的该变量是否完全一致,我们用 generate_nhanes_codebook 函数查看该 field_id。该函数的使用方法可使用? generate_nhanes_codebook查看
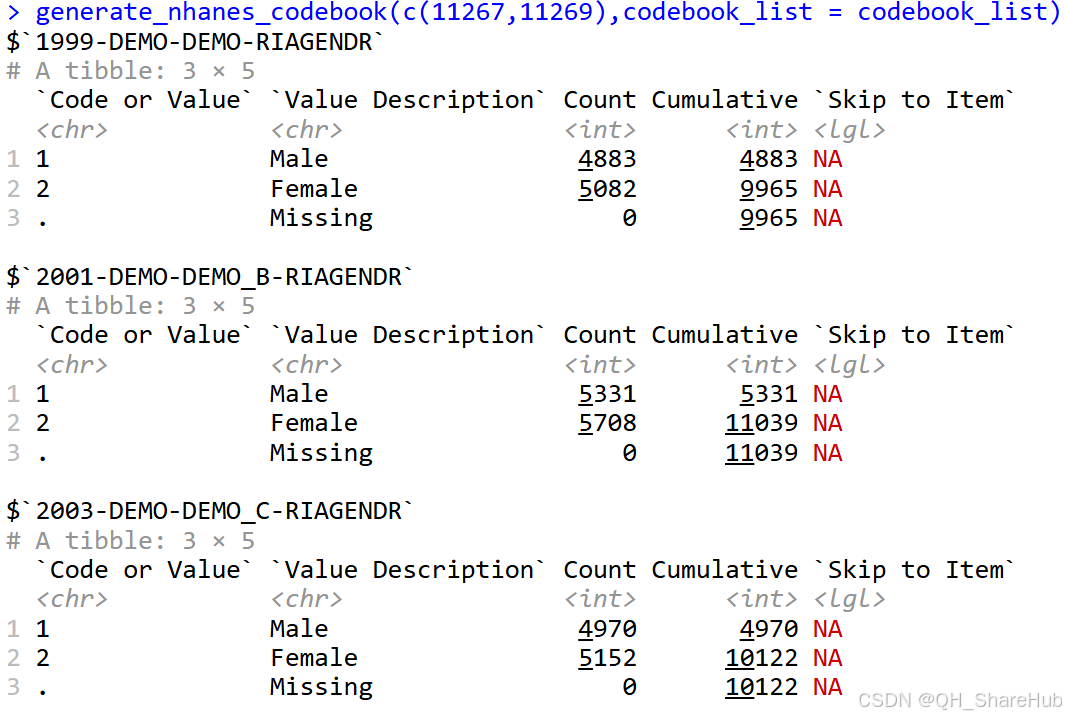
可以看到都完全一致,1代表男,2代表女,所以不用做任何处理
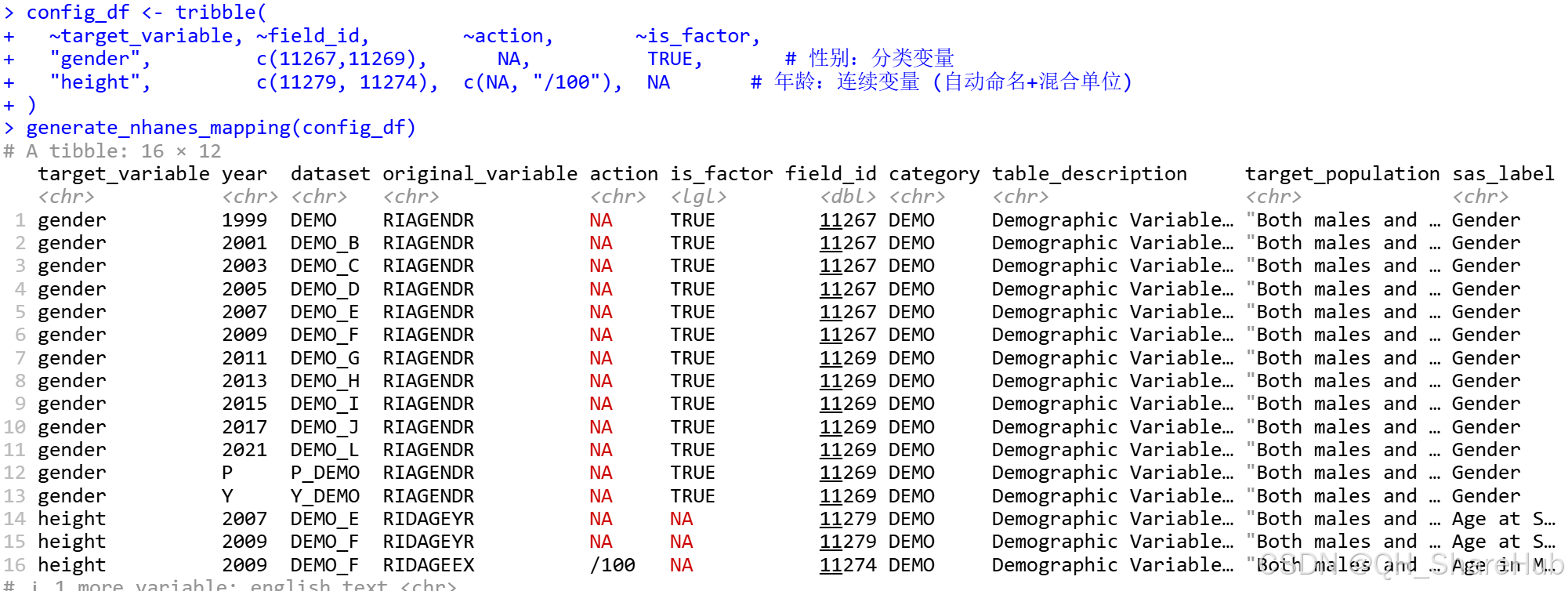
- 写你需要的变量的配置数据框

其中action列指的是是否对前面所对应的 field_id进行操作,这里以身高height 作为例子,它有11279和11274这两个 field,但是第一个field 11279 单位是cm,但11274单位是 m,那如果相统一单位为 cm,则第二个field 需要处理100,即"/100"。is_factor 是用户自己判断这个变量是否是分类变量,然后设置。
- 使用刚刚的变量配置数据框,生成针对每个数据框的操作书(对nhanes每个数据框如何操作)
- 最后一把就是根据操作书进行操作了,更多参数可通过? process_nhanes_data查看
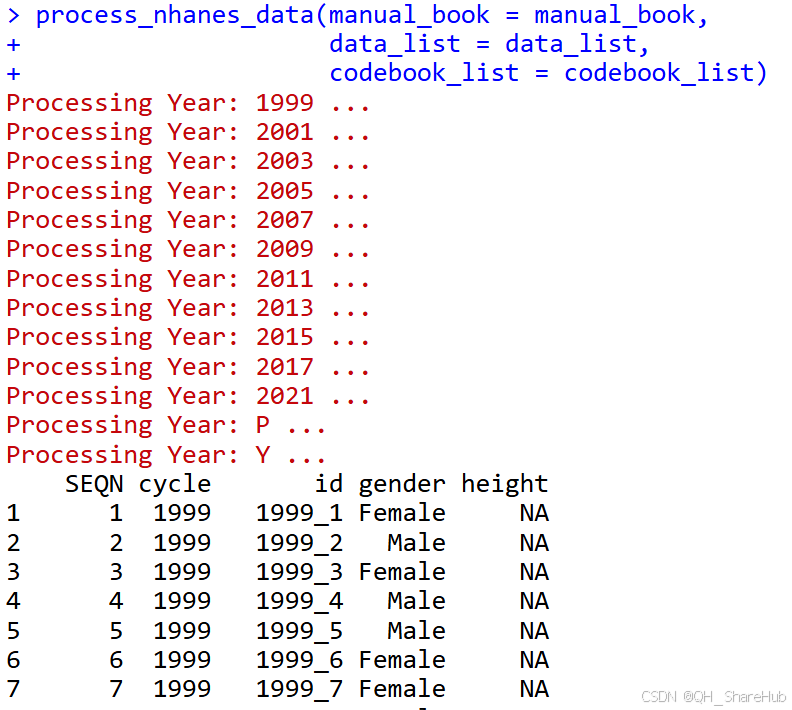
最后就可以开心地分析数据啦!!
Tips:用户可以保存变量的 config 方便后续重复使用