Apache Kafka 4.1.1 部署指南:单机开发模式与集群生产模式
1. 概述
Apache Kafka 4.1.1 是一个高性能的分布式流处理平台,自 4.0 版本开始完全采用 KRaft 模式(不再依赖 ZooKeeper)。本文档详细介绍 Kafka 4.1.1 的两种部署模式:单机开发模式 (适用于开发、测试环境)和集群生产模式(适用于高可用生产环境)。
版本特性说明
- KRaft 模式:Kafka 4.1.1 默认使用 KRaft 共识协议进行元数据管理,消除了对 ZooKeeper 的外部依赖
- 环境要求:需要 JDK 11 或更高版本
- 操作系统:支持 Linux、macOS 和 Windows(生产环境推荐 Linux)
2. 单机开发模式部署
单机模式适合本地开发、功能测试和学习环境,资源需求低,部署简单。
2.1.1 环境准备(Windows版本)
安装JDK(建议18以上,本测试中为19)
2.1.2 下载与安装
前往Kafka官网下载4.1.1版本
将下载的压缩包进行解压。
注意解压的路径不要太深,否则初始化时会报命令行太长的错误
2.1.3 配置文件(单机模式)
解压后设置配置文件:kafka_2.13-4.1.1\config\server.properties
参考如下:
bash
############################# 服务器基础设置 #############################
# 本服务器的角色。设置此项将启用 KRaft 模式(无需ZooKeeper)
# 4.1.1已经不支持ZooKeeper
process.roles=broker,controller
# 与此实例角色关联的节点 ID
node.id=1
# 用于连接到控制器集群的控制器端点列表
# 在 KRaft 模式下,`controller.quorum.voters` 参数是必需的,用于指定集群的控制器节点。
controller.quorum.voters=1@localhost:9093
############################# 日志基础设置 #############################
# 用于存储日志文件的目录的逗号分隔列表
# Windows 适配:将 Linux 路径改为合法的 Windows 路径,使用正斜杠或双反斜杠
# 集群唯一标识(生成的 UUID)
# cluster.id=
log.dirs=C:\\kafka_2.13-4.1.1\\data-logs
# 每个 Topic 的默认日志分区数量。更多分区允许更高的消费并行度,但也会导致 Broker 上的文件数量更多。
num.partitions=1
# 在启动时用于日志恢复和在关闭时用于刷新的每个数据目录的线程数。
# 对于位于 RAID 阵列中的数据目录,建议增加此值。
num.recovery.threads.per.data.dir=1
############################# Socket 服务器设置 #############################
# Socket 服务器监听的地址。
# 组合节点(即设置了 `process.roles=broker,controller` 的节点)必须至少在此列出控制器监听器。
# 如果未定义 Broker 监听器,默认监听器将使用主机名(等于 java.net.InetAddress.getCanonicalHostName() 的值),使用 PLAINTEXT 监听器名称和端口 9092。
# 格式: listeners = listener_name://host_name:port
# 示例: listeners = PLAINTEXT://your.host.name:9092
# Windows 适配:使用 `:9092` 和 `:9093` 表示绑定所有网络接口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 用于 Broker 之间通信的监听器名称。
inter.broker.listener.name=PLAINTEXT
# Broker 或控制器将向客户端通告的监听器名称、主机名和端口。
# 如果未设置,则使用 "listeners" 的值。
# Windows 适配:客户端通常通过 localhost 连接单机服务 [3](@ref)
advertised.listeners=PLAINTEXT://localhost:9092
# 控制器使用的监听器名称的逗号分隔列表。
# 如果在 `listener.security.protocol.map` 中没有设置显式映射,默认将使用 PLAINTEXT 协议。
# 如果在 KRaft 模式下运行,此项是必需的。
controller.listener.names=CONTROLLER
# 将监听器名称映射到安全协议,默认情况下它们是相同的。有关更多详细信息,请参阅配置文档。
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# 服务器用于从网络接收请求和向网络发送响应的线程数
num.network.threads=3
# 服务器用于处理请求的线程数,可能包括磁盘 I/O
num.io.threads=8
# Socket 服务器使用的发送缓冲区 (SO_SNDBUF) 大小
socket.send.buffer.bytes=102400
# Socket 服务器使用的接收缓冲区 (SO_RCVBUF) 大小
socket.receive.buffer.bytes=102400
# Socket 服务器将接受的请求的最大大小(防止内存溢出,OOM)
socket.request.max.bytes=104857600
############################# 内部 Topic 设置 #############################
# 组元数据内部主题 "__consumer_offsets" 和 "__transaction_state" 的复制因子。
# 对于开发测试以外的任何环境,建议使用大于 1 的值(例如 3)以确保可用性,但在单机模式下只能设置为 1。
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# 日志刷新策略 #############################
# 消息会立即写入文件系统,但默认情况下我们只惰性地调用 fsync() 来同步操作系统缓存。
# 以下配置控制数据刷新到磁盘的策略。
# 这里有几个重要的权衡:
# 1. 持久性:如果您没有使用复制,未刷新的数据可能会丢失。
# 2. 延迟:当刷新确实发生时,非常大的刷新间隔可能会导致延迟峰值,因为会有大量数据需要刷新。
# 3. 吞吐量:刷新通常是最昂贵的操作,小的刷新间隔可能导致过多的寻道。
# 下面的设置允许配置刷新策略,即在一段时间后或每 N 条消息后刷新数据(或两者兼施)。这可以全局设置并在每个 Topic 的基础上覆盖。
# 在强制将数据刷新到磁盘之前要接受的消息数量
#log.flush.interval.messages=10000
# 在强制刷新之前,消息可以在日志中停留的最长时间
#log.flush.interval.ms=1000
############################# 日志保留策略 #############################
# 以下配置控制日志段的处理。可以设置策略在一段时间后删除段,或者在累积到给定大小后删除段。
# 只要满足*任一*条件,段就会被删除。删除总是从日志的末尾开始。
# 日志文件有资格因存在时间而被删除的最小存活时间(小时)
log.retention.hours=168
# 日志的基于大小的保留策略。除非剩余的段低于 log.retention.bytes,否则段将从日志中修剪。独立于 log.retention.hours 运行。
#log.retention.bytes=1073741824
# 日志段文件的最大大小。达到此大小时将创建新的日志段。
log.segment.bytes=10240000
# 检查日志段是否可以根据保留策略被删除的时间间隔
log.retention.check.interval.ms=3000002.1.4 配置文件(初始化与启动)
1)初始化存储目录:
2)打开命令提示符(CMD),进入 Kafka 的 bin/windows目录。
3)生成集群 ID:kafka-storage.bat random-uuid,记录输出的 UUID(如abc123-xxxx-yyyy-zzzz)。

在server.properties中添加配置:
bash
# 集群唯一标识(生成的 UUID)
cluster.id=XZa7Ywa5REKZVHxZbQdB0A4)格式化存储目录:.\kafka-storage.bat format -t abc123-xxxx-yyyy-zzzz -c ..\..\config\server.properties。

5)启动 Kafka:在 bin/windows目录下执行:.\kafka-server-start.bat ..\..\config\server.properties。


2.1.5 验证单机服务
1)打开命令提示符(CMD),进入 Kafka 的安装目录。
2)新建命令行进入 Kafka 的 bin/windows目录:.\kafka-topics.bat --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1

3)确认是否创建了主题test-topic:.\kafka-topics.bat --list --bootstrap-server localhost:9092

4)查看 Topic 的详细信息:.\kafka-topics.bat --describe --topic test-topic --bootstrap-server localhost:9092
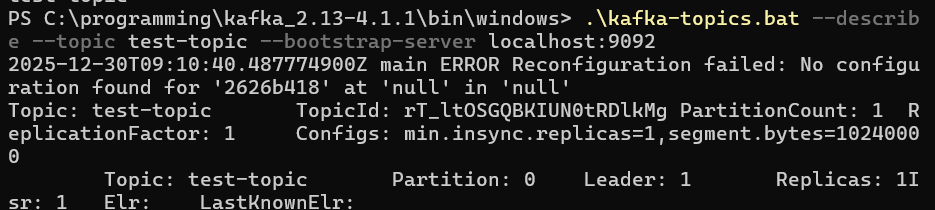
5)启动消费者:启动消费者,并让它开始监听消息。使用 --from-beginning参数确保能收到后续生产的所有消息:.\kafka-console-consumer.bat --topic test-topic --from-beginning --bootstrap-server localhost:9092

6)启动生产者并发送消息,新建窗口启动生产者:.\kafka-console-producer.bat --topic test-topic --bootstrap-server localhost:9092

7)启动后,命令行会等待输入。输入几行测试消息,每输完一行按一次回车,例如:
Hello, Kafka!
8)验证消息接收:如果一切正常,会在消费者窗口中几乎实时地看到输入的消息。

可以写一个bat快速启动
bash
安装目录\bin\windows\kafka-server-start.bat 安装目录\config\server.properties2.2.1 环境准备(Linux版本)
bash
#安装 JDK(以 Ubuntu 为例)
sudo apt update
sudo apt install -y openjdk-11-jdk
#验证安装
java -version
#创建目录
sudo mkdir -p /opt/kafka /data/kafka-logs
sudo chown -R USER:USER /opt/kafka /data/kafka-logs初始化存储目录:
打开命令提示符(CMD),进入 Kafka 的 bin/windows目录。
生成集群 ID:kafka-storage.bat random-uuid。记录输出的 UUID,例如 abc123-xxxx-yyyy-zzzz。
格式化存储目录:kafka-storage.bat format -t abc123-xxxx-yyyy-zzzz -c ...\config\kraft\server.properties。
启动 Kafka:在 bin/windows目录下执行:kafka-server-start.bat ...\config\kraft\server.properties。
测试验证:成功启动后,可新开CMD窗口创建Topic、生产及消费消息以验证服务正常 。
2.2.2 下载与安装
bash
#下载 Kafka 4.1.1
cd /tmp
wget https://downloads.apache.org/kafka/4.1.1/kafka_2.13-4.1.1.tgz
#解压到安装目录
tar -xzf kafka_2.13-4.1.1.tgz -C /opt/kafka
cd /opt/kafka2.2.3 配置文件(单机模式)
创建或编辑 config/kraft/server.properties:
bash
#基础参数
#当前节点唯一 ID
node.id=1
#节点角色:既是 controller 又是 broker
process.roles=broker,controller
#Controller 监听名
controller.listener.names=CONTROLLER
#Controller 集群成员(单机就是自己)
controller.quorum.voters=1@localhost:9093
#监听配置
#Kafka 对外监听(客户端连接用)
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
#客户端访问时看到的地址
advertised.listeners=PLAINTEXT://localhost:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
inter.broker.listener.name=PLAINTEXT
#数据与日志
#Kafka 数据目录
log.dirs=/data/kafka-logs
#Topic 默认配置
#默认分区数
num.partitions=1
#内部主题副本数(单机环境只能设为 1)
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#日志管理
#日志保留时间(小时)
log.retention.hours=168
#单个 segment 大小:1GB
log.segment.bytes=10737418242.2.4 初始化与启动
bash
#生成集群 ID(只执行一次)
cd /opt/kafka
./bin/kafka-storage.sh random-uuid
#示例输出:abc123-xxxx-yyyy-zzzz
#使用生成的 clusterId 格式化存储目录
./bin/kafka-storage.sh format \
-t abc123-xxxx-yyyy-zzzz \
-c config/kraft/server.properties
#启动 Kafka 服务(前台运行,查看日志)
./bin/kafka-server-start.sh config/kraft/server.properties
#或者后台启动
./bin/kafka-server-start.sh -daemon config/kraft/server.properties2.2.5 验证单机服务
bash
#创建测试 Topic
./bin/kafka-topics.sh --create \
--topic test-topic \
--bootstrap-server localhost:9092 \
--partitions 1 \
--replication-factor 1
#发送消息(生产者)
./bin/kafka-console-producer.sh \
--topic test-topic \
--bootstrap-server localhost:9092
#接收消息(消费者)- 另开终端执行
./bin/kafka-console-consumer.sh \
--topic test-topic \
--bootstrap-server localhost:9092 \
--from-beginning2.2.6 使用 Systemd 管理(可选)
创建 /etc/systemd/system/kafka.service:
bash
[Unit]
Description=Apache Kafka 4.1.1 (KRaft)
After=network.target
[Service]
Type=simple
User=kafka
Group=kafka
Environment="KAFKA_HOME=/opt/kafka"
Environment="PATH=/opt/kafka/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin"
WorkingDirectory=/opt/kafka
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target启用服务:
bash
sudo systemctl daemon-reload
sudo systemctl enable kafka
sudo systemctl start kafka
sudo systemctl status kafka3. 集群生产模式部署(Linux版本)
生产环境推荐使用至少 3 个节点的 Kafka 集群以确保高可用性。
3.1 集群架构规划
假设三节点集群配置:
- kafka-node1: 192.168.10.11 (node.id=1)
- kafka-node2: 192.168.10.12 (node.id=2)
- kafka-node3: 192.168.10.13 (node.id=3)
3.2 环境准备(所有节点)
bash
#所有节点执行:安装 JDK
sudo yum install -y java-17-openjdk java-17-openjdk-devel # CentOS/RHEL
#或 sudo apt install openjdk-17-jdk # Ubuntu/Debian
#创建用户和目录
sudo useradd -m -s /bin/bash kafka
sudo mkdir -p /opt/kafka /data/kafka-logs /data/kafka-meta
sudo chown -R kafka:kafka /opt/kafka /data/kafka-logs /data/kafka-meta3.3 下载并分发 Kafka
在一个节点下载后分发到其他节点:
bash
#在 kafka-node1 执行
cd /opt
wget https://downloads.apache.org/kafka/4.1.1/kafka_2.13-4.1.1.tgz
tar -xzf kafka_2.13-4.1.1.tgz
ln -s kafka_2.13-4.1.1 kafka
chown -R kafka:kafka /opt/kafka_2.13-4.1.1 /opt/kafka
#分发到其他节点
scp -r /opt/kafka_2.13-4.1.1 kafka-node2:/opt/
scp -r /opt/kafka_2.13-4.1.1 kafka-node3:/opt/
#在其他节点创建软链接
ln -s /opt/kafka_2.13-4.1.1 /opt/kafka
chown -R kafka:kafka /opt/kafka_2.13-4.1.1 /opt/kafka3.4 集群配置文件
每个节点编辑 config/kraft/server.properties:
公共配置(所有节点相同)
bash
#KRaft 基本角色配置
process.roles=broker,controller
controller.listener.names=CONTROLLER
controller.quorum.voters=1@kafka-node1:9093,2@kafka-node2:9093,3@kafka-node3:9093
#监听配置
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
listener.security.protocol.map=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT
inter.broker.listener.name=PLAINTEXT
#数据目录
log.dirs=/data/kafka-logs
metadata.log.dir=/data/kafka-meta
#Topic 默认配置
num.partitions=3
log.retention.hours=168
log.segment.bytes=1073741824
#生产环境建议设置为 3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2节点专属配置
kafka-node1 (192.168.10.11) 追加:
bash
node.id=1
advertised.listeners=PLAINTEXT://192.168.10.11:9092kafka-node2 (192.168.10.12) 追加:
bash
node.id=2
advertised.listeners=PLAINTEXT://192.168.10.12:9092kafka-node3 (192.168.10.13) 追加:
bash
node.id=3
advertised.listeners=PLAINTEXT://192.168.10.13:90923.5 集群初始化
bash
#在一个节点生成集群 ID(如 kafka-node1)
su - kafka
cd /opt/kafka
bin/kafka-storage.sh random-uuid
#示例输出:fRbs-vkR9Uevh5Cwlwk
#所有节点执行格式化(使用相同的集群 ID)
bin/kafka-storage.sh format \
-t fRbs-vkR9Uevh5Cwlwk \
-c config/kraft/server.properties3.6 启动集群
逐个节点启动(建议先启动 controller 节点):
bash
#每个节点执行
su - kafka
cd /opt/kafka
bin/kafka-server-start.sh -daemon config/kraft/server.properties
#验证进程
ps -ef | grep kafka
netstat -lnpt | grep 9092
netstat -lnpt | grep 90933.7 集群验证
bash
#创建测试 Topic(在任一节点执行)
bin/kafka-topics.sh --create \
--topic cluster-test \
--bootstrap-server 192.168.10.11:9092 \
--partitions 6 \
--replication-factor 3
#查看 Topic 分布情况
bin/kafka-topics.sh --describe \
--topic cluster-test \
--bootstrap-server 192.168.10.11:9092
#跨节点生产消费测试
#在 kafka-node1 生产消息
bin/kafka-console-producer.sh \
--topic cluster-test \
--bootstrap-server 192.168.10.11:9092
#在 kafka-node2 消费消息
bin/kafka-console-consumer.sh \
--topic cluster-test \
--from-beginning \
--bootstrap-server 192.168.10.12:90923.8 Systemd 集群管理
每个节点创建 /etc/systemd/system/kafka.service:
bash
[Unit]
Description=Apache Kafka 4.1.1 (KRaft Cluster Node)
After=network.target
[Service]
User=kafka
Group=kafka
Type=simple
Environment="JAVA_HOME=/usr/lib/jvm/java-17-openjdk"
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target启用服务:
bash
sudo systemctl daemon-reload
sudo systemctl enable kafka
sudo systemctl start kafka
sudo systemctl status kafka4. 关键配置参数说明
4.1 核心参数含义
| 参数名 | 含义 | 单机值 | 集群值 |
|---|---|---|---|
process.roles |
节点角色 | broker,controller |
broker,controller |
node.id |
节点唯一标识 | 1 |
集群内唯一整数 |
controller.quorum.voters |
控制器仲裁组 | 1@localhost:9093 |
所有 controller 节点 |
advertised.listeners |
客户端连接地址 | localhost:9092 |
节点真实 IP/域名 |
offsets.topic.replication.factor |
内部主题副本数 | 1 |
3(推荐) |
4.2 生产环境优化建议
bash
#数据可靠性配置
unclean.leader.election.enable=false
min.insync.replicas=2
#性能调优
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
#JVM 参数调整(bin/kafka-server-start.sh)
export KAFKA_HEAP_OPTS="-Xms4G -Xmx4G"
export KAFKA_JVM_PERFORMANCE_OPTS="-XX:MaxGCPauseMillis=20"5. 常见问题排查
5.1 启动失败检查
- 端口冲突:
bash
lsof -i :9092
lsof -i :9093- 目录权限:
bash
chown -R kafka:kafka /data/kafka-logs /data/kafka-meta- 集群 ID 不匹配:确保所有节点使用相同的集群 ID 进行格式化
5.2 客户端连接问题
- 检查
advertised.listeners配置是否正确 - 验证网络连通性:
bash
telnet kafka-node1 9092- 查看服务日志:
bash
tail -f /opt/kafka/logs/server.log6. 总结
本文档详细介绍了 Kafka 4.1.1 在 KRaft 模式下的两种部署方案:
- 单机开发模式:适合功能验证和开发测试,配置简单,资源需求低
- 集群生产模式:提供高可用性和容错能力,适合线上业务使用
Kafka 4.1.1 完全移除对 ZooKeeper 的依赖,简化了架构部署,同时保持了高性能和可靠性。生产环境部署时,建议至少使用 3 个节点,并合理配置副本因子和监控告警体系。
注意:本文档基于 Kafka 4.1.1 版本编写,配置参数和部署方式可能随版本更新而变化,请以官方文档为准。