《凤凰架构-构建可靠的大型分布式系统》读书笔记 -- 关于网络请求过程中的一些缓存和分流技术
-- 关于网络请求过程中的一些缓存和分流技术)
前言
我们的请求从浏览器传到服务侧的中间会经过很多个流程,在这些阶段中会有很多方式可以优化请求,加速结果的返回,可以将直接将结果返回 (其中一个重要的手段就是缓存 )、通过不同的措施进行负载均衡分流 或者对传输链路进行优化 。 这些过程很多是基础架构或者已有的软件设施实现的,从某种程度上来说是"透明"的。
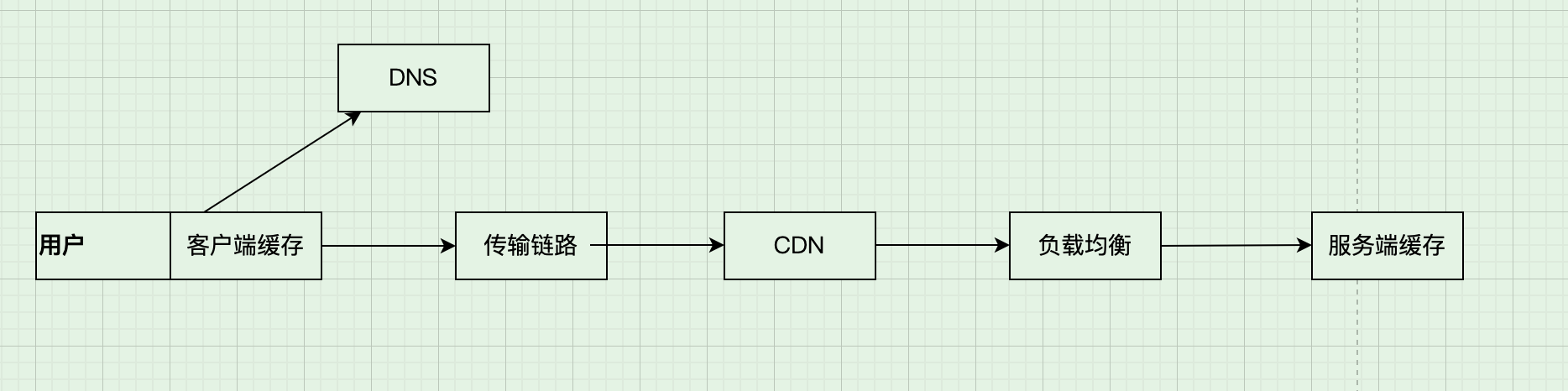
下文简单总结谈论这个过程中的一些流程和相关技术。
注"下文的客户端以web浏览器、http协议来说明。
客户端缓存
浏览器中提供了强制缓存 和协商缓存 这两种缓存机制,可以让服务端提供一些信息给客户端浏览器,告诉浏览器之前请求的一些信息在多长时间内可以直接使用客户端的本地缓存(比如说服务端在这段时间内保证不会更改),不必通过网络再次请求。 或者服务端响应304/Not Modified 告诉客户端请求没有变化,客户端直接使用上次的结果即可。
强制缓存
强制缓存主要有Expires 和Cache-Control 两种Header。 前者服务端承诺请求的资源在给定的时间截止之前不会变动;
bash
HTTP/1.1 200 OK
Expires: Wed, 21 Oct 2015 07:28:00 GMT后者可以有多个选项,如max-age, public(或者private), no-cache... 等等, 控制了缓存的时间、资源私有性质,是否要缓存等信息。
bash
HTTP/1.1 200 OK
Cache-Control: public, max-age=60协商缓存
协商缓存可以通过<Last-Modified, If-Modified-Since > 以及<ETag, If-None-Match> 这两对Header来实现。
前者Last-Modified 是服务端响应的Header, 用于告诉客户端某个资源的最后修改时间。当客户端再次请求时会通过If-Modified-Since 把之前收到的最后修改时间带给服务器端,服务端如果检测这段时间内没有修改,可以直接返回一个304/Not Modified, 这样就不用携带具体的消息体,达到省流的目的。
如下服务端第一次响应 Last-Modified
bash
HTTP/1.1 200 OK
Last-Modified: Sun, 07 Dec 2025 10:28:00 GMT客户端下一次请求的时候会带上If-Modified-Since
bash
If-Modified-Since: Sun, 07 Dec 2025 10:28:00 GMT服务端的第二次响应如下
bash
HTTP/1.1 304 Not Modified对于<ETag, If-None-Match> 这一对Header来说,是通过对资源进行标识的方式来表明资源有没有更改,服务端通过对资源进行Hash(比如说问价名、修改时间、大小等等), 然后将Hash结果通过ETag的方式传递给客户端;客户端在下一次请求的时候会If-None-Match 将上一次服务端返回的ETag带给服务端; 服务端通过返回的ETag判断资源是否有变动;
这种方式过程和 <Last-Modified, If-Modified-Since > 一样,只不过对文件的标识不一样,前者通过时间(只能精确到秒),后者通过Hash。
域名解析
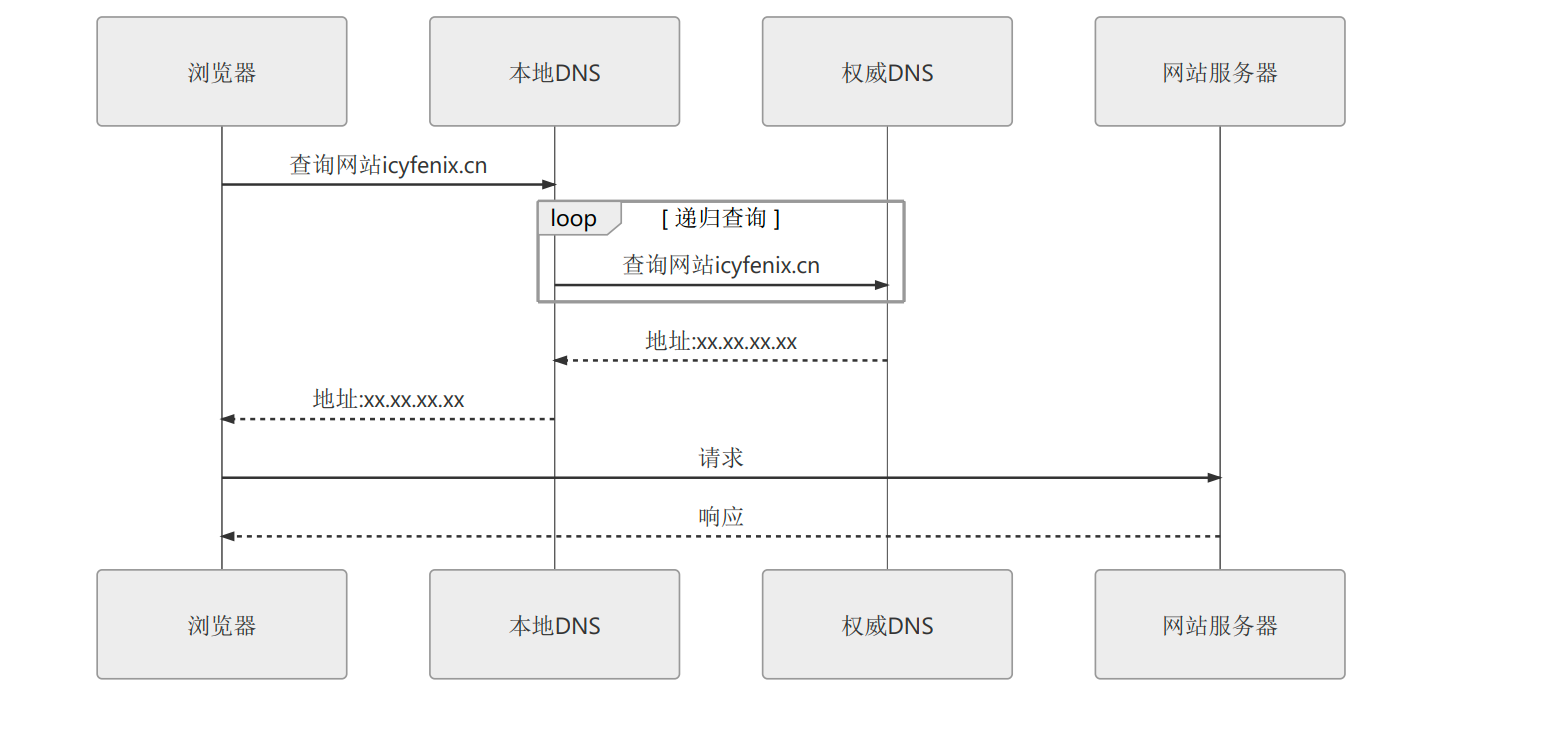
DNS域名解析是分流的一种方式,当我们请求中的域名在通过 本地HOST-> 各种权威DNS域名服务器->根域名服务器 的过程中,本地运营商可以通过请求的一些特征(最典型的就是地域特征)进行智能策略的选择 ,返回对应的地址记录 (比如说华东地区的域名就返回华东地区配置的ip。 对, 一个域名可以配置多个地址记录),将访问者路由到最合适的数据中心。
传输链路
当客户端请求准备发出,在网络中传输的时候,这个过程依然有一些方式可以优化性能。比较常见的有以下几种:
连接优化
对于http协议刚吃的那时候,走的都是短连接,每一次请求都需要建立新的tcp连接,请求结束断开连接。后来随着网络数据的不断丰富,建立连接带来的消耗在整个传输过程中占比非常大。
于是,后续除了http长连接机制,即Keep-Alive机制。客户端在与服务器建立连接,发送请求之后,不立即断开(保持心跳长连接),后续的请求可以接着从这个请求中发出。Http1.0中这个机制是默认关闭的,而在Http1.1中这个机制就是默认打开的了 。 这种保持长连接的方式,从客户端角度来看一般是以连接池的形态存在的。
连接复用虽然好,但是也有一个弊端。就是"队首阻塞 "问题。如果客户端需要同时往一个连接中并发 发送多个请求, 连接复用机制只能够在一个TCP连接中 按照顺序来一个一个发送(不然的话,没办法区分每个请求的返回结果),这样如果前面的请求花费的时间比较长,那么TCP连接就只能空着,后面的请求只能阻塞等着。
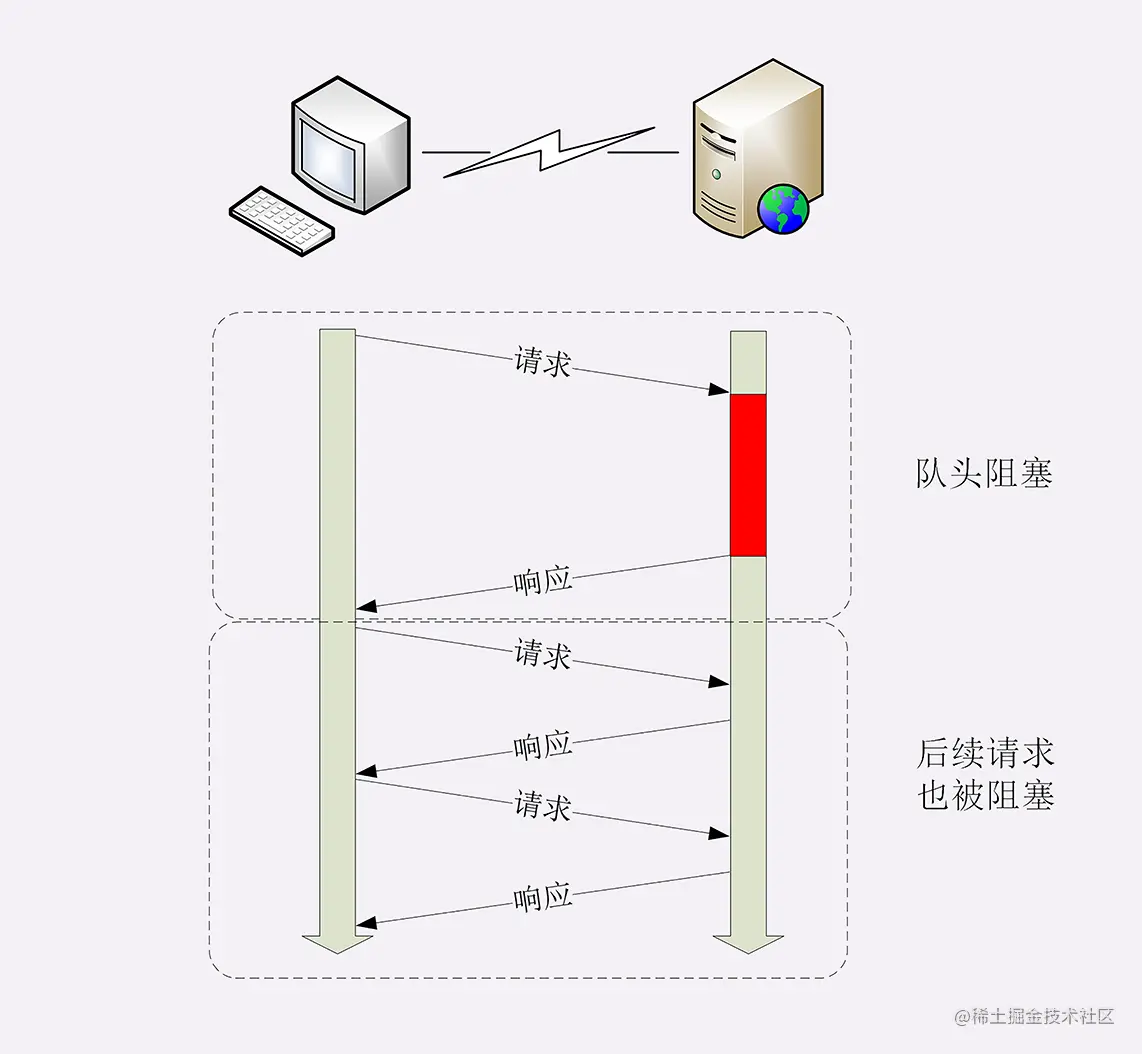
分析一下上面队首阻塞的问题,其实如果能够在一个连接中标识不同的请求,那么就可以解决这个问题,在同一个连接中不断发送不同的请求(前面的请求还没回复,后续的请求依旧可以发送)。 在Http/2中 引入了一个帧和流ID的概念。帧 用来描述最小粒度的信息单位,每一个帧都带有一个流ID用来辨识。 这样同一个TCP连接中传输的多个数据帧就可以根据流ID来区分出来,以此客户端可以将不同流中的数据重组成不同的HTTP请求。
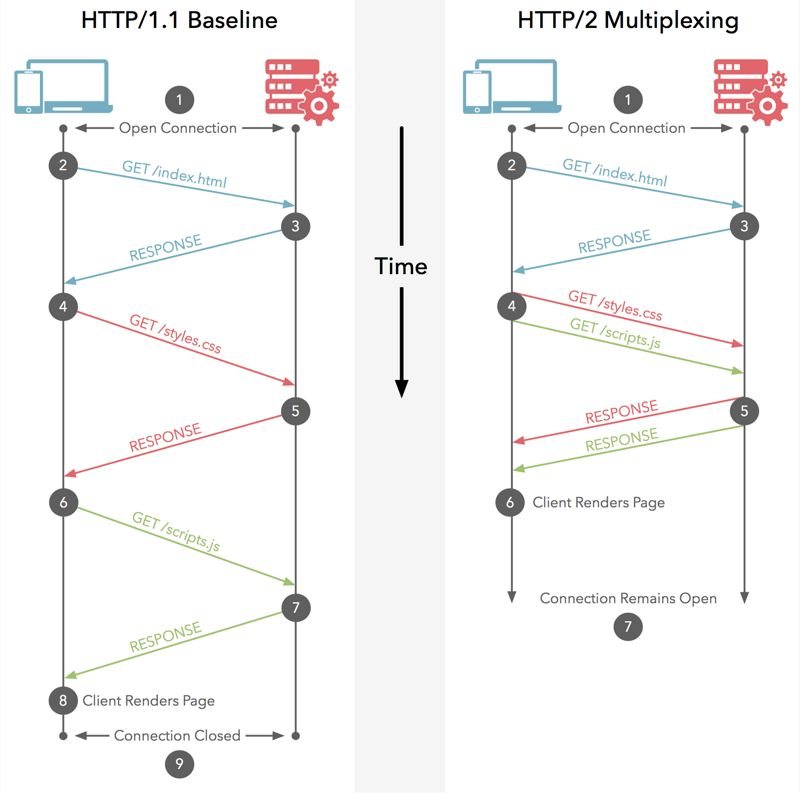
传输压缩
如果传输的数据比较大的话,http中提供了一种方式可以将数据进行压缩传输。比如说,当客户端可以接收压缩的数据时,就会在请求的Header中带有Accept-Encoding:gzip 的相关字段。如果服务端采用压缩之后的数据,那么响应的Header中也会带有Content-Encoding:gzip 的字段。 一般来说,对于文本数据来说,采用了gz压缩传输的数据量可以将至原来的20%左右。
上面针对的是包体数据的压缩。在HTTP/2中又提出了一种头部压缩 的方式,它 优化 了HTTP1.x中,使用文本的形式传输header,每次都需要重复传输多则几百到几千的字节的浪费问题。 HTTP/2中使用HPACK(HTTP2头部压缩算法)压缩格式对传输的header进行编码 ,减少了header的大小。并在两端维护了索引表,用于记录出现过的header,后面在传输过程中就可以传输已经记录过的header的键名,对端收到数据后就可以通过键名找到对应的值。
QUIC
在Http/1.x Http/2.x 版本中,使用的网络请求大部分都是Http Over TCP 这样的一种协议方式。 到了Http/3中,Google提出了一种新的底层协议,QUIC(Quick UDP Internet Connection ),即使用UDP来作为Http请求的传输层协议,Http Over UDP。
UDP本身不提供重传的机制,QUIC将丢包重传的机制上移到应用层,自己来实现丢包重传,这样可以对每个流做单独的控制,如果其他流发生错误,协议栈可以继续独立的为其他流提供服务。
同时,对于移动网络中经常涉及到的网络切换问题(比如说从wifi 切换到移动网络)对于普通的TCP连接来说,肯定要断链重连了(数据也需要重传)。在QUIC协议中,提出了一个连接标识符 的概念,这相当于之前的五元组换成了一种新的标识,无需依靠ip地址,这样网络即使切换了,依然可以复用之前连接的数据。
CDN(内容分发网络)
CDN是网站边缘加速的一种常见方式,它有点类似于部署在多个地域的网站缓存,用户请求时,自动路由到离用户近的边缘节点,这样可以提升网站的服务性能。
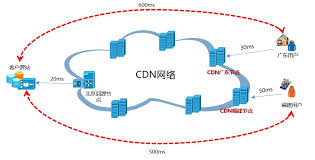
简单来说,其主要的原理是通过DNS服务器来"截获" 用户的发送请求,将请求路由到指定的边缘节点中。一般来说,网站提供者需要将域名(比如说是www.abc.com)的解析权(或者部分解析权)提供给CDN服务商,当用户发送请求时,www.abc.com这个域名会解析到CDN提供商的ip地址上。
本质上你可以认为加了一个中间层。如下图所示是原书的一个截图,画的比较清晰。
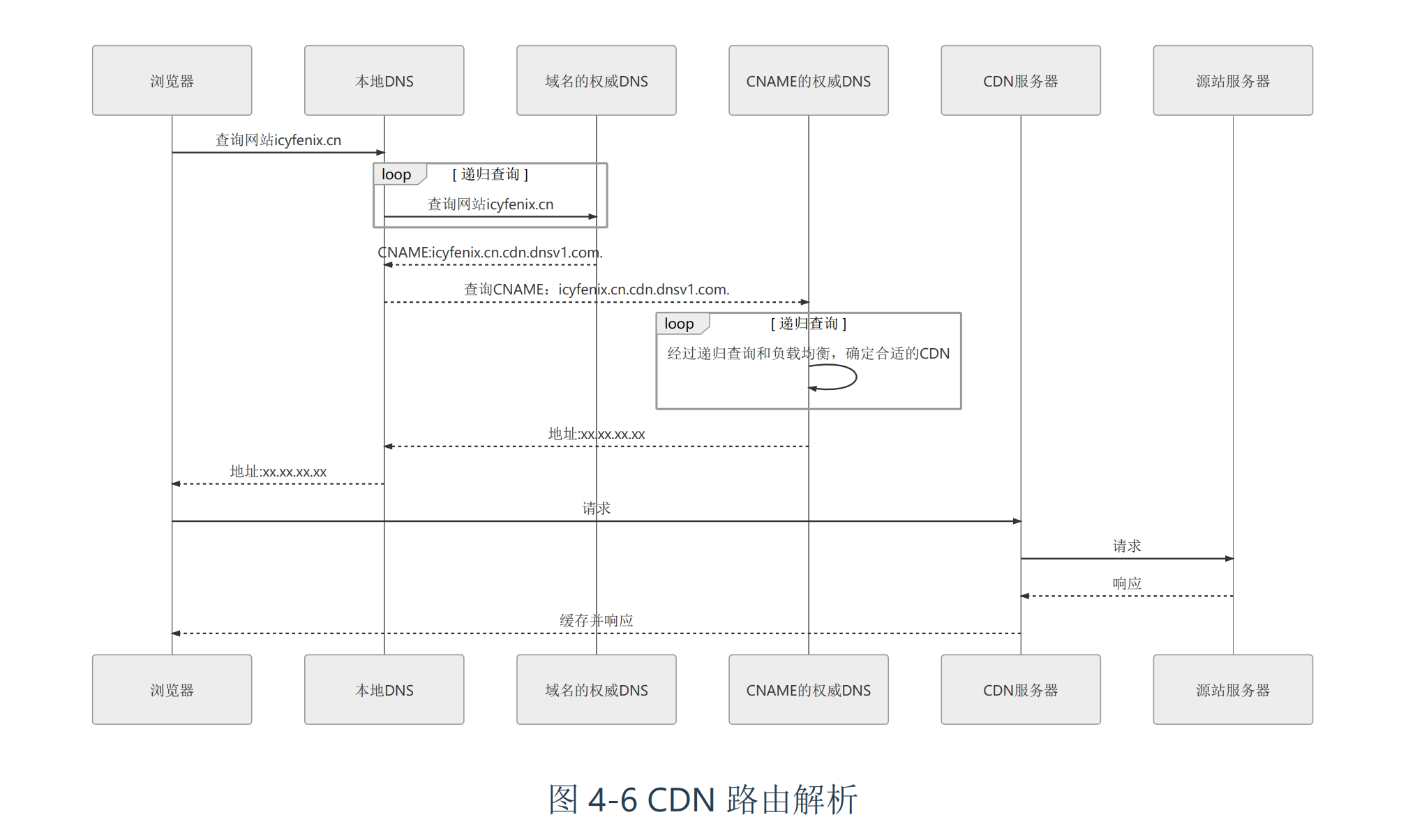
当"截获了"用户的请求之后,CDN就可以通过主动(或者被动)的方式缓存源站(真实的网站)的资源和内容,这样利用遍布各处的强大的CDN网络,可以大大提供网站的服务能力。
负载均衡
负载均衡是为了让请求可以更均匀(或者根据业务特性进行路由)的分发给服务节点上。对请求方来说,它请求的只有一个地址,但实际提供服务的是多个节点。
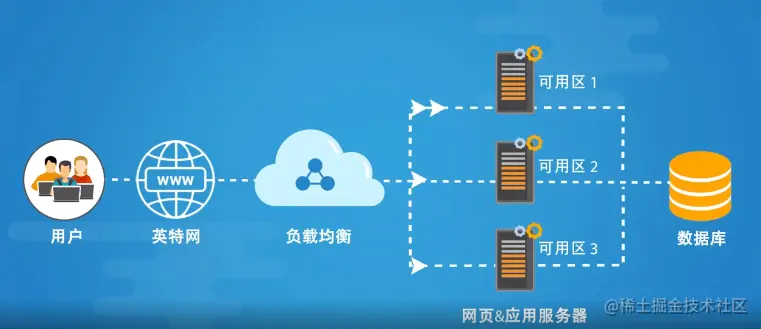
需要说明的是,负载均衡在不同的层级由不同的实体来代替。比如说在DNS解析中,会根据用户的地址分配到离用户比较近的数据中心,这也是一种负载均衡。
下面讨论的主要是请求进入数据中心内部的一些负载均衡。我把它分为两种,一种是转发型 负载均衡,一种是代理型负载均衡。
何为转发,何为代理呢?
这两个概念在有些场景确实可以混用,代表了中间的这个实体(可能是负载均衡、也可能是网关)将请求发到下游 一侧。 这里作为负载均衡的两种不同类型来讨论,区别在于这个中间实体和客户端、真实的服务器建立TCP连接 。如下图所示。
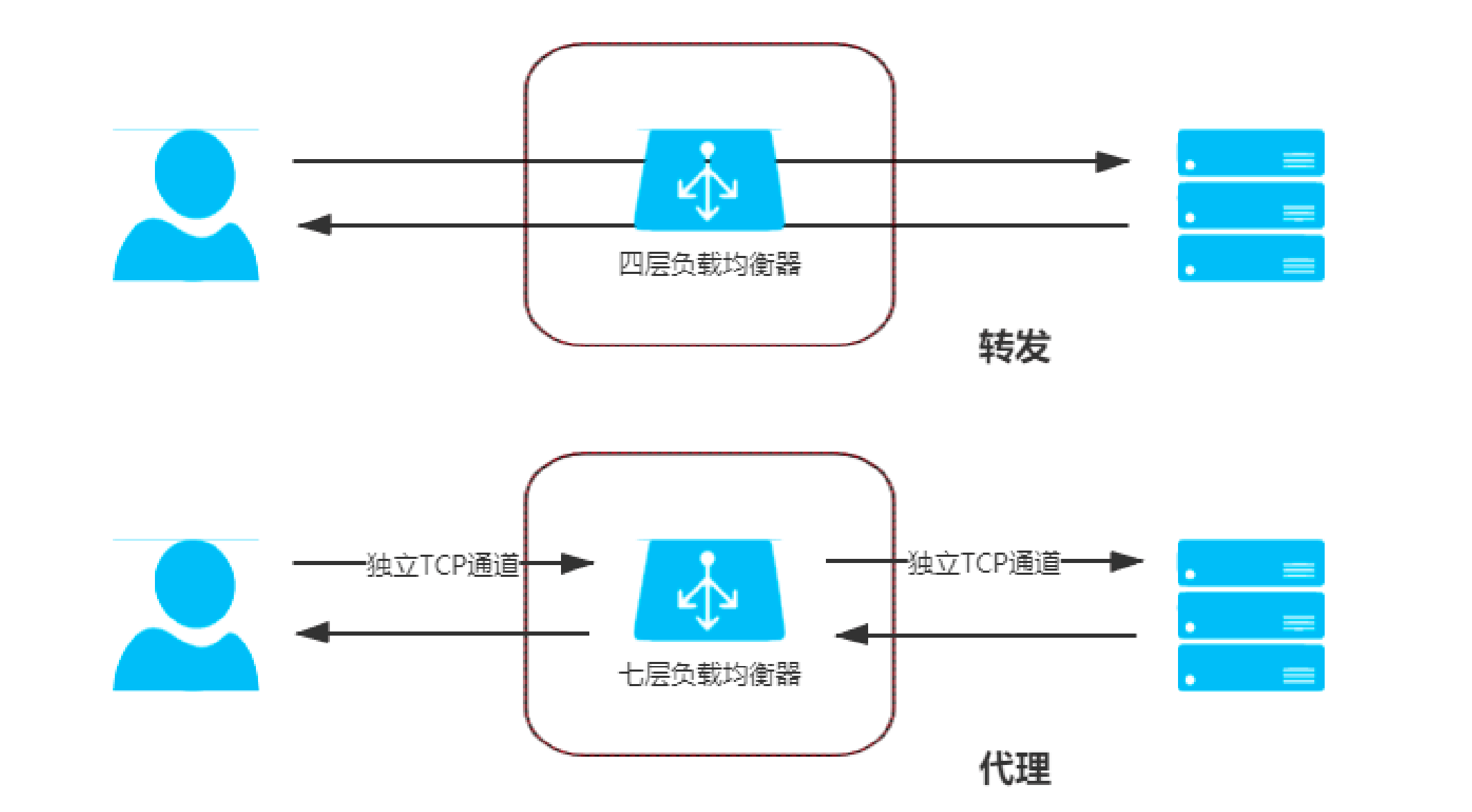
为什么要这样区分呢?
转发型负载均衡
因为对于转发型负载均衡来说,其不需要建立单独的连接,不需要消耗更多的CPU和内存资源(建立连接意味着要握手、有心跳、有缓冲这些...) ,收到请求流量之后直接转发(根据具体层次的不同,可能要修改MAC地址、IP地址等)就可以。 也就意味这种方式性能更高,一般适合作为低层次的负载均衡(连接其他较高层次的负载均衡)。
根据具体网络层次的不同,转发型的负载均衡有数据链路层的负载均衡和网络层的负载均衡。
数据链路层的负载均衡
数据链路层的负载均衡主要是是修改请求的数据帧中的 MAC 目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的 MAC 目标地址转发到服务器集群中对应的服务器。 主要原理如下图所示。
这种方式由于不改变ip层的地址变化,所以需要真实服务器和负载均衡的ip地址相同。 也因为此,采用了这种方式,服务器的返回包可以直接返给用户,而不用经过负载均衡(这种三角的转发方式,也叫做DR(Direct Routing))。
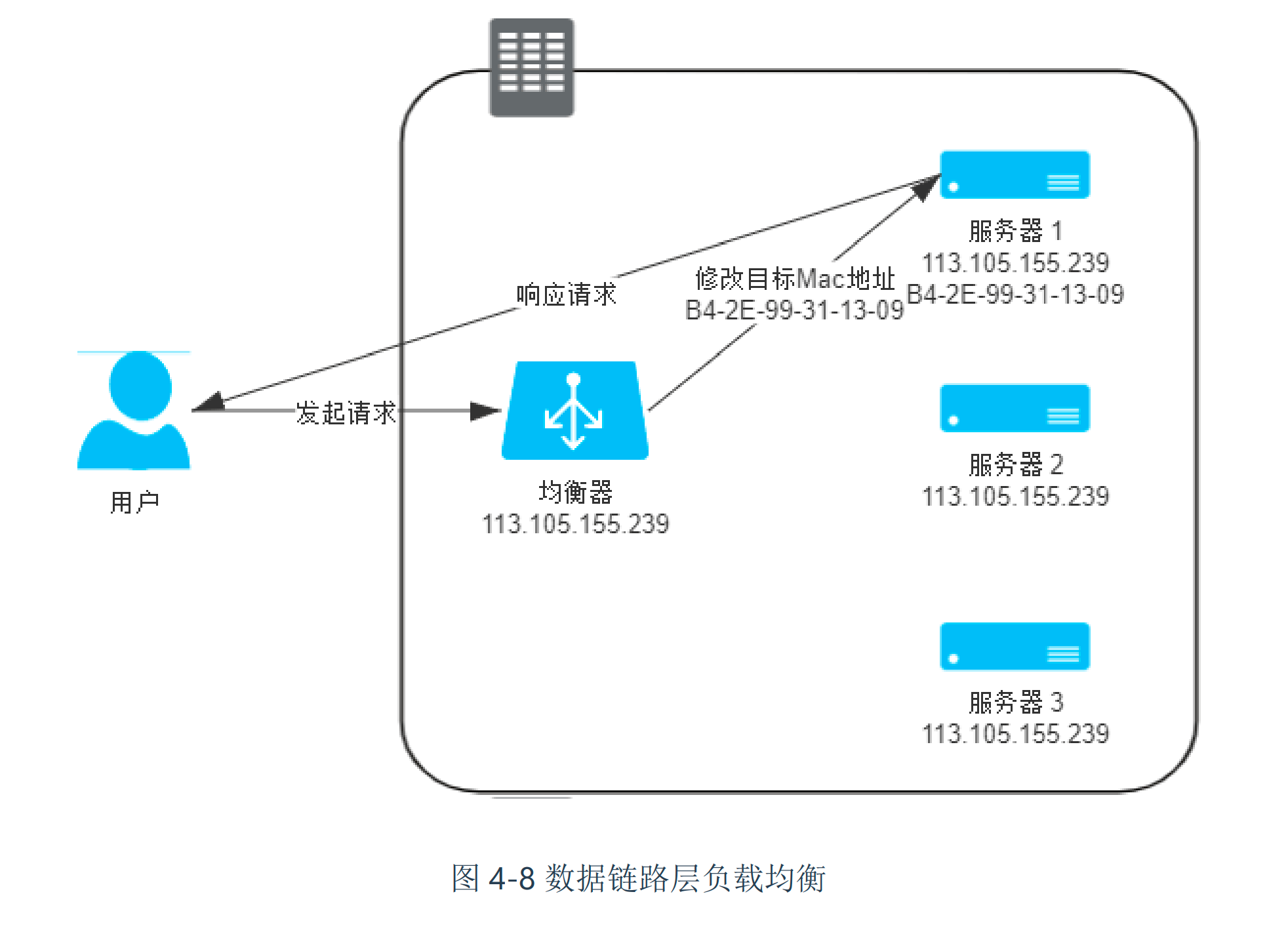
既然是二层转发,所以数据链路层的转发方式也不能跨越VLAN, 一般会在同一个子网中使用。
网络层负载均衡
还有一个工作在网络层的负载均衡,和数据链路层类似,网络层主要是通过修改ip的方式来实现的。 一般常见的又分为两种,一种是使用"IP隧道的方式",通过把原包塞进一个新的ip包中,新的ip包的目标地址是真实的ip地址。同时,服务节点收到包之后,也需要先拆掉最外层的包。如下图所示。
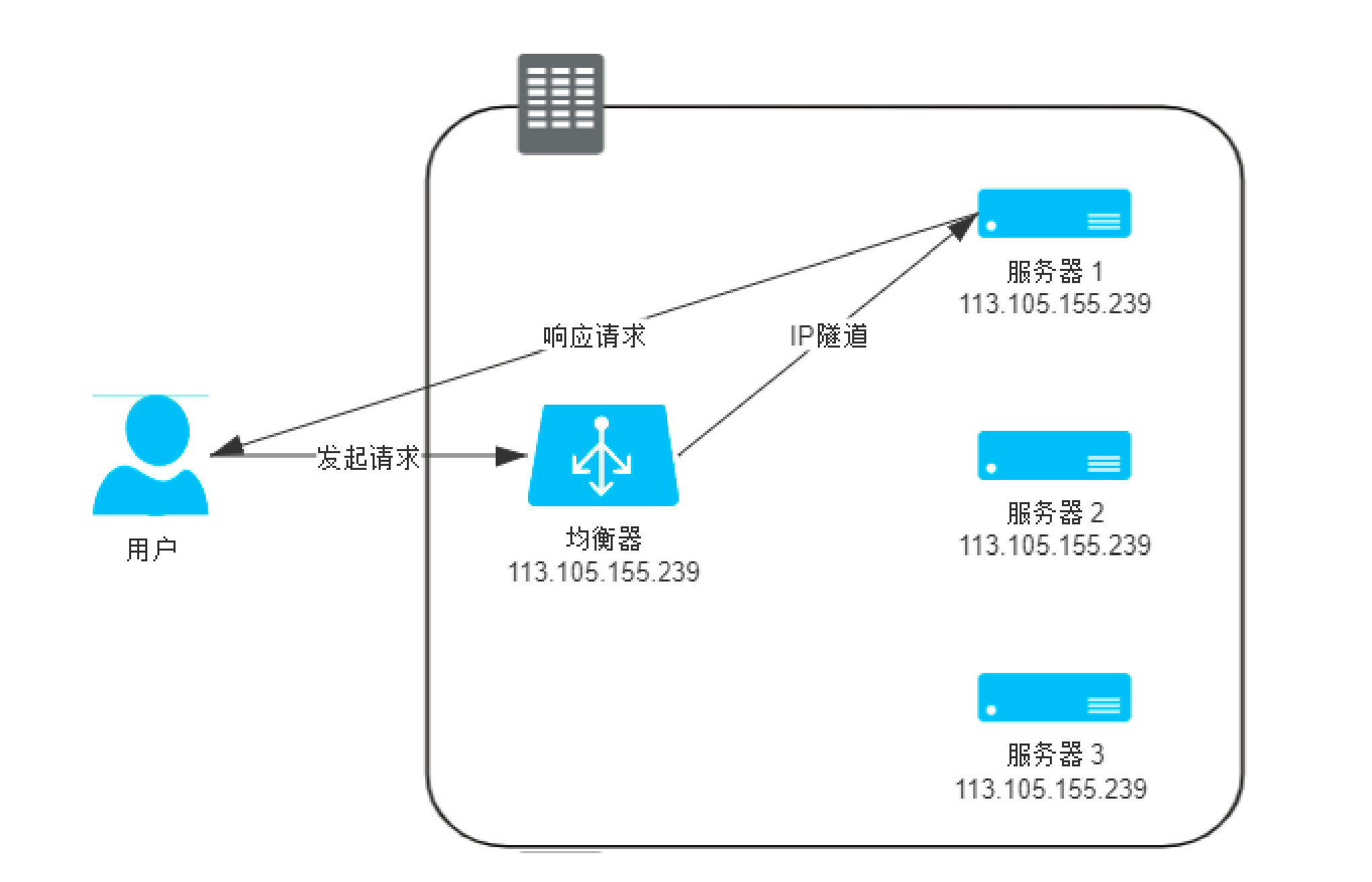
还有一种是直接修改ip地址的方式。中间的负载均衡直接把目标ip改成服务的节点ip, 然后把包转发给目标节点。目标节点处理之后还要将结果转给负载均衡,负载均衡再修改返回包的目标地址(客户端)地址,这样完成一次完整的网络请求。 这种方式和NAT很相似,也叫做NAT模式的负载均衡模式。如下图
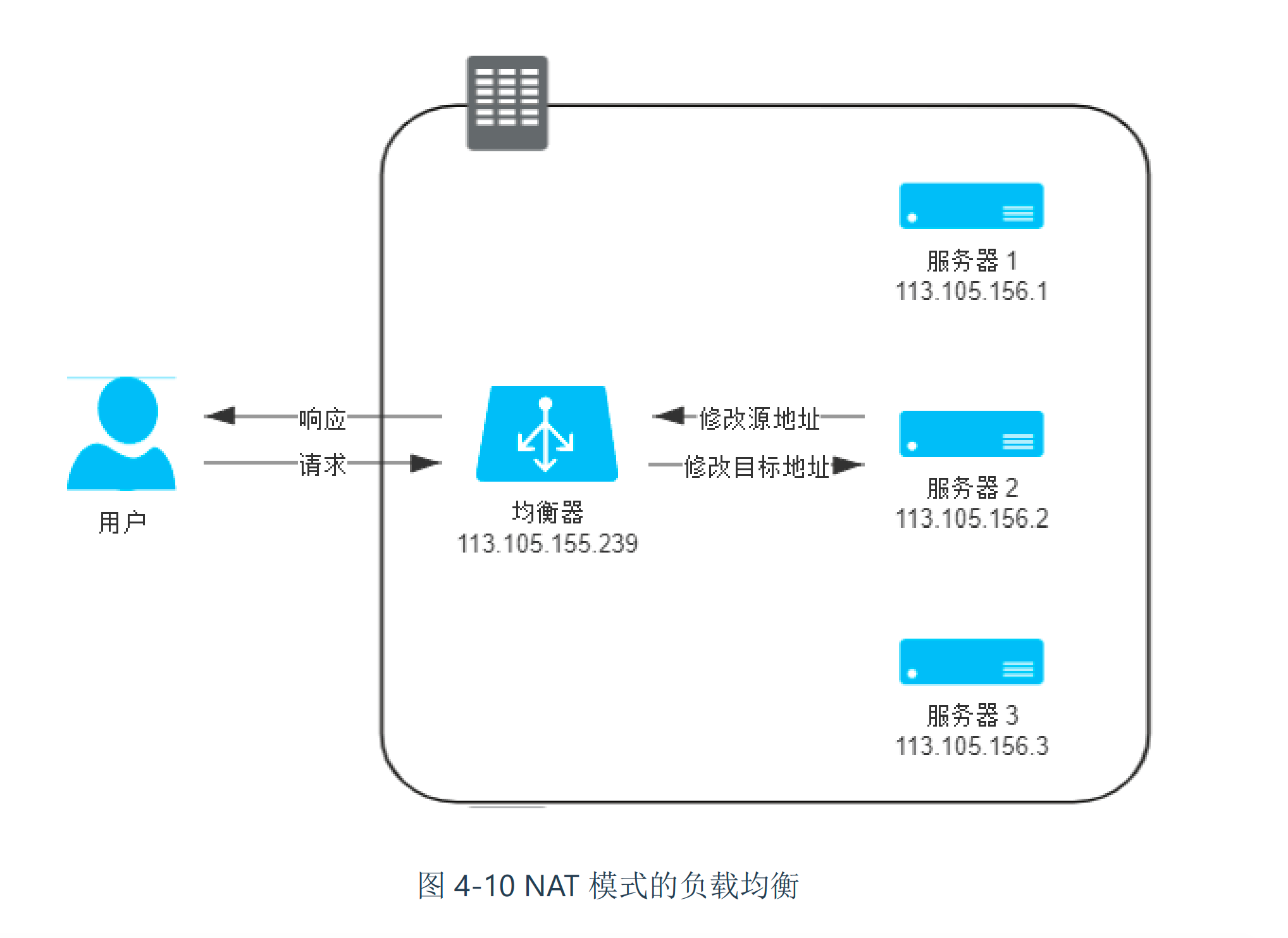
代理型负载均衡
而对于代理型负载均衡来说,它工作的层次更高,可以根据TCP和HTTP层的一些更复杂的功能(比如说根据不同的请求域名、请求路径转发到不同的服务,从某种程度上来说有点类似于网关的功能了)。 当然,由于要单独建立两条独立的连接,这种方式的性能消耗更高些。
一般对于大部分业务场景来说,使用的都是这种方式的负载均衡。包括常见的Nginx。还有一些云服务商提供的负载均衡。如【2】中介绍的那样。
均衡算法
将请求转给哪一个后端的负载,这也就是具体均衡所涉及到的内容。这个部分各个书籍和资料很多,这里简单罗列,就不赘述了。
- 轮询
- 加权轮询
- 随机
- 一致性hash
- 最少连接数
- ...
服务端缓存
为了缓解DB的IO压力,大部分的业务系统都会引入服务端缓存来提升系统的性能。最常见的要数引入一个Redis中间件,来当DB的缓存。
除了redis这种中间件类集中式缓存之外,有些一致性要求不高的服务(但是要求高性能的服务)还会引入本地缓存来提高服务的性能。如下图所示。

关于服务端缓存的一些常见用法这里就不多说了。主要说下缓存使用过程中的常见风险。
缓存穿透
缓存穿透指的是请求的数据db中没有,缓存中自然也不会有,因此请求每次都会达到db上,缓存也就起不到作用了。 对于这种情况一般有两种方式可以处理:
- 反过来想想,既然缓存中没有原始数据。那就搞一个特殊的对应为空的缓存key。这样当在缓存中查到了相应的key,说明没有数据
- 使用布隆过滤器,它可以用最小的代价判断元素是不是存在于某个集合中。如果过滤器查询到结果不存在,直接返回即可。
缓存击穿
缓存击穿指的是某些热点数据因为某种原因突然失效(比较常见的一个原因是因为超时),这样大量请求这个热点的数据就会直接达到db上,这就是缓存击穿。 如果避免缓存击穿,也有两种方式可以处理:
- 手动管理热点数据,避免自动失效
- 进行加锁同步,或者使用singleflight合并请求解决缓存击穿问题.
缓存雪崩
缓存击穿指的是个别数据,如果大批不同的数据在短时间内一起失效,造成了大量的请求打到DB上。这一般是因为大量的数据是同时加载到缓存中的(比如说通过预加载方式),如果这些数据还有相同的过期时间,则可能会产生雪崩的现象。 还有一种场景式缓存服务崩溃重启,也会造成大量的数据同时失效。 针对缓存雪崩,可以采取下面的方法:
- 将缓存的生存期从固定时间改为一个时间段的随机时间
- 建立分布式的缓存服务,这样可以提高可用性。
缓存一致性问题
既然用了缓存,数据就有了副本,一个必不可少的问题就是一致性问题。对于大部分业务来说,缓存和数据库之间一般不会采用类似2PC这种分布式一致性的协议,但是我们依旧需要尽可能保证缓存和DB之间数据的一致。
这个问题其实还是很经典的,业界其实也是有一些常见的设计模式,如Cache Aside, Read/Write Through, Write Back. 具体可以参照【3】【4】【5】中所说的,这里也就点到为止。
后记
平时我们通过浏览器访问互联网上的资源从用户的角度来看是很普通的一件事,但是这个过程从整体架构的角度看的话,其实是涉及到了很多流程和逻辑。 每一部分都是计算机技术中的大主题,这里参考【1】中透明多级分流系统,总结其中的一些相关内容(尤其是缓存和负载均衡),从大的框架上还是收获了一些东西的。
参考
【1】《凤凰架构-构建可靠的大型分布式系统》
【2】负载均衡监听器概述
【4】三种缓存策略:Cache Aside 策略、Read/Write Through 策略、Write Back 策略
【5】缓存更新的套路