目录
[1.1 用强化学习(RL)给画质"磨皮"](#1.1 用强化学习(RL)给画质“磨皮”)
[1.2 治好了数值的"抖动病"](#1.2 治好了数值的“抖动病”)
[2.1 传统架构的"割裂感"](#2.1 传统架构的“割裂感”)
[2.2 自回归的"原生融合"](#2.2 自回归的“原生融合”)
[3.1 "六小龙"的分化](#3.1 “六小龙”的分化)
[3.2 开源生态的布局](#3.2 开源生态的布局)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阶跃星辰开源NextStep-1.1图像模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
**2025年的大模型赛道,到了年底依然火药味十足。**智谱、MiniMax忙着冲刺IPO,Kimi和DeepSeek在推理模型上打得不可开交。相比之下,"六小龙"之一的阶跃星辰显得有些过于安静。
但安静不代表停滞。就在大家以为他们"闭关锁国"的时候,阶跃星辰悄悄丢出了一个小更新------NextStep-1.1。
这次更新没有铺天盖地的宣传,却精准地解决了一个让技术人员头秃的问题:怎么让自回归模型生成的图片,不再满屏"鬼影"和"马赛克"?

一、从"能用"到"好用":NextStep-1.1修了啥?
要理解1.1版本的改进,我们先得回顾一下它的前身NextStep-1。
NextStep-1采用了一种很新颖的架构------自回归流匹配(Autoregressive Flow-Matching)。简单来说,它试图用一种模型(Transformer)同时搞定文本和图像,不像传统方法那样,文本归文本,画图归画图(扩散模型)。

理想很丰满,但现实很骨感。NextStep-1虽然能画图,但经常"翻车"。用户最直观的感受就是:生成的图片有时候会出现莫名其妙的色块、网格状的纹理,甚至结构崩坏的"鬼影"。
这就是所谓的"可视化失败"(Visualization Failures)。

NextStep-1.1的核心任务就是"修Bug"。它通过两大手段,把这些毛病给治好了:
1.1 用强化学习(RL)给画质"磨皮"
在图像生成领域,强化学习通常是用来对齐人类偏好的。NextStep-1.1把RL用在了"磨皮"上。它通过后训练(Post-training),强行修正了模型生成的纹理细节。
结果就是,图片里的噪点变少了,边缘更锐利了,那些讨厌的"马赛克"和伪影也大幅减少。现在的图,看起来终于像一张专业的摄影作品,而不是显卡过热时的花屏截图。
1.2 治好了数值的"抖动病"
之前的模型之所以会画崩,根本原因是在高维空间里算数时"手抖"了(数值不稳定性)。NextStep-1.1优化了底层的计算逻辑,让模型在处理复杂的连续图像Token时更稳。这就好比给手抖的画家装了个防抖云台,每一笔都画在它该在的地方,拼缝和接头处自然就严丝合缝了。
二、技术深挖:为什么要走"自回归"这条窄路?
可能有人会问:现在Stable Diffusion、Flux这些扩散模型(Diffusion Model)已经很成熟了,阶跃星辰为什么非要死磕"自回归流匹配"这条难走的路?
这其实是一场关于"大一统"的豪赌。
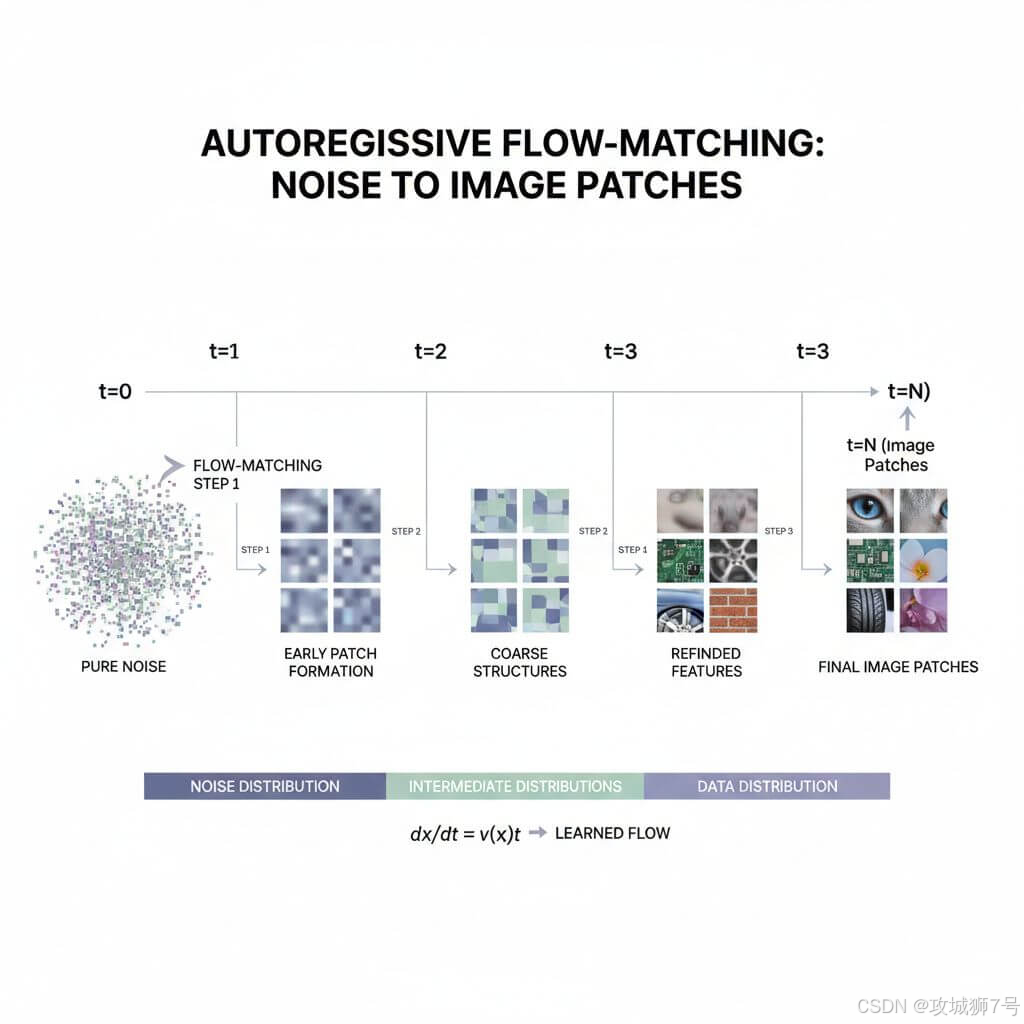
2.1 传统架构的"割裂感"
目前主流的文生图模型,大多是"拼凑"出来的。你需要一个语言模型来理解提示词,再需要一个扩散模型来生成图片。这两部分是割裂的,计算量大,且很难真正理解图文之间的深层逻辑。
2.2 自回归的"原生融合"
阶跃星辰选择的自回归路线(Autoregressive),是想让一个模型(Transformer)直接"学会"画图,就像它学会写诗一样。
在NextStep-1.1的架构里:
* 大脑:一个140亿参数(14B)的Transformer,负责统一思考。
* 左手:一个标准的语言头,负责输出文字。
* 右手:一个轻量级的"流匹配头",负责输出图像。
这种架构极其简洁。它不需要庞大的扩散去噪模块,只需要预测"下一个Patch(图像块)长什么样"。如果这条路走通了,未来的多模态模型(能看、能听、能画、能写)将不再是缝合怪,而是一个浑然天成的整体。
三、行业观察:静水流深的技术博弈
NextStep-1.1的发布,虽然没有SOTA(刷榜)那么吸睛,但透露出的信号却很耐人寻味。
3.1 "六小龙"的分化
曾经的"大模型六小龙",现在已经名存实亡。有的转型做应用,有的甚至已经掉队。依然坚持在牌桌上自研基础大模型的,只剩下智谱、MiniMax、Kimi和阶跃星辰这几家。
阶跃星辰的策略很明显:不跟风刷榜,专注啃硬骨头。
无论是之前的Step-1V视频模型,还是现在的NextStep-1.1,他们都在尝试突破现有架构的瓶颈(如扩散模型的计算效率问题),试图找到下一代模型的"版本答案"。
3.2 开源生态的布局
这次NextStep-1.1直接在GitHub和Hugging Face开源,并没有藏着掖着。结合之前开源的端侧模型GELab-Zero和数学模型PaCoRe,阶跃正在构建一个从云端到终端、从通用到垂直的完整生态。
对于开发者来说,这意味着在传统的Diffusion架构之外,多了一种"自回归生成"的新选择。虽然它现在可能还不如Flux那么完美,但它代表了另一种可能性------一种更轻量、更统一的可能性。
结语
NextStep-1.1或许不是那种让你一眼惊艳的"爆款",但它绝对是一个扎实的"补丁"。

它证明了在图像生成领域,除了"堆步数"的扩散模型,自回归+强化学习这条路也是走得通的。对于阶跃星辰来说,这不仅是一次产品的迭代,更是在为未来的原生多模态大模型积累技术拼图。
在喧嚣的AI江湖里,这种死磕底层架构的"笨功夫",或许才是通往决赛圈最稳的门票。
GitHub开源地址:
https://github.com/stepfun-ai/nextstep-1
Hugging Face开源地址:
https://huggingface.co/stepfun-ai/NextStep-1.1
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!