前言
开放域问答(Open-Domain Question Answering, ODQA)中的检索通常使用TF-IDF或BM25来实现,它通过倒排索引有效地匹配关键字,可以看作是用高维稀疏向量(带加权)表示问题和上下文。
一、TF-IDF
TF-IDF(词频-逆文档频率)是信息检索领域最经典的特征加权方法,用于衡量一个词在文档中的重要程度。
1.1 核心公式
TF-IDF的核心公式如下所示:
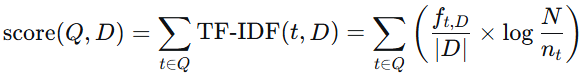
等式右边的第一项为,第二项为
。其中:
-
:完整的查询
-
-
-
-
-
-
1.2 举例说明
假设查询为 "苹果手机"。
有以下三个文档库:
D1:"苹果公司发布了新款手机,这款手机搭载了先进芯片。"
D2:"今天吃了一个红苹果,非常甜。"
D3:"手机市场竞争激烈,苹果手机销量领先。"
(1)首先使用分词库(例如jieba中文分词)对文档进行分词:
D1:"苹果", "公司", "发布", "新款", "手机", "手机", "搭载", "先进", "芯片"(总词数 9)
D2:"今天", "吃", "红", "苹果", "非常", "甜"(总词数 6)
D3:"手机", "市场", "竞争", "激烈", "苹果", "手机", "销量", "领先"(总词数 8)
(2)计算TF:
计算各个词项 对各个文档的TF:
D1:
-
TF(苹果, D1) = 1/9 ≈ 0.111
-
TF(手机, D1) = 2/9 ≈ 0.222
D2:
-
TF(苹果, D2) = 1/6 ≈ 0.167
-
TF(手机, D2) = 0/6 = 0
D3:
-
TF(苹果, D3) = 1/8 = 0.125
-
TF(手机, D3) = 2/8 = 0.250
(3)计算IDF:
-
包含"苹果"的文档数:n_苹果 = 3
-
包含"手机"的文档数:n_手机 = 2
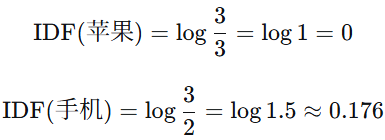
(4)计算各个词项 对各个文档的TF-IDF:
D1:
-
TF-IDF(苹果, D1) = 0.111 × 0 = 0
-
TF-IDF(手机, D1) = 0.222 × 0.176 ≈ 0.039
D2:
-
TF-IDF(苹果, D2) = 0.167 × 0 = 0
-
TF-IDF(手机, D2) = 0
D3:
-
TF-IDF(苹果, D3) = 0.125 × 0 = 0
-
TF-IDF(手机, D3) = 0.250 × 0.176 ≈ 0.044
(5)文档-查询相关性得分:
将查询中所有词项 的TF-IDF值相加(即
求和):
-
D1得分 = 0 + 0.039 = 0.039
-
D2得分 = 0 + 0 = 0
-
D3得分 = 0 + 0.044 = 0.044
排序结果:D3 > D1 > D2
二、BM25
BM25(Best Matching 25)是 TF-IDF 的改进版本 ,通过引入非线性词频处理 和文档长度归一化,显著提升了检索效果。
2.1 核心公式
BM25的核心公式如下所示:
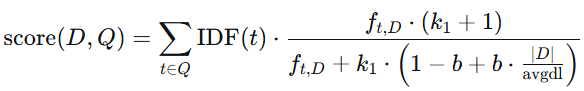
-
-
-
-
-
-
-
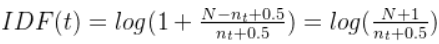
其中 是文档总数,
是包含词项
的文档数。
2.2 举例说明
假设查询为 "苹果手机"。
有以下三个文档库:
D1:"苹果公司发布了新款手机,这款手机搭载了先进芯片。"
D2:"今天吃了一个红苹果,非常甜。"
D3:"手机市场竞争激烈,苹果手机销量领先。"
(1)首先使用分词库(例如jieba中文分词)对文档进行分词:
D1:"苹果", "公司", "发布", "新款", "手机", "手机", "搭载", "先进", "芯片"(总词数 9)
D2:"今天", "吃", "红", "苹果", "非常", "甜"(总词数 6)
D3:"手机", "市场", "竞争", "激烈", "苹果", "手机", "销量", "领先"(总词数 8)
(2)计算基础统计量:
-
文档总数
-
各文档长度:
-
平均长度
-
设为
(3)计算TF:
假设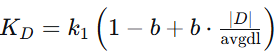 ,计算各个词项
,计算各个词项 对各个文档的TF:
D1:
苹果 = 1,
手机 = 2
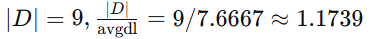
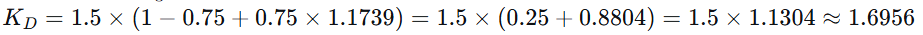
-
TF(苹果, D1)
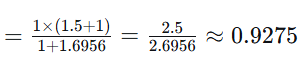
-
TF(手机, D1)
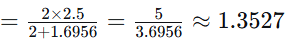
D2:
苹果 = 1,
手机 = 0
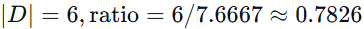
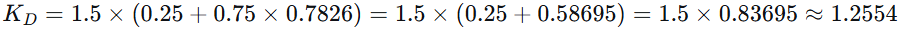
-
TF(苹果, D2)
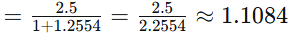
-
TF(手机, D2) = 0
D3:
苹果 = 1,
手机 = 2
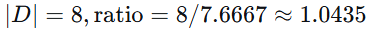
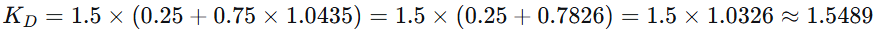
-
TF(苹果, D3)
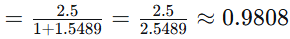
-
TF(手机, D3)
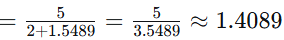
(4)计算IDF:
-
包含"苹果"的文档数:n_苹果 = 3
-
包含"手机"的文档数:n_手机 = 2
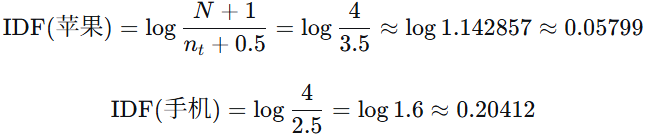
(5)计算各个词项 对各个文档的TF-IDF:
D1:
-
TF-IDF(苹果, D1) = 0.9275 × 0.05799 ≈ 0.05378
-
TF-IDF(手机, D1) = 1.3527 × 0.20412 ≈ 0.2760
D2:
-
TF-IDF(苹果, D2) = 1.1084 × 0.05799 ≈ 0.06427
-
TF-IDF(手机, D2) = 0 × -0.2218 ≈ 0
D3:
-
TF-IDF(苹果, D3) = 0.9808 × 0.05799 ≈ 0.05687
-
TF-IDF(手机, D3) = 1.4089 × 0.20412 ≈ 0.28748
(6)文档-查询相关性得分:
将查询中所有词项 的TF-IDF值相加(即
求和):
-
D1得分 = 0.05378 + 0.2760 = 0.32978
-
D2得分 = 0.06427 + 0 = 0.06427
-
D3得分 = 0.05687 + 0.28748 = 0.34435
排序结果:D3 > D1 > D2