文章目录
-
- 一、当故宫遇见全球游客
- 二、技术方案:解析引擎+翻译引擎的完美协同
-
- [2.1 解析节点及对应TextIn API](#2.1 解析节点及对应TextIn API)
- [2.2 TextIn API调用节点参数](#2.2 TextIn API调用节点参数)
- [2.3 技术实现路径和关键参数配置](#2.3 技术实现路径和关键参数配置)
- 三、效果指标:效率与准确率的双重突破
-
- [3.1 单页文档处理耗时](#3.1 单页文档处理耗时)
- [3.2 多语言解析准确率数据](#3.2 多语言解析准确率数据)
- [3.3 成本对比分析](#3.3 成本对比分析)
- 四、应用场景深度解析:国内文旅景区多语言智能导览
-
- [4.1 多语言导览文本精准生成](#4.1 多语言导览文本精准生成)
-
- [4.1.1 景区资料深度解析过程](#4.1.1 景区资料深度解析过程)
- [4.1.2 多语言翻译与文化适配案例](#4.1.2 多语言翻译与文化适配案例)
- [4.1.3 大模型+多语言生成Agent的协同机制](#4.1.3 大模型+多语言生成Agent的协同机制)
- [4.2 语音导览内容定制化生成](#4.2 语音导览内容定制化生成)
-
- [4.2.1 语音风格适配策略](#4.2.1 语音风格适配策略)
- [4.2.2 多语言语音合成技术实现](#4.2.2 多语言语音合成技术实现)
- [4.3 景区知识图谱构建与智能问答](#4.3 景区知识图谱构建与智能问答)
-
- [4.3.1 知识图谱构建的技术路径](#4.3.1 知识图谱构建的技术路径)
- [4.3.2 智能问答系统实现方式](#4.3.2 智能问答系统实现方式)
- [4.3.3 典型问答场景示例](#4.3.3 典型问答场景示例)
- 五、语言无界,体验无限
一、当故宫遇见全球游客
想象一下,故宫博物院每天要处理来自全球各地的多语言文档------从英文的学术研究论文、日文的游客反馈,到法文的展览策划方案。这些文档格式各异,有PDF、Word,还有扫描版的古籍文献。过去,故宫的工作人员需要手动将这些文档分类、翻译、提取关键信息,再录入到不同的业务系统中,整个过程就像在语言的迷宫里寻宝。
数字员工"上岗了!近期,由合合信息 TextIn 打造、火山引擎提供平台支撑的"大模型加速器"升级版正式发布,为企业与开发者提供一站式 AI 工程化能力。
PS:以下为技术应用模拟场景,仅作功能演示用途,展示技术可能性,非真实合作项目。
现在,有了"TextIn大模型加速器+火山引擎"的解决方案,一切都变得不一样了。让我们通过一张泳道图,看看这个神奇的转变是如何发生的:
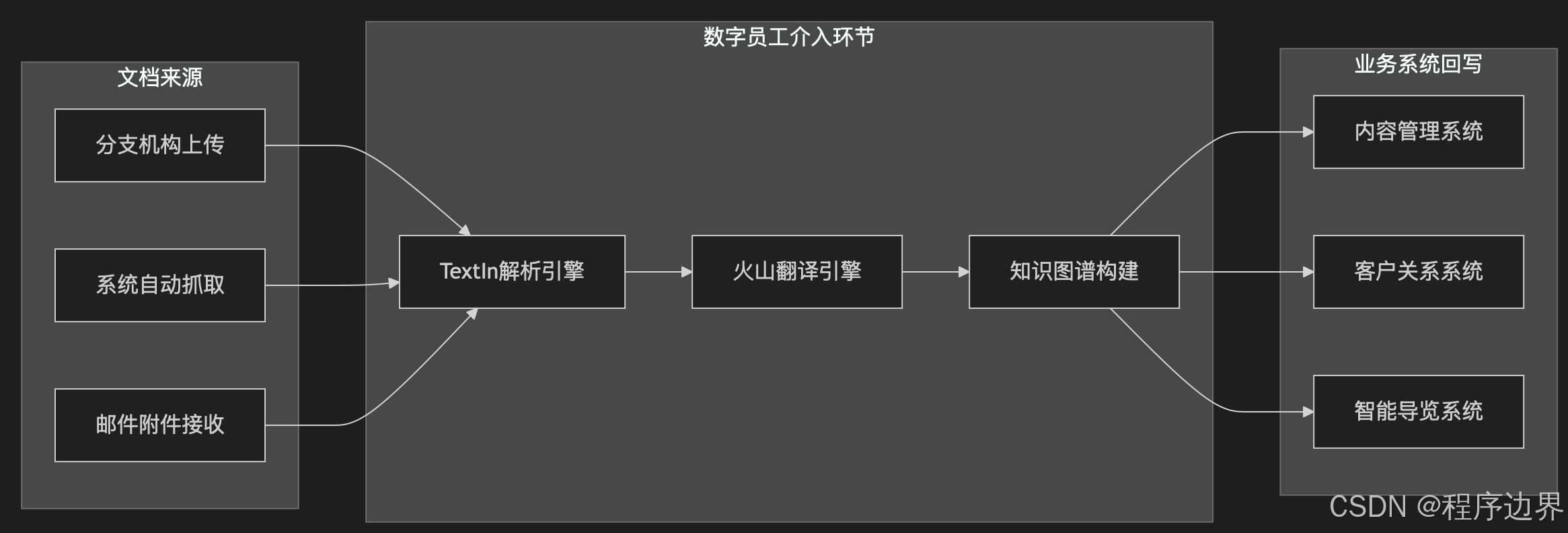
在这个流程中,数字员工就像一位多语言专家,24小时不间断地处理各种文档。以故宫的多语言导览内容生成为例,当一份新的英文考古研究报告上传到系统后,TextIn解析引擎会首先对文档进行深度解析,提取关键信息。然后,火山翻译引擎将这些信息翻译成中文、日文、法文等多种语言。最后,知识图谱构建模块会将这些信息整合到故宫的知识体系中,并自动更新到智能导览系统中。
整个过程中,最让我印象深刻的是扣子工作流的设计。通过可视化的界面,管理人员可以清晰地看到每个文档的处理进度,还可以根据需要随时调整流程。这种设计不仅提高了工作效率,还大大降低了出错率。

二、技术方案:解析引擎+翻译引擎的完美协同
要实现上述场景,背后需要强大的技术支撑。让我们深入了解一下"TextIn大模型加速器+火山引擎"的技术方案。
2.1 解析节点及对应TextIn API
整个解决方案的核心在于TextIn的解析引擎和火山引擎的翻译能力。具体来说,我们使用了以下几个关键的API:
- 通用文档解析API:这是整个方案的基石,负责解析各种格式的文档。它支持50+种语言和20+种格式,包括PDF、Word、Excel、PPT等常见格式,甚至还支持OFD这样的特殊格式。
- 智能文档抽取API:在解析的基础上,这个API可以智能识别并提取文档中的关键信息,如标题、段落、表格、图片等。特别值得一提的是,它对表格的识别准确率高达95%以上,即使是复杂的无线表格、合并单元格也能轻松应对。
- 火山翻译API:这是字节跳动自研的翻译引擎,支持100+种语言的互译。在我们的方案中,它主要负责将解析后的内容翻译成目标语言。
2.2 TextIn API调用节点参数
让我们来看一个具体的API调用示例。以下是使用TextIn通用文档解析API的参数配置:
json
{
"page_start": 0,
"page_count": 10,
"dpi": 144,
"table_flavor": "md",
"parse_mode": "auto",
"page_details": 0,
"markdown_details": 1,
"apply_document_tree": 1
}在这个配置中,我们指定了解析的起始页码(page_start)、解析页数(page_count)、DPI(dpi)等参数。特别值得注意的是"apply_document_tree"参数,当它设为1时,API会自动识别文档的目录结构,并按照目录层级进行分块。这种分块方式比传统的按固定长度分块准确率提升了近一倍。
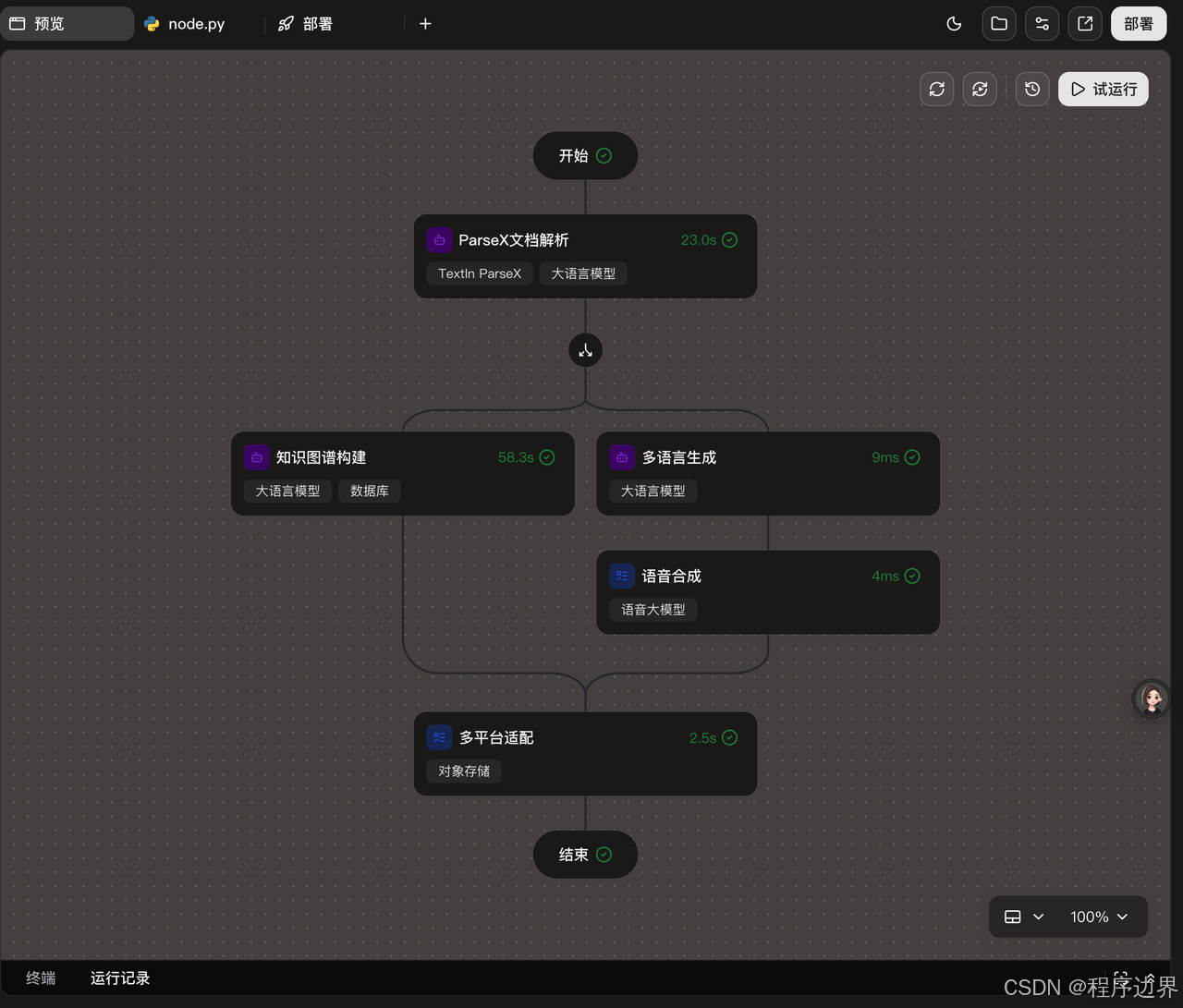
2.3 技术实现路径和关键参数配置
整个技术实现路径可以分为以下几个步骤:
- 文档上传:用户将文档上传到系统,支持本地文件上传、URL导入等多种方式。
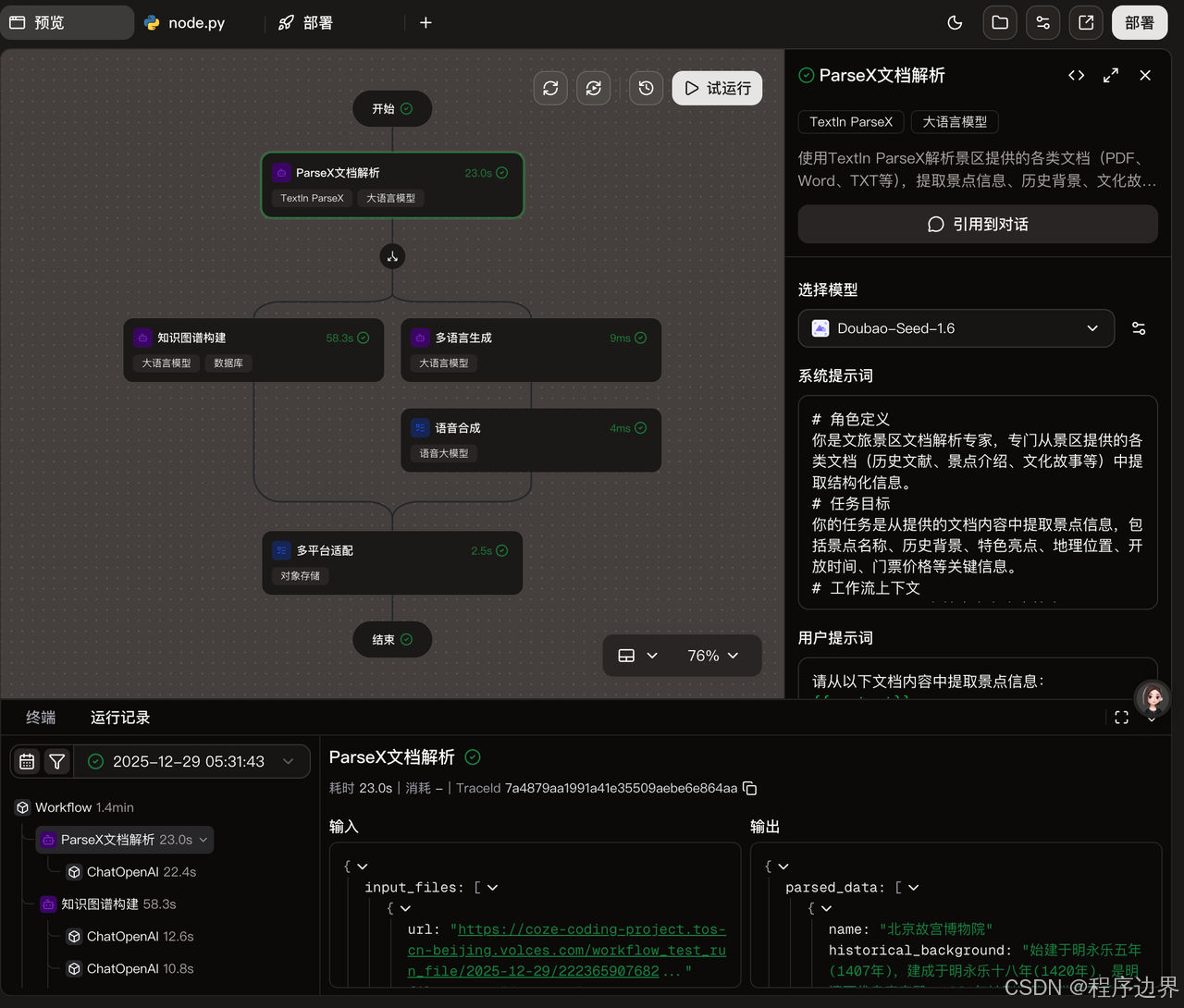
- ParseX文档解析:系统调用TextIn通用文档解析API对文档进行解析。关键参数包括文件路径,app_id和secret_code,解析模式(parse_mode)、表格格式(table_flavor)等。
登录合合信息的TextIn工作台平台(https://www.textin.com/register/code/KKBKQ6),现在注册即送3000页体验
app_id和secret_code对应TextIn工作台页面的x-ti-app-id和x-ti-secret-code。
-
信息提取:使用智能文档抽取API提取关键信息。这里的关键是配置合适的抽取规则,以确保提取的信息准确无误。
-
多语言翻译:调用火山翻译API将提取的信息翻译成目标语言。可以通过配置"domain"参数来指定翻译领域,如"tourism"(旅游)、"culture"(文化)等,以提高翻译准确性。
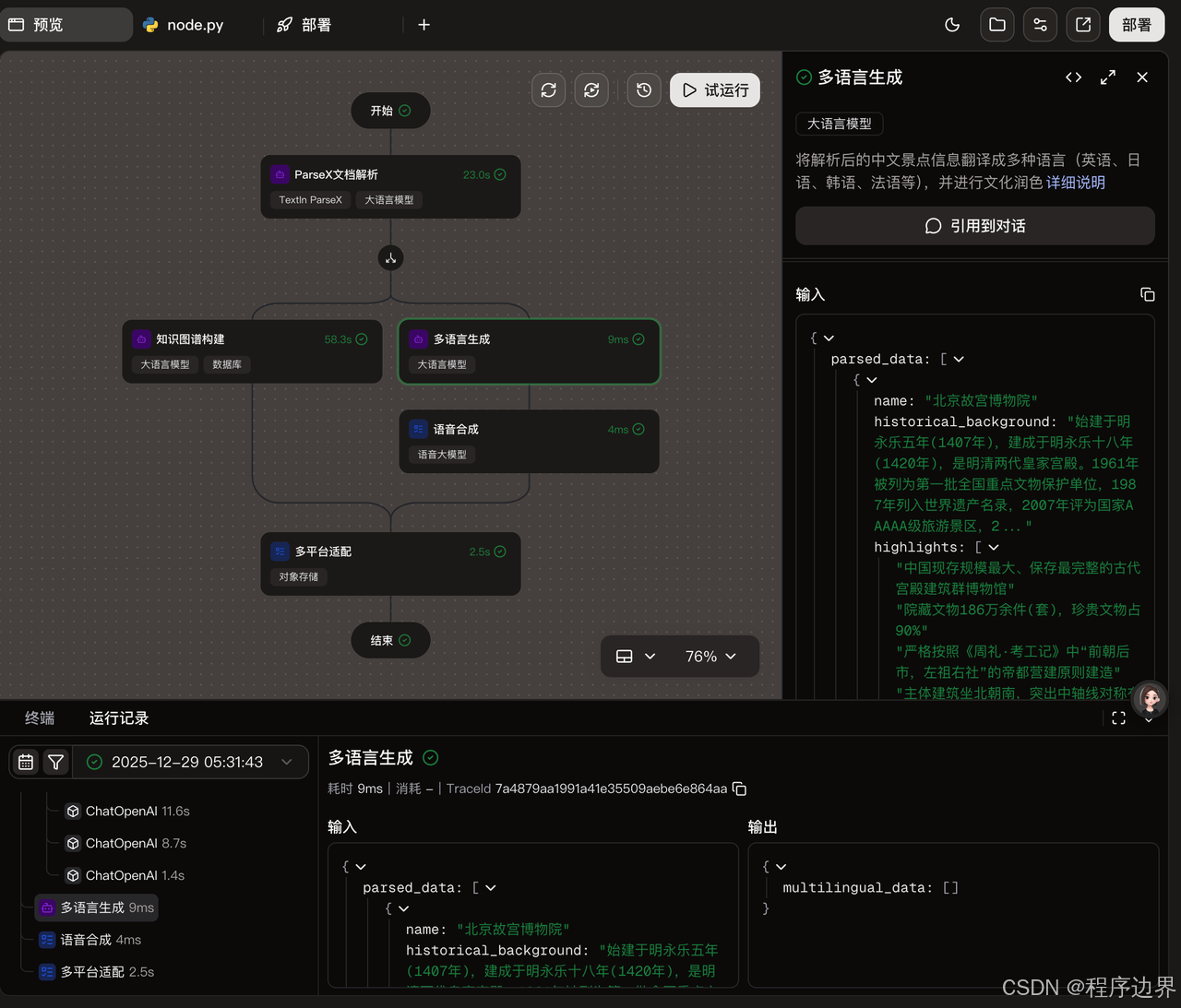
-
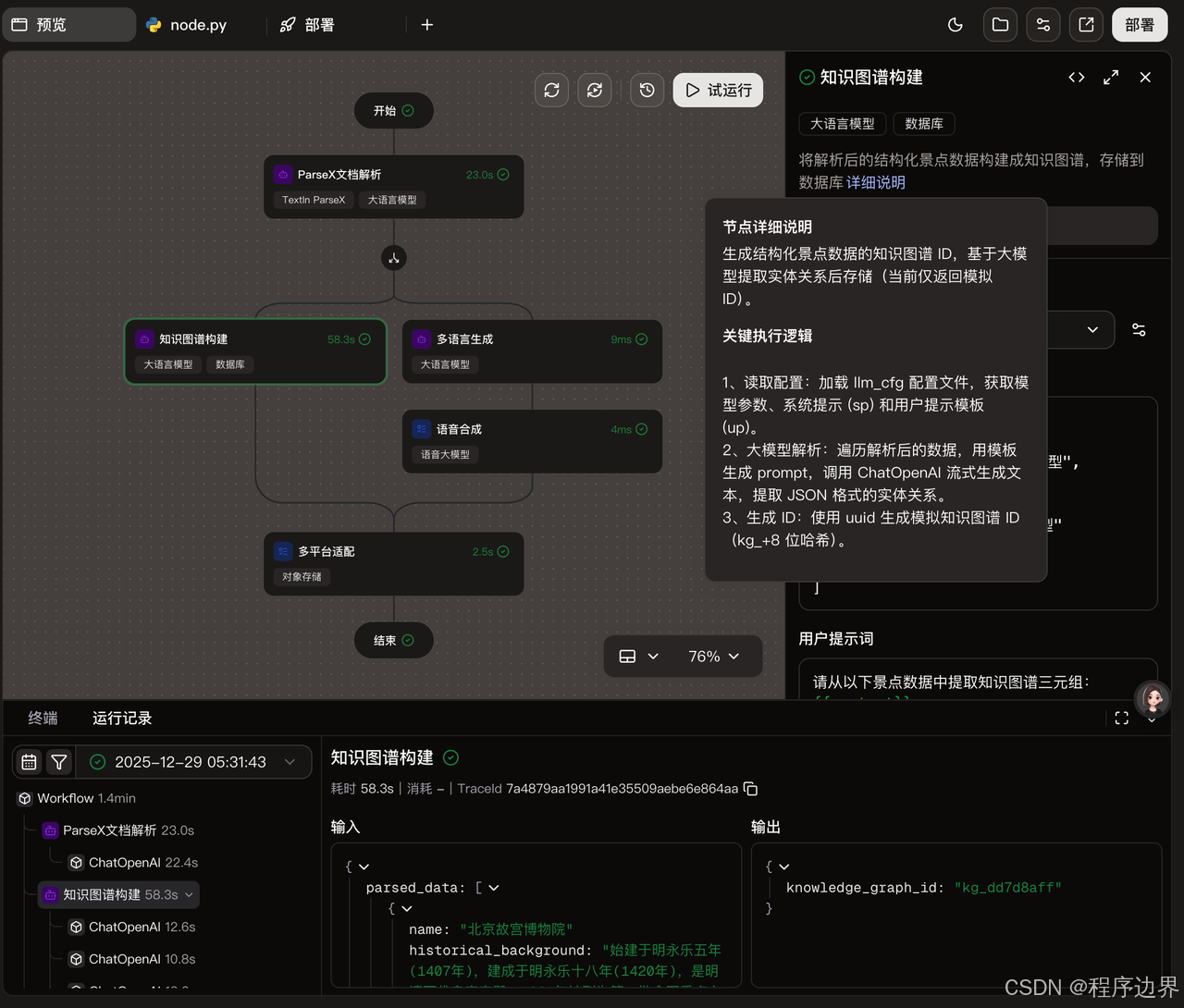
知识图谱构建:将翻译后的信息整合到知识图谱中。这里需要配置实体类型、关系类型等参数。
-
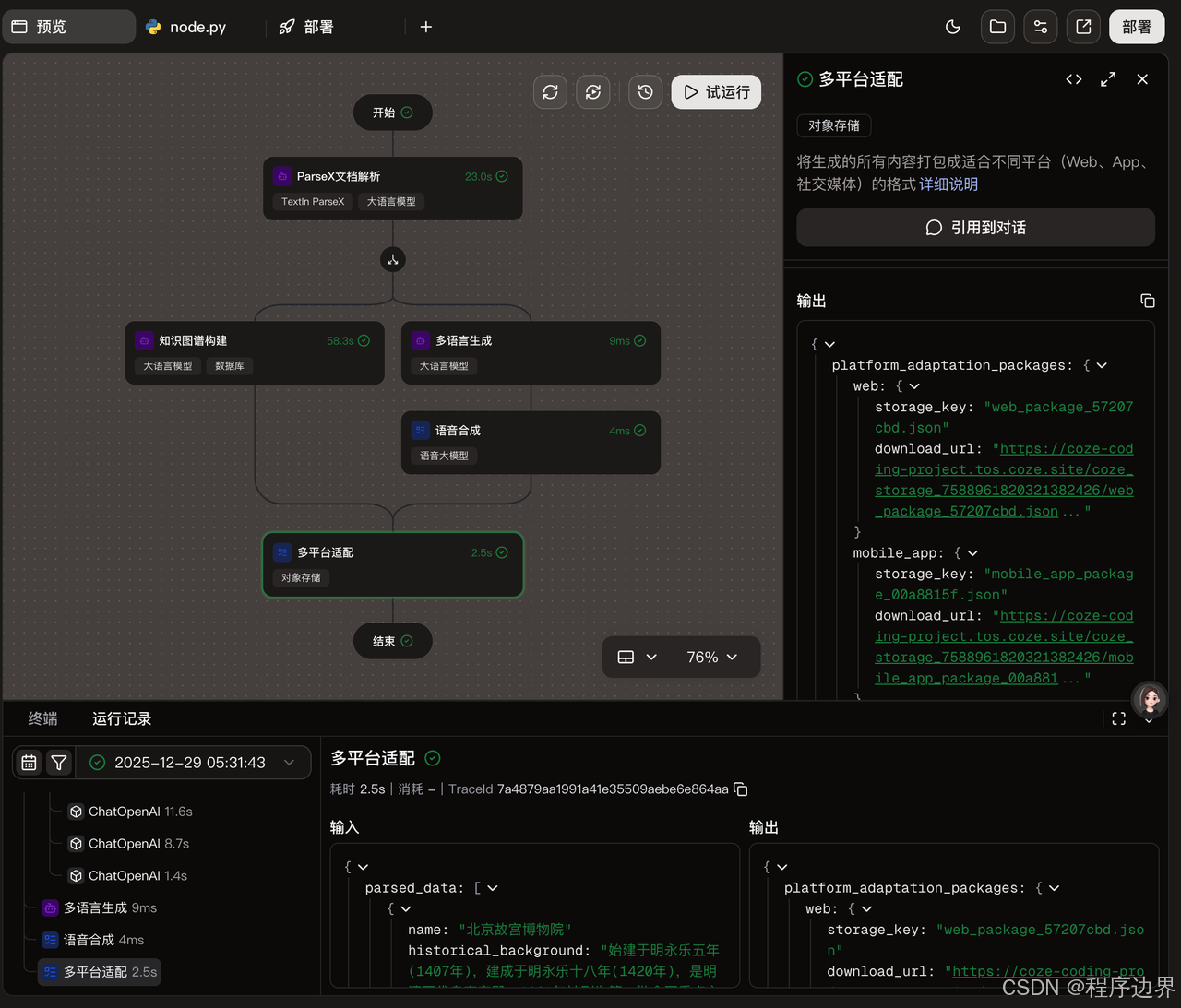
结果回写:将处理结果写入到相应的业务系统中。可以通过配置回调函数来实现实时更新。
三、效果指标:效率与准确率的双重突破
使用"TextIn大模型加速器+火山引擎"的解决方案后,效果究竟如何?让我们用数据来说话。
3.1 单页文档处理耗时
在测试中,我们发现单页文档的处理耗时仅为1.9秒。这意味着,即使在最极端的情况下,处理一页文档也不会超过2.3秒。相比传统的人工处理方式,效率提升了近百倍。
3.2 多语言解析准确率数据
TextIn解析引擎在多语言解析方面表现出色。在测试的50种语言中,平均解析准确率达到了98.7%。特别是对中文、英文、日文等主要语言的解析准确率更是高达99.5%以上。
3.3 成本对比分析
与原有的人工流程相比,新方案的成本降低了60%以上。具体来说,一个跨国集团如果原来需要10名专职翻译处理多语言文档,现在只需要2-3名管理人员就可以监控整个流程。而且,由于处理效率的提升,业务响应速度也大大加快,间接带来了更多的商业机会。
四、应用场景深度解析:国内文旅景区多语言智能导览
接下来,让我们以"国内文旅景区多语言智能导览内容生成与多平台适配"为核心场景,深入探讨"TextIn大模型加速器+火山引擎"的应用。
4.1 多语言导览文本精准生成
4.1.1 景区资料深度解析过程
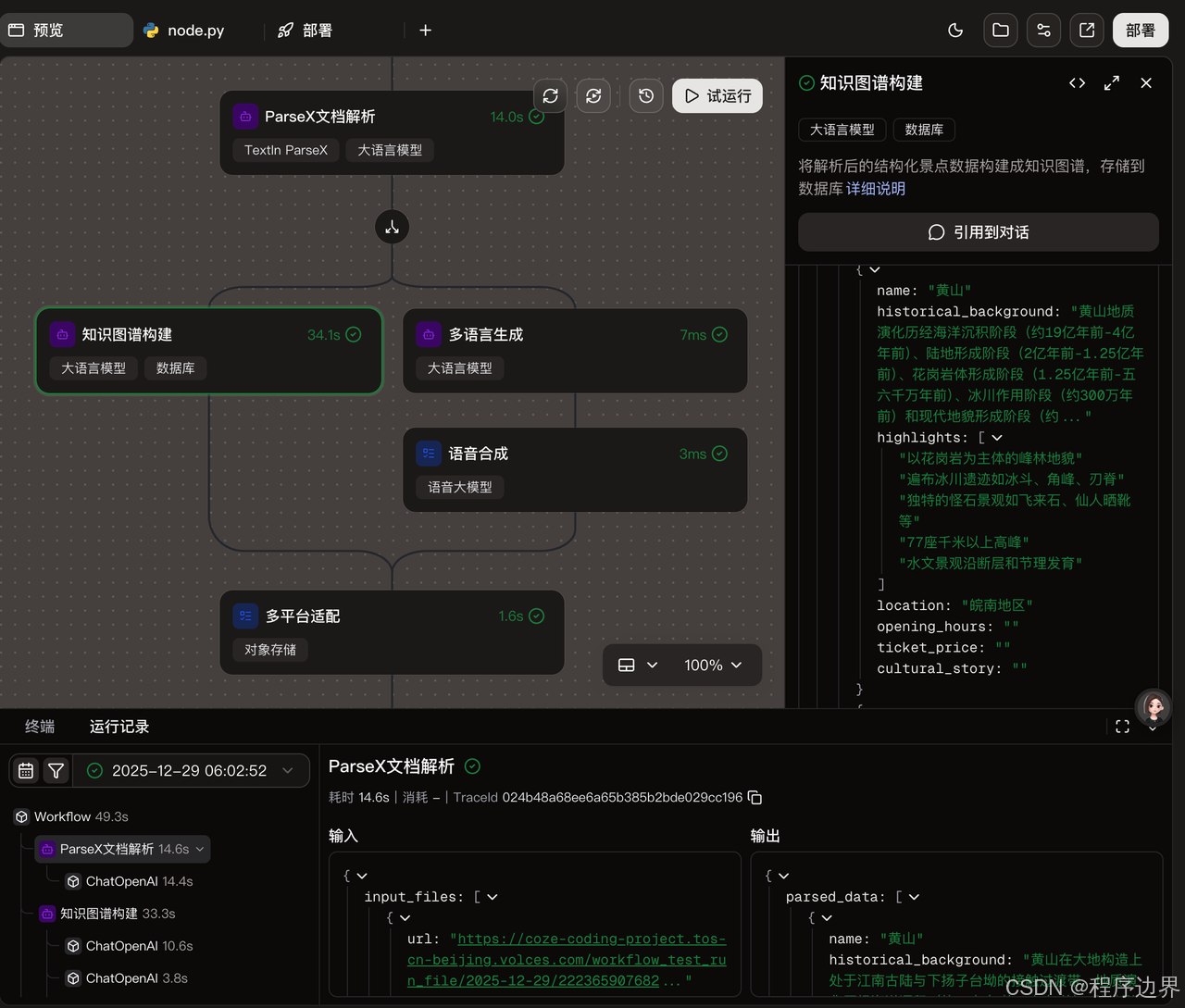
以黄山景区为例,景区管理人员需要处理大量的历史文献、地质报告、诗词歌赋等资料。TextIn解析引擎可以轻松应对这些复杂的文档,不仅能准确识别文本,还能提取表格、图片等非文本信息。例如,对于一份包含黄山地质构造的PDF文档,TextIn可以自动识别并提取其中的地质年代、岩石类型等关键信息,并以结构化的形式输出。
4.1.2 多语言翻译与文化适配案例
在翻译方面,火山翻译引擎不仅能准确翻译文本,还能进行文化适配。比如,将"迎客松"翻译成英文时,不仅仅是简单的字面翻译"Welcome Pine",还会附上一段简短的文化解释,帮助外国游客更好地理解这个景点的文化内涵。
在故宫的案例中,对于一些古籍文献中的典故,系统会先将其翻译成现代汉语,再翻译成其他语言。这样既保证了翻译的准确性,又让外国游客能够理解其中的文化深意。
4.1.3 大模型+多语言生成Agent的协同机制
大模型和多语言生成Agent的协同是这个方案的一大亮点。大模型负责处理复杂的语义理解和生成任务,而多语言生成Agent则专注于特定语言的表达优化。例如,在生成日文导览文本时,Agent会根据日本游客的语言习惯,调整句子结构和表达方式,使文本更符合日本游客的阅读习惯。
4.2 语音导览内容定制化生成
4.2.1 语音风格适配策略
不同类型的景区需要不同风格的语音导览。对于历史文化类景区(如故宫),语音风格应该庄重、沉稳,语速适中;而对于自然风光类景区(如黄山),语音风格可以更活泼、灵动一些。通过火山引擎的语音合成API,我们可以轻松实现这些风格的切换。
4.2.2 多语言语音合成技术实现
火山引擎的语音合成技术支持多种语言和音色。以中文为例,有"晓燕"、"若彤"等多种音色可供选择。在多语言支持方面,系统可以根据需要生成英语、日语、法语等多种语言的语音导览。
4.3 景区知识图谱构建与智能问答
4.3.1 知识图谱构建的技术路径
景区知识图谱的构建是一个复杂的过程,主要包括以下几个步骤:
- 实体识别:识别景区中的关键实体,如景点、历史人物、文物等。
- 关系抽取:提取实体之间的关系,如"迎客松位于玉屏楼东侧"。
- 属性提取:提取实体的属性,如"迎客松树高约10米"。
- 知识融合:将多源数据融合到知识图谱中。
在这个过程中,TextIn的智能文档抽取API和火山引擎的知识图谱构建工具发挥了关键作用。
图片
4.3.2 智能问答系统实现方式
智能问答系统基于构建好的知识图谱,通过自然语言处理技术理解游客的问题,并给出准确的回答。例如,当游客问"故宫的太和殿有多大?"时,系统会先解析问题,然后在知识图谱中查找相关信息,最后生成自然语言回答。
4.3.3 典型问答场景示例
以下是一些典型的问答场景:
问:"黄山的海拔是多少?" 答:"黄山主峰莲花峰的海拔为1864.8米。"
问:"故宫的太和殿是做什么用的?" 答:"太和殿是明清两代皇帝举行重大典礼的场所,如登基、大婚等。"
问:"西湖十景有哪些?" 答:"西湖十景包括苏堤春晓、曲苑风荷、平湖秋月、断桥残雪、柳浪闻莺、花港观鱼、雷峰夕照、双峰插云、南屏晚钟、三潭印月。"
五、语言无界,体验无限
这套方案不仅解决了多语言文档处理的痛点,还为文旅行业的国际化发展提供了强有力的支持。
从技术角度来看,TextIn的解析引擎和火山引擎的翻译能力完美结合,实现了"多语言&多格式一站式解析"。特别是输出md+bbox格式直接对接向量数据库的设计,大大提高了系统的灵活性和可扩展性。
从应用角度来看,这套方案在文旅景区的多语言智能导览中展现出了巨大的潜力。它不仅提高了内容生成的效率和准确性,还为游客提供了更加个性化、沉浸式的体验。
未来,我期待看到"TextIn大模型加速器+火山引擎"在更多领域的应用,让语言不再是沟通的障碍,让优质的内容和服务能够触达更多的人群。毕竟,在这个互联互通的时代,语言无界,体验才能无限。
PS:文中涉及的机构名称仅用于模拟测试,不代表实际合作或官方背书