主流中间件配置指南
RocketMQ:保障顺序与处理重试
RocketMQ的顺序消费和重试机制是其特色。
-
保证顺序消费 (关键配置)
-
生产者 :使用
MessageQueueSelector,通过Sharding Key(如订单ID)将同一组消息发往同一个队列。 -
消费者 :注册
MessageListenerOrderly监听器,RocketMQ会自动锁定队列并为每个队列分配单线程处理。
-
-
配置消息重试
-
生产者 :通过
setRetryTimesWhenSendFailed设置发送失败后的重试次数。 -
消费者 :在监听器中返回
RECONSUME_LATER或抛出异常,消息会自动重试。注意:顺序消息的失败重试会阻塞该队列,需尽快处理。
-
-
幂等处理建议
-
业务唯一标识:必须在消息中设置业务唯一Key(如订单号),这是实现幂等的基础。
-
消费端实现:结合数据库唯一键、Redis等方案实现去重。
-
Kafka:启用幂等与保持顺序
Kafka在生产者端提供了强大的"恰好一次"语义支持。
-
开启生产者幂等
-
核心配置 :设置
enable.idempotence=true(新版本生产者API默认开启)。这可以防止因生产者重试导致的重复。 -
协同配置 :为确保效果,建议同时设置
acks=all和max.in.flight.requests.per.connection不大于5。
-
-
保持分区顺序
-
基本原理 :Kafka仅保证分区内消息的顺序。
-
关键操作 :将需要保持顺序的消息指定相同的
key,它们会被路由到同一个分区。 -
重要限制 :若
enable.idempotence=false,则必须设置max.in.flight.requests.per.connection=1才能保序,但这会严重影响吞吐量。
-
-
注意事项
- Kafka的幂等仅针对生产者,消费端的幂等仍需业务方自己实现
RabbitMQ:利用特性实现保障
RabbitMQ本身不直接提供顺序或幂等保证,需通过其机制组合实现。
-
实现顺序消费
- 苛刻条件 :基本只能通过单一队列 + 单活消费者 (
x-single-active-consumer) 来保证。任何并行消费都会破坏顺序。
- 苛刻条件 :基本只能通过单一队列 + 单活消费者 (
-
配置消息重试
- 无内置重试 :需手动实现。常见做法是:消费失败后,拒绝消息 (
basic.nack) 并让其重新入队,或将其转发到死信交换机 (DLX),经过TTL延时后再投回业务队列。
- 无内置重试 :需手动实现。常见做法是:消费失败后,拒绝消息 (
-
幂等处理建议
- 与其他中间件一样,完全依赖消费端业务逻辑实现。
幂等校验:两种Redis实施步骤
无论使用哪种中间件,消费端的幂等校验逻辑是通用的。以下是基于Redis的两种主流方案。
方案一:Redis Set / 原子操作 (精准判断)
这是最常用、最可靠的方案,利用Redis的原子性确保并发安全。
-
核心原理 :消费前,用消息的唯一业务标识(如订单号)作为Key,尝试在Redis中设置一个状态标志 。利用
SETNX(或带选项的SET)命令的原子性,只有第一次操作会成功。 -
实施步骤:
-
生成唯一标识 :从消息体中解析出业务唯一ID(如
order_id:2025001)。 -
尝试占位 :执行Redis命令,例如
SET order_id:2025001 processing NX EX 3600。NX表示仅当Key不存在时设置成功,EX设置键的过期时间以防数据永久累积。 -
判断结果:
-
如果返回成功,说明是第一次处理,正常执行业务逻辑。
-
如果返回失败,说明该消息正在被处理或已处理过,直接丢弃或返回成功。
-
-
更新状态 (可选) :业务处理完成后,可将Key的值更新为
done或success,以便更细粒度的状态追踪。
-
-
代码示意 (Java Spring):
// 消息监听器中 String orderId = messageExt.getKeys(); // 获取业务唯一ID String redisKey = "order_msg:" + orderId; // 原子性尝试设置状态锁,有效期1小时 Boolean isFirstConsume = redisTemplate.opsForValue() .setIfAbsent(redisKey, "processing", Duration.ofHours(1)); if (Boolean.TRUE.equals(isFirstConsume)) { try { // 首次消费,执行业务逻辑... // 业务完成后,可选择更新状态 redisTemplate.opsForValue().set(redisKey, "done", Duration.ofHours(1)); } catch (Exception e) { // 业务异常,可选择删除Key,允许重试 redisTemplate.delete(redisKey); throw e; } } else { // 非首次消费,根据已有值判断是处理中还是已成功,直接响应消费成功 log.info("消息已处理或正在处理,直接确认。orderId: {}", orderId); }
方案二:布隆过滤器 (高效过滤,允许误判)
适用于海量数据、可以接受极低概率误判、且数据的历史集合相对稳定或可预热的场景(如拦截无效订单ID、过滤已读文章)。
-
核心原理 :布隆过滤器说"不存在"的元素一定不存在;说"存在"的元素可能存在(有极小的误判率)。它用多个哈希函数将元素映射到一个位数组中,空间效率极高。
-
实施步骤:
-
初始化过滤器 :根据预估的数据量
n和期望的误判率p,在Redis中创建布隆过滤器。可使用Redisson客户端的RBloomFilter。 -
预热数据 (关键) :系统启动时或异步地,将所有已处理过的历史业务ID添加到布隆过滤器中。
-
消费时判断:收到消息后,用业务ID查询布隆过滤器。
-
若返回 "不存在" ,则肯定没处理过 ,执行业务,并将该ID异步添加到过滤器。
-
若返回 "存在" ,则可能处理过 。由于有误判,通常需进一步查询更可靠的数据源(如数据库或方案一中的Redis Set)进行二次确认。如果二次确认未处理,再执行业务。
-
-
-
代码示意 (Redisson):
@Autowired private RBloomFilter<String> bloomFilter; // 1. 初始化(通常在配置类中完成) // bloomFilter.tryInit(1000000L, 0.001); // 预计元素100万,误判率0.1% // 2. 在消费逻辑中判断 String orderId = messageExt.getKeys(); if (!bloomFilter.contains(orderId)) { // 布隆过滤器说"不存在",则一定没处理过 // 执行业务逻辑... // 业务成功后,将该ID加入布隆过滤器 bloomFilter.add(orderId); } else { // 布隆过滤器说"存在",需二次确认 Boolean processed = redisTemplate.hasKey("order_msg:" + orderId); if (processed == null || !processed) { // 二次确认未处理,执行业务... } }关于自动扩容与追踪的补充
你之前还关心消息积压自动扩容和追踪问题,这里提供关键思路:
-
自动扩容核心 :本质是监控消费者延迟 (Consumer Lag) 。当延迟超过阈值(如你提到的单个队列积压1000条),通过K8s或云平台API自动增加同组消费者实例。对于Kafka,实例数不能超过分区数;对于RocketMQ,可动态增加消费线程数。
-
消息追踪排查 :无论是否入库,都应在消息生产时注入全局追踪ID (trace_id) ,并在所有环节(生产、Broker、消费、重试)的日志中打印。通过 ELK 或类似日志平台聚合,即可用
trace_id还原消息完整路径。
对于消息积压时的自动扩容,以及如何平衡重试、持久化与问题排查,确实是分布式系统设计中的难点。直接入库虽稳妥,但也可能引入性能瓶颈。下面我为你梳理了一套**"追踪-重试-扩容"**的综合方案。
顺序消费重试:入库与日志追踪的权衡
核心原则 :是否将重试消息持久化入库,取决于你对 "可靠性" 和 "可追溯性" 的要求级别
| 方案对比 | 核心机制 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 方案一:持久化入库 | 消费失败后,将消息内容、失败原因、重试次数等存入MySQL或MongoDB ,并设置状态字段(如 pending, retrying, failed)。 |
1. 状态可精确查询 ,便于人工干预与对账。 2. 数据不丢失,进程重启无影响。 | 1. 增加数据库压力 ,可能成为性能瓶颈。 2. 架构复杂度提升。 | 金融交易、核心订单等对数据一致性、可审计性要求极高的场景。 |
| 方案二:日志与消息队列追踪 | 不依赖外部数据库,利用消息队列自身+应用日志构建追踪链路。 | 1. 架构轻量 ,无额外依赖,性能好。 2. 伸缩性强。 | 1. 查询便利性较差,需组合工具。 2. 存在少量数据丢失风险(如日志未收集)。 | 实时推荐、日志处理、状态通知等允许微量数据丢失、追求高吞吐的场景。 |
-
方案二的关键实践:
-
植入全链路追踪ID :在消息生产时生成唯一
trace_id,并在所有处理环节(包括重试)透传,将trace_id打印到日志中。 -
结构化日志与聚合 :使用如 ELK(Elasticsearch, Logstash, Kibana) 或 Loki 收集日志,通过
trace_id可快速检索整条链路。 -
利用消息属性:将重试次数、首次失败时间等作为消息属性(如RocketMQ的UserProperty,Kafka的Header),随消息流动,便于监控系统直接读取。
-
智能弹性伸缩:应对消息积压
你提到的为积压Topic创建新队列的思路,本质上是一种动态分区扩容策略。更通用的自动化方案如下:
-
监控与触发器
-
核心监控指标:消费组延迟(Consumer Lag),即最新消息与当前消费位置之间的差距。
-
设置阈值:例如,单队列积压超过1000条,或总延迟超过10万条。
-
监控系统(如Prometheus)持续抓取指标,达到阈值时触发扩容动作。
-
-
执行扩容动作
-
场景1:队列数固定(如Kafka)
-
不支持运行时增加分区 :需提前预估并创建足够分区,通过增加消费者实例(
scale-out)来提升并发。例如,将消费者实例数提升至等于或小于分区总数。 -
支持动态扩容:部分框架或云服务(如Apache Pulsar)支持增加分区(或分片),随后再扩容消费者。
-
-
场景2:队列数不固定(如RabbitMQ)
-
可实现你设想的方案:自动创建新的"积压处理队列"(如
original_topic_backlog_01),并使用一个调度器(Dispatcher) 将积压的消息按一定规则(如取模)分批路由到新队列。新队列由独立的消费者组处理。 -
这本质上构建了一个两层消费系统,复杂度较高,需谨慎处理消息顺序和状态同步。、
-
缩容与稳定性
-
同样需要设置缩容阈值(如延迟小于1000条),并在缩容前等待消费者完成工作、提交偏移量,避免消息丢失。
-
为扩容操作增加冷却期(Cooldown),防止因指标波动导致集群频繁伸缩。
-
-
-
一个综合设计示例
假设一个使用 RocketMQ 处理订单状态流的场景,其架构设计如下:
这个系统的工作流程与关键设计:
-
消息生产与消费 :订单服务生产带
trace_id的消息。消费者组1的两个实例以顺序模式消费,并写入业务数据库。 -
重试与死信:失败消息进入重试Topic,按退避策略延迟重试。多次失败后进入死信Topic,由消费者组2进行告警和人工处理。
-
追踪与排查 :所有日志(含
trace_id)汇入ELK,通过Kibana可快速查询单条消息全链路。 -
弹性伸缩 :监控系统观测消费者延迟。当积压超过阈值(如单队列1000条),通过K8s或云平台自动增加消费者组1的Pod实例数,直至等于队列数(4个),以提升并发处理能力。
💡 关键实施建议
-
分级监控与告警:
-
延迟1-5分钟:配置告警,关注潜在风险。
-
延迟5-10分钟:触发低级别扩容,如增加消费者。
-
延迟>10分钟:触发高级别告警,并考虑增加队列/分区,同时需人工介入检查业务逻辑。
-
-
灰度与回滚:任何自动扩容/变更策略,都应先在小范围灰度,并具备快速回滚能力。
-
幂等性设计 :结合你的思路,在消费者端用 Redis Set (存储近期已处理
message_id)或布隆过滤器(应对海量历史判重)进行幂等判断,是比HashMap更合适的分布式方案。
布隆过滤说不存在就一定不存在我保持怀疑,如果redis冷热数据混乱犹豫redis过期策略配错会不会导致布隆过滤误判率提升
你提的这个问题非常关键,直接触及了布隆过滤器在工程实践中的一个核心挑战:"不存在则一定不存在"的特性,高度依赖于其底层位数组状态的完整性和一致性。你的怀疑完全正确,如果作为存储后端的Redis出现数据混乱或配置问题,确实会直接破坏这一核心保证。
下面我们来具体分析这个风险,并探讨如何在实践中规避。
核心:布隆过滤器的"不误判"依赖什么?
布隆过滤器说"元素不存在"的依据是:通过多个哈希函数计算出的位数组下标,至少有一位是0。
这要成立,必须满足一个致命前提 :所有已添加元素对应的那些位,在查询时都依然保持为1,没有被其他因素意外地改回0。
Redis过期与误判率风险分析
当你使用Redis(如Redisson的RBloomFilter)作为布隆过滤器的存储后端时,确实存在以下风险:
-
布隆过滤器键本身的过期或逐出:
-
如果你为布隆过滤器在Redis中的键设置了过期时间(TTL),那么当整个键过期被删除后,所有位数组信息将全部丢失 。此时,任何查询都会返回"不存在",即使这个元素曾被添加过。这已经不是误判率提升,而是功能完全失效。
-
即使未设置TTL,在Redis内存不足时,如果布隆过滤器的键被
allkeys-lru等逐出策略选中,结果同样致命。
-
-
底层位数组的数据混乱(可能性较低但更棘手):
-
场景:假设Redis中其他键的操作错误地覆盖了存储布隆过滤器位数组的内存区域。
-
后果 :部分位可能从1被错误地写为0,导致"应该存在"的元素被判断为"不存在",破坏了"不误判"的根本保证。虽然Redis内部管理机制使此概率极低,但在极端故障(如Redis bug、内存硬件故障)下不能完全排除。
-
-
我们更常用的Redis Set二次校验失效:
-
你担忧的"Redis冷热数据混乱"和"过期策略配错",在 "布隆过滤器+Redis Set"组合方案 中,风险点其实更多在作为最终裁决的Redis Set上。
-
错误配置示例 :如果用于二次校验的Redis Set键设置了过短的TTL,一个已处理但刚过期的订单ID,会先在布隆过滤器被判"可能存在",再在Redis Set被判"不存在",最终导致重复处理。此时,问题根源是二次校验失效,而非布隆过滤器误判。
-
如何规避风险与实施建议
为了确保幂等判断的绝对可靠,特别是对于金融、交易等核心场景,请遵循以下实践:
-
保证布隆过滤器数据的永久性
-
绝不设置TTL :存储布隆过滤器位数组的Redis键必须设置为永久键。
-
内存保障 :为Redis配置足够的
maxmemory,并为布隆过滤器键设置noeviction策略或使用volatile-lru时确保其有足够长的过期时间(实践中通常直接不设过期),防止被逐出。 -
数据备份:定期对Redis进行RDB或AOF持久化,并在必要时建立主从复制,防止单点数据丢失。
-
-
实施可靠的二次确认(必须环节)
-
如之前所述,永远不要单独依赖布隆过滤器做出"存在"的最终判断 。其"可能存在"的结果,必须由一个可靠的数据源进行二次确认。
-
推荐流程 :
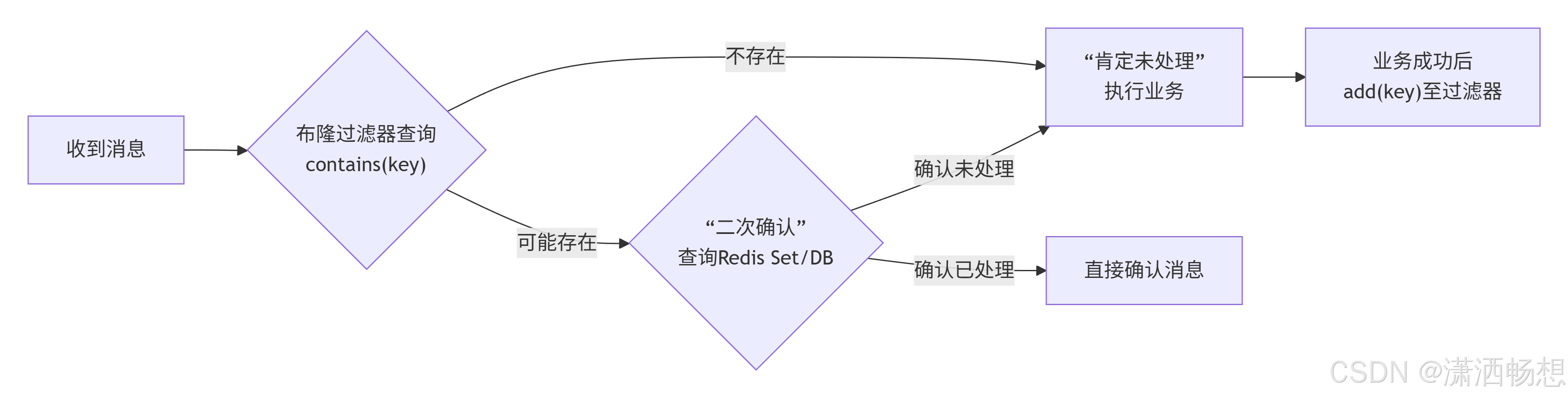
-
二次确认源选择:
- 首选数据库:业务主数据库的唯一约束是最可靠的裁决。查询性能可通过业务ID上的主键或唯一索引保障。
- 次选Redis Set/原子键:如果使用Redis,必须为其键设置远长于业务重复可能周期的TTL(例如,订单重复提交最长间隔为7天,TTL至少设为7+1天),并且监控内存使用,防止大面积Key同时过期引发雪崩。
-
-
设计预热与降级方案
-
冷启动预热 :系统发布或重启后,需要将最近一段时期内(如过去7天)所有已处理的业务ID,批量预热到布隆过滤器和Redis中。否则,新启动的系统会误将所有历史消息判为新消息。
-
降级策略 :当发现Redis连接超时或布隆过滤器功能异常时,应有熔断降级策略,例如直接退化为纯数据库查询方案,牺牲部分性能保证正确性。
-
总结来说,你的怀疑提醒了我们:布隆过滤器的理论特性,依赖于一个稳定的存储后端。在分布式系统中,没有"银弹"。 正确的做法是:
-
将布隆过滤器定位为一个前置的、高效的"过滤器"或"缓存",它负责快速排除掉"绝对的新消息"。
-
将数据库的唯一性约束 或一个精心维护的Redis Set ,作为最终判定的"裁判"。
-
为整个链路设计完备的监控 (如布隆过滤器的误判率、Redis Key的过期情况、二次确认的查询量)和降级方案。
面向两种中间件的幂等与Redis策略
首先,我们必须明确一个核心原则:布隆过滤器是高性能的"侦察兵",用于快速排除"绝对的新请求";而Redis(或数据库)是最终的"法官",做确定性裁决。 下图清晰展示了这条协作防线: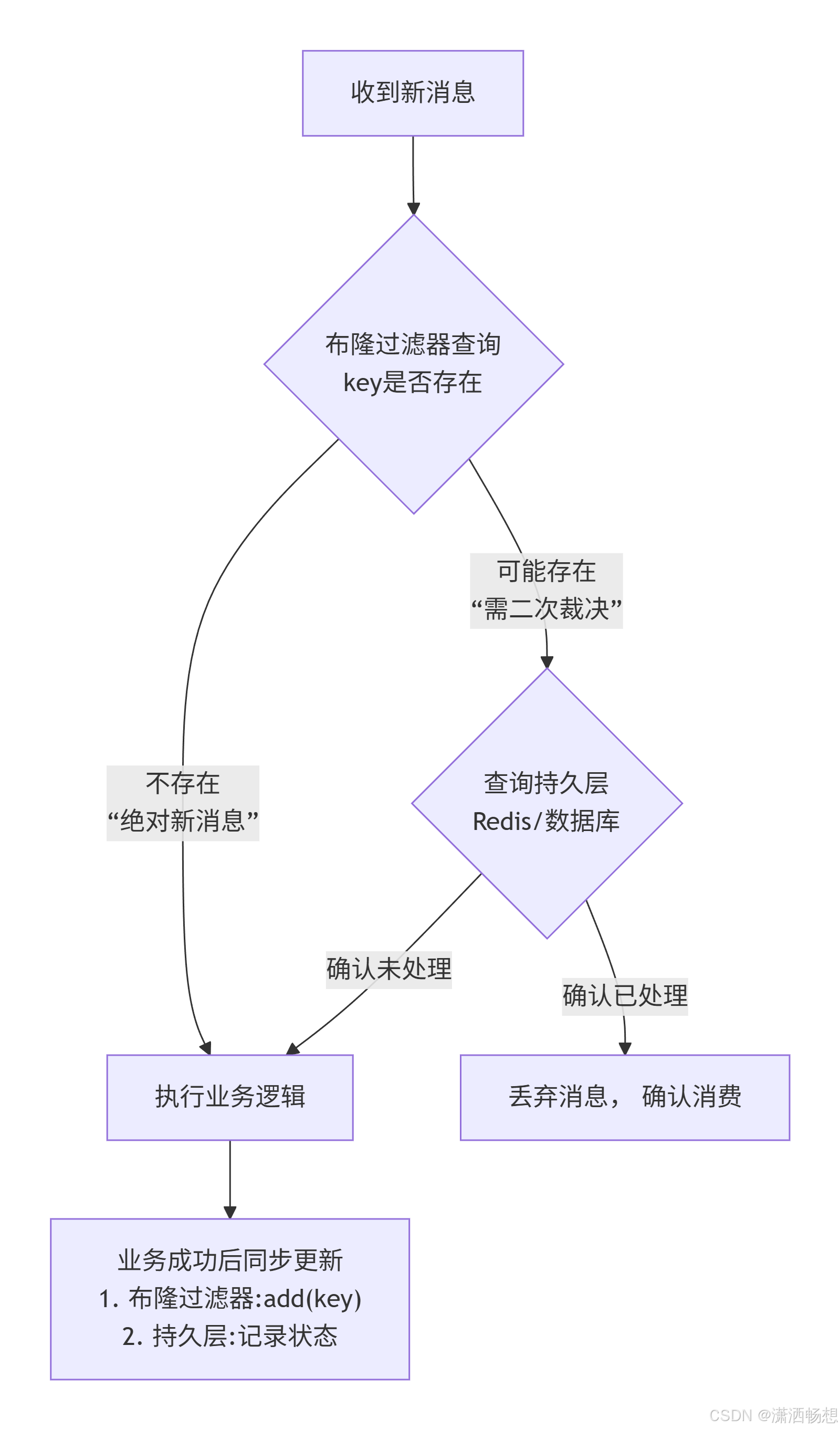
基于以上架构,我们针对不同存储的配置策略如下:
1. Redis冷热数据过期策略设置
你的担忧点正在于此,需对两类数据区别对待:
| 数据角色 | Redis 键类型 | 过期策略核心要点 | 错误配置风险 |
|---|---|---|---|
| 布隆过滤器 (BF) | 1个键,存储位数组 | 必须永久保存,绝不设置TTL。 配置 maxmemory-policy 为 noeviction 或保证内存充足不被逐出。 |
键过期或逐出将导致过滤器完全失效,所有查询返回"不存在",引发大规模重复消费。 |
| 业务状态键 (二次确认) | 大量键,如 msg_id:{orderId} |
设置基于业务逻辑的合理TTL。 例如,订单完成状态保存7天(EX 604800)。需监控Key数量与内存。 |
TTL过短:状态提前丢失,二次确认误判,导致重复。 TTL过长:内存快速增长,可能引发OOM。 |
操作建议 :在生产环境中,布隆过滤器(如使用Redisson的 RBloomFilter)初始化后,应通过 config set 命令或配置文件,确保其键为持久化。业务状态键的TTL则应作为可动态调整的应用配置。
2. RabbitMQ与RocketMQ的幂等实施重点
两者都需在消费者端实现幂等,但因特性不同,侧重点有异:
-
RabbitMQ:
-
挑战:无重试队列,需手动NACK或投递DLX。任何重试都可能带来无序和重复。
-
实施关键 :在消费逻辑的入口 立即进行幂等校验。由于消息可能因NACK而重新入队,必须保证"校验"和"业务处理完成"之间的原子性(例如,在同一个数据库事务中完成状态查询和更新)。
-
-
RocketMQ:
-
优势 :有清晰的重试/死信队列机制,消息属性(UserProperty)可携带
trace_id和重试次数。 -
实施关键 :除了通用幂等,应利用
MessageExt.getReconsumeTimes()获取重试次数。在高重试次数时,可以触发告警或直接送入死信队列人工处理
-
异常监控与处理代码深入
监控的核心是可观测性:记录日志、收集指标、设置告警。
1. 代码层面:注入Trace与捕获异常
以下是一个融合了关键实践的Spring Boot + RocketMQ监听器示例:
@Component
@RocketMQMessageListener(topic = "ORDER_TOPIC",
consumerGroup = "ORDER_CONSUMER_GROUP",
consumeMode = ConsumeMode.ORDERLY) // RocketMQ顺序消费
public class OrderMessageListener implements RocketMQListener<MessageExt> {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private RBloomFilter<String> orderIdBloomFilter; // Redisson布隆过滤器
@Autowired
private OrderService orderService;
private static final Logger logger = LoggerFactory.getLogger(OrderMessageListener.class);
private static final MeterRegistry meterRegistry = new SimpleMeterRegistry(); // 指标注册
@Override
public void onMessage(MessageExt message) {
// 1. 提取追踪信息与业务ID
String traceId = message.getUserProperty("trace_id");
String orderId = message.getKeys(); // 假设业务ID放在keys字段
int reconsumeTimes = message.getReconsumeTimes();
// 2. 使用MDC或类似机制将traceId注入日志上下文,便于聚合查询
MDC.put("traceId", traceId);
Timer.Sample sample = Timer.start(meterRegistry); // 开始计时
try {
logger.info("开始消费消息。orderId:{}, 重试次数:{}", orderId, reconsumeTimes);
// 3. 【核心】幂等校验防线
if (!isIdempotent(orderId, traceId)) {
logger.warn("消息已处理,直接确认。orderId:{}", orderId);
meterRegistry.counter("message.duplicate").increment(); // 记录重复指标
return;
}
// 4. 业务逻辑
orderService.processOrder(orderId);
// 5. 记录成功指标
sample.stop(Timer.builder("message.consumption.time")
.register(meterRegistry));
logger.info("消息消费成功。orderId:{}", orderId);
} catch (BusinessException e) {
// 6. 明确业务异常(如库存不足):记录日志,触发告警,根据策略决定是否重试
logger.error("消费失败,业务异常。orderId:{}, error:{}", orderId, e.getMessage());
meterRegistry.counter("message.consumption.failure", "type", "business").increment();
// 可根据异常类型决定是否重试,这里抛出异常让RocketMQ负责重试
throw new RuntimeException("业务处理失败", e);
} catch (RedisConnectionFailureException e) {
// 7. Redis连接异常:触发熔断降级,可能转由数据库进行幂等校验
logger.error("缓存服务异常,降级处理。orderId:{}, error:{}", orderId, e.getMessage());
meterRegistry.counter("message.consumption.failure", "type", "infrastructure").increment();
// 调用降级服务,可能性能下降但保证正确性
fallbackIdempotentCheckAndProcess(orderId);
} catch (Exception e) {
// 8. 其他未知异常
logger.error("消费失败,系统异常。orderId:{}", orderId, e);
meterRegistry.counter("message.consumption.failure", "type", "system").increment();
throw new RuntimeException("系统处理失败", e);
} finally {
MDC.clear(); // 清理日志上下文
}
}
private boolean isIdempotent(String orderId, String traceId) {
// 防线1:布隆过滤器快速过滤
if (orderIdBloomFilter.contains(orderId)) {
// 防线2:Redis精确二次确认
String statusKey = "order:status:" + orderId;
String status = redisTemplate.opsForValue().get(statusKey);
// 状态存在且为成功,则判定为重复
return !(status != null && "SUCCESS".equals(status));
}
// 布隆过滤器判断为"绝对不存在",是全新消息
return true;
}
private void fallbackIdempotentCheckAndProcess(String orderId) {
// 降级方案:直接绕过Redis,通过数据库唯一约束或查询实现幂等和业务处理
// 这里直接调用一个内置了数据库幂等判断的服务方法
orderService.processOrderWithDbIdempotence(orderId);
}
}2. 监控与告警配置要点
将代码中的指标(如 message.duplicate, message.consumption.failure)暴露给Prometheus,并在Grafana中配置面板和告警。
-
关键监控面板:
-
消息吞吐与延迟:各Topic的消费速度、消费组延迟(RocketMQ控制台可看)。
-
幂等拦截率 :
message.duplicate计数器增长情况,突增可能意味着重试风暴或上游Bug。 -
异常比例 :
message.consumption.failure按类型的分布,重点关注infrastructure(基础设施)类型。 -
Redis健康度:连接数、内存使用率、布隆过滤器Key是否存在。
-
-
关键告警规则:
-
消费延迟告警 :
消费延迟 > 1000持续5分钟,触发扩容或人工检查。 -
重复率突增告警 :
重复消息数 / 总消费数 > 10%,可能业务逻辑或上游有问题。 -
基础设施异常告警 :
基础设施类消费失败 > 每分钟10次,触发Redis或数据库健康检查。 -
布隆过滤器Key丢失告警 :通过定时任务检查
EXISTS布隆过滤器Key,丢失则发送最高级别告警。
-
总结与最终建议
对于你的技术栈组合,我的核心建议是:
-
分而治之:
-
对 RabbitMQ ,因其机制较"原始",请将重心放在消费端逻辑的强壮性上,幂等校验务必与业务操作在同一事务内。
-
对 RocketMQ ,因其功能完善,请充分利用其内置的重试/死信机制 和消息属性,将监控和治理(如重试次数)作为重点。
-
-
明确存储职责:
-
布隆过滤器 :一个只增不减的永久位图,仅用于加速否定判断。
-
Redis业务键 :带合理TTL的临时状态缓存,作为二次确认的快速通道。
-
业务数据库 :最终裁决与持久化的唯一真相源,所有争议以它为准。
-
-
监控驱动运维:
-
将代码中埋点的指标,通过 Prometheus + Grafana 形成可视化大盘和告警规则。
-
特别关注 "布隆过滤器Key丢失" 和 "Redis连接异常" 这两类基础设施告警,它们直接威胁系统的正确性。
-
如果你的团队在Spring Cloud体系内,可以进一步考虑集成Sentinel对消费者进行熔断降级,或使用Sleuth/Zipkin增强链路追踪。