那么上一篇,小编讲到一些自动化测试中,一些概念讲解
那么接下来,小编继续分享下基于selenium框架下,一些常用方法
构建依赖环境:
java
<!-- 请根据需要选择版本 -->
<!-- 测试框架依赖 -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0</version>
</dependency>
<!-- 驱动管理依赖 -->
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>5.8.0</version>
<scope>test</scope>
</dependency>构建第一个驱动程序:
java
public void test01(){
//安装驱动管理
WebDriverManager.chromedriver().setup();
//设置谷歌浏览器选项
ChromeOptions options=new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
//获取浏览器驱动对象
WebDriver driver=new ChromeDriver(options);
//获取网页链接标题
driver.get("https://www.baidu.com");
String title=driver.getTitle();
if(title.contains("百度")){
System.out.println("测试通过!");
}else {
System.out.println("测试失败!");
}
//关闭驱动链接
driver.quit();
}运行结果:
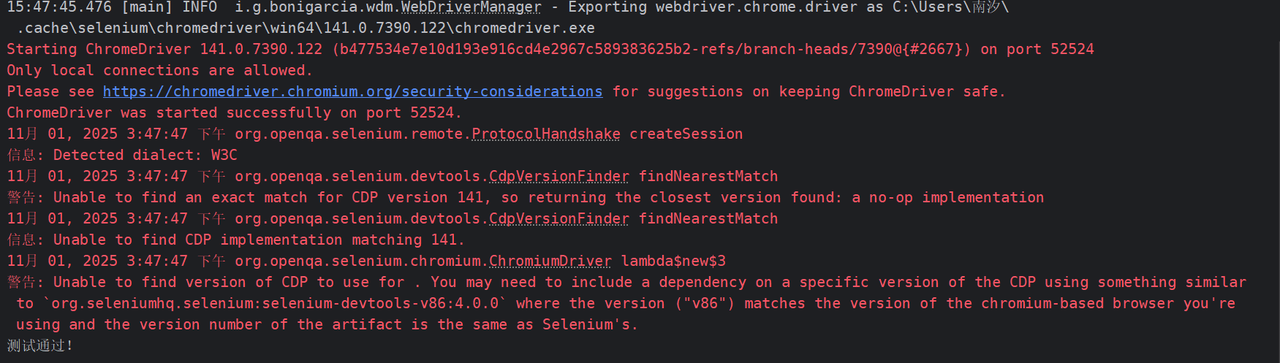
解析代码:
WebDriverManager.chromedriver().setup();
这里以谷歌浏览器作为例子
这行代码作用是:
自动下载当前系统中chrome浏览器版本兼容的chromeDriver,并将其路径设置到系统属性中,以便selenium能正确启动Chrome浏览器
注意:
-
setUp()方法是不会启动浏览器的,它只是"准备驱动"
-
首次运行会稍慢,因为要先下载驱动,后续运行后会从缓存加载,速度快
这里也有解决方案:
java
//下载驱动
WebDriverManager.chromedriver()
//固定版本测试(需要本地已有该驱动包,以及本地浏览器大版本对应)
.driverVersion("141.0.7390.123")
.avoidBrowserDetection() //关闭自动检测
.setup();- 如若是网络问题,那么可以配置镜像源
配置镜像源:
java
WebDriverManager.chromedriver()
.driverRepositoryUrl(URI.create("https://npmmirror.com/mirrors/chromedriver"))
.setup();作用: 解决因CORS(跨域)安全策略导致的DevToolsActivePort或链接拒绝错误,尤其是在Selenium 4.8+ 与新版的Chrome(V111+)配合使用时
原因:
自Chrome 111版本开始,Google加强了DevTools协议的安全策略,默认禁止远程(remote)连接未授权的源(Origin)
而Selenium通过ChromeDirver 与 Chrome浏览器进行通信时,本质上是通过WebSocket 连接到DevTools的调试端口,这被Chrome视为"远程连接"
-
--remote-allow-origins是 Chrome 的一个命令行启动参数; -
*表示允许所有来源(origins)进行远程连接; -
这样 Chrome 就会接受来自 ChromeDriver(localhost 或 127.0.0.1)的 DevTools 连接请求。
注意:
*是通配符,表示"全部允许"。在生产环境或高安全要求场景中,建议指定具体来源,例如:
options.addArguments("--remote-allow-origins=http://localhost:12345");
WebDriver driver=new ChromeDriver(options);
核心作用:
创建一个 WebDriver 实例,启动一个由 ChromeDriver 控制的 Chrome 浏览器窗口,并应用你指定的启动选项(如无头模式、允许跨域等)
那么以上就是第一个驱动程序,代码简单讲解。
接下来,就是重头戏了,毕竟Web自动化核心就是找到页面对应的元素,然后对元素进行相应操作。
一、元素定位:
铺垫: findElement:表示查找元素,findElements:表示查找多个元素
By:
它是selenium的"定位器工厂",即是一个抽象基类,它本身不执行查找操作,而是封装了"如何定位元素"的策略
可以理解为"查找元素方式的描述符"
1.1 cssSelector:
其原本是CSS中用来选定HTML元素并应用样式的语法。
Selenium 借用了这一标准语法,将其作为定位页面元素的一种方式
优势:
-
语法简洁、表达力强
-
支持层级、属性、伪类等复杂匹配
-
执行速度快(浏览器原生支持)
-
比 XPath 更轻量、更推荐用于现代 Web 自动化
举例:

常见语法: 示例页面:
html
<input id="username" class="form-input" type="text" placeholder="请输入用户名">
<button class="btn primary" data-action="submit">登录</button>
<div id="container">
<span class="error-message">用户名不能为空</span>
</div>标签名选中:
driver.findElement(By.cssSelector("input"));
此时是匹配第一个<input>元素
ID名选中
driver.findElement(By.cssSelector("#username"));
#表示ID选择器
class选中
driver.findElement(By.cssSelector(".form-input")); driver.findElement(By.cssSelector(".btn.primary")); // 同时包含 btn 和 primary 两个 class
.表示 class 选择器;多个 class 连写(无空格)表示"同时拥有"
属性选中:
driver.findElement(By.cssSelector("input[type='text']")); driver.findElement(By.cssSelector("button[data-action='submit']"));
[属性名='值']精确匹配属性
组合定位选中(层级关系)
// 在 #container 内部查找 .error-message driver.findElement(By.cssSelector("#container .error-message")); // 直接子元素(> 表示父子关系) driver.findElement(By.cssSelector("#container > span"));
伪类选择器选中(常用于动态元素)
// 第一个 input driver.findElement(By.cssSelector("input:first-child")); // 最后一个 button driver.findElement(By.cssSelector("button:last-of-type"));
1.2 Xpath
Xpath最初用于XML文档导航设计的,但由于HTML本质是一种"宽松"的XML,因此XPath也被广泛用于在网页中查找元素
Selenium支持通过By.xpath()使用Xpath表达式定位元素上的任意元素
核心能力:
-
按元素层级路径定位
-
按文本内容定位
-
向上查找父元素(CSS Selector 无法做到!)
-
使用逻辑运算符(and/or)、函数(contains, text(), starts-with 等)
Xpath常用语法: 获取到HTML页面所有的节点:
//*
获取HTML页面上指定的节点
//指定节点
//ul:获取HTML页面所有的ul节点
//input:获取HTML页面上所有的input节点
获取该节点下的某个子节点
/
//span/input
获取一个节点的父节点
..
//input/.. :获取input节点的父节点
实现节点属性的匹配: @...
//*@id='kw' 匹配HTML页面中id属性为KW的节点
使用指定索引的方式来获取对应的节点内容:
注意:xpath的索引从1开始
//*@id="hotsearch-content-wrapper"/li3 :百度首页的热搜第三个
常用语法:
页面示例:
html
<div class="form-container">
<label for="email">邮箱</label>
<input id="email_123abc" type="email" placeholder="请输入邮箱">
<button class="btn">提交</button>
<div class="alert error">邮箱格式错误</div>
</div>绝对路径:
driver.findElement(By.xpath("/html/body/div[1]/input"))
脆弱:页面结构一变就失效
相对路径(推荐)
driver.findElement(By.xpath("//input")); // 任意位置的第一个 input
以
//开头,从任意位置开始匹配
按属性定位
driver.findElement(By.xpath("//input[@id='email_123abc']")); driver.findElement(By.xpath("//input[@type='email']"));
按文本内容定位
driver.findElement(By.xpath("//button[text()='提交']")); driver.findElement(By.xpath("//div[contains(text(), '邮箱格式错误')]"));
使用函数:contains(), starts-with()
// ID 动态但包含 "email" driver.findElement(By.xpath("//input[contains(@id, 'email')]")); // placeholder 以 "请输入" 开头 driver.findElement(By.xpath("//input[starts-with(@placeholder, '请输入')]"));
轴(Axes):定位父级、兄弟等
// 找到"邮箱"label 的下一个兄弟 input driver.findElement(By.xpath("//label[text()='邮箱']/following-sibling::input")); // 找到包含"错误"的 div 的父容器 driver.findElement(By.xpath("//div[contains(text(), '错误')]/.."));
逻辑组合(and / or)
// 同时满足 type=email 且 placeholder 包含"邮箱" driver.findElement(By.xpath("//input[@type='email' and contains(@placeholder, '邮箱')]"));
Xpath和cssSelector区别:
表格 还在加载中,请等待加载完成后再尝试复制
当然,除了这个,findElement还支持其他寻找方式:
driver.findElement(By.id("kw"));
这个是代表寻找页面中,寻找id为kw的元素
driver.findElement(By.name("wd"));
这个是代表寻找HTML标签定义的name属性值
二:操作测试对象
场景:
有以下页面:

当我们需要进行文本输入,按钮点击,文本清空再输入时,就可以使用以下方法
文本点击
//举例,百度一下 WebElement element=driver.findElement(By.cssSelector("#chat-submit-button") element.click()
文本输入
//举例,百度搜索框输入 WebElement element=driver.findElement(By.cssSelector("#chat-textarea") element.sendKeys("UI自动化测试")
文本清空
//举例,百度搜索框输入 WebElement element=driver.findElement(By.cssSelector("#chat-textarea") element.sendKeys("UI自动化测试") element.clear()
除此之外,对于选中的元素还可以获取它的文本内容
获取文本内容:
//举例,获取文本内容 WebElement element=driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(2) > a > span.title-content-title") Strinig text=element.getText()
值得一提的是,driver也提供两个较为常用的方法
getTitle():获取当前页面标题信息
getCurrentUrl():获取当前页面的URL
三、窗口切换
场景:
从百度搜索页点击图片超链接进入图片页面
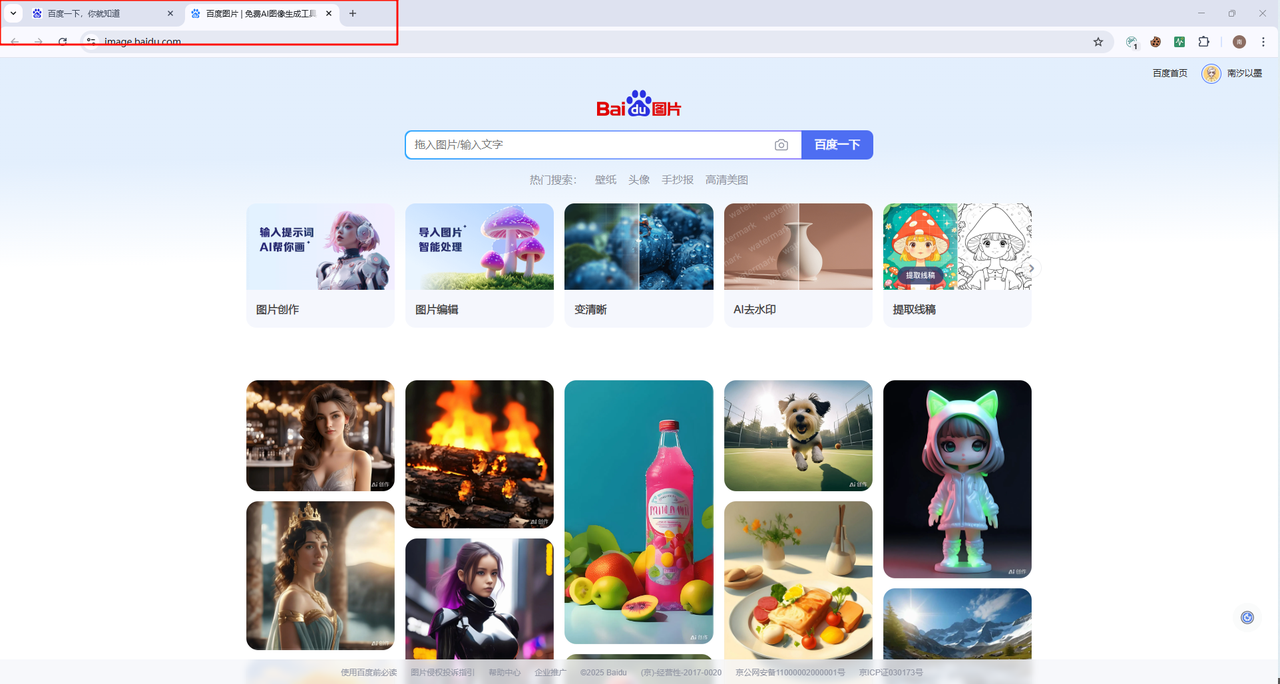
那么,可以观察到出现了两个窗口,那么也有对应的方法可操控
先值得一说的是,driver方法指的是当前页面的,当跳到第二个页面时,也不可操作第二个页面的元素
1.获取当前页面句柄方法
driver.getWindowHandle()
2.获取所有页面的句柄
driver.getWindowHandles()
以下方法是获取最新句柄,
java
String curWindow = driver.getWindowHandle(); // 获取当前窗口句柄
Set<String> allWindows = driver.getWindowHandles(); // 获取所有窗口句柄
for (String w : allWindows) {
if (!w.equals(curWindow)) { // 注意:应使用 .equals() 而非 !=
driver.switchTo().window(w); // 切换到新窗口
break; // 建议加上 break!
}
}3.窗口大小设置
java
driver.manage().window().maximize();//窗口最大化
driver.manage().window().minimize();//窗口最小化
driver.manage().window().fullscreen();//全屏窗口
driver.manage().window().setSize(new Dimension(1024,768))//手动设置窗口4.窗口关闭
driver.close() //注意窗口关闭后,driver不再生效,需重新定义
5.屏幕截图
该方法需要引入依赖:
java
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>这里提供一个方法:
java
import org.apache.commons.io.FileUtils;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Locale;
public class ScreenshotUtil {
private static final Logger logger = LoggerFactory.getLogger(ScreenshotUtil.class);
// 默认截图根目录(可根据项目结构调整)
private static final String SCREENSHOT_BASE_DIR = "./screenshots";
/**
* 截图并保存到指定目录,文件名格式:{prefix}-{yyyyMMdd-HHmmss}.png
*
* @param driver WebDriver 实例
* @param prefix 文件名前缀,如 "login_error", "goods_browser"
* @return 截图文件的绝对路径(可用于测试报告嵌入),失败返回 null
*/
public static String takeScreenshot(WebDriver driver, String prefix) {
if (driver == null) {
logger.warn("WebDriver 为 null,无法截图");
return null;
}
try {
// 1. 生成时间戳
String datePart = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd", Locale.ENGLISH));
String timePart = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HHmmss", Locale.ENGLISH));
// 2. 构建目录路径(按日期分文件夹)
String folderPath = SCREENSHOT_BASE_DIR + File.separator + "autotest-" + datePart;
File folder = new File(folderPath);
if (!folder.exists()) {
boolean created = folder.mkdirs(); // 自动创建多级目录
if (!created) {
logger.error("无法创建截图目录: {}", folderPath);
return null;
}
}
// 3. 构建完整文件名
String fileName = String.format("%s-%s.png", prefix, timePart);
//使用 File.separator(Windows 用 \,macOS/Linux 用 /);
String fullPath = folderPath + File.separator + fileName;
// 4. 执行截图
File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
// 5. 保存到指定路径
FileUtils.copyFile(screenshot, new File(fullPath));
logger.info("截图成功保存: {}", fullPath);
return new File(fullPath).getAbsolutePath();
} catch (IOException e) {
logger.error("截图保存失败", e);
return null;
} catch (ClassCastException e) {
logger.error("当前 WebDriver 不支持截图(需实现 TakesScreenshot 接口)", e);
return null;
}
}
}4.等待
场景: 由于网络因素,或是代码层级因素,比如网络过慢,规定时间内无法加载元素,代码执行速度过快,无法有效定位元素,所以这些问题,可能会导致结果是误报的。
解决以上场景,可引入等待策略
4.1强制等待
使用Thread.sleep(毫秒) 让线程无条件暂停指定时间
Thread.sleep(3000)
-
特点: 简单粗暴:不管页面是否加载完成,都等满指定时间
-
不智能:如若元素1秒出现,仍需等待数秒,浪费时间
-
不稳妥:如若网络慢,3秒不够,依旧会失败
适用场景:
极少数的调试场景(如临时观察页面)
4.2隐式等待
设置一个全局的超时时间,WebDriver 在查找元素时,如若第一次没找到,则隔一段时间重试,直到重试
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
工作原理:
-
设置后,对所有
findElement/findElements调用生效; -
如果元素立即存在 → 立即返回;
-
如果元素不存在 → 每隔几百毫秒重试,最多等 10 秒;
-
超时后抛出
NoSuchElementException。
优点:
简单,一行代码覆盖全局
避免因网络延时导致的偶发失败
缺点:
-
只对"查找元素"有效,对其他操作(如判断元素是否可点击,弹窗)无效;
-
一旦设置,全程生效,无法针对特定场景调整;
-
与显式等待混用可能产生叠加效应(总等待时间 = 隐式 + 显式),导致脚本变慢
4.3显示等待
针对特定条件进行等待,直到条件满足或超时,使用WebDriverWait + ExpectedConditions
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10)); WebElement element = wait.until( ExpectedConditions.elementToBeClickable(By.id("submit-btn")) );
工作原理:
-
每隔 500ms(默认)检查一次条件;
-
条件满足 → 立即返回元素或 true;
-
超时未满足 → 抛出
TimeoutException
常用等待条件:
表格 还在加载中,请等待加载完成后再尝试复制
优点:
-
精准:只在需要的地方等待;
-
灵活:可自定义任意等待条件(甚至结合 lambda 表达式);
-
高效:条件一旦满足立即继续,不浪费时间;
-
稳定:能处理动态内容、AJAX 加载、弹窗等复杂场景
5.浏览器导航
场景:
当执行页面跳转时,需要进行回退操作,此时需要用到浏览器导航

常见操作: 1.打开网站
driver.navigate().to("xxxxxx") //更为简洁方法 driver.get("xxxxxx")
2.浏览器的前进、后退、刷新
driver.navigate().back();//后退 driver.navigate().forword();//前进 driver.navigate().refresh();//刷新
6.弹窗
场景: 当对页面进行操作时,弹出弹窗,此时需要进行相关操作
6.1警告弹窗+确认弹窗
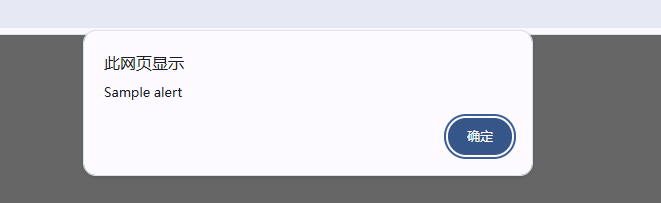

Alert alert=driver.swithTo.alert(); //确认 alert.accpet() //取消 alert.dismiss()
6.2 提示弹窗
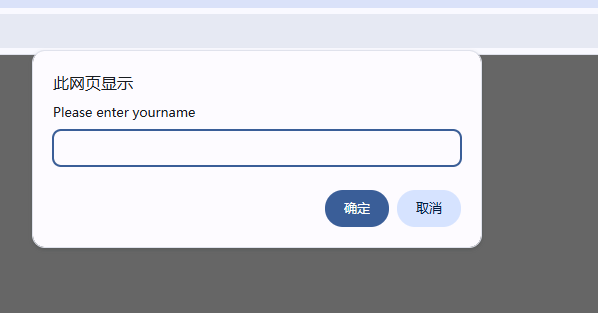
Alert alert=driver.swithTo.alert(); //发送文本 alert.sendKeys("hello") //确认 alert.accpet() //取消 alert.dismiss()
7.文件上传
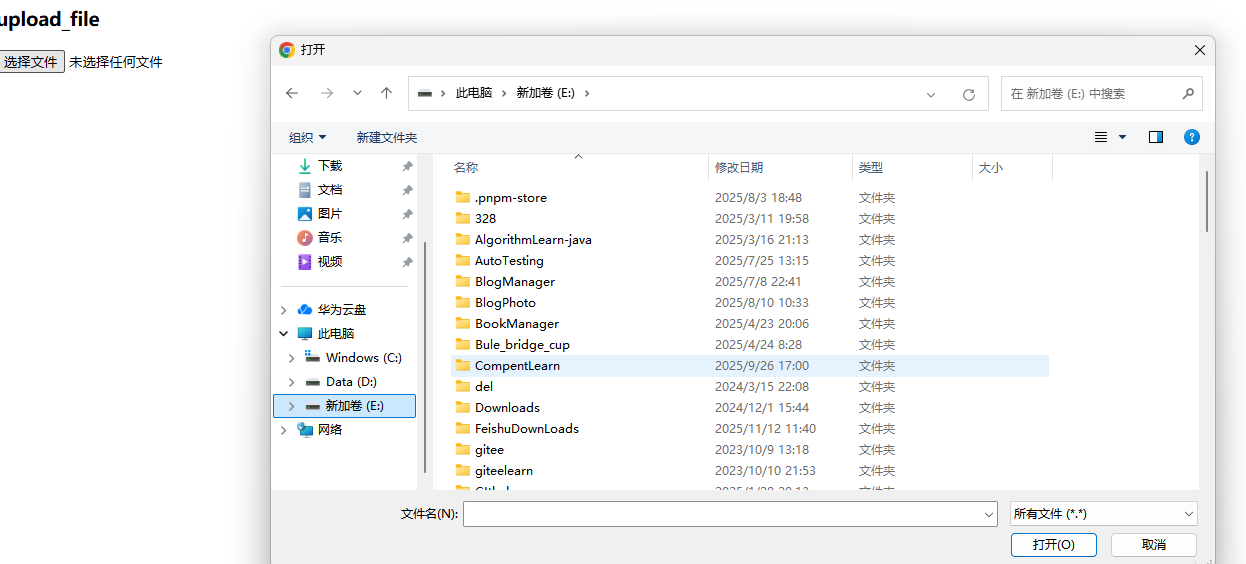
此时,代码操作如下:
WebElement element = driver.findElement(By.cssSelector("body > div > div > input[type=file]")); element.sendKeys("xxxxxx")//通过发送关键词,效果类似上传文件
8.浏览器参数设置
为什么设置浏览器参数?
-
默认启动的浏览器可能包含弹窗、扩展、缓存等干扰自动化;
-
某些网站会检测自动化工具(如
navigator.webdriver); -
需要在 CI/CD 环境中无界面运行(Headless);
-
模拟真实用户环境(如 User-Agent、地理位置、语言);
-
提升执行速度或稳定性(如禁用 GPU、沙箱)。
核心类:ChromeOptions
java
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless=new"); // 无头模式
options.addArguments("--disable-gpu"); // 禁用 GPU 加速
options.addArguments("--no-sandbox"); // 禁用沙箱(Linux/CI 必加)
options.addArguments("--remote-allow-origins=*"); // 允许远程连接(Chrome 111+ 必加)
WebDriver driver = new ChromeDriver(options);注意:从 Chrome 109+ 开始,推荐使用 --headless=new 替代旧的 --headless,以获得完整 DevTools 支持。
常用参数说明: 基础参数
表格 还在加载中,请等待加载完成后再尝试复制
性能与稳定参数:
表格 还在加载中,请等待加载完成后再尝试复制
绕过安全参数:
表格 还在加载中,请等待加载完成后再尝试复制
模拟真实用户参数
表格 还在加载中,请等待加载完成后再尝试复制
这里有值得一说的是:同源策略
一、什么是同源策略?
同源策略(Same-Origin Policy)是浏览器实施的一种安全机制,用于限制一个源(origin)的文档或脚本如何与另一个源的资源进行交互。
它的核心目的是:防止恶意网站窃取用户数据或操作其他网站的内容。
二、"源"(Origin)由什么决定?
一个 URL 的"源"由以下三部分共同定义:
表格 还在加载中,请等待加载完成后再尝试复制
只有当两个 URL 的协议、主机名、端口完全相同时,才被认为是"同源"。
同源示例:
-
https://www.example.com/page1 -
https://www.example.com/page2?query=123→ 同源(路径和查询参数不影响)
非同源示例:
表格 还在加载中,请等待加载完成后再尝试复制
注意:
localhost和127.0.0.1被视为不同源!
三、同源策略限制哪些行为?
浏览器主要限制以下跨源操作:
表格 还在加载中,请等待加载完成后再尝试复制
重点:跨域请求其实会发送到服务器,只是浏览器阻止你读取响应!
四、为什么需要同源策略?------安全场景举例
假设没有同源策略:
-
用户登录了银行网站
https:``//bank.com,Cookie 中保存了身份凭证; -
用户又打开了恶意网站
https://evil.com; -
evil.com的 JS 发起请求:fetch('https://bank.com/transfer?to=hacker&amount=1000'); -
浏览器自动带上
bank.com的 Cookie → 转账成功!
同源策略阻止了第 4 步中 JS 读取响应或发起敏感操作,从而保护用户。
五、如何合法地"跨域"?------CORS
为支持正当的跨域需求(如前后端分离、CDN),W3C 引入了 CORS(Cross-Origin Resource Sharing,跨域资源共享)。
工作原理:
-
浏览器检测到 AJAX 请求跨域;
-
自动在请求头中添加
Origin: https://your-site.com; -
服务器检查该 Origin 是否被允许;
-
若允许,返回响应头:
-
Http
-
编辑
1Access-Control-Allow-Origin: https://your-site.com
- 浏览器收到后,才将响应内容交给 JS。
关键点:CORS 是服务器控制的,前端无法绕过!
六、常见误区澄清
|------------------|-------------------------------------------|
| 误区 | 正确理解 |
| "跨域是服务器阻止的" | 实际是浏览器阻止,服务器可能根本不知道 |
| "JSONP 是绕过 CORS" | JSONP 利用了 <script> 标签不受同源限制的特性,但只支持 GET |
| "CORS = 允许所有跨域" | CORS 是精细化授权,可控制方法、头、凭证等 |