微服务跨库查询:从 24 秒优化到 0.6 秒,我做了什么
做运营看板的时候遇到个问题:需要把用户对 AI 回复的评价(点赞/点踩)和用户名一起展示出来。听起来简单,但数据分散在两个库里------评价数据在业务库,用户名在用户库。
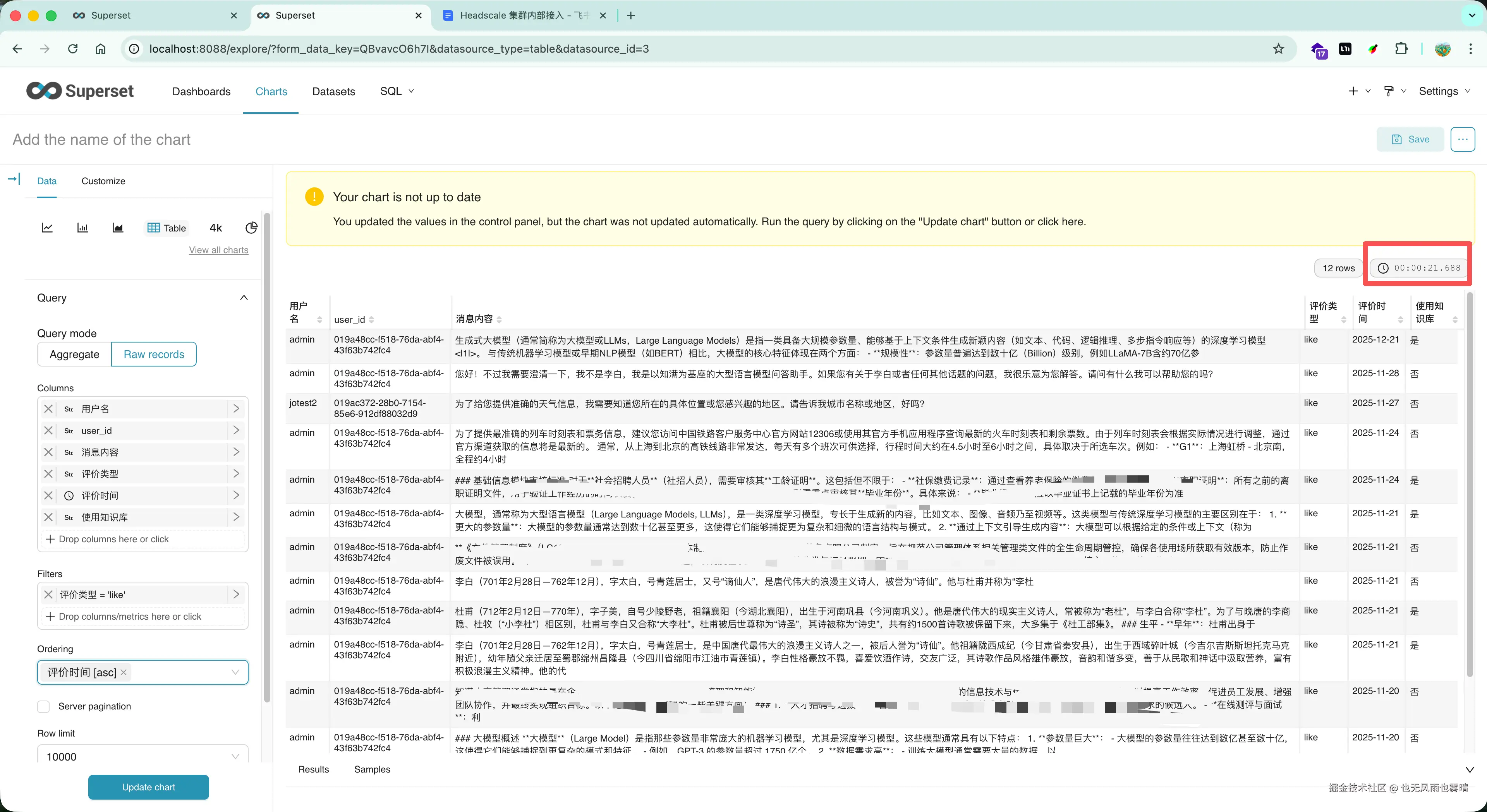
第一反应是用 Superset 的跨库查询功能,结果查一次要 24 秒,完全没法用。
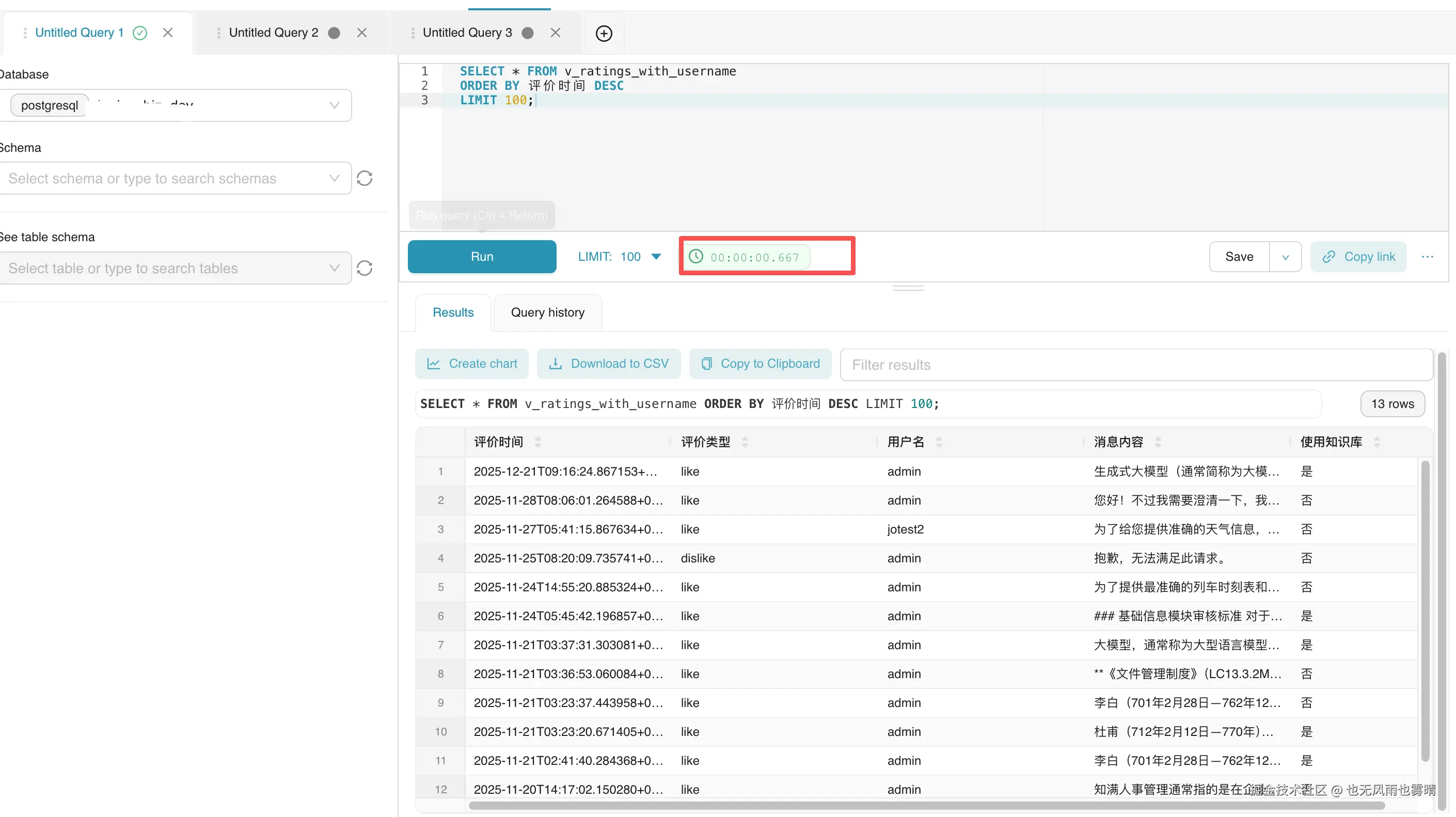
折腾了一圈,换成 PostgreSQL FDW 方案,同样的查询 0.6 秒就出来了。40 倍的性能差距。
meta database:
FDW:
背景:微服务的数据隔离问题
我们的系统是典型的微服务架构,三个服务各用各的数据库:
innies_biz_dev → 业务数据(消息、评价、知识库)
innies_users_dev → 用户数据(用户名、邮箱、权限)
innies_loom_dev → Agent 执行数据平时服务间通信走 gRPC,数据隔离得挺好。但做运营看板的时候问题来了:
sql
-- 需求:展示评价记录,带上用户名
SELECT
r.rating_type, -- 评价类型(业务库)
u.username, -- 用户名(用户库)← 跨库了
m.content -- 消息内容(业务库)
FROM message_ratings r
JOIN users u ON r.user_id = u.id两个库里的表,没法直接 JOIN。
第一次尝试:Superset Meta Database
Superset 有个实验性功能叫 Meta Database,号称可以跨库查询。配置挺简单:
python
# superset_config.py
FEATURE_FLAGS = {
"ENABLE_SUPERSET_META_DB": True,
}添加三个数据库连接,再加一个 Meta Database(URI 是 superset://),就可以这样查了:
sql
SELECT *
FROM "innies_biz_dev.public.message_ratings" r
LEFT JOIN "innies_users_dev.public.users" u ON r.user_id = u.id语法有点怪,整个表路径要用双引号包起来。但能跑就行,对吧?
结果:24 秒。
查 13 条数据,等了 24 秒。复杂一点的查询直接超时。
问题在哪?
用 EXPLAIN ANALYZE 看了一下数据库层的执行时间:12 毫秒。
数据库只花了 12ms,但整个查询要 24 秒。时间都花在哪了?
画个图就明白了:
问题就在这:它把所有表的数据都拉到应用层,再用 Python 做 JOIN。
- 多次网络往返
- 全量数据传输(即使你只要 10 条结果)
- Python 做 JOIN(效率远低于数据库引擎)
换方案:PostgreSQL FDW
FDW(Foreign Data Wrapper)是 PostgreSQL 的内置功能,可以把远程数据库的表映射到本地,像本地表一样查。
关键区别:JOIN 下沉到了数据库内核层。
虽然在这种跨库场景下(本地表 JOIN 远程表),JOIN 动作依然发生在本地,但它比 Superset 快得多的原因是:
- 内核级效率:C 语言实现的数据库引擎做 JOIN,比 Python 在内存里处理 Pandas/List 快几个数量级。
- 按需传输:PG 优化器很聪明,会把 WHERE 条件下推到远程库,只拉取需要的数据,而不是全量拉取。
- 协议高效:数据库内部传输用的是二进制协议,比 HTTP/JSON 高效得多。
配置过程
FDW 配置需要数据库管理员权限,分这么几步:
1. 创建外部服务器
sql
-- 告诉 PostgreSQL 远程库在哪
CREATE SERVER users_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'postgres-cluster.svc.cluster.local',
dbname 'innies_users_dev',
port '5432'
);2. 创建用户映射
sql
-- 告诉 PostgreSQL 用什么凭证连远程库
CREATE USER MAPPING FOR innies_dev
SERVER users_server
OPTIONS (user 'innies_dev', password 'xxx');这步容易踩坑。如果报 user mapping not found,说明当前用户没有对应的映射。
3. 导入外部表
sql
-- 把远程的 users 表映射过来,放到 fdw_users schema
CREATE SCHEMA IF NOT EXISTS fdw_users;
IMPORT FOREIGN SCHEMA public
LIMIT TO (users)
FROM SERVER users_server
INTO fdw_users;4. 创建视图
sql
-- 封装 JOIN 逻辑,方便使用
CREATE VIEW v_ratings_with_username AS
SELECT
r.created_at AS 评价时间,
r.rating_type AS 评价类型,
u.username AS 用户名,
SUBSTR(m.content, 1, 200) AS 消息内容,
CASE
WHEN m.references IS NOT NULL
AND m.references::text != '[]'
THEN '是'
ELSE '否'
END AS 使用知识库
FROM message_ratings r
LEFT JOIN task_messages m ON r.message_id = m.id
LEFT JOIN fdw_users.users u ON r.user_id::uuid = u.id
WHERE m.role = 'assistant';配置完成后,在 Superset 里直接查这个视图就行:
sql
SELECT * FROM v_ratings_with_username LIMIT 100;结果对比
| 方案 | 查询耗时 | 数据库耗时 |
|---|---|---|
| Superset Meta DB | 21-24s | 12ms |
| PostgreSQL FDW | 0.5-0.8s | 0.5s |
40 倍的性能提升。
踩过的坑
1. 权限不够
lua
permission denied to create extension "postgres_fdw"创建 FDW 扩展需要超级用户权限,得让 DBA 帮忙。
2. 用户映射找不到
sql
user mapping not found for user "innies_dev"DBA 配好了 FDW,但只给 postgres 用户创建了映射,没给应用用户创建。补一个就好:
sql
CREATE USER MAPPING FOR innies_dev
SERVER users_server
OPTIONS (user 'innies_dev', password 'xxx');3. 表找不到
arduino
relation "users" does not exist外部表被导入到了 fdw_users schema,不是 public。查的时候要用 fdw_users.users。
什么时候用哪个方案
| 场景 | 推荐方案 |
|---|---|
| 数据量小、偶尔查一次 | Superset Meta DB 够用 |
| 需要秒级响应 | PostgreSQL FDW |
| 可以接受数据延迟 | 定时同步到一个库 |
| 大规模数据分析 | 搞个数据仓库(成本高) |
总结
同样的 JOIN,在应用层做和在数据库层做,性能差距可以到 40 倍。
微服务架构的数据隔离是好事,但做跨服务报表的时候确实麻烦。FDW 是个不错的解决方案:
- 配置一次,长期使用
- 实时数据,无需同步
- 对线上库影响很小
- PostgreSQL 内置功能,不用额外装东西
代价是需要 DBA 权限来配置,但这个一次性成本是值得的。
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills (按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB