在数字化浪潮下,企业数据架构正朝着多云化、分布式、异构化方向高速演进。从业务系统的碎片化数据采集,到跨区域的大规模数据处理,再到核心业务的高可用调度,传统调度工具逐渐暴露出触发方式僵化、依赖管理薄弱、多云兼容不足、部署灵活度欠缺等痛点。
作为数新智能 CyberData 产品的调度引擎, CyberScheduler 以"全场景适配、全链路可控、全架构兼容"为设计理念,从触发机制、依赖管理、统一编排、部署能力到高可用架构,构建了一套覆盖企业数据调度全生命周期的解决方案。今天,我将从技术本质出发,带大家深度拆解 CyberScheduler 的核心能力。
多维度触发机制
适配全场景任务启动需求
数据调度的第一步,是让任务在"正确的时间、正确的场景"下精准启动。 CyberScheduler 基于企业多样化的业务场景,设计了覆盖周期调度、手动触发、API 集成的全维度触发体系,彻底打破传统调度"单一启动方式"的局限。
1. 周期调度:自动化任务的核心基石
针对需要重复执行的常规任务,CyberScheduler 提供两类周期调度能力:
· 周期调度任务:支持平台定时周期触发(如每日凌晨00:05执行的ETL任务),也可通过外部事件API触发(如第三方系统数据同步完成后主动调用),适配"固定周期"与"事件驱动周期"两类场景;
· 周期调度文件夹:支持对批量任务进行文件夹级别的统一周期调度,无需逐个配置,大幅提升批量任务的管理效率,尤其适用于按业务域划分的任务集群。
2. 灵活触发:满足应急与集成需求
面对非周期类任务,CyberScheduler 提供灵活的触发方式:
· 触发调度任务:支持平台页面手动运行(如不定期运行、测试验证、紧急数据补跑等场景),也可通过API调用触发(如业务系统触发的数据处理任务);
· 触发调度任务工作流:支持通过API直接触发整个工作流及下属所有任务的运行,适配复杂业务链路的一键启动场景,大幅提升跨系统集成效率。
多维度的触发机制,让 CyberScheduler 既能支撑自动化的常规任务,也能响应应急处理、跨系统集成等灵活需求,真正实现"场景无死角"。
精细化依赖管理
构建可靠的任务执行链路
在复杂数据链路中,任务间的依赖关系直接决定了调度的准确性与稳定性。CyberScheduler 支持7类核心依赖关系,并通过严格的成环校验机制,确保任务链路"可预期、无死锁"。
1. 全场景依赖覆盖
针对企业数据任务的复杂关联场景,CyberScheduler 提供全面的依赖支持:
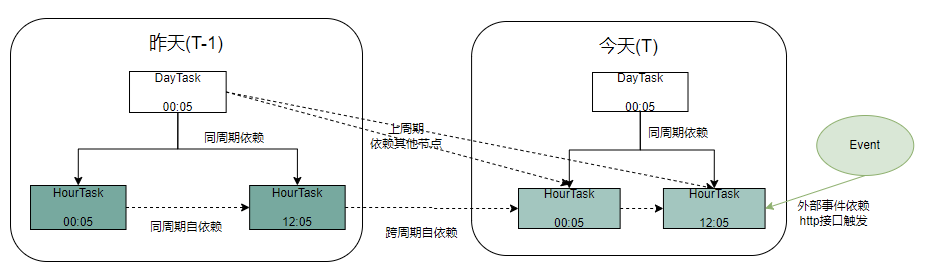
· 同周期依赖:同一调度周期内的任务关联(如A任务执行完成后再启动B任务);
· 自依赖:任务依赖自身上一周期的执行结果(如每日累计数据统计任务);
· 跨周期依赖:依赖上一周期其他节点的执行结果(如本周数据汇总依赖上周数据归档);
· 跨环境依赖:不同部署环境下的任务关联(如测试环境任务依赖生产环境的基础数据);
· 外部数据依赖:依赖外部数据源的就绪状态(如数据文件上传完成、数据库表更新);
· 外部事件触发依赖/任务实例回调:通过外部事件或任务执行结果回调触发(如支付完成事件触发对账任务);
· 文件夹依赖:文件夹级别的批量依赖管理(如文件夹A中所有任务完成后,启动文件夹B的任务)。
2. 成环校验:从源头规避风险
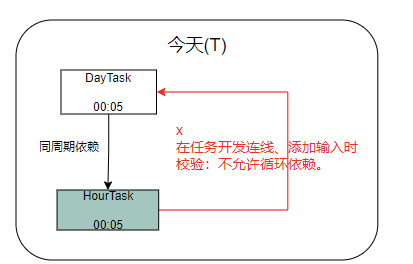
依赖关系的复杂性容易导致循环依赖(如A依赖B、B依赖C、C依赖A),进而造成任务死锁。CyberScheduler 在任务开发阶段(连线配置、添加输入时)即启动自动校验,严格禁止循环依赖的产生,从源头保障调度链路的顺畅执行,避免因依赖问题导致的任务阻塞。
精细化的依赖管理,让 CyberScheduler 能够支撑复杂业务场景下的任务编排,确保数据处理链路的有序、可靠。
多云多引擎统一编排
打破数据调度的碎片化壁垒
当前,企业采用多云(阿里云、华为云、谷歌云、AWS云、私有云等)和多计算引擎(Spark、Flink、Doris、ClickHouse、MaxCompute等)架构已成常态,但不同云厂商、不同引擎的调度工具碎片化,导致数据管理效率低下、运维成本高企。
CyberScheduler 的核心突破之一,就是实现了"多云+多计算引擎"的统一编排与调度:
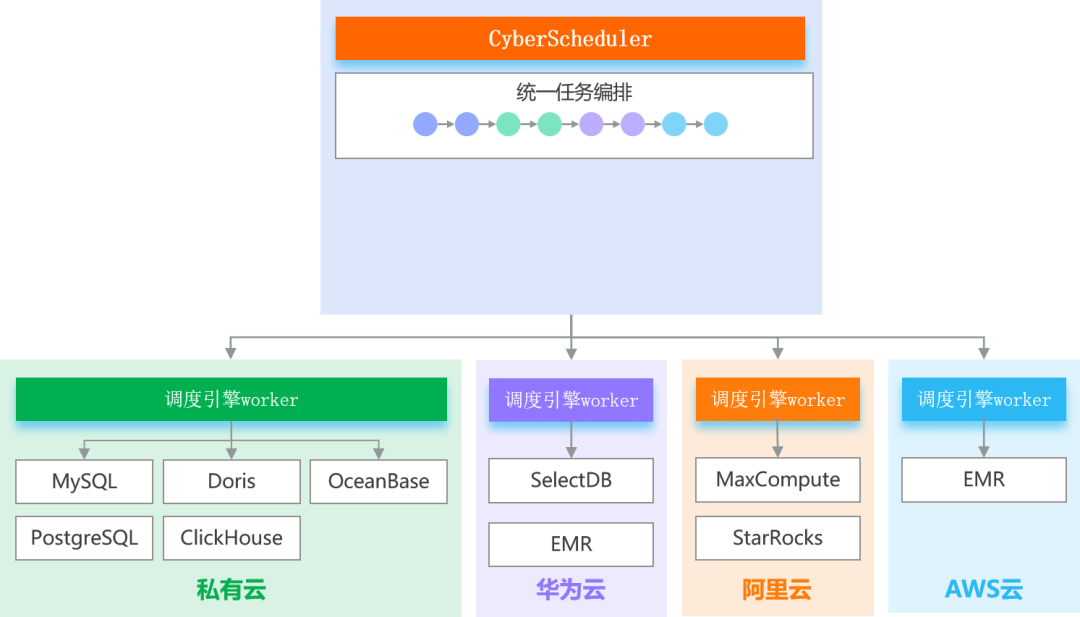
· 跨云兼容:无缝适配公有云(阿里云、华为云、谷歌云、AWS云等)、私有云等多种部署环境,无需针对不同云环境开发专属调度方案;
· 多引擎适配:全面兼容 Spark、Flink、Presto、Doris、ClickHouse 等主流计算引擎,以及MySQL、OceanBase、PostgreSQL 等数据库,实现异构引擎的统一调度;
· 统一管理:通过调度引擎 Worker 集群,对分布在不同云、不同引擎上的任务进行集中编排,实现多地域大数据集群的统一数据管理与编排,打破"数据孤岛"与"调度孤岛"。
这种统一编排能力,让企业无需重构现有IT架构,即可实现全环境、全引擎的调度协同,大幅降低运维复杂度,提升数据流转效率。
灵活可演进部署
适配企业多样化IT架构
不同企业的IT架构、数据分布、合规要求存在显著差异,单一的部署模式无法满足所有需求。CyberScheduler 提供四种灵活的部署架构,可根据企业实际场景按需选择:
1. 开发、生产共用集群
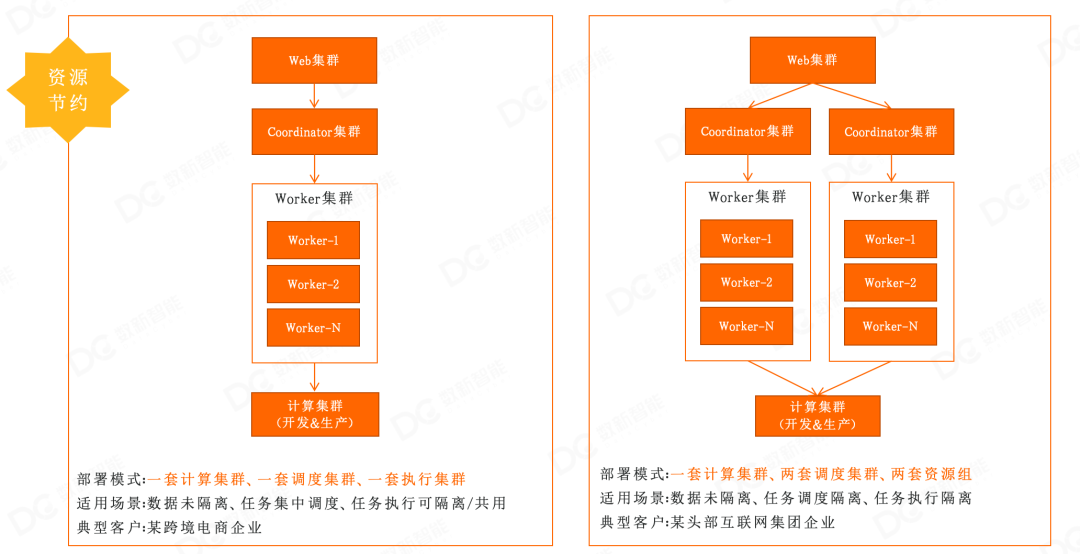
2. 开发生产集群隔离
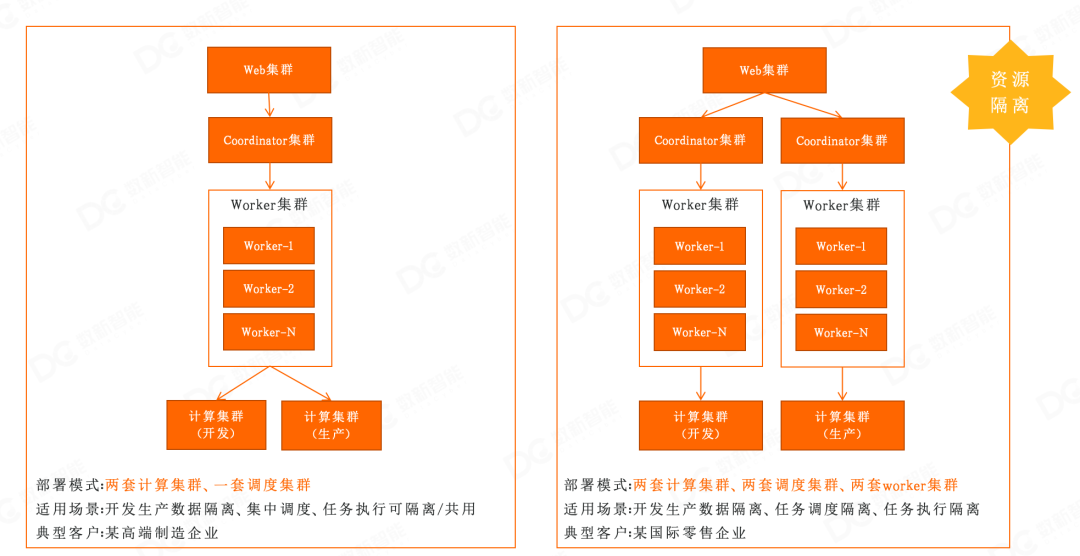
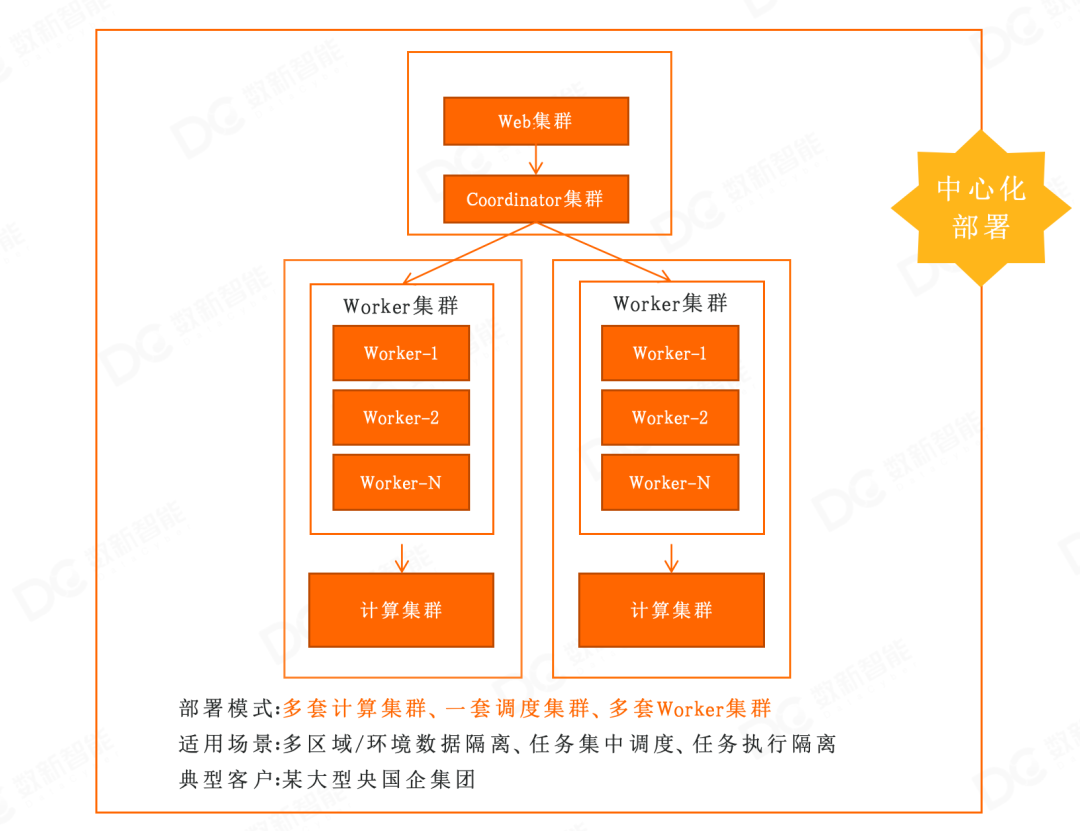
3. 跨区域中心化调度
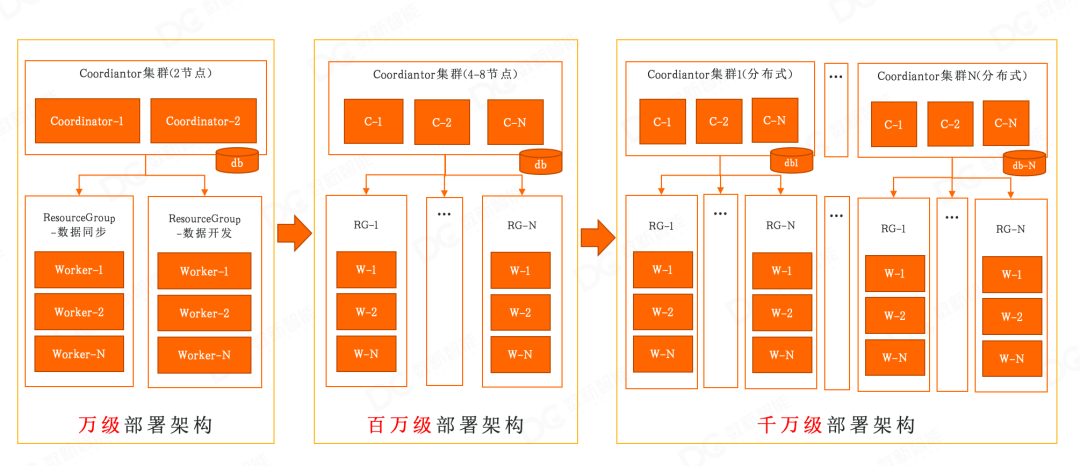
4. 可演进部署架构
四种部署模式的灵活适配,让 CyberScheduler 能够无缝融入企业现有IT架构,无论是集中式还是分布式部署,都能提供稳定高效的调度能力,降低企业的迁移与适配成本。
隔离式高可用架构
保障核心业务不中断
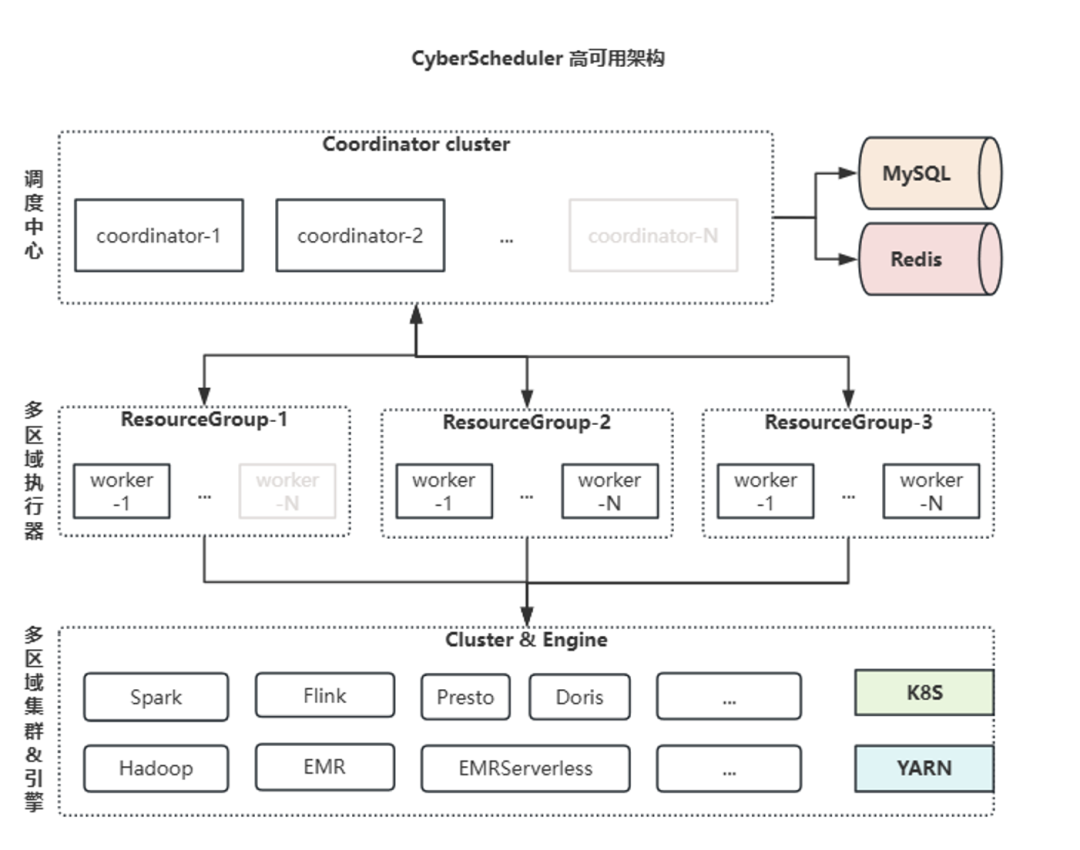
对于企业核心业务而言,调度系统的稳定性直接决定了数据服务的连续性。CyberScheduler 采用"环境隔离+资源隔离+集群化部署"的高可用架构,从根本上保障调度服务的稳定可靠。
1. 双重隔离机制:规避交叉影响
· 环境隔离:支持自定义选择DEV、UAT、SIT、PROD等多环境,不同环境的任务独立运行,避免测试任务影响生产环境的稳定性;
· 资源隔离:通过资源组划分,为不同区域、不同业务、不同优先级的任务分配专属资源,确保核心业务任务不会因非核心任务抢占资源而延迟,保障关键链路的SLA达标。
2. 服务集群化:保障系统高可用
· 调度中心集群化:采用多 Coordinator 节点集群部署,配合 MySQL 存储元数据、Redis保障缓存高可用,实现调度中心的无单点故障;
· 自动化故障转移:支持故障自动转移与任务实例失败重试,进一步提升架构容错能力;
· 多区域执行器:Worker 节点按区域分布式部署,各区域内 Worker 集群化部署避免单点故障,区域之间worker相互隔离、互不影响,确保跨区域任务工作流的连续性;
· 全引擎兼容:适配K8S、YARN、EMR、EMR Serverless等多种运行环境,以及Flink、Spark、Presto 等计算引擎;
这种高可用架构,能够满足企业级核心业务的稳定性要求,即使面对硬件故障、环境波动等突发情况,也能保障调度服务不中断、数据任务正常执行。
技术赋能业务
核心价值与未来展望
在数字化转型的深水区,数据已成为企业的核心资产,而调度引擎则是数据流转的"中枢神经"。CyberScheduler 通过技术创新,让数据调度从"被动适配"走向"主动赋能",帮助企业实现数据价值的高效释放。
未来,我们将继续深耕多云融合、智能调度等技术方向,引入AI驱动的任务优先级动态调整、故障智能预测与自愈等能力,让调度系统更智能、更高效、更可靠。数新智能也将持续以技术创新为核心,为企业数字化转型提供更强大的底层支撑,与客户共同探索数据价值的无限可能。