2026 年 2 月 12 日,字节跳动 Seed 实验室正式发布Seedance 2.0(即梦 2.0) 多模态音视频生成大模型。它以统一多模态联合架构为底座,在运动稳定性、角色一致性、多镜头叙事与音画同步上实现全面突破,成为当前国内最接近工业级生产的 AI 视频模型之一。
一、核心定位与行业地位
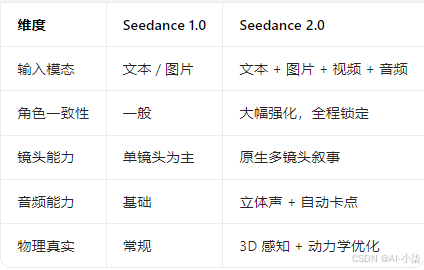
- 定位:全能型 AI 视频生成模型,支持文生视频、图生视频、视频续作、音频驱动、多模态混合生成
- 成绩:在权威榜单Video Arena中文生视频、图生视频双赛道登顶
- 输出规格:2K 电影级分辨率 ,最长支持15 秒高质量多镜头成片,支持视频平滑延长
二、四大核心能力(真正解决创作痛点)
1. 多模态全能参考:一次输入,全域控制
支持文本 + 图片 + 视频 + 音频四模态混合输入,是目前业界参考能力最全面的模型:
- 最多上传:9 张图片 + 3 段视频 + 3 段音频
- 可提取:构图、角色、动作、运镜、节奏、色调、声效
- 交互方式:用
@素材名精准指定用途,零基础也能精准控制
2. 角色 / 场景一致性:告别 "掉脸""穿模"
这是 Seedance 2.0 最具竞争力的升级点:
- 人脸、服装、体型全程锁定,大幅减少变形、闪烁
- 跨镜头、转场、动作变化中保持视觉统一
- 物理模拟更真实,复杂运动、多人交互自然流畅
3. 原生多镜头叙事:一句话出 "分镜短片"
- 自动理解剧本逻辑,生成远景→中景→特写连贯镜头
- 自带运镜:推拉、摇移、慢动作、卡点转场
- 无需手动剪辑拼接,直接产出可发布的短片 / 广告 / 短剧片段
4. 原生音画同步:立体声 + 自动卡点
- 内置双声道立体声生成,环境音、人声、BGM 同步输出
- 上传音频可自动卡点运镜,适配 MV、短视频、广告
- 声画时序对齐精度显著提升,告别音画错位
三、技术亮点:从 "能用" 到 "好用"
- 运动可用率 SOTA:复杂动作、多人交互、物理动力学更接近实拍
- 3D 空间感知:减少穿模、扭曲、漂浮感
- 细节增强:文字、纹理、反光、毛发稳定性更高
- 生成速度提升:较上一代提速约 30%,支持高并发 API 调用
四、接入与使用场景
面向用户
- 普通用户:即梦、豆包等产品内直接使用
- 开发者 / 企业:通过Seedance 2.0 API接入,支持 RESTful 调用、高并发、批量生成
典型场景
- 短视频 / 广告批量生产
- 短剧、漫剧、动画分镜快速预览
- 品牌宣传片、MV、知识科普视频
- 个人 IP 数字人视频、商品展示视频
五、与上一代核心差异
六、总结
Seedance 2.0 标志着AI 视频从 "随机生成" 进入 "精准可控" 的新阶段。它不再是玩具级工具,而是能直接降低成本、提升效率的工业级生产力引擎。
对内容创作者、短视频团队、广告与短剧行业而言,Seedance 2.0 意味着:一人即可等效一个小型拍摄 + 剪辑团队,创意落地速度与成本控制迎来质变。