1. 并发编程的基础知识
- 并发和并行的区别?
1.1 并发模型
1.1.1 抢占式
总控制权在操作系统手中,操作系统会轮流询问每一个任务是否需要使用 CPU,需要使用的话就让他使用,不过在一定时间之后,操作系统会剥夺当前任务的 CPU 使用前,把他排在询问队列的最后,再去询问下一个任务
- 例如
- windows
1.1.2 协作式
一个任务得到了 CPU 时间,除非他自己放弃使用 CPU,否则将完全霸占 CPU,所以任务之间需要写作,使用一段时间 CPU 然后放弃,其他任务也是如此,这样才能保证系统正常运行
- 例如
- 嵌入式系统,例如早期的游戏机系统
1.2 同步编程原语(Windows)
1.2.1 用户态和内核态
-
用户态: CriticalSection, SRWLock, InterLocked
-
内核态: Mutex, Event, Semaphore, AsyncIO
-
优缺点
- 用户态:速度快,无法命名,无法设置超时,容易卡死
- 内核态:速度慢(用户/内核态切换),可命名,可设置超时
-
推荐参考书
- Windows Via C++
-
问题:大的分布式系统,访问共享资源,如何加锁
-
答:把锁放在数据里面,利用数据库的锁和事务的特性就解决了
1.3 关键字
-
Volatile 关键字(嵌入式系统非常重要)
- 提醒编译器他后面所定义的变量随时都可能发生改变,因此编译后的程序每次需要存储或者读取这个变量的时候,都会直接从变量地址中读取数据,如果没有 Volatile 关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致现象。
- 无锁编程
-
无锁编程
- 利用 Compare and Swap 原子操作
- 不推荐使用,可移植性和可读性都有问题
1.4 异步编程模型
-
案例
- 阿里 Dubbo 中间件系统
- Nginx
- Linux: epoll
- Windows: AsyncIO
-
多线程能解决 C10K 问题吗?
- 有十万个并发,多线程扛不住,线程的调度资源就很大
- 线程的本身也有很大的开销
- 线程不是很多的时候,可以做线程池的优化
IO 密集型,而不是 CPU 密集型的话,用异步可以极大提高效率
- 如何利用单线程支持多任务?
- 建立正确的异步世界观
- HTTP 服务器案例
1.5 高并发系统如何优化
- 降低所的粒度和锁的持有时间
- 使用读写分离锁
- 确保顺序获取锁
TA: x, yTB: x, y
- 重要场景要设置超时等待时间,不能无线等
- 减少对写共享资源的访问依赖
- 宁可做多份,分散开,也不要大量挤在一起去访问
- 同步变异步优化 CPU 使用率,避免过多的线程切换浪费 CPU 资源
- 线程切换的成本比较大
2. Map/Reduce
2.1 简介
-
为什么要 Map/Reduce?
-
Map/Reduce 是什么
- Map: 分解工作,把一个大任务分解成独立不相关,可以并行的子任务并完成处理
- Reduce:把每个子任务的处理结果汇总成最终的结果
-
单机版矩阵乘法的例子
a[i][j] = i行 * j列- 结合稀疏矩阵的运算
- GPU 更快
-
单机版 TopK 计算的例子
- 一亿个数,找到最大的 500 个
- 排序 nlog(n)
- 拆成 100 份, 100 万个数找最大的 500 个
- 一亿个数,找到最大的 500 个
-
作业
- 自己去搭建一个单机版的 hadoop 集群
- 跑单词统计
- 实在不行,用 python 的 map reduce 函数,实现超简化版本的
2.2 Hadoop 与 Spark 的区别
- Hadoop 实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件。
- Hadoop 还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度。
- Spark,则是那么一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
- 在内存中做流数据处理
- Hadoop 更庞大
- 包含分布式文件系统
- spark 可以替换 hadoop 的某个组件,hadoop 提供的是整个分布式处理的基础服务,包括分布式存储,工作的断点继续,工作记录的保存,包括 map reduce 模块
- 是一个大而全的东西,所以他慢
2.2 为什么 Spark 速度更快?
- MapReduce 是分步对数据进行处理的: 从集群中读取数据,进行一次处理,将结果写到集群,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群,等等...
- Spark 会在内存中以接近"实时"的时间完成所有的数据分析:"从集群中读取数据,完成所有必须的分析处理,将结果写回集群,完成。
- Hadoop 可以和 Spark 一起工作,也可以各自独立与其他工具组合。
- 什么时候用 Spark,Hadoop
- 有些是实时流处理,可以忍受丢数据,但要快速得到结果,结果不必是最优的,用 Spark
- 每天有海量的商业数据做分析,数据在内存里面装不下,用 Hadoop,可以一块一块的处理,保存之后在处理,中间结果也可以有效保存下来
3. 分布式系统设计简介
3.1 CAP
-
关于 CAP 问题
- C = Consistency 一致性
- A = Availability 可用性
- P = Partition Tolerance 容错性
-
CPA 三个指标不可能被同时满足,最多同时满足其中两项。
-
CAP 场景分析
- 假设我们使用一台服务器 A 对外提供存储服务,为了避免服务器宕机导致服务不可用,我们又部署了服务器 B 做为备份。每次用户往 A 写入数据时,A 同步在 B 上写入备份。用户在读取数据时可以任意从 A 或 B 读取写入的历史和最新数据。
- 故障发生,A 和 B 之间网络中断导致无法通信,用户往 A 写入数据时,B 没有更新,针对这种情况我们策略该如何设计?
- 牺牲可用性 A:A 停止数据写入服务,但是依然可以读取,一致性得到保证。
- 牺牲一致性 C:A 选择不把数据写入 B 就向用户返回操作成功。可用性得到保证。
- 弱 CPA 可以满足,比如放弃强一致性而选择最终一致性。比如淘宝大促时的各种限流开关。
3.2 传统服务架构的局限性
- 单机性能处理有上限
- 负载分配不均衡。
- 开发、升级成本高
- 部署成本高
- 维护成本高
3.3 微服务架构简介
- 拆分服务,通过 RPC 通讯进行协同工作
- 负载更均衡,服务弹性更强。
- 理论吞吐量更高
- 开发部署效率更高
- 缺点
- 通讯成本高
- 依赖导致的部署成本
- 服务治理和故障调试
3.4 分布式系统常见优化方案
- 动静分离
- CDN
- 多级访问,缓存读优化
- 牺牲强一致性,改为最终一致性。
- 同步变异步,通过队列传递消息。
4. 分布式存储系统设计案例
4.1 常见挑战
- 数据的高效检索
- 数据的高效存储
- 数据冗余与效率的平衡
- 灾难恢复
- 小文件存储优化
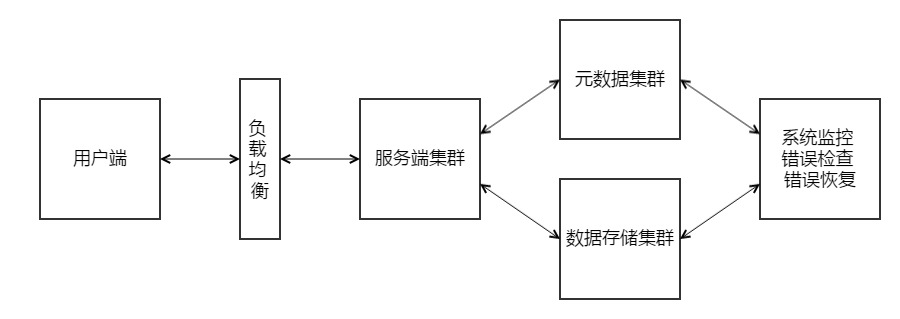
4.2 解决方案
- 元数据(meta data)通过数据库独立存储,通过元数据访问实际存储数据。
- 增量存储与压缩合并
- 增量
- 如果一直变,增量做合并
- 通过专门算法降低冗余存储
- 早期亚马逊,盛大做云存储,数据都是一式三份,很浪费
- EMC(易安信,2016 年,EMC 公司被戴尔科技(Dell Technologies) 以 670 亿美元的天价收购,现在叫 Dell EMC)搞了一个很牛逼的算法,一份数据只要拿出来三分之一做冗余即可,把一份数据打成 12 块,12 块数据存储在 12 块硬盘上,只要没有 4 块硬盘同时坏,那就没问题,因为他们有运维脚本,实时监控数据的完整性,有哪一份数据,找到的块数少于 12 块,如果找到的只有 9 块,那会把剩余的 3 块恢复出来,只要硬盘坏的速度没有运维脚本扫描的速度快,那么就是安全的。当时他们一个数据中心,差不多 12 万 块硬盘,一个数据中心,5000 台服务器,每台服务器,24 块硬盘,差不多一年坏 1%,一年坏 1000 块左右
- 运维脚本实时监控扫描数据完整性
- 小文件直接数据库存储,或者合并存储,在元数据中记载偏移量和大小信息。
- 小文件容易浪费空间
4. 从数字货币谈共识机制
4.1 简介
- 比特币的区块链本质是分布式账本
- 分布式账本面临谁来记账的问题
- 比特币运行的环境毫无信任可言
- 比特币愿意支付什么代价
- 计算成本
- 不要求实时计算,效率可以牺牲。
4.2 共识机制的实现
- 完成工作量证明,首先证明的拿到记账权。
- 将交易记录打包生成新区块,同时广播告诉其它节点。同时系统对记账者发放奖励,俗称"挖矿"
- 其它节点收到广播后对新区块就行校验,接收后继续广播,最终全网接收,交易确认。
5. 设计模式
5.1 设计模式常见面试题目
- 如何编写一个线程安全的单例
- 什么是 IOC,IOC 的优点与应用举例
- 通过配置文件控制代码的行为
- 现在是通过注解来
- 工厂模式应用场景
- 配置文件告诉要什么,就生产什么
- 面向接口编程
- 开放闭合原则的应用案例
- 推荐教材:大话设计模式
5.2 面试经验分享
- 精简建立,突出重点
- 不打无准备之仗
- 白板编程先确认题目,明确思路,先实现再优化
- 架构问题想办法往经典套路靠拢
6. 作业
- 阅读 Windows Via C++并发编程部分内容
- 阅读大话设计模式并实践全部例子代码,了解各个设计模式实现原理和应用场景。
- 配置单机版 hadoop 并跑通基本的单词计数案
例。参考链接: