RLIKE正则表达式
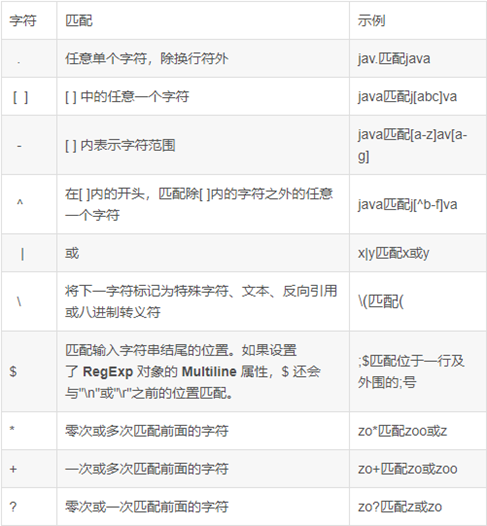
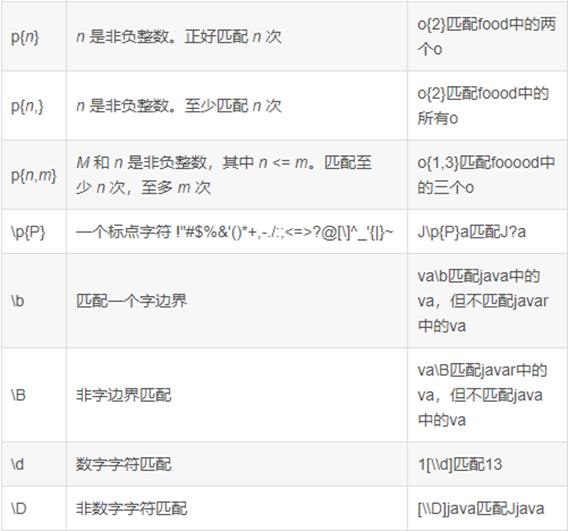
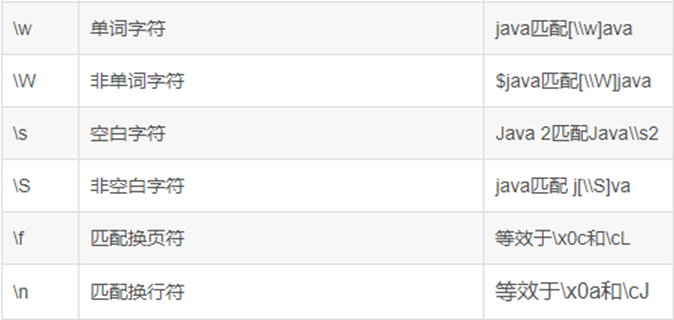
注意:反斜杠要写两个斜杠,表示转义
例:
查找广东省的数据
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*广东.*';
查找用户地址是:xx省 xx市 xx区的数据
SELECT * FROM itheima.orders WHERE useraddress RLIKE '..省 ..市 ..区';
查找用户姓为张、王、邓
SELECT * FROM itheima.orders WHERE username RLIKE '张王邓\\S+';
查找手机号符合:188****0*** 规则
SELECT * FROM itheima.orders WHERE userphone RLIKEE '188\\S{4}0\\S{3}';
union联合
UNION 用于将多个 SELECT 语句的结果组合成单个结果集。
要求:每个 select 语句返回的列的数量和名称必须相同。否则,将引发架构错误。
基础语法:
SELECT ...
UNION ALL
SELECT ...
可以用在:(用在任何需要select的地方)
1,直接UNION:去重。UNION ALL:不去重
2,也可以写在子查询from中,连接两个select语句
3,用于insert select中
快速随机采样操作/sampling采样
进行随机抽样,本质上就是用TABLESAMPLE函数
语法1,基于随机分桶抽样:
SELECT... FROM table TABLESAMPLE(BUCKET****x OUT OF y ON(colname | rand()))
•y表示将表数据随机划分成y份(y个桶)
•x表示从y里面随机抽取第x份数据作为取样
假设:x=3,y=10,表示把表的数据随机分成10份(10个桶),取其中第三份
•colname表示随机的依据基于某个列的值(基于某个列的值做哈希取模分桶)
•rand()表示随机的依据基于整行(纯随机分桶)
示例:
SELECT username, orderId, totalmoney FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON username);
SELECT * FROM itheima.orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON rand());
注意:
•使用colname作为随机依据,则其它条件不变下,每次抽样结果一致。在分桶表的形式下快
•使用rand()作为随机依据,每次抽样结果都不同,普通表快
语法2,基于数据块抽样
SELECT... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
•num ROWS 表示抽样num条数据
•num PERCENT 表示抽样num百分百比例的数据
•num(K|M|G) 表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
注意:
使用这种语法抽样,条件不变的话,每一次抽样的结果都一致,基于数据块
即无法做到随机,只是按照数据顺序从前向后取。
Virtual columns虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
- INPUT__FILE__NAME,显示数据行所在的具体文件
- BLOCK__OFFSET__INSIDE__FILE,显示数据行所在文件的偏移量
- ROW__OFFSET__INSIDE__BLOCK,显示数据所在HDFS块的偏移量。此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
示例:
SELECT *, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.course;
虚拟列不仅仅可以用于SELECT,在WHERE、GROUP BY等均可使用
SELECT *, BLOCK__OFFSET__INSIDE__FILE FROM course WHERE****BLOCK__OFFSET__INSIDE__FILE > 50;
SELECT INPUT__FILE__NAME, COUNT(*) FROM itheima.orders_bucket GROUP BY INPUT__FILE__NAME;
除此以外,在某些错误排查场景上,虚拟列可以提供相关帮助。
Hive函数
lHive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数****UDF(User-Defined Functions):

官方文档:(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-MathematicalFunctions)
Hive内建了不少函数
使用show functions查看当下可用的所有函数;
通过describe function extended funcname来查看函数的使用方式。