1. 论文摘要介绍表格
| 维度 | 内容总结 |
|---|---|
| 核心问题 | 当前视频 MLLM 将视频视为孤立帧,缺乏真正的空间认知、流式处理能力和内部世界模型,难以处理长时程、无界的连续视频流。 |
| 核心概念 | 空间超感知 (Spatial Supersensing):超越语言描述,包含流式事件认知、隐式 3D 空间认知和预测性世界建模的能力。 |
| 基准测试 (Benchmark) | VSI-SUPER : 1. VSR (Recall) :长达数小时的视频中,回忆不寻常物体的出现顺序(防暴力破解)。 2. VSC (Count):跨越场景和视角的持续物体计数(测试流式累积能力)。 |
| 数据贡献 | VSI-590K:包含 59 万个问答对的空间指令微调数据集,源自真实 3D 标注视频、模拟器数据和伪标注的网络视频。 |
| 模型贡献 | Cambrian-S:基于 Qwen2.5 和 SigLIP2 的空间接地视频 MLLM,在 VSI-Bench 上 SOTA。 |
| 范式创新 | 预测性感知 (Predictive Sensing) : 引入自监督的潜帧预测 (LFP) 头。通过计算预测帧与实际帧的差异(惊奇/Surprise)来指导记忆保留和事件分割。 |
| 主要结果 | Cambrian-S 在标准空间基准上大幅领先 (+30%)。利用预测性感知机制后,在 VSI-SUPER 长视频任务上显著优于 Gemini-2.5 等长上下文模型,解决了长视频处理中的记忆和计算瓶颈。 |
2. 论文具体实现流程
1. 输入与基础架构
- 输入:任意长度的视频流(在 VSI-SUPER 中可达数小时)。
- 基础模型 (Cambrian-S) :
- 视觉编码器:SigLIP2-SO400m(冻结,提取视觉特征)。
- 连接器:2层 MLP(将视觉特征映射到语言空间)。
- LLM:Qwen2.5-Instruct(负责推理和生成)。
2. 数据流程 (VSI-590K 构建)
- 来源:整合 S3DIS, ScanNet 等 3D 标注数据 + ProcTHOR 模拟数据 + 网络视频。
- 处理 :
- 对于无标注网络视频:使用 Grounding-DINO 检测物体 -> SAM2 分割 -> VGGT 提取 3D 点 -> 生成伪标注。
- 生成 QA:利用 12 种时空问题模板(如"门离桌子多远?")生成问答对。
3. 训练流程 (4个阶段)
- 视觉-语言对齐:仅训练连接器(2.5M 数据)。
- 图像指令微调:训练连接器和 LLM(Cambrian-7M 数据,AnyRes 策略)。
- 通用视频微调:混合视频和图像数据(3M 数据)。
- 空间视频微调 :使用 VSI-590K + 通用视频数据进行微调,并联合训练 LFP 头。
4. 预测性感知流转逻辑 (核心创新)
这是模型在推理(Inference)阶段处理长视频的逻辑:
- 步骤 A:流式输入
- 视频帧按顺序进入模型(例如 1 FPS)。
- 步骤 B:双路预测
- 主路:LLM 正常处理当前帧特征。
- 辅路 (LFP 头) :基于当前信息,预测下一帧的潜在特征向量。
- 步骤 C:惊奇计算 (Surprise Calculation)
- 当下一帧真实出现时,计算 预测特征 vs. 真实特征 的余弦距离。
- 距离越大 = 惊奇 (Surprise) 越大(说明发生了意想不到的变化,如新场景、怪东西)。
- 步骤 D:记忆与决策
- 若惊奇 > 阈值 :
- 记忆:该帧被视为重要,保留在长期记忆中(或进行较少压缩)。
- 分割 (VSC 任务):判定为新事件/场景的开始,触发阶段性总结(如汇总当前房间的椅子数量),清空短期缓存。
- 若惊奇 < 阈值 :
- 压缩/遗忘:该帧被视为冗余,进行高倍压缩或直接丢弃,不占用宝贵的上下文窗口。
- 若惊奇 > 阈值 :
- 输出:针对用户提问(如"刚才那个泰迪熊在哪出现的?"),从筛选后的高价值记忆中检索信息并生成文本回答。
3. 有趣的白话版解说
标题:AI 终于学会像人类一样"看电影"了------告别金鱼记忆!
今天来聊聊这篇叫做《Cambrian-S》的论文,它试图解决目前 AI 看视频时的一个超级大傻缺问题。
现在的 AI 有什么毛病?
想象一下,你让一个 AI 看一部 2 小时的电影《复仇者联盟》,然后问它:"钢铁侠在第 10 分钟把咖啡杯放哪了?"
现在的顶尖 AI(比如 Gemini 或者 GPT-4o)处理这个问题的方式是:它试图把这 2 小时里的每一帧画面 都死记硬背下来。这就好比一个学生考前复习,不管重点不重点,把整本书每一个字都背下来。
结果呢?
- 脑容量爆炸:视频太长,它记不住了(Context Limit)。
- 变傻:因为记了太多废话,当你问它关键问题时,它反而懵了。
- 不懂空间:它知道画面里有"杯子",但它脑子里没有构建出一个 3D 的房间模型,不知道杯子是在桌子左边还是右边。
这篇论文做了什么牛事?(Cambrian-S)
作者团队(来自 NYU 和斯坦福的大佬们)觉得这样不行。人类看电影不是这么看的。人类是有选择性 的,而且人类会脑补 。
于是他们造了一个新模型 Cambrian-S ,并提出了一个核心概念:预测性感知(Predictive Sensing)。
核心黑科技:这也是能预测的?
这个模型最有趣的地方在于,它在看视频的时候,一直在心里玩一个"猜猜看"的游戏。
- 正常情况:模型看着视频,心里想:"下一秒画面应该还是这个房间吧?"
- 结果:下一秒确实还是这个房间。
- 模型反应 :"切,没劲,猜对了。" -> 低惊奇(Low Surprise) 。
- 处理方式 :这段记忆没用,扔掉或者压缩,别占我脑子。
- 突发情况:突然,画面里出现了一只泰迪熊在洗澡!或者镜头突然切到了室外!
- 模型反应 :"卧槽?!刚才还是卧室,怎么变浴室了?" -> 高惊奇(High Surprise) 。
- 处理方式 :这是重点!记下来!或者把这一段作为一个新故事的开始。
这有什么用?
通过这种"只记让我吃惊的东西 "的策略,Cambrian-S 实现了一个超能力:
它能看无限长的视频!
不管视频是 1 小时还是 10 小时,它只保留那些"惊奇"的瞬间。这样,它的内存永远不会爆,而且因为它记住的都是关键节点(比如场景切换、新物体出现),回答"刚才那个泰迪熊在哪"这种问题时,准确率吊打那些试图死记硬背的商业大模型(比如 Gemini-2.5)。
个人观点与理解 :
这篇论文非常精彩,因为它指出了 AI 进化的下一个方向:从"被动阅读"到"主动建模" 。
以前的 AI 像是一个只会做阅读理解的书呆子;Cambrian-S 则像是一个有常识的观察者。它开始拥有了类似人类的世界模型 ------我知道世界通常长什么样,所以我只关注那些不一样 的东西。
这种**"惊奇驱动(Surprise-driven)"**的学习方式,极其接近人类大脑的工作原理(大脑也是预测引擎)。这不仅仅是让 AI 视频理解变强了,更是让 AI 向真正的"智能生物"迈进了一大步。以后你的家庭机器人可能真的能看懂你家东西都在哪,而不是只会傻傻地盯着摄像头看了。
4. 论文完整翻译
摘要
我们认为,真正的多模态智能的进步要求从反应式的、任务驱动的系统和暴力破解的长上下文,转向更广泛的超感知(supersensing)范式。我们将空间超感知构建为超越单纯语言理解的四个阶段:语义感知 (命名所见之物)、流式事件认知 (在连续体验中保持记忆)、隐式3D空间认知(推断像素背后的世界)以及预测性世界建模 (创建内部模型以过滤和组织信息)。当前的基准测试主要仅测试早期阶段,对空间认知的覆盖范围狭窄,并且很少以需要真正世界建模的方式挑战模型。为了推动空间超感知的进步,我们提出了 VSI-SUPER ,这是一个两部分的基准测试:VSR (长时程视觉空间回忆)和 VSC (持续视觉空间计数)。这些任务需要任意长度的视频输入,且能够抵抗暴力上下文扩展。随后,我们通过整理 VSI-590K 数据集并训练 Cambrian-S 模型来测试数据扩展的极限,在不牺牲通用能力的情况下,在 VSI-Bench 上实现了 +30% 的绝对提升。然而,VSI-SUPER 上的性能仍然有限,表明仅靠规模不足以实现空间超感知。我们提出**预测性感知(predictive sensing)作为前进的道路,并展示了一个概念验证,其中自监督的下一潜帧预测器利用惊奇(surprise,即预测误差)**来驱动记忆和事件分割。在 VSI-SUPER 上,这种方法大幅优于领先的专有基线模型,表明空间超感知要求模型不仅能看,还能预测、选择和组织经验。
- 网站: https://cambrian-mllm.github.io
- 代码: https://github.com/cambrian-mllm/cambrian-s
- Cambrian-S 模型: https://hf.co/collections/nyu-visionx/cambrian-s
- VSI-590K 数据集: https://hf.co/datasets/nyu-visionx/vsi-590k
- VSI-SUPER 基准: https://hf.co/collections/nyu-visionx/vsi-super
1. 引言
视频不仅仅是孤立的帧序列。它是隐藏的、不断演变的 3D 世界在像素上的连续、高带宽投影 46, 90。尽管多模态大语言模型(MLLMs)通过将强大的图像编码器与语言模型配对取得了迅速进步 1, 122, 3, 78, 124,但大多数视频扩展 137, 65, 9 仍然受到根本性的限制。它们仍然将视频视为稀疏的帧,未能充分表现空间结构和动力学 148,并严重依赖文本回忆 168,从而忽略了视频模态独特的强大之处。
在本文中,我们认为要迈向真正的多模态智能,需要从以语言为中心的感知转向空间超感知:不仅能看,还能从连续的感官体验中构建、更新并利用 3D 世界的隐式模型进行预测的能力。我们并不声称在此实现了超感知;相反,我们迈出了第一步,阐明了通往这一方向的发展路径,并展示了沿此路径的早期原型:
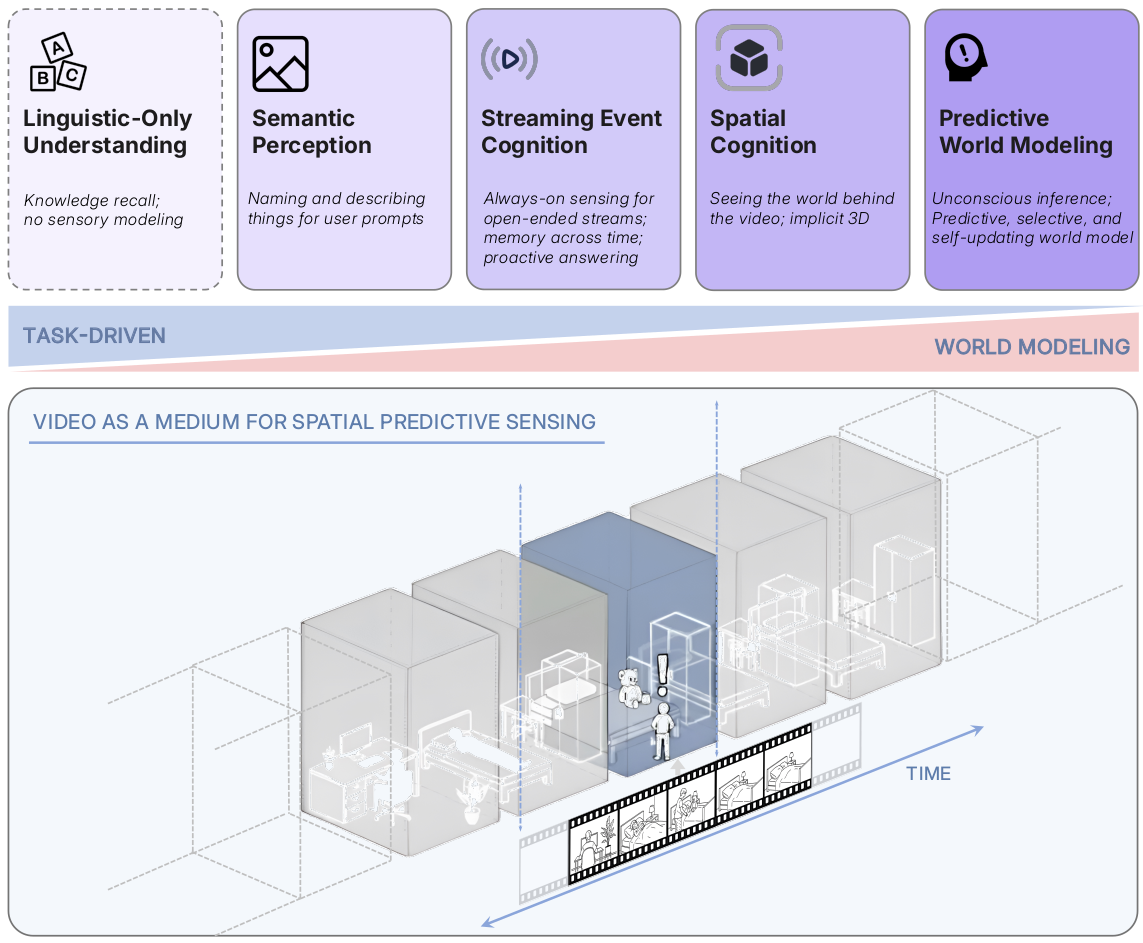
图 1 | 从像素到预测性思维 :我们超越纯语言理解,设想多模态智能能够作为连续、真实世界的一部分进行观看、记忆和推理。它始于语义感知 :命名和描述所见之物。流式事件认知 更进一步,实现对开放式流的时刻在线感知,跨时间整合记忆,并支持主动响应。空间认知 捕捉视频的隐式3D结构,能够推理物体、配置和度量。最后,预测性世界模型涌现,它从经验中被动学习,通过预测和惊奇进行更新,并保留信息以供将来使用。下图说明:视频是理想的实验领域。模型必需从帧级问答进步到构建隐式世界模型,从而实现更深的空间推理,扩展到无界视界,并实现媲美甚至最终超越人类视觉智能的超感知。
- (仅语言理解):无感知能力;推理仅限于文本和符号。当前的 MLLM 已经超越了这个阶段,但仍保留了其偏见的痕迹。
- 语义感知:将像素解析为对象、属性和关系。这对应于 MLLM 中强大的多模态"看图说话"能力。
- 流式事件认知:处理实时、无界的流,同时主动解释和响应正在发生的事件。这与使 MLLM 成为实时助手的努力相一致。
- 隐式 3D 空间认知:将视频理解为 3D 世界的投影。智能体必须知道什么在场、在哪里、事物如何关联以及配置随时间如何变化。今天的视频模型在此方面仍然有限。
- 预测性世界建模 :大脑通过基于先前的期望预测潜在的世界状态来进行无意识推断 130。当这些预测被违反时,惊奇(surprise)会引导注意力、记忆和学习 41, 120, 60。然而,当前的多模态系统缺乏预测未来状态并利用惊奇来组织感知以进行记忆和决策的内部模型。
我们的论文分为三个部分。第一部分 (§ 2) ,我们通过超感知层级的视角重新审视现有的基准。我们发现大多数基准对应于前几个阶段,而一些基准如 VSI-Bench 148 开始探索空间推理。然而,没有一个充分解决了预测性世界建模这一关键的最后阶段。为了具体化这一差距并激发方法的转变,我们引入了 VSI-SUPER (VSI 代表视觉-空间智能),这是一个针对空间超感知的两部分基准:VSI-SUPER Recall (VSR) 针对长时程空间观察和回忆,而 VSI-SUPER Count (VSC) 测试跨越变化视点和场景的持续视觉空间计数。这些任务由任意长的时空视频构建,故意设计成能够抵抗主流的多模态配方;它们要求感知是选择性的 和结构化的,而不是不加区分的累积。我们表明,即使是最好的长上下文商业模型在 VSI-SUPER 上也很吃力。
第二部分 (§ 3) ,我们调查空间超感知是否仅仅是一个数据问题。我们整理了 VSI-590K ,这是一个针对图像和视频的空间聚焦指令微调语料库,我们用它训练了 Cambrian-S,这是一个空间接地的视频 MLLM 家族。在当前范式下,精细的数据设计和训练将 Cambrian-S 推向了 VSI-BENCH 上的最先进空间认知水平(>30% 的绝对增益),而没有牺牲通用能力。然而,Cambrian-S 在 VSI-SUPER 上仍然表现不佳,表明虽然规模奠定了关键基础,但仅靠它不足以实现空间超感知。
这引出了第三部分也是最后一部分 (§ 4) ,我们提出预测性感知 作为迈向新范式的第一步。我们提出了一个基于自监督下一潜帧预测的概念验证解决方案。在这里,我们利用模型的预测误差或"惊奇"来实现两个关键功能:(1)记忆管理 ,通过将资源分配给意外事件;(2)事件分割 ,将无界流分解为有意义的块。我们证明,这种方法虽然简单,但在我们的两个新任务上显著优于强大的长上下文基线(如 Gemini-2.5)。虽然这不是最终解决方案,但该结果提供了令人信服的证据,表明通往真正超感知的路径需要模型不仅能看 ,还能主动预测并从世界中学习。
我们的工作做出了以下贡献:(1) 我们定义了空间超感知的层级,并引入了 VSI-SUPER,这是一个揭示当前范式局限性的超感知基准。(2) 我们开发了 Cambrian-S,这是一种推动空间认知极限的最先进模型。Cambrian-S 作为一个强大的新基线,通过在我们新基准上界定当前方法的边界,为新范式铺平了道路。(3) 我们提出预测性感知作为 MLLM 的一个有前景的新方向,表明利用模型惊奇比被动上下文扩展对长时程空间推理更有效。
2. 基准测试空间超感知
为了立足于我们对空间超感知的追求,我们首先建立如何衡量它。本节对基准测试该能力进行了两部分调查。我们首先审计了一套流行的视频 MLLM 基准,我们的分析(图 3)显示它们绝大多数关注语言理解和语义感知,而忽视了超感知所需的更高级的空间和时间推理(第 2.1 节)。为了填补这一关键空白,我们随后引入了 VSI-SUPER,这是一个专门设计用于探测任意长流式场景中空间智能的更难、持续方面的新基准(第 2.2 节)。我们在论文的其余部分使用此基准来测试当前 MLLM 范式的极限。
2.1. 解构现有的视频基准
MLLM 的最新进展导致了 Video-QA 基准的激增。然而,一个关键问题仍然存在:现有的视频基准在多大程度上真正检查了视觉感知能力,而不是简单地测试语言先验? 我们的诊断测试通过改变视觉输入的丰富度和文本线索的信息量,解开了模型对视觉感知与语言先验的依赖。仅通过纯文本输入(例如字幕或盲 MLLM)即可解决的基准偏向于检查语言理解。相反,只有通过多帧输入才能回答的基准问题需要真正的视觉感知。我们使用基于图像的多模态大语言模型 Cambrian-1 124 进行评估,这使我们能够探测潜在的任务需求,而不会将其与视频特定架构和后训练配方的能力混淆。
我们建立了几个向 Cambrian-1 124 模型输入视频的实验条件:
- 多帧 (Multiple Frames):模型处理从视频剪辑中均匀采样的 32 帧。这是文献中表示视频输入的标准方法 65。
- 单帧 (Single Frame):模型仅处理给定视频剪辑的中间帧。此条件测试对最小的、上下文中心的视觉信息的依赖。
- 帧字幕 (Frame Captions):模型接收对应于相同 32 个均匀采样帧的字幕,而不是视频帧。此条件旨在揭示如果没有低级感知接地,任务的可解决性如何。我们使用 Gemini-2.0-Flash API 重新为视频帧生成字幕。
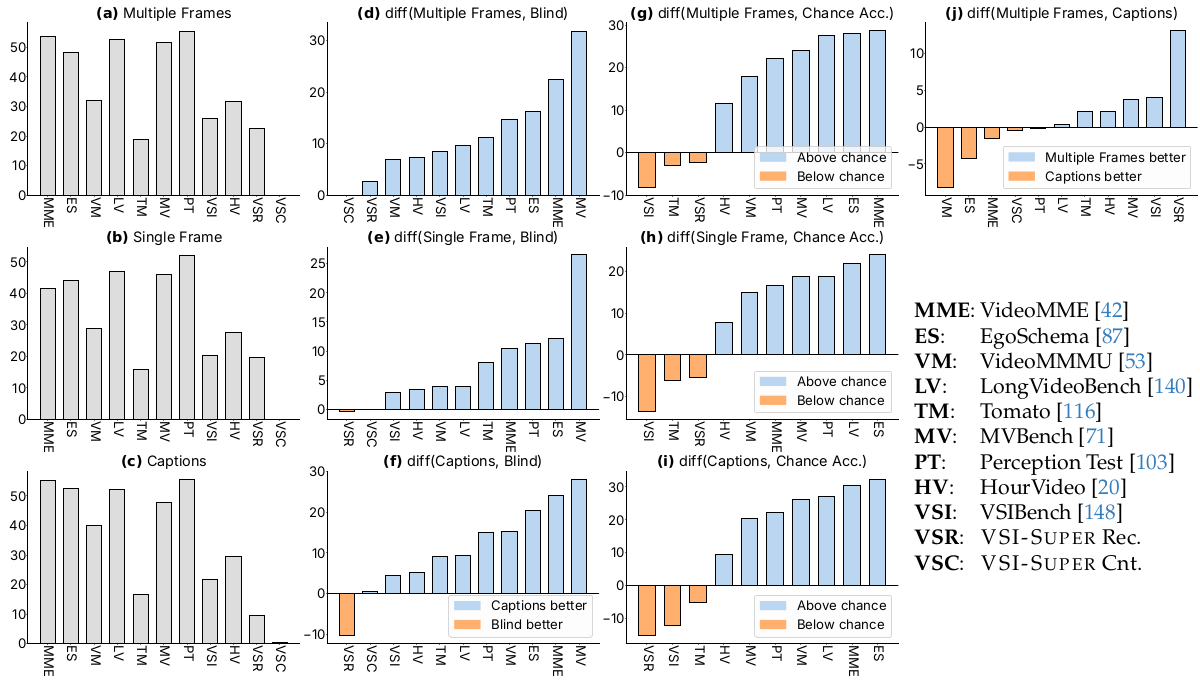
图 2 | 基准诊断结果揭示了对视觉输入的不同依赖性 :我们在不同输入条件下评估模型:(a) 多帧(32帧),(b) 单帧,© 帧字幕,并与随机猜测水平和盲测结果(忽略视觉输入)进行对比。(a-c) 面板显示绝对准确率;(d-j) 面板显示条件之间的性能差异。对于 VSI-Bench、Tomato 和 HourVideo,视觉输入至关重要,而对于 VideoMME、MVBench 和 VideoMMMU,其影响较小。VSR 和 VSC 是第 2.2 节介绍的新超感知基准。
为了将这些条件下的表现情境化,我们引入了另外两个基准:
- 盲测 (Blind Test) :模型仅使用任务的问题尝试任务。忽略所有视觉输入,不使用视觉字幕。此基线衡量基于模型预先存在的知识、语言先验以及基准问题中任何潜在偏见的表现。
- 随机准确率 (Chance Acc):这代表通过随机猜测特定任务格式(例如多项选择题)可达到的准确率,作为性能的底线。
我们通过比较这些条件和基线之间的性能,对每个基准的特征进行了细粒度分析。我们关注以下关键比较 (diff(A,B) = A-B):
diff(x, Blind),其中x ∈ {Multiple, Single, Captions},用于量化不同输入模态相对于盲基线的提升;diff(x, Chance),其中x ∈ {Multiple, Single, Captions},用于衡量相对于随机猜测的性能增益;diff(Multiple, Captions),用于理解当前主流做法与强语言基线之间的性能差距。
图 2 (a-c) 呈现的结果表明,Cambrian-1 124,一个没有任何视频后训练的基于图像的 MLLM,可以在许多基准上获得合理的性能,在某些情况下超过随机水平准确率 10-30%(见图 2-g,h)。这表明这些基准目标的大部分知识可以通过标准的单图指令微调流程获得。然而,在两个现有的数据集 VSI-Bench 148 和 Tomato 116 上,模型的性能低于随机水平。对于 VSI-Bench,这主要是因为其空间理解问题需要真正的视频感知以及针对性的数据整理和训练。对于 Tomato,这种表现不佳是预期的:该基准要求理解高帧率视频的细粒度细节,使得时间上大幅下采样的单帧和 32 帧输入显得不足。
使用文本字幕 代替视觉输入也产生了显著的性能提升,在 EgoSchema 87、VideoMME 42、LongVideoBench 140、VideoMMMU 53、Perception Test 103 和 MVBench 71 等基准上超过随机准确率 20% 以上(图 2-i)。将基准性能与盲测 结果进行比较时也可以得出类似的结论(图 2-d,f)。这种表现意味着这些基准主要探测可从视频内容的文本摘要推断出的能力。解释"多帧"和"帧字幕"之间的性能差异(图 2-j),显著的正向差距(有利于多帧输入)标志着基准对细微视觉感知的需求。相反,小或负的差距(更有利于"帧字幕")表明更以语言为中心的性质。我们的分析将 VideoMMMU、EgoSchema、VideoMME、Perception Test 和 LongVideoBench 归入后一类,表明它们潜在地依赖于语言理解而不是视觉线索。VSC 是一个显著的例外,它对当前的 MLLM 极具挑战性,以至于所有三种输入条件都产生接近零的性能,使得它们之间无法进行任何有意义的比较。
💡 现有的基准压倒性地关注语言理解和语义感知,而忽视了超感知所需的更高级的空间和时间推理。
我们希望强调基准测试的内在挑战以及创建一个单一的、包罗万象的基准来评估每种能力的不切实际性。例如,依赖语言先验不应仅被视为缺点,因为在许多情况下,访问丰富的世界知识及其有效检索无疑是有益的。我们认为,视频基准不应被视为衡量"视频理解"这一单一、统一概念的标准。相反,它们的设计和评估应基于它们旨在评估的具体能力。 因此,前面的分析旨在指导开发能更有效地推动向空间超感知进展的任务,这将是本文其余部分的重点。
2.2. VSI-SUPER:迈向多模态 LLM 中的空间超感知基准测试
参考图 1,空间超感知要求 MLLM 具备四种关键能力:语义感知、流式事件认知、隐式 3D 空间认知和预测性世界建模。然而,正如我们在图 2 中的分析所概述的,大多数现有的视频 QA 基准主要评估语言理解和语义感知方面,这些方面更具反应性并由特定任务驱动 42, 87, 53。虽然最近的研究已经开始通过持续感知、记忆架构和主动回答来解决流式事件认知 24, 104, 97, 139, 119, 159,但这种能力通常是在测试时工程化的,而不是原生模型技能。此外,尽管空间推理偶尔作为现有基准中的一个类别出现,但这些任务很少达到真正的空间认知水平,并且远未探测定义超感知的世界建模能力(图 3)。虽然 VSI-Bench 148 在检查空间认知方面迈出了初步一步,但其视频仍然是短格式和单场景的,并且它既没有形式化该问题,也没有评估预测性世界建模这一基本能力。

图 3 | 当前视频基准中空间感知概念化的插图 :左侧展示了 VideoMME 42 中"空间推理"子类别的示例,包括关于重力和宇航员装备的问题。相比之下,右侧展示了 VSI-Bench 148 的样本,突出了视觉-空间推理任务,如物体计数、识别相对方向、路线规划等。
为了阐明当前 MLLM 与空间超感知之间的差距,我们引入了 VSI-SUPER ,这是一个针对持续空间感知的两部分基准。这些任务直观且对人类来说通常很容易,人们只需观看并跟踪发生的事情,但它们对机器来说仍然具有惊人的挑战性。它们要求选择性过滤和结构化积累无界空间视频中的视觉信息,以维持连贯的理解并回答问题。重要的是,它们能够抵抗暴力上下文扩展,暴露了对真正空间推理的需求。

图 4 | VSR 基准构建过程和格式的插图
VSI-SUPER Recall (VSR):长时程空间观察与回忆。VSR 基准要求 MLLM 观察长时程时空视频,并按顺序回忆不寻常物体的位置。如图 4 所示,为了构建此基准,人工标注者使用图像编辑模型(即 Gemini 30)将令人惊讶或格格不入的物体(例如泰迪熊)插入视频的四个不同帧(和空间位置)中,该视频捕捉了室内环境的漫游 33, 153, 12。然后将此编辑过的视频与其他类似的房间游览视频连接起来,创建一个任意长且连续的视觉流。此任务类似于语言领域中常用的"大海捞针"(NIAH)测试,用于压力测试 LLM 的长上下文能力 79。类似的 NIAH 设置也被提议用于长视频评估 162, 138, 54。然而,与插入不相关的文本段或帧的基准不同,VSR 通过帧内编辑保留了"针"的真实性。它通过要求顺序回忆进一步扩展了挑战,这实际上是一个多跳推理任务,并且在视频长度上保持任意可扩展。为了彻底评估模型在不同时间尺度上的性能,该基准提供了五种时长:10、30、60、120 和 240 分钟。
VSI-SUPER Count (VSC):变化视点和场景下的持续计数 。在这里,我们测试 MLLM 在长格式空间视频中持续积累信息的能力。为了构建 VSC,我们连接了来自 VSI-Bench 148 的多个房间游览视频片段,并任务模型统计所有房间中目标物体的总数(见图 5)。这种设置具有挑战性,因为模型必须处理视点转换、重复目击和场景转换,同时保持一致的累计计数。对于人类来说,计数是一个直观且可概括的过程。一旦理解了"一"的概念,将其扩展到更大的数量是很自然的。相比之下,正如我们稍后证明的那样,当前的 MLLM 缺乏真正的空间认知,并且过度依赖统计模式。
除了标准评估(即在视频结束时提问)外,我们还在多个时间戳查询模型,以评估其在流式设置中的性能,其中 VSC 中的正确答案随时间动态演变。为了检查长期一致性,VSC 包括四种视频时长:10、30、60 和 120 分钟。对于此定量任务,我们使用平均相对准确度 (MRA) 指标报告结果,与 VSI-Bench 评估协议 148 一致。

图 5 | VSC 基准概述
最先进的模型在 VSI-SUPER 上陷入困境。为了测试 VSI-SUPER 是否对前沿 MLLM 构成真正的挑战,我们评估了最新的 Gemini-2.5-Flash 122。如表 1 所示,尽管拥有 1,048,576 个 token 的上下文长度,该模型在处理两小时视频时仍达到其上下文限制。这突出了视频理解的开放式性质,其中连续流实际上需要"无限输入,无限输出"的上下文,并且可以任意增长,这表明仅仅扩展 token、上下文长度或模型大小可能是不够的。虽然是合成的,但我们的基准反映了空间超感知中的一个真实挑战:人类毫不费力地整合并保留从数小时或数年展开的持续感官体验中获得的信息,而目前的模型缺乏类似的可持续感知和记忆机制。Gemini-2.5-Flash 在关注语义感知和语言理解的视频基准(如 VideoMME 42 和 VideoMMMU 53)上表现出强大的性能,达到了约 80% 的准确率。然而,即使对于完全在其上下文窗口内的 VSI-SUPER 中的 60 分钟视频,VSR 和 VSC 上的性能仍然有限------分别为 41.5 和 10.9。如图 6 所示,该模型的预测对象计数未能随视频长度或真实物体数量扩展,而是在一个小的恒定值处饱和,表明计数能力缺乏泛化性且依赖于训练分布先验。
表 1 | Gemini-2.5-Flash 结果

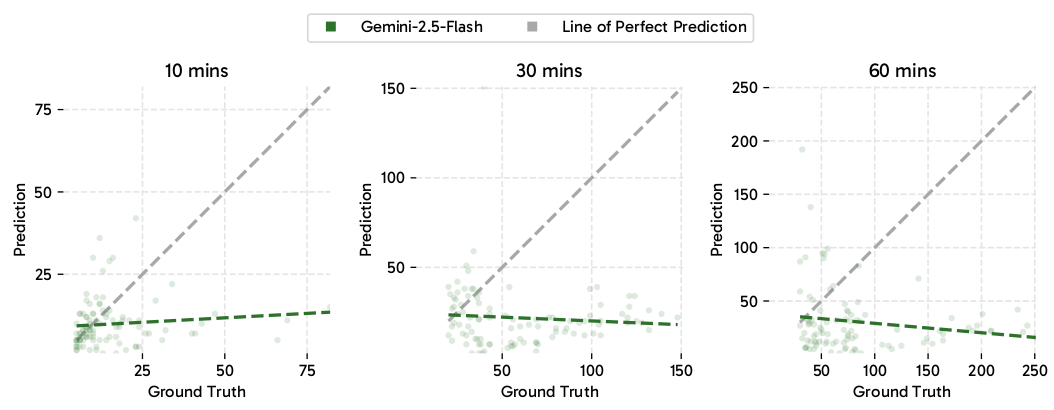
图 6 | Gemini-2.5-Flash 预测 vs. VSC 上的真实值可视化
VSI-SUPER 如何挑战当前范式。虽然任务设置很简单,但 VSI-SUPER 构成的挑战超越了单纯的空间推理,并揭示了当前 MLLM 范式的基本局限性。
💡 VSI-SUPER 任务挑战了仅靠规模就能保证进步的信念。
通过允许任意长的视频输入来模拟流式认知的动态,VSI-SUPER 被故意构建为超过任何固定的上下文窗口。这种设计表明,逐帧标记化和处理作为长期解决方案在计算上不太可能可行。人类通过选择性地关注并仅保留一小部分感官输入(通常是无意识的)来高效且适应性地解决此类问题 40, 130。这种预测和选择机制是人类认知的核心,但在当前的 MLLM 中仍然缺失,但对于预测性世界模型至关重要。
💡 VSI-SUPER 任务要求在测试时泛化到新的时间和空间尺度。
例如,VSC 要求在任意长的视频中计数,类似于理解计数概念的人类可以将其扩展到任何数字。关键不在于维持极长的上下文窗口(人类并不保留扩展视觉体验中的每一个视觉细节),而在于学习计数过程本身。预测性感知通过将连续的视觉流分割成连贯的事件来促进这一点,利用"惊奇"时刻来施加时间结构。这种分割充当分而治之的机制,允许模型决定何时开始、继续或重置动态变化场景中的行为。
这些挑战跨越计算效率、泛化以及诸如无意识推断和预测性感知等认知机制,呼吁范式转变。未来的模型不应仅仅依赖于扩展数据、参数或上下文长度,而应学习能够感知并预测跨时空无尽展开的视觉世界的内部世界模型。
3. 当前范式下的空间感知 (Spatial Sensing Under the Current Paradigm)
正如上一节所展示的,Gemini-2.5-Flash 在空间感知任务上的表现并不理想(见表 1)。这一观察引出了一个关键问题:有限的空间感知仅仅是一个数据问题吗? 这是一个值得提出的问题,因为当前的视频 MLLM 在训练期间并没有明确优先考虑以空间为重点的视频,而且现有的预训练和后训练设计是否非常适合我们的目标任务仍未可知。我们首先通过一系列架构和训练改进来增强 Cambrian-1 124,以建立更强大的图像 MLLM 作为我们的基础模型(第 3.1 节)。接着,我们构建了一个大规模的、以空间为重点的指令微调数据集 VSI-590K(第 3.2 节)。该数据集由不同来源整理并经过仔细标注。由于目前公开领域不存在此类数据,VSI-590K 旨在为空间感知提供坚实的数据基础。最后,通过改进的训练配方(第 3.3 节),我们介绍了空间接地的 Cambrian-S 模型系列(第 3.4 节)。
Cambrian-S 模型系列在既定的空间推理基准(如 VSI-Bench 148)上表现出强大的性能,并为空间超感知的基础模型设计、数据整理和训练策略提供了宝贵的见解。然而,尽管取得了这些进展,这种方法并不能直接解决 VSI-SUPER 的持续感知挑战(第 3.5 节);相反,它提供了一个关键的基础,激发了我们在第 4 节中介绍的新范式。
3.1. 基础模型训练:升级版 Cambrian-1 (Base Model Training: Upgraded Cambrian-1)
我们首先开发一个基于图像的 MLLM 基础模型,因为强大的语义感知构成了更高级别空间认知的基础。我们遵循 Cambrian-1 124 的两阶段训练流程。我们将视觉编码器升级为 SigLIP2-SO400m 128,将语言模型升级为经过指令微调的 Qwen2.5 145。对于视觉-语言连接器,我们主要出于计算效率的考虑,采用了一个简单的双层 MLP。Cambrian-1 的其他训练组件,包括超参数和数据配方,保持不变。完整的实施细节在附录 D 中提供。
3.2. 空间视频数据整理:VSI-590K (Spatial Video Data Curation: VSI-590K)
众所周知,数据质量和多样性在 MLLM 的训练中起着至关重要的作用 124, 93。我们假设 VSI-Bench 148 上的性能差距主要来自当前指令微调数据集中缺乏高质量、空间接地的数据 161, 32。为了填补这一空白,我们构建了 VSI-590K,这是一个旨在提高视觉-空间理解的大规模指令微调数据集。
表2
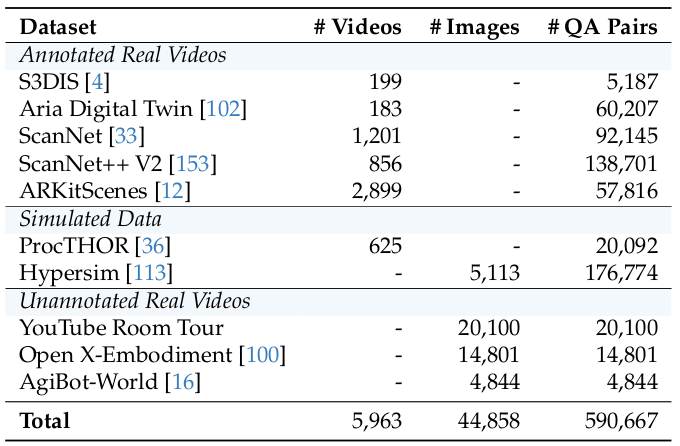
数据整理和处理。我们从多种数据源和类型(即模拟和真实)构建 VSI-590K。数据源及视频数量、图像数量和 QA 对的数据集统计信息见表 2。我们发现,这样产生的数据集比仅从单一来源得出的同等规模的数据集要稳健得多。下面,我们详细介绍数据处理过程。
- 带标注的真实视频 (Annotated real videos):多模态视觉-空间推理依赖于对 3D 几何和空间关系的扎实理解。遵循 VSI-Bench,我们重新利用了现有室内扫描和第一人称视频数据集的训练集,这些数据集提供了 3D 实例级标注,包括 S3DIS 4、ScanNet 33、ScanNet++ V2 153、ARKitScenes 12 和 ADT 102。对于每个数据集,标注被整合到一个元信息文件中,捕获场景级属性,如按类别分类的物体计数、物体边界框、房间尺寸和相关元数据。然后自动实例化问题模板以生成相应的问题。
- 模拟数据 (Simulated data):由于 3D 标注数据的可用性有限,仅从真实标注视频构建大规模且多样化的 3D 标注 SFT 数据集具有挑战性。遵循 SIMS-V 13,我们利用具身模拟器程序化地生成空间接地的视频轨迹和 QA 对,在 ProcTHOR 36 场景中渲染了 625 个视频遍历,具有不同的布局、物体配置和视觉外观。我们对 Hypersim 113 应用了相同的方法,从 461 个室内场景中采样了 5,113 张图像。利用实例级边界框,我们生成了与我们标注的真实视频设置一致的问答对。
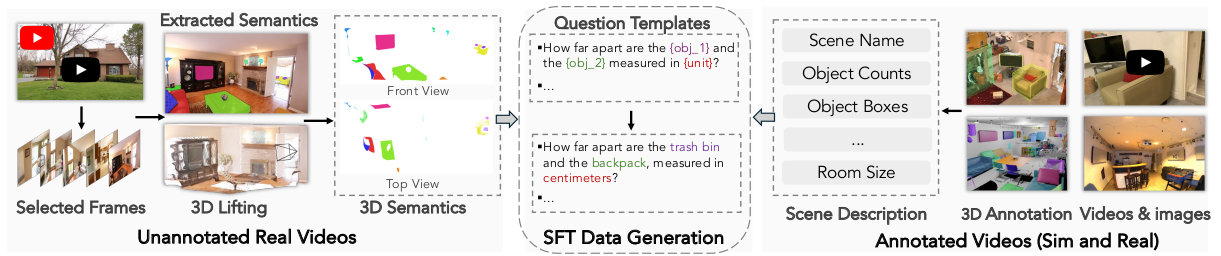
- 无标注真实视频 (Unannotated real videos):虽然网络来源的视频缺乏显式标注,但它们在室内环境类型、地理区域和空间布局方面提供了丰富的多样性。我们收集了大约 19K 个来自 YouTube 的房间游览视频,并额外整合了来自机器人学习数据集的视频,包括 Open-X-Embodiment 100 和 AgiBot-World 16。由于这些视频不包含构建空间指令微调数据所需的 3D 标注,我们开发了一个伪标注流程。如图 7 所示,我们对视频帧进行二次采样和过滤,应用物体检测 80、分割模型 109 和 3D 重建模型 133,以此遵循 SpatialVLM 21 的方法生成伪标注图像。我们选择在图像级别而不是整个视频上生成标注,因为从识别和重建模型得出的全视频伪标注往往噪音太大,不适合训练。
问题类型定义和模板增强 。我们在时空分类法中定义了 12 种问题类型,以构建全面且多样化的指令微调问题集。我们定义了五种主要问题类型------大小 (size)、方向 (direction)、计数 (count)、距离 (distance) 和出现顺序 (appearance order) ------广泛归类为测量配置 (measuring configuration)、测量 (measurement) 或时空能力 (spatiotemporal capabilities),遵循 148。除出现顺序类型外,每个问题类别都包括相对 (relative) 和绝对 (absolute) 变体,反映了这些互补推理形式在视觉-空间理解中的重要性 148。例如,对于大小,我们会询问两个物体之间的大小比较(相对)以及物体的度量尺寸(绝对)。为了增加多样性,我们改变了制定方向和距离问题时使用的视角。例如,距离问题可能会询问哪个物体更靠近相机,或者哪个物体更靠近第三个参考物体。我们还通过问题措辞的变化和测量单位(例如,米与英尺)的变化来使数据集多样化。数据集的更多细节在附录 C 中提供。
表3
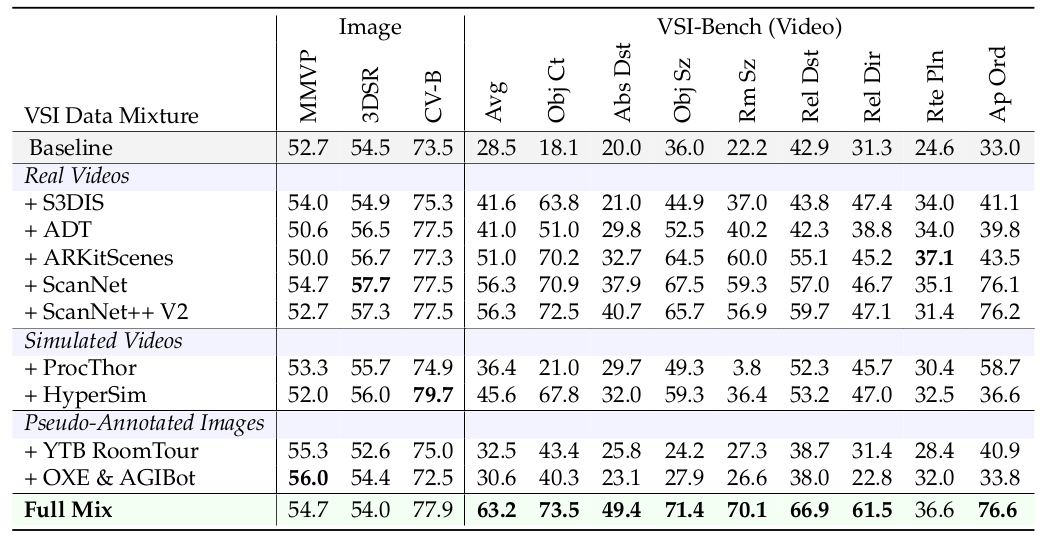
VSI-590K 数据源消融 。为了评估我们提出的 VSI-590K 数据集的有效性,我们通过微调第 3.1 节中描述的改进版 Cambrian-1 MLLM 进行了消融研究,使用了 LLaVA-Video-178K 161 中的一部分视频指令微调样本。该模型作为表 3 中的基线。通过在单个数据集以及它们的组合上微调模型来评估每个数据源的贡献。VSI-590K Full Mix(全混合)在视频空间推理任务上实现了最高的整体性能,优于基线和所有单一来源的对应物。所有数据源在微调后都做出了积极贡献,尽管它们的有效性各不相同。
💡 数据有效性排名为:标注的真实视频 > 模拟数据 > 伪标注图像。
这表明,对于空间推理,视频本质上比静态图像包含更多的信息,因为仅在视频数据上训练在视频和基于图像的空间推理基准上都产生了优越的性能。这些发现支持了这样一种直觉,即视频的时间连续性和多视角多样性是开发稳健空间表征的关键。
3.3. 空间感知的后训练配方 (Post-Training Recipe for Spatial Sensing)
表4
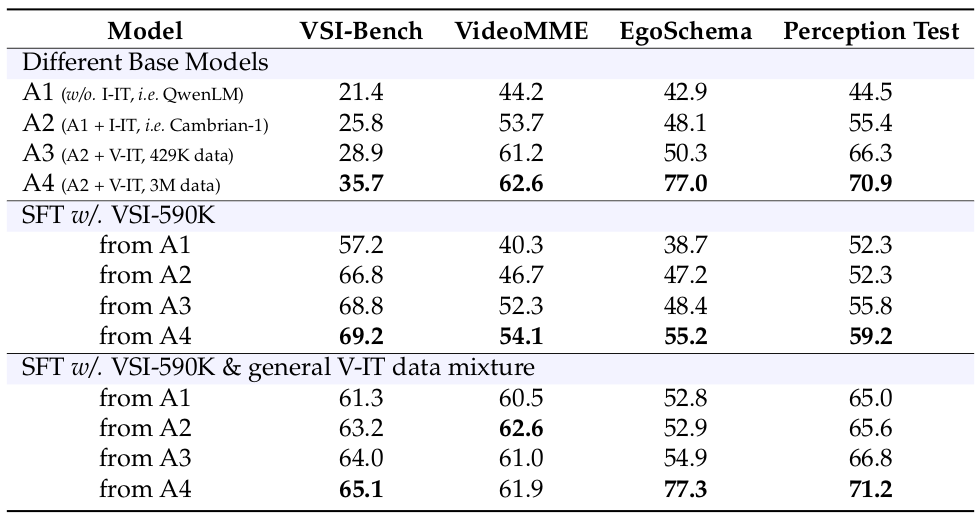
我们进一步分析和消融了我们的视频指令微调流程,重点关注预训练基础视频模型的作用和指令微调数据集的混合。如表 4 所示,我们要从四个基础模型开始,它们代表了视频理解能力的逐步提升:
- A1 仅在 Cambrian-1 对齐数据上训练图像-文本对齐。语言模型与 QwenLM 相同,因为在训练期间被冻结。
- A2 在 A1 之上微调图像指令,本质上是我们改进的 Cambrian-1。
- A3 从 A2 初始化,并在 429K 视频指令微调数据上进行微调。
- A4 从 A2 初始化,并在 3M 视频指令微调数据上进行微调。
然后,我们使用两种不同的数据配方微调这些模型:(1) 仅 VSI-590K,和 (2) VSI-590K 混合类似数量的通用视频指令微调数据。
💡 拥有更多通用视频数据暴露的更强基础模型会导致 SFT 后空间感知的提升。
如表 4 所示,使用更强的基础模型(即在 VideoMME 42 和 EgoSchema 87 等通用视频基准上表现良好的模型)进行 SFT,可以增强空间理解。这突出了在基础模型训练期间广泛接触通用视频数据的重要性。
💡 混合通用视频数据可以防止因域内 SFT 造成的泛化损失。
此外,虽然仅在 VSI-590K 上进行域内 SFT 在 VSI-Bench 上实现了最高性能,但这导致在通用视频基准上的性能显着下降。然而,通过在包含通用视频的数据混合上进行训练,可以有效地减轻这种性能下降。
3.4. Cambrian-S:空间接地的多模态大语言模型 (Cambrian-S: Spatially-Grounded MLLMs)
基于所有先前的见解,我们开发了 Cambrian-S ,这是一个空间接地的模型家族,具有不同的 LLM 规模:0.5B、1.5B、3B 和 7B 参数。这些模型通过专门设计的四阶段训练流程构建,首先建立通用的语义感知,然后开发专门的空间感知技能,如图 8 所示。

前两个阶段遵循 Cambrian-1 框架来开发强大的图像理解能力。在第 3 阶段,我们将模型扩展到视频,通过在 CambrianS-3M(一个由 300 万样本组成的精选数据集,详细构成见图 16)上进行通用视频指令微调。这一阶段在引入专门技能之前建立了坚实的通用视频理解基础。在最后也是至关重要的第 4 阶段,我们针对空间感知训练模型。在这里,我们遵循表 4 中描述的设置,在结合了我们专门的 VSI-590K 与第 3 阶段使用的通用视频数据的成比例子集的混合语料库上微调模型。完整的训练细节在附录 D.3 中提供。
3.5. 实证结果:改进的空间认知 (Empirical Results: Improved Spatial Cognition)
接下来,我们评估 Cambrian-S 多模态模型,以评估我们的数据驱动方法的优势和局限性。
表5
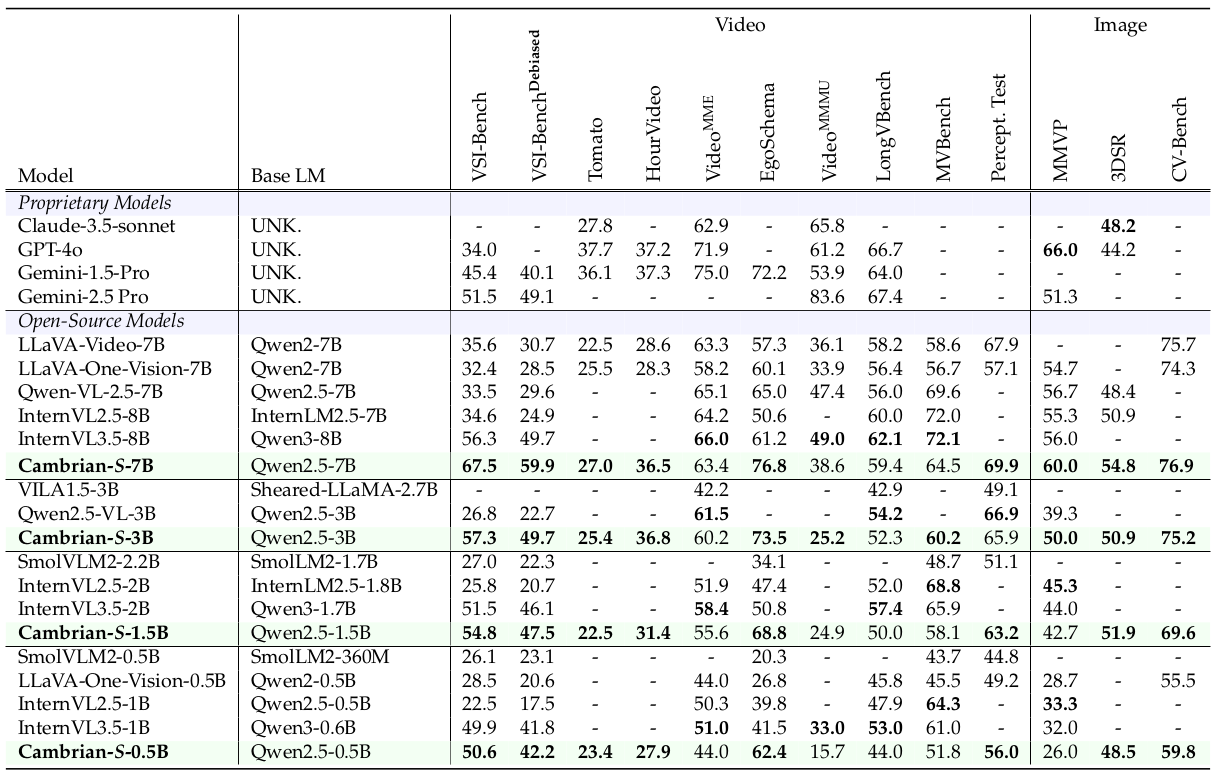
改进的空间认知 。如表 5 所示,我们的模型在视频中的视觉-空间理解方面达到了最先进的性能。Cambrian-S-7B 在 VSI-Bench 上达到了 67.5%,显着优于所有开源模型,并在绝对点数上超过专有的 Gemini-2.5-Pro 16 个点以上。由于本节中的工作可以被视为数据扩展的努力,一个自然的问题是:性能的提升仅仅是由于更广泛的数据覆盖(包括更多样化的视觉配置和问答对),还是模型实际上发展了更强的空间认知? 首先,我们强调 VSI-590K 和基准数据集之间没有数据重叠。虽然有些数据集来自相同的来源(例如 ScanNet),但我们只使用训练集,而基准使用验证集和测试集。此外,我们在空间推理中观察到明显的泛化迹象。例如,在具有挑战性的"路线规划"子任务中(由于高昂的标注成本,其问题类型在 VSI-590K 中缺失),Cambrian-S-7B 仍然表现强劲,且随着模型规模的增加显示出明显的扩展行为(见表 6)。
表6
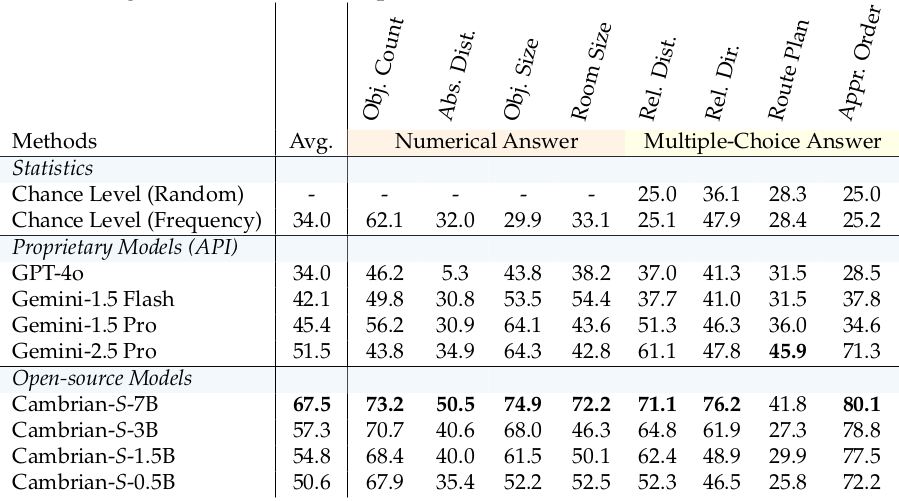
此外,我们的训练方法证明即使在较小的模型尺寸下也非常有效:我们最小的 0.5B 模型在 VSI-Bench 上的表现与 Gemini-1.5 Pro 相当。重要的是,这种对空间推理的强调并没有以牺牲通用能力为代价:Cambrian-S 在诸如 Perception Test 103 和 EgoSchema 87 等标准视频基准上继续提供有竞争力的结果(完整结果见表 14)。
💡 Cambrian-S 在实现最先进的空间感知性能的同时,对未见过的空间问题类型具有强大的泛化能力,同时在通用视频理解方面保持竞争力。
VSI-Bench-Debiased 上的稳健空间推理。最近的一项研究 14 揭示,模型在空间推理任务上可能依赖于强大的语言先验。例如,当被要求估计桌子的长度时,模型可能会利用关于典型桌子尺寸(例如 120-180 厘米)的自然世界知识,而不是分析视觉证据。为了调查 Cambrian-S 是否学会了视觉推理,我们在 VSI-Bench-Debiased 14 上对其进行评估,这是一个专门设计用于通过去偏来消除语言捷径的基准。如表 5 所示,尽管与标准 VSI-Bench 相比性能下降了约 8%,但我们的模型仍然优于专有模型,展示了稳健的视觉-空间推理能力,并证实我们的训练扩展到了基于语言的学习之外。
VSI-SUPER 上的结果:持续空间感知的局限性 。尽管在 VSI-Bench 的短预分割视频上表现出色,但 Cambrian-S 并不具备持续空间感知的能力。这种局限性体现在两个方面。首先,它在长视频上的性能显着恶化。如表 7 所示,当在流式风格设置下以 1 FPS 采样在 VSI-SUPER 上进行评估时,随着视频长度从 10 分钟增加到 60 分钟,得分从 38.3% 稳步下降到 6.0%,并且模型在长于 60 分钟的视频上完全失败。其次,模型难以泛化到新的测试场景。虽然在多房间房屋游览视频上进行了训练,但它无法处理仅包含几个额外房间的未见过示例。这个问题不仅仅是关于上下文长度:即使在舒适地适合模型上下文窗口的短 10 分钟视频上,性能也会下降。这些结果强调,当前 MLLM 框架内纯粹的数据驱动方法,无论投入多少数据或工程努力,都面临根本性的限制。解决这些限制需要向能够主动建模和预测世界的人工智能系统转变,同时更有效地组织它们的经验,我们将在接下来进行探讨。
表7

💡 扩展数据和模型是必不可少的,但仅靠它无法解锁真正的空间超感知。
4. 作为新范式的预测性感知 (Predictive Sensing as a New Paradigm)
Gemini-2.5-Flash(表 1)和 Cambrian-S(表 7)在 VSI-SUPER 上的性能急剧下降揭示了一个基本的范式差距:仅靠扩展数据和上下文不足以实现超感知。我们提出预测性感知 (predictive sensing) 作为前进的道路,其中模型学习预测其感官输入并构建内部世界模型以处理无界视觉流。这种设计受到人类认知理论的启发。与当前对整个数据流进行标记化和处理的视频多模态模型不同,人类感知(和记忆)具有高度选择性,仅保留一小部分感官输入 130, 95, 52, 108。大脑不断更新内部模型以预测传入的刺激,压缩或丢弃不提供新信息的可预测输入 29, 41。相反,违反预测的意外感官信息会产生"惊奇 (surprise)"并驱动增加的注意力和记忆编码 115, 45, 60。我们通过自监督的下一潜帧预测方法(第 4.1 节)对这一概念进行原型设计。产生的预测误差作为两个关键能力的控制信号:记忆管理 以选择性保留重要信息(第 4.2 节),以及事件分割以将无界流划分为有意义的块(第 4.3 节)。我们在 VSI-SUPER 上的两个案例研究中证明,这种方法大幅优于强大的长上下文和流式视频模型基线。
4.1. 通过潜帧预测实现的预测性感知 (Predictive Sensing via Latent Frame Prediction)
我们通过一个称为潜帧预测 (LFP) 头的轻量级自监督模块来实现我们的预测性感知范式,该模块与主要的指令微调目标联合训练。这是通过修改第 4 阶段的训练配方来实现的,如下所示:
-
潜帧预测头 (Latent frame prediction head) :我们引入一个 LFP 头,这是一个双层 MLP,与语言头并行运行,以预测后续视频帧的潜在表示。该架构在图 9 的左上角说明。
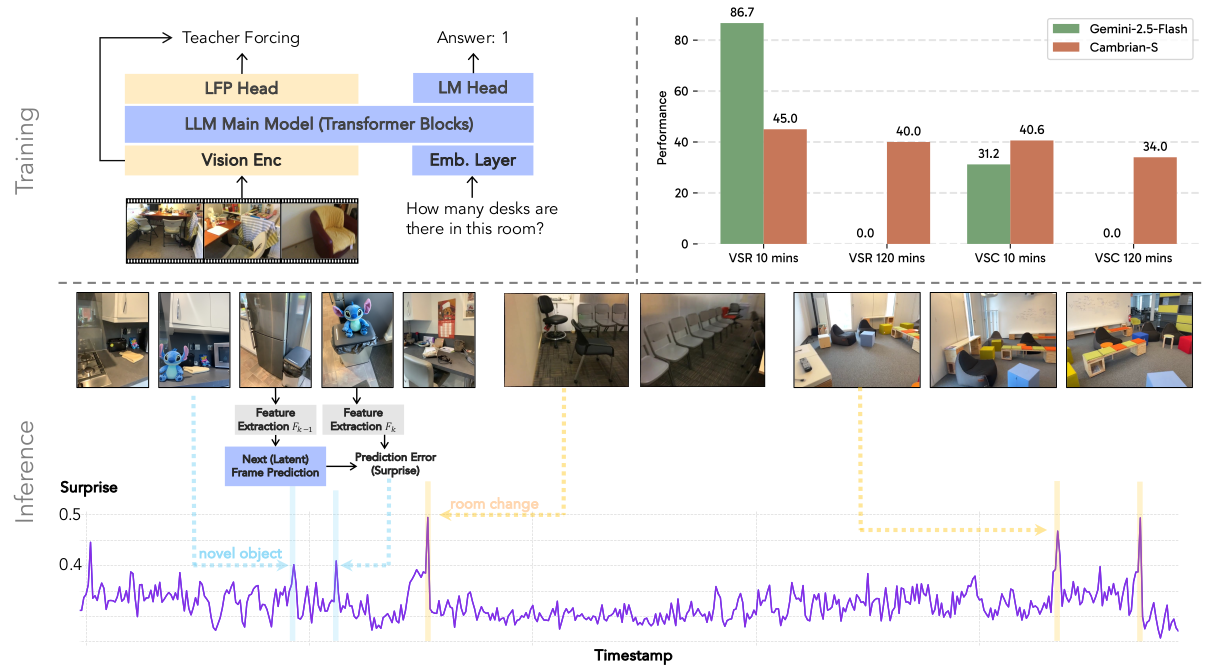
图9 -
学习目标 (Learning objectives):为了优化 LFP 头,我们引入了两个辅助损失:均方误差 (MSE) 和余弦距离 (cosine distance),它们测量预测的潜在特征与下一帧的真实特征之间的差异。一个加权系数平衡 LFP 损失与主要的指令微调下一词预测目标。
-
LFP 训练数据 (Data for LFP training):我们用来自 VSI-590K 的 290K 视频子集增强第 4 阶段的数据,该子集专门用于 LFP 目标。与指令微调不同,这些视频以 1 FPS 的恒定速率采样,以确保潜帧预测的均匀时间间隔。
在这个修改后的第 4 阶段微调期间,我们以端到端的方式联合训练连接器、语言模型以及语言头和 LFP 头,同时保持 SigLIP 视觉编码器冻结。所有其他训练设置与原始第 4 阶段配置保持一致。为简洁起见,在随后的实验中,我们仍将通过 LFP 目标联合优化的模型表示为 Cambrian-S。
推理:通过预测误差估计惊奇 。在推理过程中,我们利用训练好的 LFP 头来评估每个传入视觉感官输入的"惊奇"。在心理学中,这个框架通常被描述为违反期望 (VoE) 范式 17。具体来说,在推理期间,视频帧以恒定的采样率输入 Cambrian-S。除非另有说明,否则以下实验中的视频在输入模型之前均以 1 FPS 进行采样。当模型接收传入的视频帧时,它不断预测下一帧的潜在特征。然后,我们测量模型预测与该传入帧的实际地面真值特征之间的余弦距离。此距离作为惊奇的定量度量:值越大表示偏离模型学习到的期望越大。此惊奇分数作为接下来探索的下游任务的强大的、自监督的指导信号。
4.2. 案例研究 I:VSI-SUPER Recall 的惊奇驱动记忆管理系统 (Case Study I: Surprise-driven Memory Management System for VSI-SUPER Recall)
大多数当前的 MLLM 平等对待所有视频帧,存储每一帧而不进行选择性压缩或遗忘,这限制了效率和可扩展性。在这个案例研究中,我们探索用惊奇驱动的记忆管理 框架增强 MLLM,以支持长时程视频的持续空间感知问答。我们表明,通过惊奇引导的压缩,Cambrian-S 保持了一致的准确性和稳定的 GPU 内存占用,且与视频长度无关。
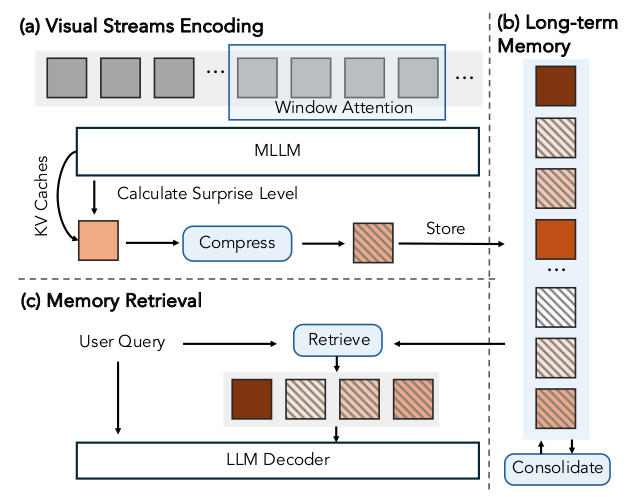
图10
惊奇驱动的记忆管理系统 。我们的记忆管理系统基于"惊奇"的估计动态压缩和整合视觉流。如图 10-a 所示,我们使用具有固定窗口大小的滑动窗口注意力对传入帧进行编码。潜帧预测模块随后测量"惊奇水平"并将其分配给每一帧的 KV 缓存。惊奇水平低于预定义阈值的帧在被推入长期记忆之前经过 2 倍压缩。为了保持稳定的 GPU 内存占用,此长期记忆通过整合函数限制为固定大小,该函数再次基于惊奇操作:根据惊奇分数丢弃或合并帧(见图 10-b)。最后,在收到用户查询时,系统通过计算查询与存储帧特征之间的余弦相似度,从长期记忆中检索前 KKK 个最相关的帧(见图 10-c)。更多设计细节见第 F.2 节。虽然之前的工作探索了长视频的记忆系统设计 119, 159,但我们的重点是探索预测误差(即惊奇)作为指导信号。
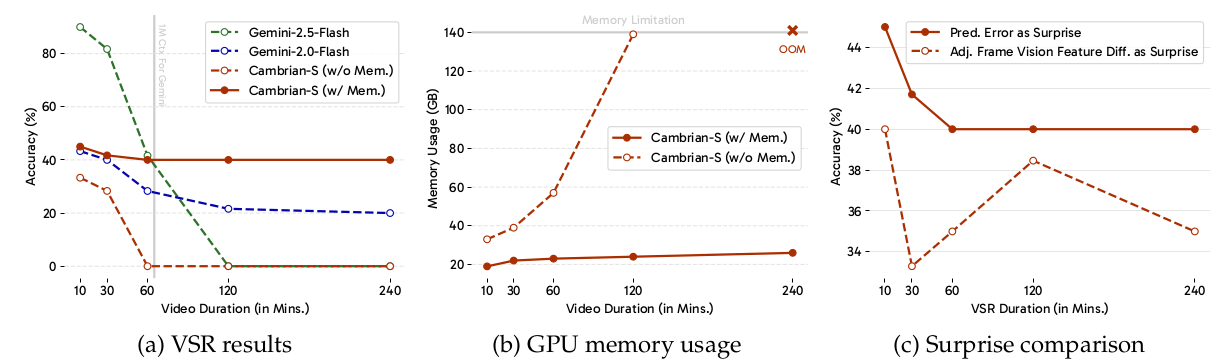
图11
结果。我们将带有和不带有惊奇基础记忆系统的 Cambrian-S 与两个先进的专有模型 Gemini-1.5-Flash 122 和 Gemini-2.5-Flash 30 在 VSR 基准上进行了比较。如图 11a 所示,Cambrian-S (w/ Mem.) 在所有视频长度上都优于 Gemini-1.5-Flash 和 Cambrian-S (w/o Mem.),展示了跨视频持续时间的稳定空间感知性能。虽然 Gemini-2.5-Flash 在一小时内的视频上产生了很好的结果,但它无法处理更长的输入。除了保持高精度外,Cambrian-S (w/ Mem.) 还在不同视频长度上保持稳定的 GPU 内存使用率(图 11b)。这表明惊奇基础记忆有效地压缩了冗余数据而没有丢失关键信息。我们在表 17 中包括了两个长视频基线,MovieChat 119 和 Flash-VStream 159,以供比较。
关于惊奇测量的消融。我们惊奇基础记忆系统的核心是测量惊奇的机制,它决定了如何在被动感知方式下(即不假设任何关于未来查询的先验知识)压缩或整合帧。在这里,我们将我们的设计(即预测误差作为惊奇)与另一个简单的基线进行比较:相邻帧视觉特征相似度。具体来说,我们使用 SigLIP2 作为视觉编码器,直接比较两个相邻帧之间的帧特征差异(余弦距离)。如果差异超过阈值,我们将后一帧视为惊奇帧。我们在所有 VSR 变体中比较这两种方法。对于每个 VSR 时长,我们保持实验设置相同,除了惊奇阈值,我们对两种方法都进行了调整。如图 11c 所示,使用预测误差作为惊奇测量在不同视频时长上始终优于相邻帧相似度。
💡 预测性感知提供了一种比基于每帧特征的静态相似度测量更具原则性的方法来建模视频数据的时空动态。
虽然我们目前的系统采用简单的预测头作为初始原型,但未来集成更强大的世界模型可能会产生更丰富、更可靠的惊奇信号,最终实现更广泛的空间超感知进展。
4.3. 案例研究 II:VSI-SUPER Count 的惊奇驱动持续视频分割 (Case Study II: Surprise-driven continual video segment for VSI-SUPER Count)
虽然 VSR 侧重于评估 MLLM 的长期观察和回忆能力,但对超感知的更具挑战性的测试将涉及测试模型解释其感官输入、跨不同环境导航并执行累积、多跳推理的能力。例如,模型可能需要在一个环境中完成任务,移动到另一个环境,最终整合所有经验中的信息以达成最终决策。
惊奇驱动的事件分割。事件可以理解为体验的时空连贯片段 64。在空间超感知的背景下,事件对应于位于特定空间并感知其环境的连续体验。这一定义强调,真实的感官体验通常被组织成局部连贯的片段------即感知、空间和时间特征保持相对稳定或一致的情节。因此,事件分割是基于这种连贯性的变化将连续的感官输入流解析为离散、有意义的单元的过程。这种分割对于推理和行为至关重要 37:它允许智能体(生物或人工)形成体验的结构化表示,检测发生重大变化的边界,并相应地更新关于环境的预测。最近的研究强调,预测误差和工作记忆/上下文的变化是驱动分割的两种可能机制 98, 118。
在 VSI-SUPER Count (VSC) 基准中,我们检查了一个简单的设置,其中惊奇用于分割连续的视觉输入,识别场景变化作为划分视频流的自然断点,将其划分为空间连贯 的片段。这种方法也类似于人类解决问题的过程:在统计大区域内的物体时,人们通常先专注于一个部分,然后再合并结果。这种行为也与"门口效应" 106 有关,即穿过门口或进入新房间会在记忆中创建一个自然边界。如图 12 所示,模型在事件缓冲区中不断累积帧特征。当检测到高惊奇帧时,缓冲的特征被汇总以产生片段级答案,并且缓冲区被清除以开始新片段。这个循环重复直到视频结束,之后所有片段答案被聚合以形成最终输出。
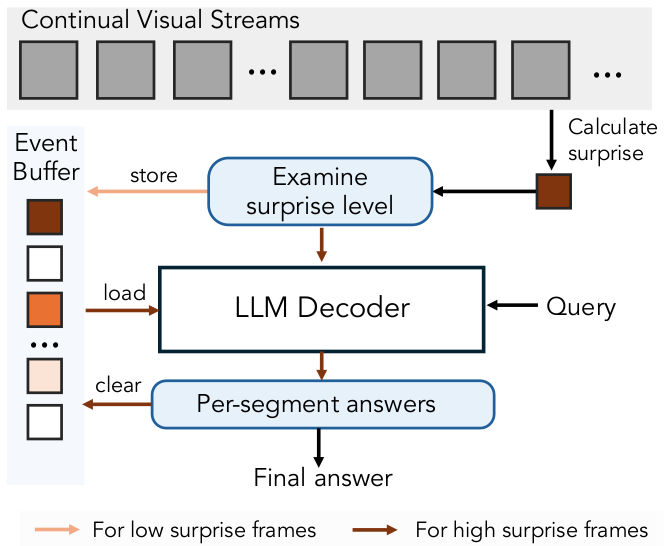
图12
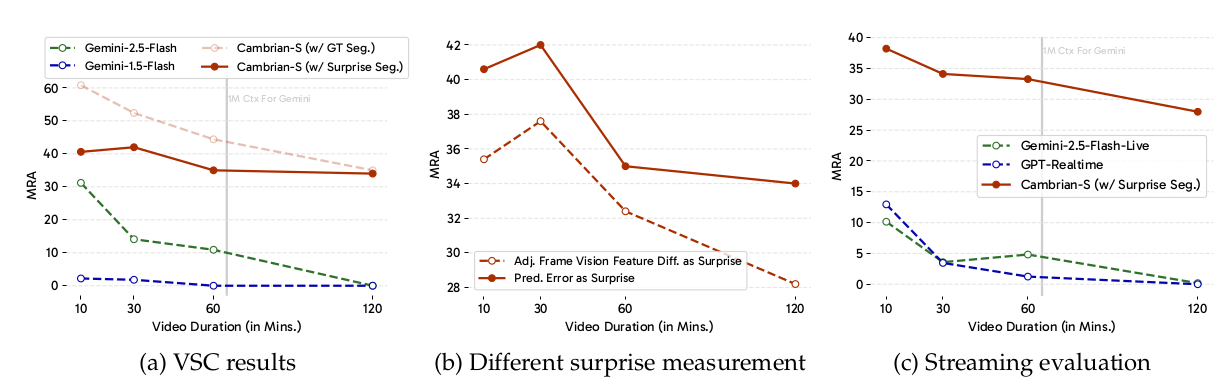
图13
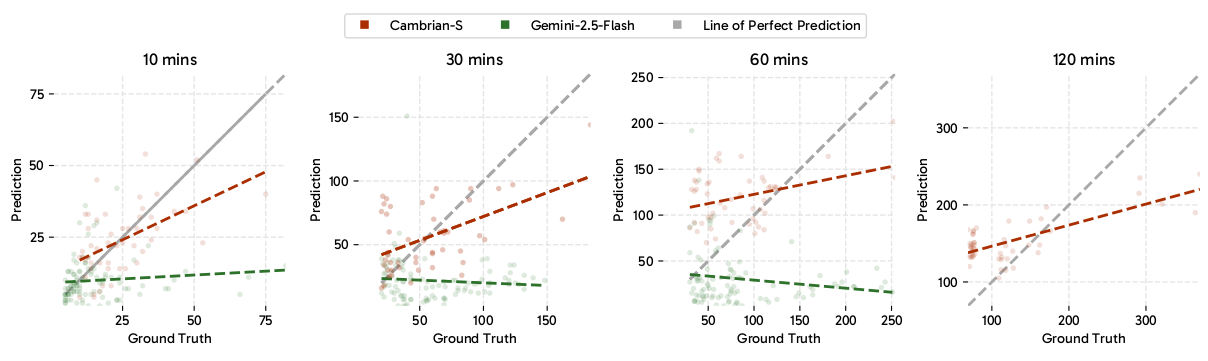
图14
结果。Gemini-1.5-Flash 在 VSC 上获得接近零的性能(图 13a),显示了任务的难度。尽管 Gemini-2.5-Flash 在 10 分钟视频上产生了好得多的结果,但在更长的视频上其性能迅速下降。相比之下,Cambrian-S (w/ Surprise Seg.) 使用的惊奇驱动事件分割方法在所有视频长度上实现了更高且更稳定的性能。当视频使用地面真值场景转换进行分割(即 Cambrian-S w/ GT Seg.)时,性能进一步提高,代表了一个近似上限。图 14 的深入分析显示,Gemini-2.5-Flash 的预测局限于有限范围,并且随着视频中出现更多物体而不按比例增加。相比之下,Cambrian-S (w/ Surprise Seg.) 产生的计数虽然尚未完全准确,但与真实物体数量表现出更强的相关性,表明更好的泛化能力。
关于惊奇测量的消融。我们将我们的惊奇驱动方法与使用相邻帧特征相似度的基线进行了比较(图 13b)。对于这两种方法,我们报告超参数调整后的最佳结果。与我们在 VSR 中的观察一致,使用预测误差作为惊奇的度量在所有视频持续时间上均以显着优势优于外观相似度。
流式设置中的评估。由于 VSC 中的正确答案随视频演变,我们创建了一个流式 QA 设置,在 10 个不同的时间戳提出相同的问题。最终性能是所有查询的平均值。我们以针对实时视觉输入进行营销的商业 MLLM 为基准。如图 13c 所示,尽管 Gemini-Live 和 GPT-Realtime 旨在用于流式场景,但它们在 10 分钟视频上的 MRA 低于 15%,并且在 120 分钟的流上性能下降到接近零。然而,Cambrian-S 表现出更强的性能,在 10 分钟流上达到 38% MRA,并在 120 分钟时保持在 28% 左右。
总结。在 VSR 回忆和 VSC 计数任务中,通过惊奇驱动的记忆和事件分割进行的预测性感知使 Cambrian-S 能够克服第 3 节中描述的固定上下文限制。尽管这仍然是一个早期的原型,但它突出了构建不仅能看而且能预测、选择和组织经验的 AI 系统的潜力。此类系统超越了帧级 QA,迈向构建支持更深空间推理、跨无界时间视界扩展并实现媲美甚至最终超越人类视觉智能的超感知的隐式世界模型。
5. 相关工作 (Related Work)
视频多模态大语言模型 (Video Multimodal Large Language Models)。预训练 LLM 强大的语言理解能力 15, 126, 7, 127,结合用作特征提取器的视觉基础模型的表征能力 105, 157, 128, 50, 39,推动了将这些模型扩展到文本之外以实现视觉内容语义感知的重大进展,主要是在图像领域 56, 78, 65, 8, 124, 121, 27, 134, 68。这一势头激发了对基于视频的 MLLM 的研究 74, 65, 161, 119, 9, 167, 158, 69, 168, 89 的增长,这被视为将多模态智能与现实世界应用(如具身智能体)连接起来的关键步骤 61, 147。正如整篇论文所强调的,开发真正有能力的超感知系统需要重新思考几个核心方面,包括如何衡量进步、什么构成正确的数据、哪种架构设计最有效以及什么建模目标最符合系统的目标。
流式视频理解 (Streaming Video Understanding) 。视频是视觉信号的连续且潜在无限的流。虽然人类毫不费力地处理它,但其无界性质对视频 MLLM 构成了挑战,因为 token 长度随持续时间增加,导致计算和存储成本上升。最近的工作探索了几种解决这个问题的方法:高效的架构设计 。自注意力的二次方成本使得处理长视频变得困难。最近的方法 70, 112 使用更简单、更快的架构 135, 48, 58,减少了计算量并更好地处理较长的输入。上下文窗口扩展 。预训练 LLM 中固定的上下文长度限制了它们对长期内容的理解。最近的工作 26, 160, 25 通过精心的系统设计扩展了这个窗口,使模型能够处理和推理更长的视频序列。检索增强的视频理解 。为了处理长视频,一些方法仅从较大的集合中检索最相关的片段 63, 101, 136 并将其用作进一步分析的上下文。视觉 token 减少或压缩。其他方法通过减少帧间或帧内的视觉 token 来缩短输入 117, 73, 57, 72, 19,使处理长视频序列变得更容易。虽然这些方法提高了性能,但它们主要将连续视频视为标准的序列建模问题,类似于文本。我们相信未来的 MLLM 应该构建内部预测模型来像人类一样高效地处理连续的视觉流。
视觉空间智能 (Visual Spatial Intelligence)。从视觉输入中理解空间关系对于感知物理世界并与之交互至关重要。随着多模态模型在物理上变得更加接地,对空间智能的兴趣激增,导致了新的基准测试 148, 107, 154, 86, 152, 75, 142, 123 以及专注于增强模型空间推理能力的研究 151, 84, 99, 38, 21, 28, 18, 76, 67, 166, 110。在本文中,我们通过视频中的空间超感知概念研究视觉空间智能,并探索通过完善数据整理、优化训练策略和引入新范式来加强 MLLM 空间推理的方法。
预测性建模 (Predictive Modeling)。学习到的内部预测模型 31, 49 允许智能代理表示和模拟其环境的各个方面,从而实现更有效的规划和决策。模型预测控制 (MPC) 43 在控制理论中应用类似原则,利用内部前向模型实时预测未来轨迹并选择最佳动作。这一概念从人类如何形成世界的心智模型 108, 52, 41 以及这些内部表征如何影响行为(例如,无意识推断 130)中汲取灵感,充当现实的简化抽象,从而实现预测和高效行动。越来越多的工作探索了通过自监督表征学习 5, 6 以及文本或动作条件视频生成 164, 150, 11, 22, 10, 44 进行预测性建模的想法。在本文中,受人类如何利用内部世界模型高效且有效地处理无界感官输入的启发,我们研究如何为 MLLM 配备类似的预测感知能力。
6. 结论 (Conclusion)
我们强调了视频中空间超感知 (supersensing) 能力的重要性并提出了一个层级结构,认为实现超级智能需要 AI 系统超越基于文本的知识和语义感知(这是目前大多数 MLLM 的重点),也要发展空间认知和预测性世界模型。为了衡量进展,我们引入了 VSI-SUPER,并发现当前的 MLLM 很难应对它。为了测试当前的进展是否受限于数据,我们整理了 VSI-590K 并用它训练了我们的空间接地 MLLM------Cambrian-S。尽管 Cambrian-S 在标准基准测试中表现良好,但它在 VSI-SUPER 上的结果揭示了当前 MLLM 范式的局限性。我们对预测性感知进行了原型设计,利用潜帧预测和惊奇估计来处理无界视觉流。它提高了 Cambrian-S 在 VSI-SUPER 上的性能,标志着迈向空间超感知的早期一步。
局限性 (Limitations)。我们的目标是提出一个概念框架,鼓励社区重新考虑发展空间超感知的重要性。作为一个长期的研究方向,我们目前的基准、数据集和模型设计在质量、规模和泛化能力方面仍然有限,原型仅作为概念验证。未来的工作应该探索更多样化和具身的场景,并与视觉、语言和世界建模方面的最新进展建立更紧密的联系。