JVM
虚拟机的结构
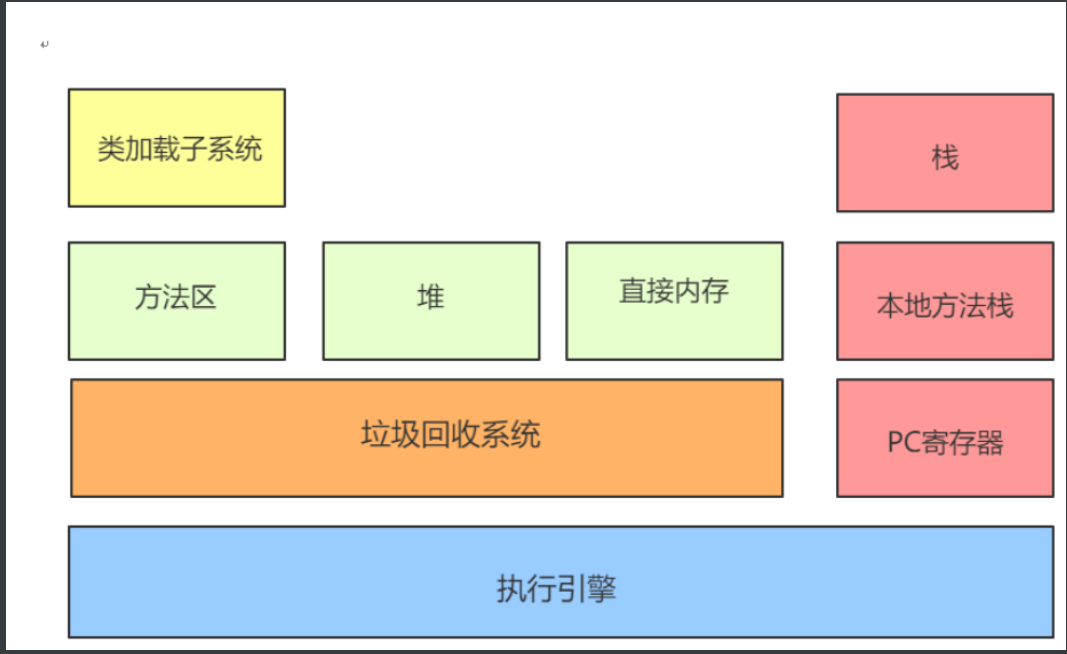
1.类加载子系统 (Class Loader Subsystem)
对应图中左上角的黄色方框。
- 功能 :负责从文件系统或网络中加载
.class文件。 - 过程 :它不负责运行,只负责加载、连接(验证、准备、解析)和初始化。加载后的类信息会存放于"方法区"中。
- 运行时数据区 (Runtime Data Areas)
这是 JVM 的内存部分,也是面试最常问的地方。根据图中颜色和分布,我们可以分为两类:
A. 线程共享区域(图中绿色部分)
- 方法区 (Method Area):存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等。
- 堆 (Heap) :JVM 管理的最大一块内存,几乎所有的对象实例都在这里分配内存。这是垃圾回收(GC)发生的主要阵地。
- 直接内存 (Direct Memory):图中特意标注了这一块。它不属于 JVM 运行时数据区的一部分,而是通过 NIO 使用 Native 函数库直接分配的堆外内存,常用于提高 I/O 性能。
B. 线程私有区域(图中红色部分)
- 栈 (Stack / VM Stack):每个方法执行时都会创建一个"栈帧",存放局部变量表、操作数栈、动态链接等。方法执行完即出栈。
- 本地方法栈 (Native Method Stack) :与虚拟机栈类似,但它是为 JVM 使用到的 Native 方法(如 C/C++ 编写的底层代码)服务的。
- PC 寄存器 (Program Counter Register) :保存当前线程执行的字节码的行号指示器。它是唯一一个在 Java 虚拟机规范中没有规定任何
OutOfMemoryError情况的区域。
- 执行引擎 (Execution Engine)
对应图中底部的蓝色长方框。
- 功能 :字节码本身不能直接被操作系统执行。执行引擎负责将字节码指令 解释或编译成底层的本地机器码。
- 组件:通常包含解释器(Interpreter)、即时编译器(JIT Compiler)和分析器。
- 垃圾回收系统 (Garbage Collection System)
对应图中橙色部分。
- 功能:这是 Java 自动内存管理的核心。它会自动识别"堆"和"方法区"中不再被使用的对象,并释放其占用的内存空间。
- 关联:图中它横跨在内存区域之上,说明它会持续监控堆内存状态,并在合适的时机触发回收。
什么是JVM
JDK、JRE、JVM、JNI
结构关系
JDK** > JRE > JVM (JNI 则是连接 Java 与 Native 代码的桥梁)
JDK(Java开发工具包)
├── JRE(Java运行时环境)
│ ├── JVM(Java虚拟机,核心执行层)
│ └── 核心类库(java.lang、java.util等,运行程序的基础)
└── 开发工具集(javac、javadoc、jdb、jar等,开发/编译/调试用)
概念讲解
JVM (Java Virtual Machine) ------ Java 虚拟机
- 功能:JVM 是 Java 跨平台的核心。它负责将字节码(.class 文件)解释或编译成机器码,并在不同的操作系统上运行。
- 特点:JVM 是"虚"的计算机,它屏蔽了底层操作系统的差异。
JRE (Java Runtime Environment) ------ Java 运行时环境
- 包含 :JVM + Java 核心类库 (如
java.lang,java.util等)。 - 功能 :如果你只需要运行已经开发好的 Java 程序,安装 JRE 就足够了。它不包含任何开发工具(如编译器)。
JDK (Java Development Kit) ------ Java 开发工具包
- 包含 :JRE + 开发工具 (如
javac编译器、jdb调试器、jstat等诊断工具)。 - 功能 :它是给开发者准备的。如果你要编写、编译 Java 代码,必须安装 JDK。
JNI (Java Native Interface) ------ Java 本地接口
- 定义:JNI 是一种编程框架,允许运行在 JVM 上的 Java 代码与其他语言(如 C、C++)编写的应用或库进行交互。
- 功能 :
- 性能提升:在对性能要求极高的场景下调用 C/C++。
- 底层交互:调用操作系统底层的驱动或特定库。
- 图中位置:JNI 位于执行引擎与外部本地库(Native Libraries)之间,对应你之前图片中"本地方法栈"所服务的对象。
他们之间的区别
| 特性 | JVM | JRE | JDK | JNI |
|---|---|---|---|---|
| 全称 | Java Virtual Machine | Java Runtime Environment | Java Development Kit | Java Native Interface |
| 主要用途 | 执行字节码 | 提供运行环境 | 提供开发与调试工具 | 实现 Java 与 C/C++ 互调 |
| 面向人群 | 它是内部核心,不直接面对用户 | 终端用户(仅需运行程序) | 开发者(需要编写代码) | 进阶开发者(需底层优化) |
| 包含关系 | 最底层 | 包含 JVM | 包含 JRE 和 JVM | 独立的通信接口规范 |
Java堆
堆不仅是内存占比最大的一块,也是垃圾回收(GC)发生的核心战场
- 什么是 Java 堆?
Java 堆是 JVM 所管理的内存中最大的一块,它在虚拟机启动时创建。
- 核心目的:存放对象实例。几乎所有的对象实例以及数组都在这里分配内存。
- 线程共享:堆是所有线程共享的内存区域,因此在分配内存时需要考虑同步机制(如 TLAB)。
- 管理机制:堆是垃圾收集器(GC)管理的主要区域,因此也被称为"GC 堆"。
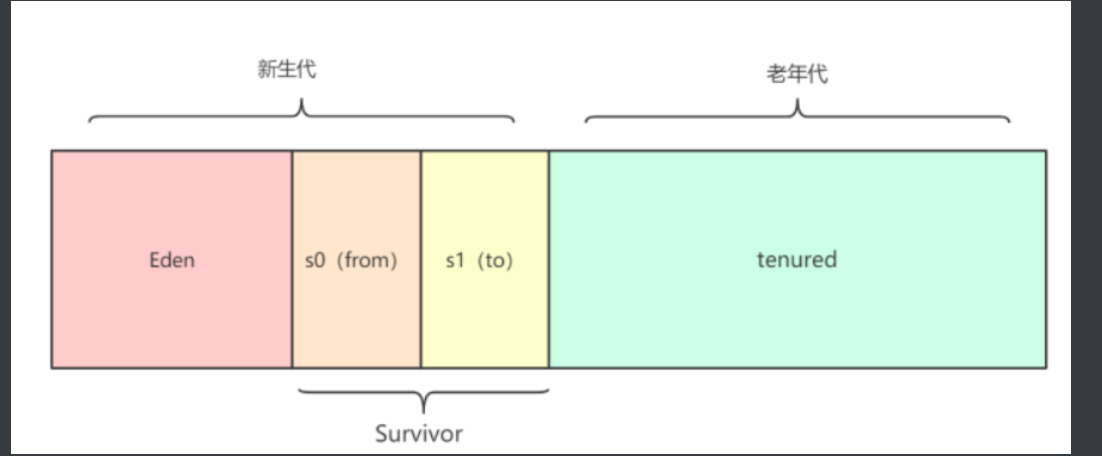
- 堆的内存布局(分代概念)
为了提高垃圾回收的效率,主流 JVM(如 HotSpot)将堆划分为不同的区域。传统的划分方式如下:
A. 新生代 (Young Generation)
新创建的对象通常先分配在这里。新生代又细分为三个部分:
- Eden 区:大部分对象出生的地带。
- Survivor 0 (S0/From) 和 Survivor 1 (S1/To):用于存放经过一次 Minor GC 后依然存活的对象。
- 比例 :默认情况下
Eden : S0 : S1 = 8 : 1 : 1。
B. 老年代 (Old Generation)
- 存放生命周期较长的对象(如大对象、长期存活的对象)。
- 当对象在新生代经历过多次(默认 15 次)GC 依然存活时,会晋升到老年代。
注意: 在 JDK 8 以后,原有的"永久代(Permanent Generation)"已被**元空间(Metaspace)**取代,且元空间使用的是本地内存(堆外内存),不再占用 JVM 堆内存。
-
对象在堆中的生命周期
-
诞生 :新对象在 Eden 区被创建。
-
存活 :当 Eden 区满时触发 Minor GC ,存活对象进入 S0。
-
交换 :下一次 Minor GC 时,Eden 和 S0 的存活对象会被复制到 S1,然后清空 Eden 和 S0。S0 和 S1 如此反复交换(标记-复制算法)。
-
晋升 :对象头中的"分代年龄"每经历一次 GC 就加 1。当达到阈值(通常为 15)后,进入老年代。
-
终结 :当老年代空间不足时,触发 Major GC 或 Full GC ;如果回收后依然无法存放新对象,则抛出
OutOfMemoryError: Java heap space。
堆相关的面试高频点
- 为什么要分代?
- 效率! 绝大多数对象都是"朝生夕死"的。通过分代,GC 可以只针对新生代进行频繁回收(Minor GC),而不需要每次都扫描整个堆,极大提升了性能。
- 什么是 TLAB (Thread Local Allocation Buffer)?
- 由于堆是共享的,多线程同时申请空间会产生竞争。JVM 在 Eden 区为每个线程预先分配了一块私有缓冲区(TLAB),对象优先在这里分配,从而避免了加锁,提高了分配效率。
常用参数:
-Xms:堆的起始内存大小。-Xmx:堆的最大内存大小。-Xmn:新生代的大小。-XX:NewRatio:老年代与新生代的比例。
栈、堆、方法区的关系
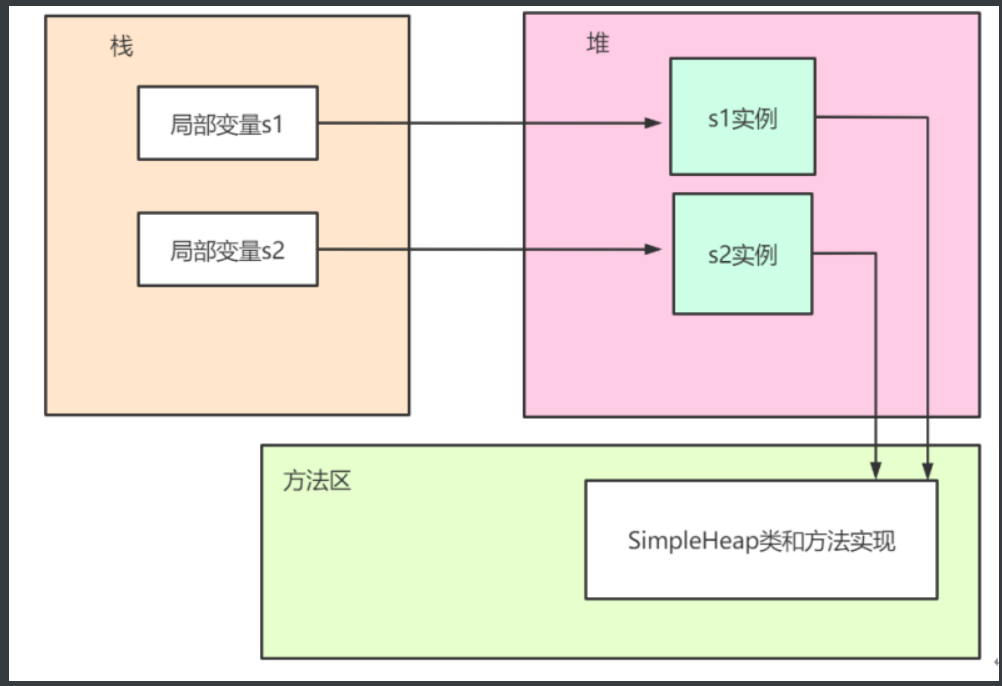
栈(Stack): 存放的是引用(Reference) 。当你声明 SimpleHeap s1 时,JVM 在当前线程栈的局部变量表中划出一块空间,记录这个变量名。
堆(Heap): 存放的是实例(Object Instance) 。当你执行 new SimpleHeap() 时,JVM 在堆中开辟内存,存放对象的属性数据(如成员变量的值)。
方法区(Method Area): 存放的是元数据(Metadata)。它保存了类的结构信息,包括类的名称、方法代码、常量池、静态变量等。
出入java栈
Java栈是一块线程私有的内存空间。如果说,Java堆和程序数据密切相关,那么Java栈就是和线程执行密切相关的。线程执行的基本行为是函数调用,每次函数调用的数据都是通过Java栈传递的。
Java栈只支持出栈和入栈两种操作。
栈帧
在Java栈中保存的主要内容为栈帧。每一次函数调用, 都会有一个对应的栈帧
被压入Java栈,每一个函数调用结束,都会有一个栈帧被弹出Java栈。
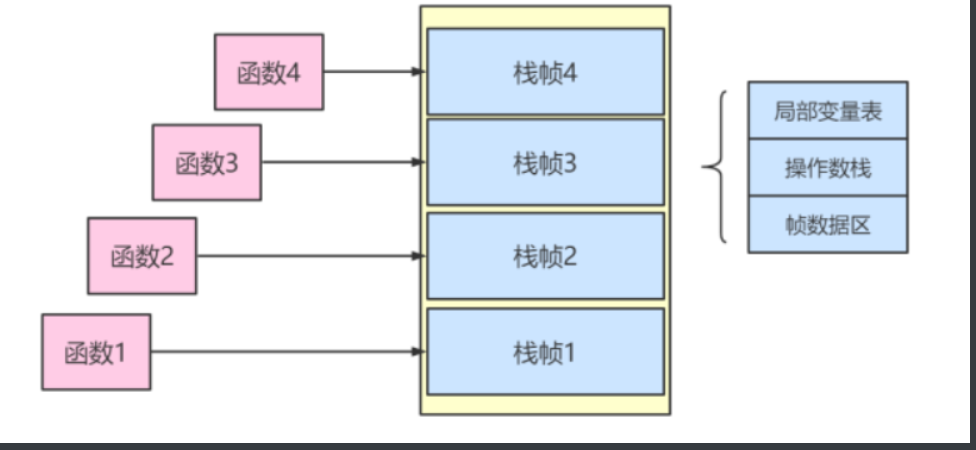
入栈(Push):函数的开启
当一个函数被调用时,系统会执行"入栈"操作。
- 过程描述 :
- 当函数 1 调用函数 2 时,栈帧 1 先入栈,紧接着 栈帧 2 入栈。
- 此时,栈帧 2 位于栈顶,它成为了当前帧(Current Frame)。
- 存储内容 :入栈的栈帧里保存了该函数运行所需的"全副武装",包括:
- 局部变量表:存方法里的参数和变量。
- 操作数栈:存放计算过程中的中间数据。
- 帧数据区:记录返回地址和常量池引用。
出栈(Pop):函数的结束
当函数执行完毕后,对应的栈帧就会从栈顶弹出,这个过程叫"出栈"。
- 触发方式 :
- 正常返回 :执行到
return指令,函数正常结束。 - 抛出异常:执行过程中遇到未捕获的异常,导致函数非正常退出。
- 正常返回 :执行到
- 结果:无论哪种方式,栈帧被弹出后,该函数占用的内存随之释放。此时,原本位于下方的栈帧重新回到栈顶,成为当前执行的函数。
栈溢出的真相(StackOverflowError)
由于 Java 栈的大小是有限的(可以通过 -Xss 参数指定),出入栈的平衡非常重要。
- 溢出场景:如果一个函数不断地调用自己(递归)且没有出口,就会有源源不断的栈帧被压入栈中。
- 后果 :当请求的栈深度大于最大可用深度时,弹夹塞满了,系统就会抛出
StackOverflowError。
"在 JVM 的世界里,堆(Heap)是静态的仓库,负责存放对象实体;而栈(Stack)是动态的流水线,通过不停的入栈与出栈驱动着程序的运行。
每一个方法的执行都对应着一个栈帧的起伏。理解了出入栈,你就理解了 Java 程序是如何在线程中'活'起来的。"
局部变量表
它是栈帧中最重要的组成部分之一,直接决定了函数执行时数据的存取效率。
局部变量表的本质
- 功能 :局部变量表是一组变量值存储空间,用于存放方法参数 和方法内部定义的局部变量。
- 存储单位 :以 变量槽(Slot) 为最小单位。
- 分配时机 :在编译期间,方法需要多大的局部变量表就已经确定,并写入
.class文件的 Code 属性中。
局部变量表存放的具体内容
局部变量表主要存放以下三类数据:
- 基本数据类型 :
- 包括
boolean、byte、char、short、int、float、long、double。 - 注意 :其中 64 位长度的
long和double类型会占用 2 个连续的变量槽,其余类型占用 1 个。
- 包括
- 对象引用 (Reference) :
- 并不直接存储对象本身,而是存储一个指向堆中对象起始地址的指针 (正如你提供的图片所示,栈中的
s1指向堆中的s1实例)。
- 并不直接存储对象本身,而是存储一个指向堆中对象起始地址的指针 (正如你提供的图片所示,栈中的
- 返回地址 (Return Address) :
- 指向了一条字节码指令的地址(现在较少见,通常由异常处理表替代)。
变量槽 (Slot) 的特殊规则
- this 引用 :如果执行的是非静态方法(实例方法),局部变量表中第 0 位索引的 Slot 默认是用于传递方法所属对象实例的引用,即代码中的 this。
- Slot 复用 :为了节省栈空间,如果一个变量已经超出了其作用域(比如在一个
if块内定义的变量执行完了),该变量所占用的 Slot 可以被后续定义的变量复用。
局部变量表与栈深度的"生死"关系
局部变量表的大小直接影响函数嵌套调用的深度(即 StackOverflowError 发生的快慢)。
- 空间占用 :局部变量表在栈帧中占据空间。函数的参数越多、局部变量越多,局部变量表就越膨胀。
- 因果链条 :局部变量表膨胀 →\rightarrow→ 单个栈帧占用空间变大 →\rightarrow→ 相同大小的栈(
-Xss指定)能容纳的栈帧数量减少 →\rightarrow→ 函数嵌套调用深度变浅。 - 实验结论 :在相同的
-Xss128k配置下,不含参数和变量的函数比含大量long型变量的函数拥有更深的调用层次。
变量槽 (Slot) 的存储规则与复用
局部变量表以"槽"为单位管理数据,具有独特的分配逻辑:
- 字长分配 :
long和double类型占用 2 个字(Slot)。int、short、byte、boolean、char、对象引用以及返回地址占用 1 个字(Slot)。
- 槽位复用机制 :
- 原理 :栈帧中的槽位是可以重复利用的。如果一个变量已经超过了它的作用域,此后声明的新局部变量就可以复用该变量的槽位。
- 意义:通过复用,可以缩小栈帧总体大小,变相节省内存并增加函数调用的潜在深度。
- 实例 :如
localvar2中,变量b复用了已失效变量a的槽位,总槽位数比不复用时少 1 个。
局部变量表对垃圾回收(GC)的影响
局部变量表中的变量是 GC Roots 的重要组成部分。一个对象能否被回收,不仅看它是否超过了作用域,还要看它的槽位是否被占用或清除。
| 场景 | 情况描述 | GC 结果 | 原因分析 |
|---|---|---|---|
| 场景 1 | 申请空间后立即 GC | 不回收 | 变量 a 仍在作用域内,持有强引用。 |
| 场景 2 | a = null 后 GC |
回收 | 强引用被手动切断。 |
| 场景 3 | 变量 a 离开作用域后 GC |
不回收 | 重点: 虽然 a 失效,但其槽位仍指向对象,未被其他变量复用,引用链仍在。 |
| 场景 4 | 离开作用域并定义新变量 c |
回收 | 新变量 c 复用了 a 的槽位,导致 a 的旧引用被覆盖销毁。 |
| 场景 5 | 方法返回后再 GC | 回收 | 方法返回意味着栈帧销毁,局部变量表随之消失,引用彻底断开。 |
操作数栈
操作数栈是 JVM中每个栈的核心组成部分,是方法执行过程中完成算术运算、方法调用的 "临时计算区",也是理解 JVM 字节码执行逻辑的关键。
- 操作数栈的本质:计算执行的"中转站"
- 定义 :操作数栈是栈帧内的一个后进先出(LIFO)的数据结构,主要用于保存计算过程的中间结果,并作为变量临时的存储空间。
- 职能:它是 JVM 执行引擎的工作区。几乎所有的计算指令(如加减乘除、对象字段读写)都是通过操作数栈来完成的。
- 特点:它不支持索引访问,只能通过入栈(Push)和出栈(Pop)来操作数据。
- 从字节码指令看数据流动
操作数栈与局部变量表紧密协作,通过特定的指令实现数据交互。你可以将指令分为以下几类:
- 装载(Load) :将局部变量表中的值压入操作数栈。如
iload(加载int)、aload(加载对象引用)。 - 存储(Store) :将操作数栈顶的值弹出并保存到局部变量表中。如
istore、astore。 - 计算(Invoke/Math) :
- 算术指令 :如
iadd。它会连续弹出栈顶两个元素,相加后将结果压回栈中。 - 字段指令 :如
getfield获取属性值入栈,putfield弹出栈顶值赋给属性。 - 方法调用 :如
invokevirtual。它会弹出栈中的参数值(包括对象引用this),并将其传给被调用方法。
- 算术指令 :如
- 经典案例深度解析(i++ 与 ++i)
这是面试最常问的问题,通过操作数栈的指令顺序可以一眼看出区别:
-
i = i++:
iload先把旧值 0 压入栈。iinc直接在局部变量表里把值加 1(此时变量为 1,但栈顶还是 0)。istore把栈顶的 0 重新写回局部变量表,覆盖了加 1 后的结果。
- 结果 :
i依然是 0。
-
i = ++i:
iinc先在局部变量表里加 1(此时变量为 1)。iload把加完后的新值 1 压入栈。istore把栈顶的 1 写回局部变量表。
- 结果 :
i变成了 1。
核心作用
1、支撑字节码指令的算术运算。
2、支撑方法调用 / 返回。
3、作为局部变量表和计算逻辑之间的 "数据中转站"。
所属关系
每个栈帧对应一个独立的操作数栈,随栈帧创建而初始化,随栈帧销毁而释放,线程私有,完全隔离。
核心结构与存储规则
1、存储单元
以 "数据项" 为基本单位,无局部变量表的 "Slot" 概念,但有明确的类型和深度规则:
01、可存储数据类型:基本数据类型(8 种)、引用类型(对象 / 数组引用)、方法返回地址。
02、类型转换规则:byte/short/char/boolean 类型入栈前会先转换为 int 类型。2、栈深度限制
01、操作数栈的最大深度在编译期就已确定,写入到方法的字节码中,运行时不可动态扩展。
02、若运行时操作数栈的实际深度超出编译期设定的最大值,会抛出StackOverflowError。
3、64 位数据处理
01、long、double 类型占用2 个连续的栈深度位置。
02、其他类型(int、float、引用等)仅占用 1 个栈深度位置。
JVM 常用指令类型概览
| 指令类型 | 常见示例指令 | 核心作用 |
|---|---|---|
| 入栈指令 (Load/Push) | bipush, iload_n, ldc |
将常量或局部变量表中的数据压入操作数栈顶。 |
| 运算/逻辑指令 | iadd, lmul, if_icmpgt |
从栈顶弹出 操作数进行计算,结果再压回栈顶。 |
| 出栈指令 (Store) | istore_n, pop |
将栈顶数据弹出,写入局部变量表或直接丢弃。 |
| 方法调用 / 返回 | invokevirtual, ireturn |
涉及参数传递(压栈)和结果返回(弹出并传递给调用者)。 |
- 字节码执行流程拆解 (模拟 y = (x + 5) * 2)
这张表展示了代码执行过程中,操作数栈是如何随指令动态变化的(假设左侧为栈底,右侧为栈顶)。
| 步骤 | 字节码指令 | 操作数栈状态 (栈底 → 栈顶) | 指令详细说明 |
|---|---|---|---|
| 1 | iload_1 |
[x] |
从局部变量表 Slot 1 读取参数 x 并压栈 |
| 2 | bipush 5 |
[x, 5] |
将单字节常量 5 扩展为 int 值后压栈 |
| 3 | iadd |
[x + 5] |
弹出 x 和 5,相加后将结果压回栈顶 |
| 4 | istore_2 |
[] |
弹出栈顶结果,存入局部变量表 Slot 2 (赋值给变量 y) |
| 5 | iload_2 |
[y] |
从局部变量表 Slot 2 读取变量 y 压栈 |
| 6 | bipush 2 |
[y, 2] |
将常量 2 压入栈顶 |
| 7 | imul |
[y * 2] |
弹出 y 和 2,相乘后将结果压回栈顶 |
| 8 | ireturn |
[] |
弹出栈顶最终结果,结束方法并返回给调用者 |
操作数栈和局部变量表是栈帧中最核心的两个组件,二者频繁交互完成方法执行,关系如下:

数据流向 1(局部变量表 → 操作数栈):通过xload_n指令(如iload_1、aload_2),将局部变量表中指定位置的数据压入操作数栈,为计算做准备;
数据流向 2(操作数栈 → 局部变量表):通过xstore_n指令(如istore_2、astore_3),将操作数栈顶的计算结果弹出,存入局部变量表指定位置(即赋值给局部变量);
核心定位对比:
局部变量表:是 "数据存储区",存储方法参数、局部变量,可通过索引随机访问;
操作数栈:是 "数据计算区",仅支持栈顶操作,专门完成运算和指令交互。
6、特性
1、线程私有:每个线程的每个方法调用都有独立的操作数栈,无并发安全问题。
2、无 GC 参与:操作数栈存储的是临时计算数据,随栈帧销毁而释放,无需垃圾回收。
3、类型严格匹配:JVM 会严格校验操作数栈中数据的类型与指令要求是否匹配(如iadd只能处理 int 类型),不匹配则抛出VerifyError或ClassCastException。
7、异常场景
1、StackOverflowError:操作数栈深度超出编译期设定的最大值(多因方法递归过深、局部变量 / 运算过多导致栈帧整体过大)。
2、NullPointerException:若操作数栈中存储的引用为 null,却执行调用实例方法 / 访问字段的指令(如invokevirtual)。
3、VerifyError:字节码校验阶段发现操作数栈类型不匹配(如用ladd处理 int 数据)。