引言
程序通过编译生成CPU可执行的机器码进行运算,为此设计者在CPU指令执行的编排上做了许多优化工作。本文将从多程序调度执行指令的角度,对CPU指令执行的设计理念进行剖析,希望对你有帮助。
你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
github.com/shark-ctrl/...
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
CPU指令流水线设计的艺术
指令串行化
我们首先回顾一下一条指令的执行过程:
- 读取指令电路根据寄存器给出的下一条指令地址读取指令(Instruction Fetch, IF)
- 译码电路执行指令译码(Instruction Decode, ID)
- 算术逻辑单元ALU执行指令(Execute, EX)
- 访问内存(Memory Access, MEM)
- 数据回写(Write Back, WB)
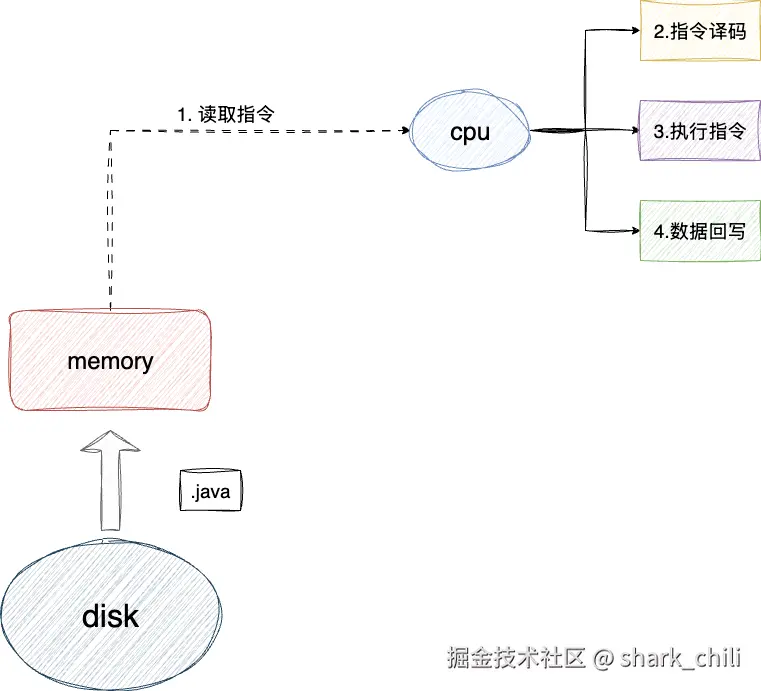
这些不同的动作都会交由不同的执行电路执行,我们以单核CPU为例剖析一下该过程,假设我们有4条执行指令,对应的步骤为:
- 加载指令1
- 指令1译码
- 指令1运算
- 指令1回写
- 指令2加载
- .......
假设每条指令执行一个步骤需要1ns,那么:
- 执行一条完整的指令需要经过4个步骤对应耗时4ns
- 4条指令也就是
4*4ns也就是16ns
从CPU微观的角度来说,这就是一种串行的、单位时间内未能充分利用电路单元的流水线设计:
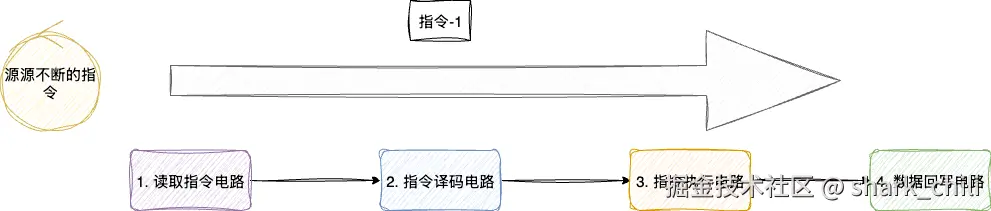
流水线设计思想
为了解决这个问题,我们需要进行优化。上文提及,每条步骤都会对应一个电路,这意味着它们可以并行执行而不冲突。因此,我们可以采用流水线思想,尽可能地利用各个电路单元。例如,现在要执行指令1~4,对应的流水线设计思路为:
- 读取指令电路加载指令1加载,此时译码、运算、回写流程空闲,指令2排队
- 读取指令电路完成指令1读取,向下一步推进,指令交由译码电路进行指令译码,同一时间内流水线的指令读取电路可以从内存中加载指令2,此时运算和回写电路空闲
- 读取指令电路传递指令2,读取指令3,译码电路完成指令1解析,继续指令读取指令电路传递来的指令2
- ......

按照这种设计,指令1执行完成即4ns的时候,对应其它指令执行进度为:
- 执行2执行到alu逻辑单元计算,还差1步回写,即还需要1ns
- 指令3执行到译码,还差2步,即还需要2ns
- 执行4执行到加载,还差3步,即还需要3ns
因为这三条指令是流水线方式执行的,所以在指令4执行完成之后,其它指令也就全部执行完成了,最终耗时约为7ns。相比于完全的串行执行(16ns),性能提升了约56%。
分级流水线与不完美的资源开销
基于这个指令流水线的思想,我们可以看出通过分级流水线的方式,可以在单位时间内更多更好的利用到资源保证指令的高效执行,所以我们是否可以尝试分更多的等级,加深流水线的深度,让需要指令的指令更早的加入流水线,保证单位时间内可以容纳更多的指令,来提升单核CPU的吞吐量。
假设我们将4个步骤拆分为8个步骤,每个执行0.5ns,带入之前的4条指令的执行步骤为:
- 步骤1执行指令1,其它步骤等待
- 步骤1传递指令1,继续执行指令2,即指令2在1ns时就进入流水线,相比于4个步骤的流水线早了0.5ns

- ......
- 指令1在步骤8执行完成,对应指令4还差1步,即0.5ns
- 全部执行完成大约5.5ns

和多线程上下文切换开销一样,盲目的增加的电路设备散列工作提升流水线并行度始终会因为过多的电路功耗而出现新的性能瓶颈,所以对于流水线深度设计并不是设置越多越好,而是需要通过压测来平衡流水线级数和功耗。
平衡分级下的竞争问题
同时,上述的情况还是理想情况,实际上指令的执行并非是串行独立的,可能指令1执行时需要内存资源,指令2也需要这个内存资源,此时的并行就必须存在一方阻塞等待一方用完才能使用,同理对应的竞争存在:
- 结构冒险:即单位时间内多条指令需要同一个硬件资源
- 数据冒险:单位时间内,后续指令依赖前一条指令结果,例如指令2需要指令1的结果,那么流水线就必须停下让指令1执行完成得到结果后,才让指令2完成后续流水线工作
- 控制冒险:单位时间内,后执行指令依赖前一条指令的执行结果决定下一步的分支
乱序指令cpu指令
乱序执行的设计理念
上文提到的数据冒险和结构冒险都会使CPU电路单元因依赖问题初导致流水线阻塞停顿,导致CPU未能得到充分的利用,于是设计者们就考虑是否存在一种方式可以通过进一步提升CPU利用率从而提升性能表现。

于是就有了乱序执行的设计理念,即没有关联性的指令可以预先执行等待使用,如下代码所示,按照原有的流水线设计,整体运算思路为:
- 代码段2的加法运算依赖于num1生成,所以代码段2需要等待num1执行完成运算并回写
- 代码1完成运算,代码2继续完成指令执行
- 代码段3和代码段4的num1、num2、num3继续按照流水线的顺序执行
ini
//代码段1
int num1 = RandomUtil.randomInt(1000000);
//代码段2依赖于代码段1
int num2 = num1 + RandomUtil.randomInt(1000000);
//num3没有依赖性可以预先执行
int num3 = 0;
//上述数据累加
int result = num1 + num2 + num3;
System.out.println("结果:" + result);在乱序执行的设计思路下,因num3并不存在依赖性问题,我们完全可以在代码段2阻塞期间,即:
- 代码段1执行随机生成
- 代码段2阻塞,代码段3现在流水线顺序执行
- 代码段2在代码段1完成后继续在流水线上执行
- 代码段4进行累加回写
如何实现乱序并发
有了上述的思路,我们就需要思考这样一个问题?如何确定指令间的依赖性?答案是加一层缓存,我们都知道指令执行的顺序为:
- 指令读取
- 指令译码
- alu计算
- 数据回写
查看该指令是否存在依赖,只需在指令译码和alu执行单元之间加一层缓存我们称为保留站,在译码后通过这层缓存记录当前指令是否有依赖的数据?是否依赖硬件且硬件是否忙碌?需要读写的寄存器是哪些?通过这些信息将指令进行归类,执行单元就可以基于这些信息预先执行一些没有依赖性的指令,然后在指令重排序阶段将乱序指令结果重排序输出,从而提升cpu单位时间的吞吐量和利用率:
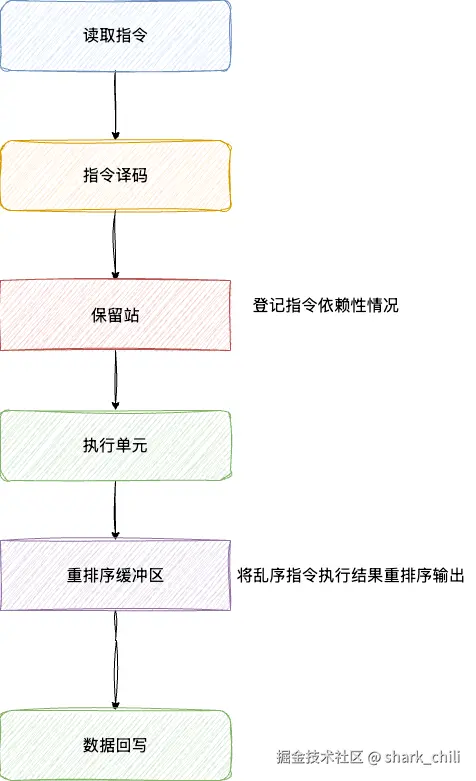
寄存器依赖问题
解决指令乱序执行的依赖性问题,还剩下一个寄存器冲突问题,即多条指令执行时都依赖于一个寄存器导致阻塞停顿怎么办?CPU还是采用了空间换时间的思路,即在内部生产无数寄存器,在指令进入保留站之前预先将其分配映射到内部寄存器中,即执行操作时用到的寄存器都是这些内部寄存器,然后在重排序缓冲区将指令按顺序排列后存到外部寄存器完成数据回写工作,整个过程内部的乱序高效执行,但是对外确是透明让人感觉是顺序执行的一样,由此解决的结构冒险(硬件资源竞争)和数据冒险(后执行的指令依赖于前一条指令的结果)问题,这也就是java并发编程中的as-if-serial思想:

小结
CPU流水线技术是现代处理器设计中的核心优化手段,通过将指令执行过程分解为多个独立的阶段,并允许不同指令在不同阶段并行执行,显著提升了CPU的指令吞吐量。本文从指令串行执行的低效性出发,介绍了流水线设计的基本思想,通过具体的数据计算展示了流水线相比串行执行的巨大性能优势。
同时,我们也了解到流水线设计并非没有代价。随着流水线级数的增加,虽然理论上可以提高性能,但也会带来硬件复杂度增加、功耗上升以及各种冒险问题。因此,CPU设计者需要在流水线深度、硬件资源和性能之间找到平衡点。
在实际应用中,数据冒险、控制冒险和结构冒险是影响流水线性能的主要因素。通过数据前推、分支预测、指令重排序等技术手段,现代CPU能够有效缓解这些问题,最大限度地发挥流水线的性能优势。
理解CPU流水线的工作原理不仅有助于我们编写更高效的代码,也为深入学习计算机体系结构奠定了基础。在今后的学习中,我们还会接触到更复杂的流水线技术,如超标量执行、乱序执行等,它们都是在流水线技术基础上的进一步发展。 你好,我是 SharkChili ,禅与计算机程序设计艺术布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
github.com/shark-ctrl/...
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
参考
《趣话计算机底层技术》
本文使用 markdown.com.cn 排版