CAT(Central Application Tracking)深度技术解读
1. 整体介绍
1.1 项目概况
CAT 是由美团点评(现美团)开源的实时应用监控平台,项目地址为:https://github.com/dianping/cat。截至当前,该项目在GitHub上获得超过1.8万星标,被分叉超过7千次,具备活跃的社区生态。项目采用Apache 2.0开源协议,主要使用Java语言开发。
1.2 核心功能特性
CAT定位为分布式系统的实时监控基础设施,其核心特性包括:
- 秒级实时处理能力:监控数据从客户端产生到服务端处理展示的延迟控制在秒级,实现近实时监控。
- 多语言客户端支持:提供Java、C/C++、Node.js、Python、Go等多语言客户端SDK,便于异构技术栈接入。
- 四种监控数据模型 :
- Transaction:记录跨系统边界的事务(如HTTP请求、RPC调用)
- Event:记录离散事件(如异常、关键日志)
- Heartbeat:定期上报系统指标(JVM状态、负载等)
- Metric:记录业务指标和计数器
- 全量数据采集与分析:客户端进行数据预计算,服务端进行全量统计分析,避免采样偏差。
1.3 解决问题与适用场景
解决的问题要素:
- 故障发现滞后:传统监控系统数据处理延迟高,故障发现时间长。
- 故障定位困难:分布式系统调用链复杂,问题根因定位成本高。
- 监控数据不完整:基于采样的监控系统可能遗漏关键故障数据。
- 多语言系统监控分散:不同技术栈需要不同的监控工具,运维复杂度高。
- 监控系统自身故障影响业务:部分监控方案侵入性强,可能影响业务稳定性。
对应场景:
- 大规模分布式微服务架构的系统监控
- 需要实时业务指标监控的电商、金融等系统
- 多技术栈混合的复杂系统环境
- 对系统可用性和性能有较高要求的在线服务
1.4 解决方案演进
传统方式:
- 基于日志文件的离线分析,延迟通常在小时级别
- 采样监控(如1%采样率)可能遗漏关键异常
- 各语言使用独立的监控方案,数据难以聚合
- 监控系统与业务系统紧耦合,故障可能相互影响
CAT新方式的优势:
- 实时性提升:从小时级降至秒级,大幅缩短MTTR
- 数据完整性:全量数据采集确保故障复盘准确性
- 统一监控平台:多语言统一接入,降低运维复杂度
- 对业务透明:客户端异步上报,监控系统故障不影响业务
1.5 商业价值分析
价值估算逻辑:
- 代码复用成本节约:企业自研同等能力的监控系统通常需要20-30人月的投入,CAT提供了成熟的开源实现。
- 故障恢复效益:实时监控可将故障平均恢复时间(MTTR)降低50-70%,按每次故障损失1万元计算,年节约数十万至数百万。
- 运维效率提升:统一监控平台减少多工具维护成本,预计提升运维效率30%。
- 问题预防价值:通过趋势分析提前发现潜在问题,避免重大故障发生。
保守估计,中型互联网企业采用CAT可获得年化百万元级别的综合收益。
2. 详细功能拆解
2.1 架构模块分解
markdown
CAT架构层级:
1. 数据采集层(Client SDK)
- Java客户端(lib/java)
- 多语言客户端(C/C++、Node.js等)
- 埋点与数据预计算
2. 数据处理层(Consumer)
- 消息队列缓冲
- 实时分析器(Analyzer)
- 报表生成
3. 数据存储层
- 本地文件存储(Bucket机制)
- HDFS归档存储(cat-hadoop)
- MySQL配置存储
4. 服务展示层(Home)
- Web管理界面
- 实时报表展示
- 配置管理
5. 告警服务层(Alarm)
- 阈值监控
- 告警规则引擎
- 多渠道通知2.2 核心功能设计
实时处理流程:
plaintext
客户端埋点 → 本地队列缓冲 → 异步网络传输 → 服务端接收队列 →
实时分析器处理 → 内存聚合 → 分钟级持久化 → 报表展示数据模型设计特点:
- Transaction模型:支持嵌套结构,记录完整调用链路
- 采样策略:全量统计与采样链路相结合,平衡性能与数据完整性
- 预计算机制:客户端进行初步统计,减轻服务端压力
3. 技术难点与解决方案
3.1 高吞吐实时处理
难点 :单机需要处理数万到数十万QPS的监控数据。 解决方案:
- 客户端本地缓冲+批量发送
- 服务端使用内存队列缓冲(MessageQueue)
- 多分析器并行处理架构
3.2 全量数据统计与存储
难点 :全量数据带来的存储和计算压力。 解决方案:
- 分层存储策略:热数据内存聚合,温数据本地文件,冷数据HDFS
- 基于时间的分片存储(Bucket机制)
- 压缩存储优化(Snappy压缩算法)
3.3 客户端采样与服务器聚合
难点 :平衡数据完整性和系统负载。 解决方案:
java
// AbstractMessageAnalyzer中的采样逻辑
public boolean isEligable(MessageTree tree) {
// 采样判断逻辑,控制分析的数据量
return true; // 默认全量处理,特定分析器可重写
}3.4 多语言客户端一致性
难点 :保证不同语言客户端行为一致。 解决方案:
- 统一定义消息编码协议
- 各语言实现核心接口的一致性
- 共享测试用例确保行为对齐
4. 详细设计图
4.1 整体架构图
graph TB
subgraph "客户端层"
A1[Java应用] --> A2[CAT Java客户端]
B1[Go应用] --> B2[CAT Go客户端]
C1[Python应用] --> C2[CAT Python客户端]
end
subgraph "传输层"
A2 --> D[消息编码/序列化]
B2 --> D
C2 --> D
D --> E[网络传输]
end
subgraph "服务端层"
E --> F[消息接收器]
F --> G[消息队列]
G --> H{分析器路由}
subgraph "分析器集群"
H --> I1[Transaction分析器]
H --> I2[Event分析器]
H --> I3[Heartbeat分析器]
H --> I4[Metric分析器]
end
I1 --> J[报表管理器]
I2 --> J
I3 --> J
I4 --> J
J --> K[存储管理器]
K --> L[本地文件存储]
K --> M[MySQL配置存储]
K --> N[HDFS归档存储]
J --> O[告警引擎]
O --> P[告警通知]
end
subgraph "展示层"
Q[Web管理界面] --> R[实时报表]
Q --> S[配置管理]
Q --> T[日志查询]
end
4.2 核心处理序列图
sequenceDiagram
participant Client as 客户端
participant Queue as 消息队列
participant Analyzer as 分析器
participant Storage as 存储层
participant Manager as 报表管理器
Client->>Queue: 发送监控消息
Note over Client,Queue: 异步批量发送
loop 实时处理循环
Analyzer->>Queue: poll()获取消息
Queue-->>Analyzer: MessageTree
Analyzer->>Analyzer: process(MessageTree)
Note over Analyzer: 内存聚合统计
Analyzer->>Manager: 更新报表数据
end
Note right of Analyzer: 每分钟触发检查点
Analyzer->>Storage: doCheckpoint()
Storage->>Storage: 持久化到文件/HDFS
Storage-->>Analyzer: 确认完成
4.3 核心类图
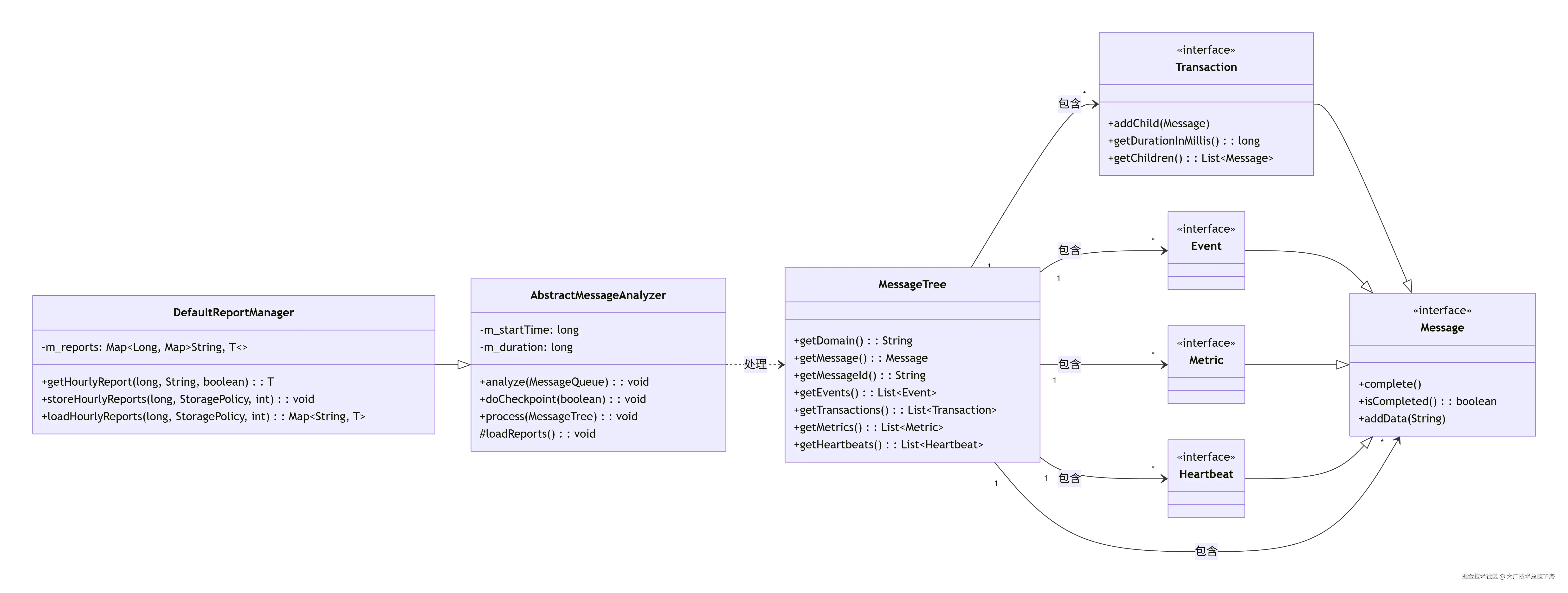
5. 核心代码解析
5.1 消息分析器基类
java
/**
* 抽象消息分析器 - 所有具体分析器的基类
* 负责消费消息队列并进行实时分析
*/
public abstract class AbstractMessageAnalyzer<R> extends ContainerHolder
implements MessageAnalyzer {
// 时间常量定义
public static final long MINUTE = 60 * 1000L;
public static final long ONE_HOUR = 60 * 60 * 1000L;
public static final long ONE_DAY = 24 * ONE_HOUR;
@Inject
protected ServerConfigManager m_serverConfigManager;
protected long m_startTime; // 分析时段开始时间
protected long m_duration; // 分析时段持续时间
protected Logger m_logger;
protected int m_index; // 分析器实例索引
/**
* 核心分析方法 - 从队列消费消息并处理
* 实现了双重循环确保消息完全消费
*/
@Override
public void analyze(MessageQueue queue) {
// 第一轮:在超时时间内尽可能处理消息
while (!isTimeout() && isActive()) {
MessageTree tree = queue.poll();
if (tree != null) {
try {
process(tree); // 抽象方法,由子类实现具体逻辑
} catch (Throwable e) {
handleProcessingError(e);
}
}
}
// 第二轮:清空队列中剩余消息
while (true) {
MessageTree tree = queue.poll();
if (tree != null) {
try {
process(tree);
} catch (Throwable e) {
handleProcessingError(e);
}
} else {
break;
}
}
}
/**
* 检查是否超时
* 考虑额外缓冲时间,避免数据丢失
*/
protected boolean isTimeout() {
long currentTime = System.currentTimeMillis();
long endTime = m_startTime + m_duration + m_extraTime;
return currentTime > endTime;
}
// 抽象方法,子类必须实现
protected abstract void process(MessageTree tree);
protected abstract void loadReports();
public abstract void doCheckpoint(boolean atEnd);
public abstract R getReport(String domain);
}5.2 报表管理器实现
java
/**
* 默认报表管理器 - 按小时维度管理监控报表
* 支持内存缓存和持久化存储
*/
public class DefaultReportManager<T> extends ContainerHolder
implements ReportManager<T>, Initializable, LogEnabled {
@Inject
private ReportDelegate<T> m_reportDelegate; // 报表代理,处理序列化等
@Inject
private ReportBucketManager m_bucketManager; // 存储桶管理
@Inject
private HourlyReportDao m_reportDao; // 数据库访问
// 核心数据结构:时间戳 -> (域名 -> 报表对象)
private Map<Long, Map<String, T>> m_reports =
new ConcurrentHashMap<Long, Map<String, T>>();
/**
* 获取或创建小时报表
* 支持懒加载和缓存机制
*/
@Override
public T getHourlyReport(long startTime, String domain,
boolean createIfNotExist) {
// 双重检查锁定确保线程安全
Map<String, T> reports = m_reports.get(startTime);
if (reports == null && createIfNotExist) {
synchronized (m_reports) {
reports = m_reports.get(startTime);
if (reports == null) {
reports = new ConcurrentHashMap<String, T>();
m_reports.put(startTime, reports);
}
}
}
if (reports == null) {
reports = new LinkedHashMap<String, T>();
}
T report = reports.get(domain);
if (report == null && createIfNotExist) {
synchronized (reports) {
report = m_reportDelegate.makeReport(domain, startTime, HOUR);
reports.put(domain, report);
}
}
return report;
}
/**
* 存储小时报表到持久化层
* 支持文件和数据库两种存储策略
*/
@Override
public void storeHourlyReports(long startTime,
StoragePolicy policy,
int index) {
Transaction t = Cat.newTransaction("Checkpoint", m_name);
Map<String, T> reports = m_reports.get(startTime);
ReportBucket bucket = null;
try {
if (reports != null) {
// 数据验证:过滤非法域名
Set<String> errorDomains = new HashSet<String>();
for (String domain : reports.keySet()) {
if (!m_validator.validate(domain)) {
errorDomains.add(domain);
}
}
// 存储前回调,允许数据预处理
m_reportDelegate.beforeSave(reports);
// 文件存储
if (policy.forFile()) {
bucket = m_bucketManager.getReportBucket(startTime,
m_name, index);
storeFile(reports, bucket);
}
// 数据库存储
if (policy.forDatabase()) {
storeDatabase(startTime, reports);
}
}
t.setStatus(Message.SUCCESS);
} catch (Throwable e) {
Cat.logError(e);
t.setStatus(e);
} finally {
cleanup(startTime); // 清理过期数据
t.complete();
}
}
// 存储策略枚举
public static enum StoragePolicy {
FILE, // 仅文件存储
FILE_AND_DB; // 文件和数据库双重存储
public boolean forFile() {
return this == FILE_AND_DB || this == FILE;
}
public boolean forDatabase() {
return this == FILE_AND_DB;
}
}
}5.3 客户端事务实现
java
/**
* 默认事务实现 - 记录跨系统边界的操作
* 支持嵌套子事务和时间统计
*/
public class DefaultTransaction extends AbstractMessage
implements Transaction {
private TraceContext m_ctx; // 追踪上下文
private volatile long m_durationInMicros; // 微秒级持续时间
private List<Message> m_children; // 子消息列表
public DefaultTransaction(TraceContext ctx, String type, String name) {
super(type, name);
m_ctx = ctx;
// 记录开始时间(纳秒转微秒)
m_durationInMicros = System.nanoTime() / 1000L;
m_ctx.start(this); // 注册到上下文
}
/**
* 完成事务,计算持续时间
* 自动完成未完成的子事务
*/
@Override
public void complete() {
// 如果持续时间未设置,计算实际耗时
if (m_durationInMicros > 1e9) {
long end = System.nanoTime();
m_durationInMicros = end / 1000L - m_durationInMicros;
}
super.setCompleted();
// 自动完成未结束的子事务
if (m_children != null) {
for (Message child : m_children) {
if (!child.isCompleted() &&
child instanceof ForkableTransaction) {
child.complete();
}
}
}
m_ctx.end(this); // 从上下文注销
}
/**
* 添加子消息,构建调用树
*/
@Override
public DefaultTransaction addChild(Message message) {
if (m_children == null) {
m_children = new ArrayList<Message>();
}
if (message != null) {
m_children.add(message);
} else {
Cat.logError(new Exception("Null child message."));
}
return this;
}
@Override
public long getDurationInMillis() {
if (super.isCompleted()) {
return m_durationInMicros / 1000L;
} else {
return 0; // 事务未完成时返回0
}
}
}5.4 服务器配置管理
java
/**
* 服务器配置管理器
* 支持动态配置更新和本地文件回退
*/
@Named
public class ServerConfigManager implements LogEnabled, Initializable {
@Inject
private ConfigDao m_configDao;
@Inject
private ContentFetcher m_fetcher;
private volatile ServerConfig m_config; // 当前配置
private volatile Server m_server; // 当前服务器配置
/**
* 初始化配置,支持数据库和本地文件两种来源
*/
@Override
public void initialize() throws InitializationException {
try {
// 1. 优先从数据库加载配置
Config config = m_configDao.findByName(CONFIG_NAME,
ConfigEntity.READSET_FULL);
m_config = DefaultSaxParser.parse(config.getContent());
} catch (DalNotFoundException e) {
try {
// 2. 数据库不存在时从默认配置创建
String content = m_fetcher.getConfigContent(CONFIG_NAME);
m_config = DefaultSaxParser.parse(content);
} catch (Exception ex) {
// 3. 回退到本地文件
File localServerFile = new File(Cat.getCatHome(),
"server.xml");
initialize(localServerFile);
}
}
// 配置验证和服务器信息刷新
m_config.accept(new ServerConfigValidator());
refreshServer();
// 注册配置同步任务
TimerSyncTask.getInstance().register(new SyncHandler() {
@Override
public void handle() throws Exception {
refreshConfig(); // 定期检查配置更新
}
});
}
/**
* 动态刷新配置(热更新)
*/
private void refreshConfig() throws Exception {
Config config = m_configDao.findByName(CONFIG_NAME,
ConfigEntity.READSET_FULL);
long modifyTime = config.getModifyDate().getTime();
synchronized (this) {
if (modifyTime > m_modifyTime) {
// 配置有更新,重新加载
ServerConfig serverConfig =
DefaultSaxParser.parse(config.getContent());
serverConfig.accept(new ServerConfigValidator());
m_config = serverConfig;
m_modifyTime = modifyTime;
refreshServer(); // 刷新服务器配置
}
}
}
}技术对比与总结
与同类方案对比
| 特性 | CAT | Zipkin | SkyWalking |
|---|---|---|---|
| 实时性 | 秒级 | 分钟级 | 准实时 |
| 数据模型 | 四种模型 | 追踪为主 | 追踪+指标 |
| 存储策略 | 文件+HDFS | ES/Cassandra | ES/MySQL |
| 客户端支持 | 多语言完善 | 主流语言 | Java为主 |
| 部署复杂度 | 中等 | 较低 | 较高 |
| 数据完整性 | 全量统计 | 采样 | 采样+统计 |
核心优势总结
- 生产环境验证:在美团大规模业务中经过验证,稳定性有保障
- 实时性突出:秒级延迟满足快速故障响应需求
- 数据完整性:全量数据统计避免采样导致的误差
- 多语言生态:完善的多语言客户端支持
- 配置灵活性:支持动态配置更新和多种存储后端
适用建议
- 推荐使用场景:对实时性要求高、多语言技术栈、需要全量数据分析的大中型分布式系统
- 注意事项:CAT的部署和运维需要一定的技术储备,建议从非核心业务开始逐步接入
CAT作为美团开源的监控解决方案,在实时性、数据完整性和多语言支持方面具有明显优势,是构建企业级监控体系的可靠选择。其模块化设计和可扩展架构也为二次开发和定制化集成提供了良好基础。