今天,我们尝试在ubuntu环境下使用RK3576的NPU推理LLM
首先,我们声明一下,本文的参考文档为[速看!EASY-EAI教你离线部署Deepseek R1大模型](https://blog.csdn.net/EASY_EAI/article/details/126951058?fromshare=blogdetail&sharetype=blogdetail&sharerId=126951058&sharerefer=PC&sharesource=xfddlm&sharefrom=from_link)
好的,接下来我们先在服务器端搭建conda环境,用于将目标部署模型的safetensor文件,并转换为瑞芯微NPU支持的rkllm模型文件,使用如下命令创建并进入conda环境
bash
conda create -n RKLLM python=3.8 -y
conda activate RKLLM
然后,下载如下安装包并安装
https://pan.baidu.com/s/1kW1wuZuYpnBaKvwrlCFdxw?pwd=1111

bash
pip3 install nvidia_cublas_cu12-12.1.3.1-py3-none-manylinux1_x86_64.whl
pip3 install torch-2.1.0-cp38-cp38-manylinux1_x86_64.whl
pip3 install rkllm_toolkit-1.1.4-cp38-cp38-linux_x86_64.whl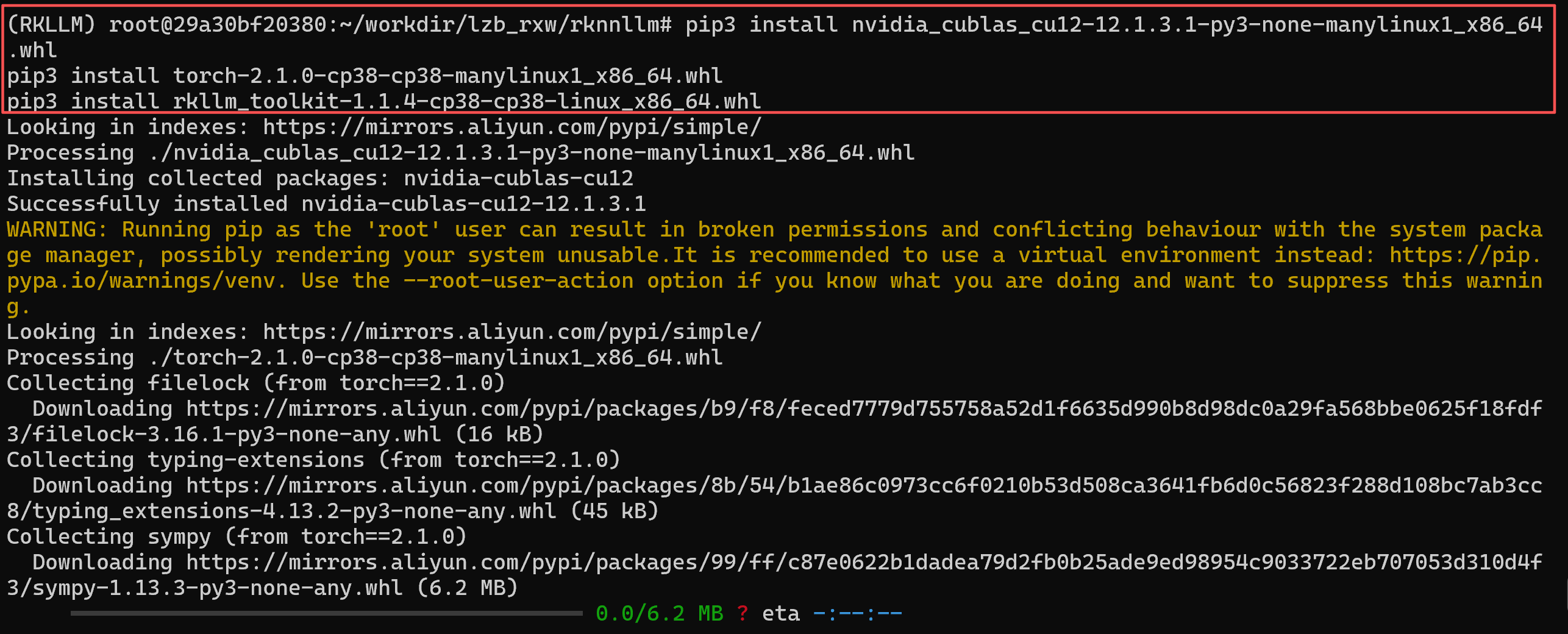
安装完成之后,下载需要部署的原始模型然后进行转换,我这里下载DeepSeek和Qwen,使用如下命令进行下载
(由于python3.8环境和最新的魔塔兼容,可以创建一个新的安装了python3.12环境的conda环境,下载好模型之后再切换回来
)
bash
conda create -n llm_download python=3.12 -y
conda activate llm_download
bash
pip install modelscope
modelscope download --model suayptalha/DeepSeek-R1-Distill-Llama-3B --local_dir ./DeepSeek-R1
conda activate RKLLM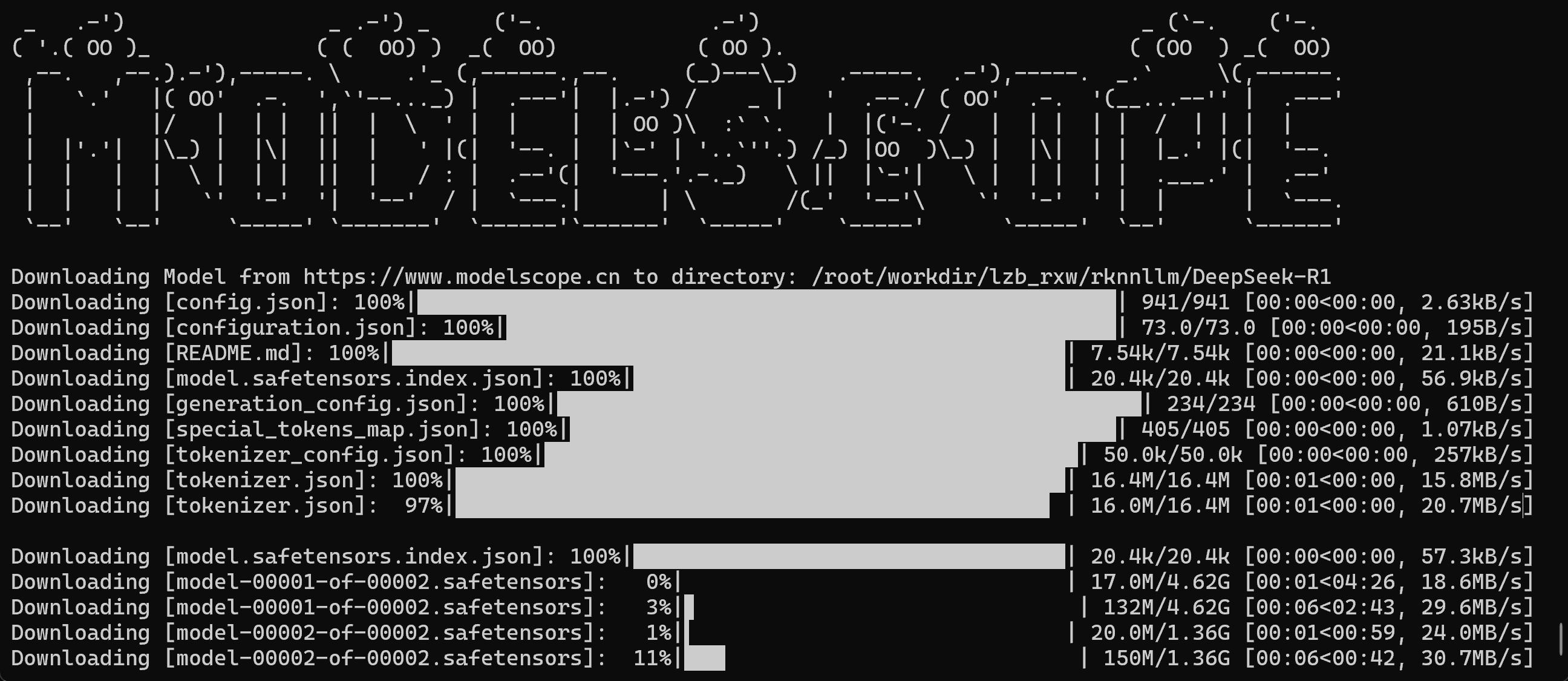

然后使用如下脚本实现模型转换
bash
from rkllm.api import RKLLM
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
import torch
from torch import nn
import os
# os.environ['CUDA_VISIBLE_DEVICES']='1'
modelpath = './DeepSeek-R1'
llm = RKLLM()
# Load model
# Use 'export CUDA_VISIBLE_DEVICES=2' to specify GPU device
# options ['cpu', 'cuda']
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cpu')
# ret = llm.load_gguf(model = modelpath)
if ret != 0:
print('Load model failed!')
exit(ret)
# Build model
dataset = "./data_quant.json"
# Json file format, please note to add prompt in the input,like this:
# [{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手KK!"},...]
qparams = None
# qparams = 'gdq.qparams' # Use extra_qparams
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w4a16',
quantized_algorithm='normal', target_platform='rk3576', num_npu_core=2, extra_qparams=qparams, dataset=None)
if ret != 0:
print('Build model failed!')
exit(ret)
# Evaluate Accuracy
def eval_wikitext(llm):
seqlen = 512
tokenizer = AutoTokenizer.from_pretrained(
modelpath, trust_remote_code=True)
# Dataset download link:
# https://huggingface.co/datasets/Salesforce/wikitext/tree/main/wikitext-2-raw-v1
testenc = load_dataset(
"parquet", data_files='./wikitext/wikitext-2-raw-1/test-00000-of-00001.parquet', split='train')
testenc = tokenizer("\n\n".join(
testenc['text']), return_tensors="pt").input_ids
nsamples = testenc.numel() // seqlen
nlls = []
for i in tqdm(range(nsamples), desc="eval_wikitext: "):
batch = testenc[:, (i * seqlen): ((i + 1) * seqlen)]
inputs = {"input_ids": batch}
lm_logits = llm.get_logits(inputs)
if lm_logits is None:
print("get logits failed!")
return
shift_logits = lm_logits[:, :-1, :]
shift_labels = batch[:, 1:].to(lm_logits.device)
loss_fct = nn.CrossEntropyLoss().to(lm_logits.device)
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
neg_log_likelihood = loss.float() * seqlen
nlls.append(neg_log_likelihood)
ppl = torch.exp(torch.stack(nlls).sum() / (nsamples * seqlen))
print(f'wikitext-2-raw-1-test ppl: {round(ppl.item(), 2)}')
# eval_wikitext(llm)
# Chat with model
messages = "<|im_start|>system You are a helpful assistant.<|im_end|><|im_start|>user你好!\n<|im_end|><|im_start|>assistant"
kwargs = {"max_length": 128, "top_k": 1, "top_p": 0.8,
"temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
# print(llm.chat_model(messages, kwargs))
# Export rkllm model
ret = llm.export_rkllm("./deepseek_r1_rk3576_w4a16.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)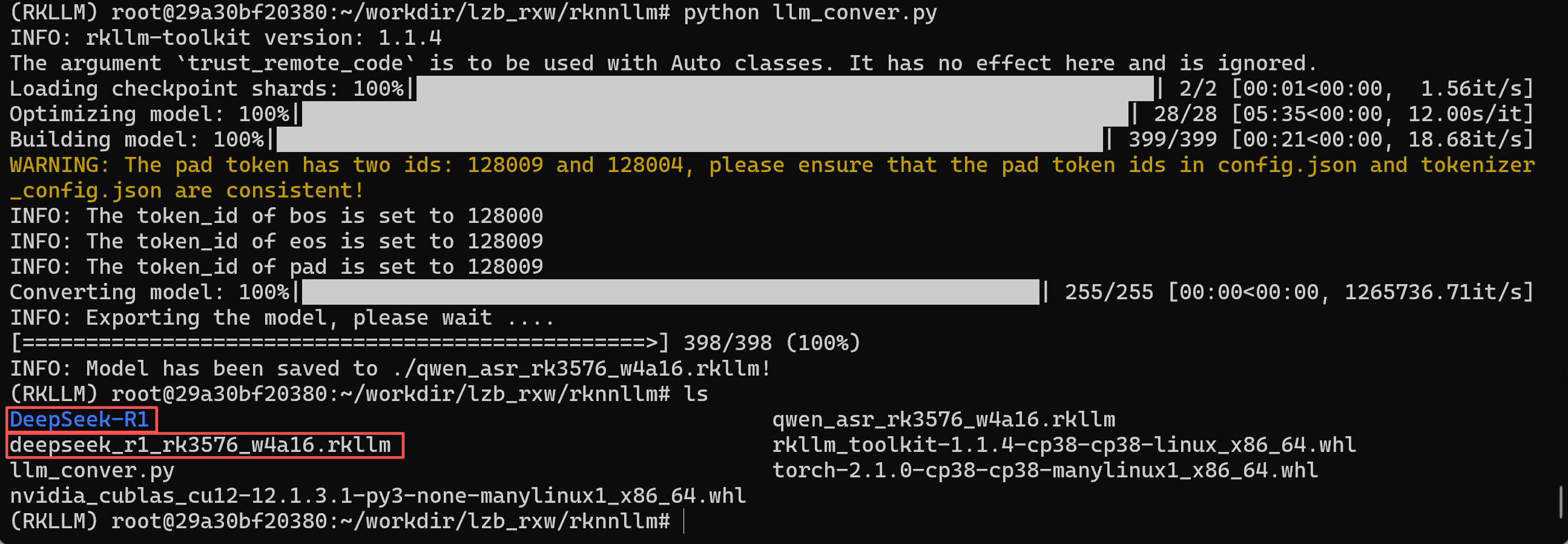
然后,将转换好的模型部署到开发板上
bash
scp -r -p ./deepseek_r1_rk3576_w4a16.rkllm root@192.168.1.127:/userdata/deepseeknp
至此,部署完成,然后准备如下推理代码
推理代码下载地址如下:
https://pan.baidu.com/s/1kXrC3byVWRtR6vUPlSMfBA?pwd=1111
下载好后使用如下命令解压
bash
tar -zxf deepseek-demo.tar.gz然后,使用如下命令进行编译
bash
bash build.sh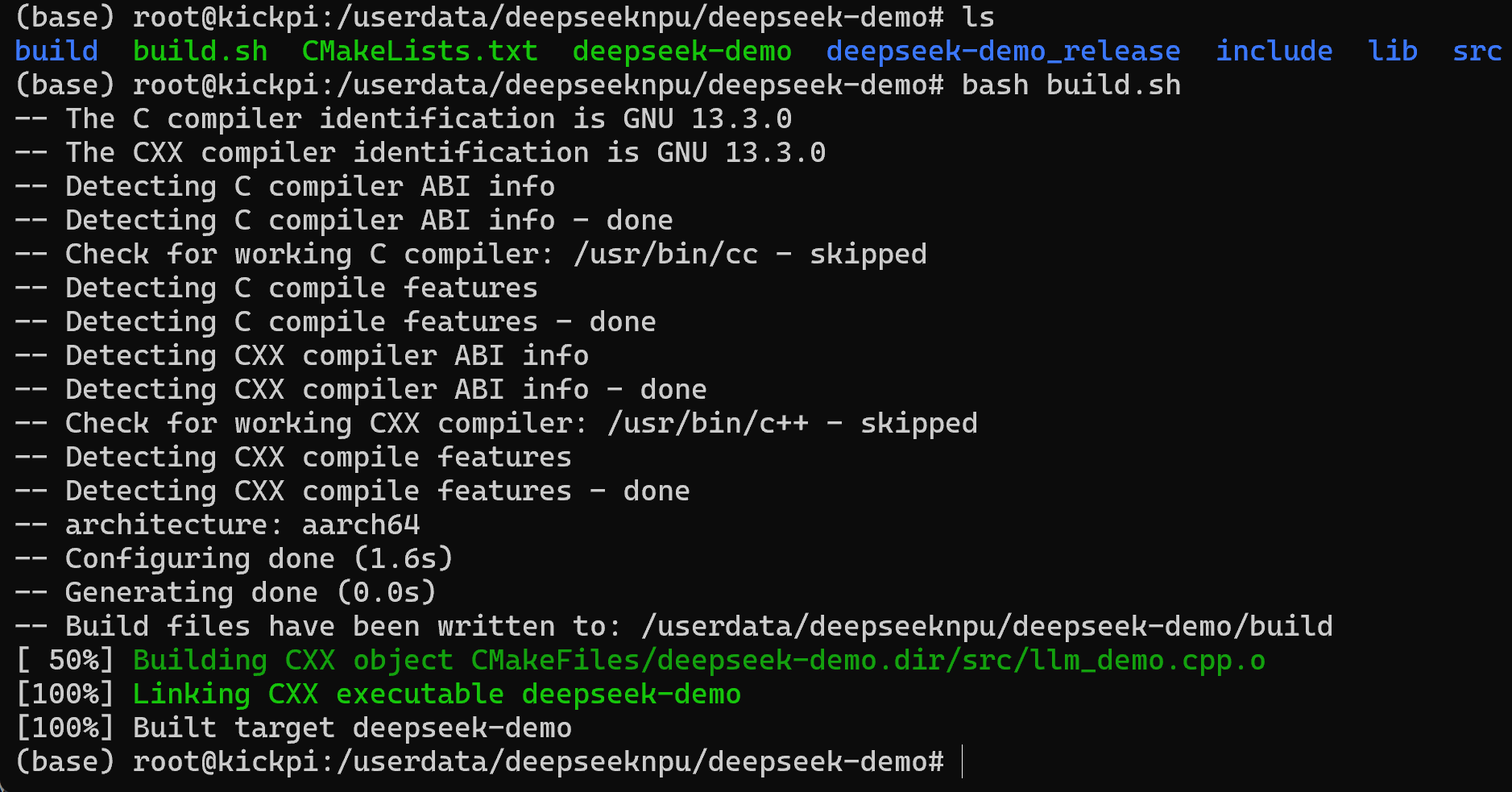
然后,使用如下命令执行推理
bash
LD_LIBRARY_PATH=./lib ./build/deepseek-demo /userdata/deepseeknpu/deepseek_r1_rk3576_w4a16.rkllm 256 512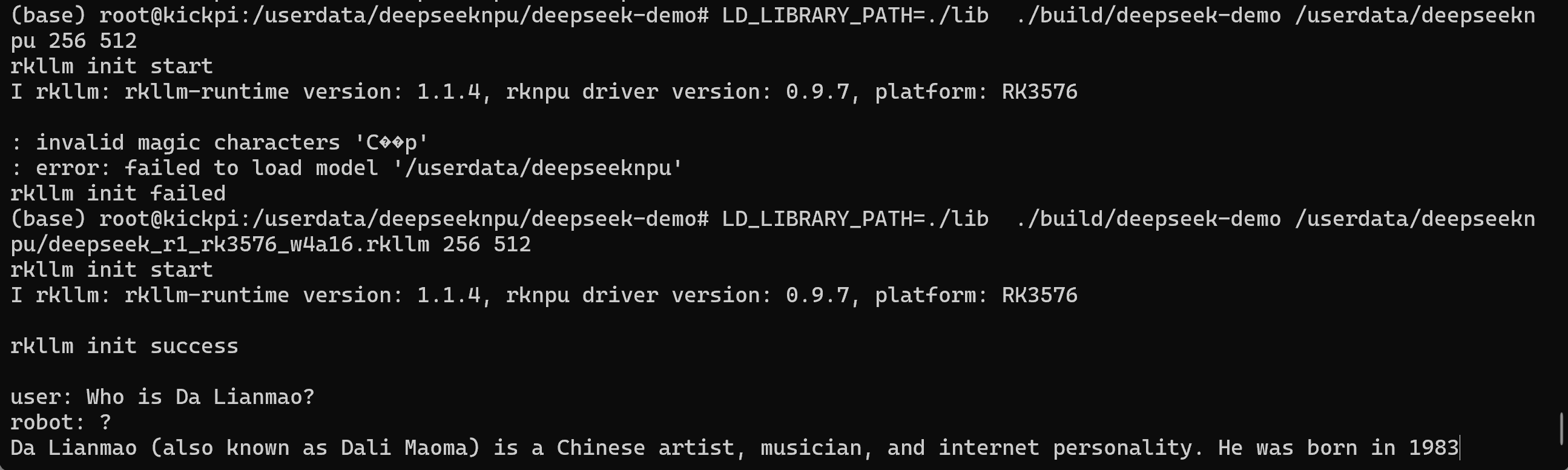
其中,LD_LIBRARY_PATH=./lib为动态库目录,./build/deepseek-demo为推理可执行文件,/userdata/deepseeknpu/deepseek_r1_rk3576_w4a16.rkllm为模型文件