1、Seata配置中心
Seata支持哪些配置中心?
- nacos
- consul
- apollo
- etcd
- zookeeper
- file (读本地文件, 包含conf、properties、yml配置文件的支持)
在seata的安装包conf目录下有一个application.example.yml文件,这个文件里有各种配置中心的配置示例
1.1、nacos配置
参考application.example.yml文件中nacos的配置
yaml
seata:
config:
# support: nacos 、 consul 、 apollo 、 zk 、 etcd3
type: nacos
nacos:
server-addr: 192.168.0.109:8848
namespace:
group: SEATA_GROUP
username: nacos
password: nacos
context-path:
##if use MSE Nacos with auth, mutex with username/password attribute
#access-key:
#secret-key:
data-id: seataServer.properties替换application.yml文件中的原配置
yaml
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: file修改完后重启
1.2、推送配置
在seata的安装包script/config-center,目录下对应有各个seata支持的配置中心的推送脚本,比如nacos目录下:
shell
ubuntu@ubuntu-server-mixer:~/tools/seata/seata/script/config-center/nacos$ ll
total 24
drwxr-xr-x 2 ubuntu ubuntu 4096 Dec 30 21:55 ./
drwxr-xr-x 7 ubuntu ubuntu 4096 Dec 30 21:46 ../
-rw-r--r-- 1 ubuntu ubuntu 2877 Jan 6 2023 nacos-config-interactive.py
-rwxr-xr-x 1 ubuntu ubuntu 3463 Jan 6 2023 nacos-config-interactive.sh*
-rw-r--r-- 1 ubuntu ubuntu 1927 Jan 6 2023 nacos-config.py
-rwxr-xr-x 1 ubuntu ubuntu 2851 Jan 6 2023 nacos-config.sh*其中分为py脚本和shell脚本,带interactive的是交互式的脚本,也就是会在执行的时候提示输入相关的参数,比如nacos主机、端口号、账号密码等等,不带interactive的是需要在执行的时候填对应的参数的,比如:
shell
-h: nacos主机
-p: nacos端口号
-t: nacos租户,也就是命名空间的ID
-u: nacos账号
-w: nacos密码可以直接执行sh nacos-config-interactive.sh,等到执行完成之后可以看到在nacos的配置管理>配置列表菜单下多出了一百多条配置信息,这些信息源自seata安装目录下的script/config-server/config.txt文件,所以可以提前修改好这个文件,特别是下面几个配置项:
properties
# 修改为自己的seata地址
service.default.grouplist=192.168.0.109:8091
# 改为数据库存储,这个时候需要新建一个数据库,并且执行seata安装目录下的script/server/db下对应数据库类型的sql脚本,比如我的是mysql,就执行mysql.sql
store.mode=db
# 修改数据库的连接信息
store.db.driverClassName=com.mysql.cj.jdbc.Driver
# 我自己建的数据库名称为seata-2.0.0
store.db.url=jdbc:mysql://192.168.0.109:3306/seata-2.0.0?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=root1.3、集中配置
上述推送的配置是每个配置项作为一个dataId,非常不便于管理,seata从1.4.2版本之后支持将这些文件集中到一个配置文件里边,seata的nacos的配置在ConfigNacosProperties这个类中,如下图所示:

可以看到默认的dataId是seata.properties,但是之前在配置seata-server的时候默认的dataId又是seataConfig.properties,所以要注意前后一致。我们这里统一用seataConfig.properties
1.4、修改客户端配置
在上一篇文章的下单案例的基础之上,我们给每个seata事务参与者添加对应的配置
properties
seata.data-source-proxy-mode=AT
seata.config.type=nacos
seata.config.nacos.group=SEATA_GROUP
seata.config.nacos.username=nacos
seata.config.nacos.password=nacos
seata.config.nacos.server-addr=192.168.0.109:8848
seata.config.nacos.data-id=seataServer.properties1.5、执行接口
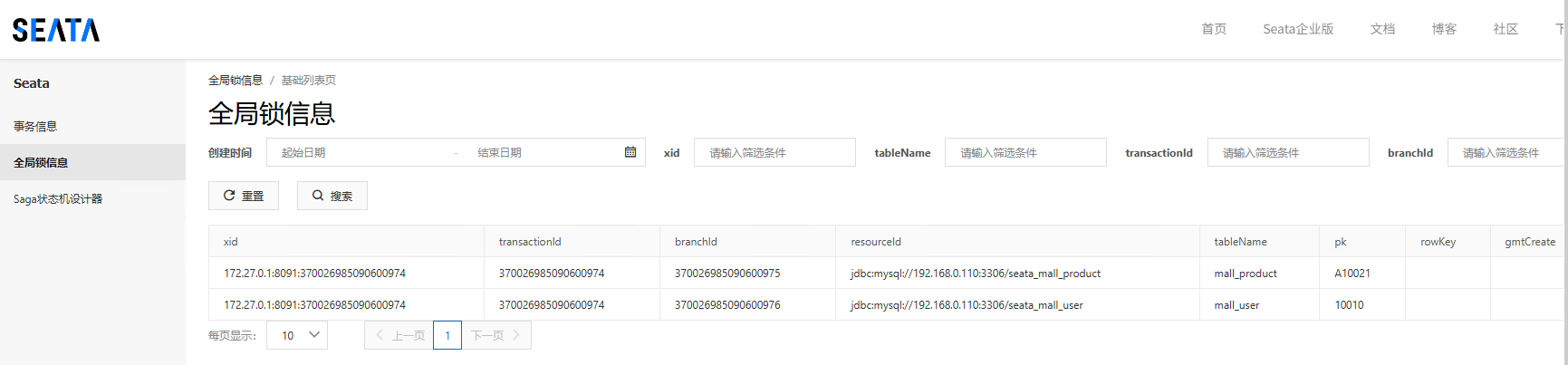
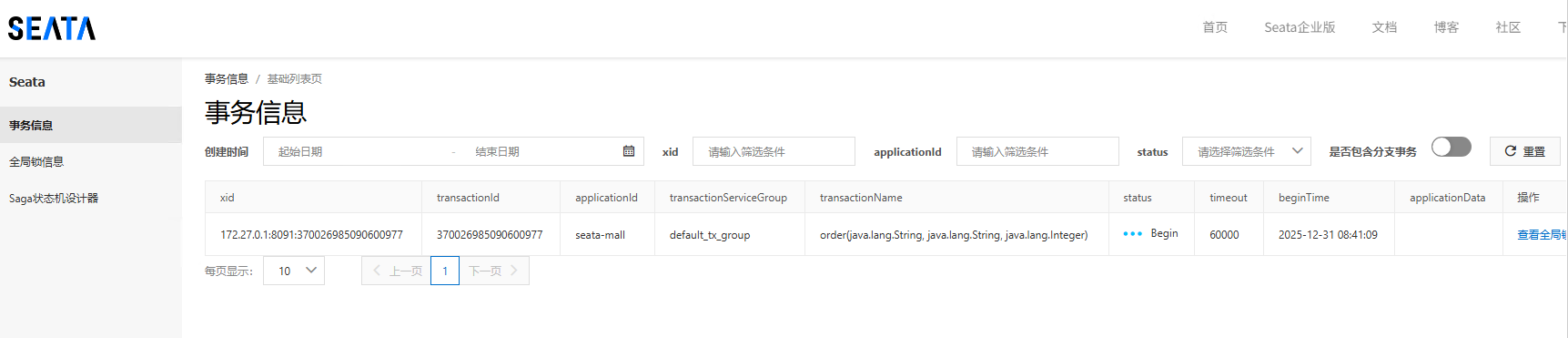
配置完成后,将四个应用都启动起来,然后用postman调用一下,并且在order服务里打一个断点,可以看到当程序执行到order的时候seata控制台多了两条全局锁信息和一条
同时,在user的数据库和product的数据库和order的数据库中的undo_log表也多了一条记录:

其中rollback_info信息copy出来如下:
json
{"@class":"org.apache.seata.rm.datasource.undo.BranchUndoLog","xid":"172.27.0.1:8091:370026985090600977","branchId":370026985090600980,"sqlUndoLogs":["java.util.ArrayList",[{"@class":"org.apache.seata.rm.datasource.undo.SQLUndoLog","sqlType":"INSERT","tableName":"mall_order","beforeImage":{"@class":"org.apache.seata.rm.datasource.sql.struct.TableRecords$EmptyTableRecords","tableName":"mall_order","rows":["java.util.ArrayList",[]]},"afterImage":{"@class":"org.apache.seata.rm.datasource.sql.struct.TableRecords","tableName":"mall_order","rows":["java.util.ArrayList",[{"@class":"org.apache.seata.rm.datasource.sql.struct.Row","fields":["java.util.ArrayList",[{"@class":"org.apache.seata.rm.datasource.sql.struct.Field","name":"amount","keyType":"NULL","type":-5,"value":["java.lang.Long",19600]},{"@class":"org.apache.seata.rm.datasource.sql.struct.Field","name":"num","keyType":"NULL","type":4,"value":2},{"@class":"org.apache.seata.rm.datasource.sql.struct.Field","name":"order_id","keyType":"PRIMARY_KEY","type":4,"value":7},{"@class":"org.apache.seata.rm.datasource.sql.struct.Field","name":"product_id","keyType":"NULL","type":12,"value":"A10021"},{"@class":"org.apache.seata.rm.datasource.sql.struct.Field","name":"user_id","keyType":"NULL","type":12,"value":"10010"}]]}]]}}]]}也就是对应事务数据的事务操作前和操作后的镜像,待跳过断点将程序执行完后undo_log日志也会自动删除,而数据库中的余额、库存和订单仍然能够保持数据一致,也就是我们的分布式事务仍然是生效的
但是这里还有一个问题,在content字段中可以看到serialzer=jackson字样,这是因为默认采用的jackson序列化方式
properties
client.undo.logSerialization=jacksonseata支持多种序列化方式,比如kryo,所以接下来给nacos上的配置改为kryo,并且给所有的seata事务参与方都添加kryo的jar包,否则会提示xxxClassNotFound
xml
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.2</version>
</dependency>
<dependency>
<groupId>de.javakaffee</groupId>
<artifactId>kryo-serializers</artifactId>
<version>0.45</version>
</dependency>重启后再次执行,可以看到已经编程了kryo了

而rollback_info内容也看不懂了:

这里为什么换成kryo?因人因业务场景而异,只是演示多一种可能多一种选择,kryo相对来说会有更快的序列化和反序列化以及更小的序列化后的数据体积,但是在可读性上确实不如我们习以为常的json
为什么要用配置中心呢?主要目的是为了进行配置的统一管理,在客户端只需要简单配置一下对应的nacos地址就可以了
2、Seata注册中心
Seata支持哪些注册中心?
- eureka
- consul
- nacos
- etcd
- zookeeper
- sofa
- redis
- file (直连)
这里还是以nacos注册中心为例
2.1、修改seata-server的配置
修改seata-server安装目录下conf/application.yaml,添加对应nacos注册中心的配置
yaml
registry:
# support: nacos 、 eureka 、 redis 、 zk 、 consul 、 etcd3 、 sofa
type: nacos
nacos:
application: seata-server
server-addr: 192.168.0.109:8848
group: SEATA_GROUP
namespace:
cluster: default
username: nacos
password: nacos
context-path:
##if use MSE Nacos with auth, mutex with username/password attribute
#access-key:
#secret-key:
data-id: seataServer.properties修改完成后,重启seata-server,可以看到在nacos的控制台的服务列表中看到我们的seata-server服务了
2.2、客户端配置修改
修改各个seata分布式事务参与方的配置文件
properties
seata.registry.type=nacos
seata.registry.nacos.cluster=default
seata.registry.nacos.application=seata-server
seata.registry.nacos.group=SEATA_GROUP
seata.registry.nacos.username=nacos
seata.registry.nacos.password=nacos
seata.registry.nacos.server-addr=192.168.0.109:8848配置文件都修改完后重新执行,发现分布式事务还是生效的
那为啥还要引入注册中心呢?个人理解还是为了统一管理。之前原始的方式是在客户端要配置default.grouplist指向对应的seata-server,引入配置中心和注册中心之后这些就不需要在客户端进行配置了,seata会从注册中心去找seata.registry.nacos.cluster配置对应的集群,比如这里是default集群,也就是我们注册到nacos上的seata-server服务
3、Seata事务分组
我们在前面Seata的使用的过程中知道,在Seata Client端的file.conf配置中,有一个vgroup_mapping属性,它表示事务分组映射,是Seata的资源逻辑,类似于服务实例的概念,主要的作用就是根据分组来获取Seata Server的服务实例
3.1、通过事务分组如何找到后端集群?
- 程序会通过用户配置的配置中心去寻找
service.vgroupMapping.[事务分组配置项],取得配置项的值就是TC集群的名称 - 拿到集群名称程序通过一定的前后缀+集群名称去构造服务名,各配置中心的服务名实现不同
- 拿到服务名去相应的注册中心去拉取相应服务名的服务列表,获得后端真实的TC服务列表
假如我们有一个项目
mall-order-provider1、它的
txServiceGroup=test_tx_group,这个代表该实例的事务分组test_tx_group2、通过拼接,
service.vgroupMapping.test_tx_group,去配置中心查找集群名,得到的是default3、拼接
service.default.grouplist,查找集群名对应的Seata Server的服务地址,从而进行事务的处理
3.2、为什么设计一个这样的事务分组?
这里多了一层获取事务分组到映射集群的配置。这样设计后,事务分组可以作为资源的逻辑隔离单位,出现某集群故障时可以快速failover,只切换对应分组,可以把故障缩减到服务级别,但前提也是你有足够server集群。
3.3、事务分组与高可用
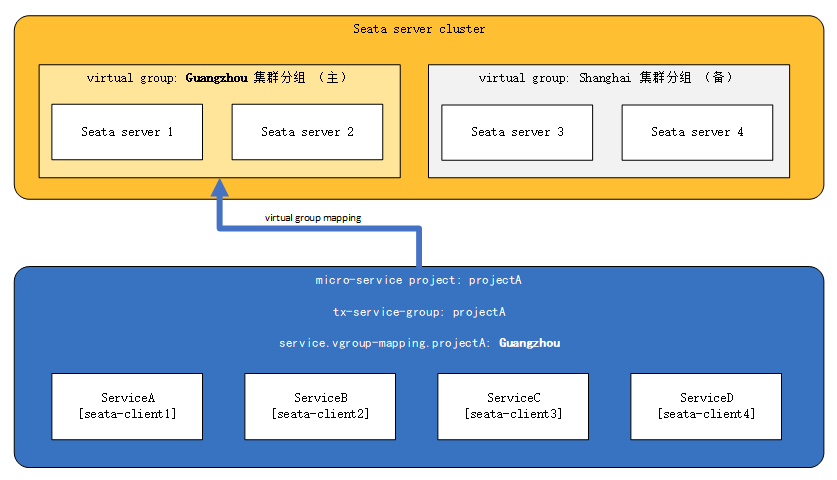
3.3.1、TC异地多机房容灾
集群出现故障随时切换
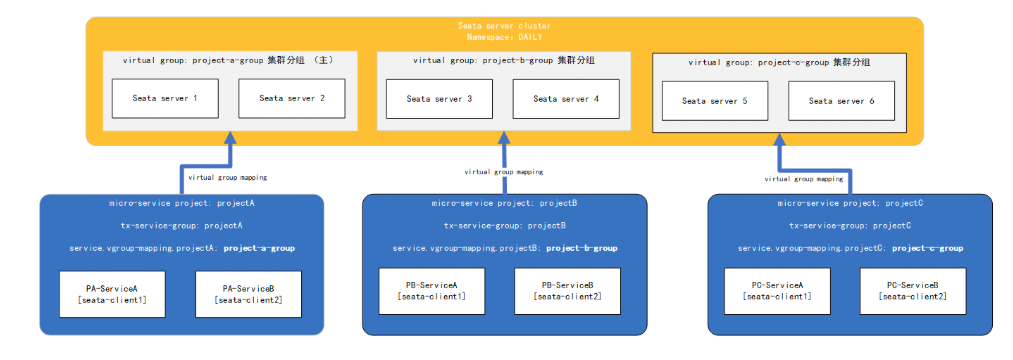
3.3.2、单一环境多应用接入
将seata集群的不同分组提供给不同的项目的多个服务,比如将a分组给项目A的服务a和服务b,将b分组分配给项目B的服务a和服务b,将c分组分配给C项目的服务a和服务b,从而实现项目A、项目B和项目C这三个项目共用一套seata集群环境
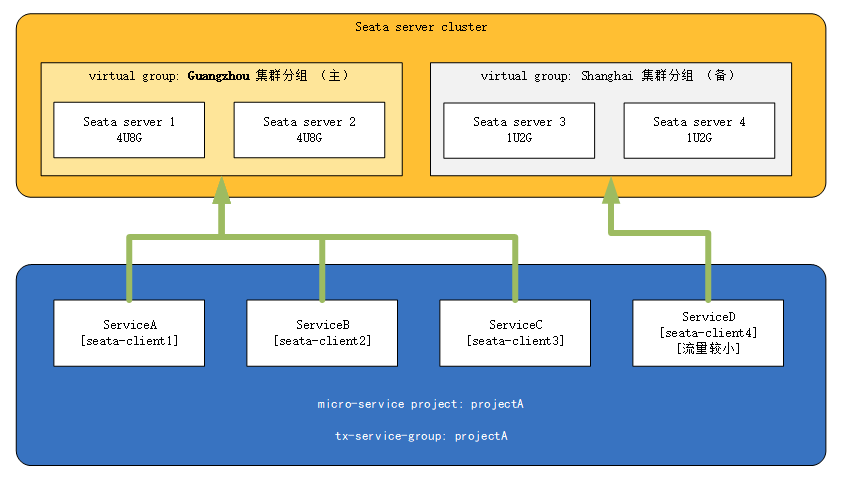
3.3.3、client精细化管理
- 假定现在存在seata集群,Guangzhou机房实例运行在性能较高的机器上,Shanghai集群运行在性能较差的机器上
- 现存微服务架构项目projectA、projectA中有微服务ServiceA、ServiceB、ServiceC与ServiceD
- 其中ServiceD的流量较小,其余微服务流量较大
那么此时,我们可以将ServiceD微服务引流到Shanghai集群中去,将高性能的服务器让给其余流量较大的微服务(反之亦然,若存在某一个微服务流量特别大,我们也可以单独为此微服务开辟一个更高性能的集群,并将该client的virtual group指向该集群,其最终目的都是保证在流量洪峰时服务的可用)
3.3.4、seata的预发布环境和生产环境隔离