一、逃逸分析
1、定义
逃逸分析是 JVM 在即时编译阶段 执行的一种数据分析技术,它的核心目标是:分析对象的引用范围,判断一个对象的生命周期是否会 "逃出" 某个作用域。
JVM 会检查:创建的对象,是不是只在当前方法内部使用,还是会被暴露到方法外(比如返回给调用者、传给其他方法、被其他线程访问)。
2、逃逸常见场景
| 逃逸类型 | 具体场景 | 示例代码片段 |
|---|---|---|
| 方法逃逸 | 对象被返回给调用者 | return new User(); |
| 方法逃逸 | 对象赋值给方法外的全局变量 | globalObj = new User(); |
| 线程逃逸 | 对象被放入多线程共享的集合(如 ConcurrentHashMap) | concurrentMap.put("key", new User()); |
3、核心作用
如果 JVM 判断对象没有逃逸,就可以基于这个结论做一系列优化,比如:
- 栈上分配(代替堆分配)
- 标量替换
- 同步消除(比如去掉无逃逸对象的 synchronized 锁)
二、标量替换
标量替换是基于逃逸分析的核心优化手段。
- 标量 :无法再分解的最小数据单元,比如
int、long、boolean、对象引用(User)等,JVM 中对标量的操作是最基础的。 - 聚合量 :可以分解成多个标量的复合数据,比如自定义的
User对象(包含int id、String name)、Point对象(包含int x、int y)。
1、定义
如果逃逸分析判定一个聚合量对象没有逃逸,JVM 会将这个对象 "拆解" 成它的各个标量字段,直接在栈上分配这些标量,而不是在堆上创建整个对象 ------ 这个过程就是标量替换。
2、标量替换优化
JVM 会通过标量替换优化:
java
public class ScalarReplacementDemo {
// 自定义聚合量:Point对象(包含x、y两个标量)
static class Point {
private int x;
private int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}
// 计算两点距离(Point对象仅在方法内使用,无逃逸)
public static double calculateDistance() {
// 创建Point对象(聚合量)
Point p1 = new Point(1, 2);
Point p2 = new Point(3, 4);
// 计算距离
double dx = p1.x - p2.x;
double dy = p1.y - p2.y;
return Math.sqrt(dx*dx + dy*dy);
}
public static void main(String[] args) {
calculateDistance();
}
}优化前 :JVM 会在堆上创建p1和p2两个 Point 对象,使用完后还需要 GC 回收。
优化后(标量替换):JVM 不会创建 Point 对象,而是直接在栈上分配 4 个标量:
p1_x = 1、p1_y = 2p2_x = 3、p2_y = 4然后直接用这些标量计算距离,完全省去了堆对象的创建和 GC 开销。
3、标量替换启用
JVM 中,逃逸分析和标量替换默认是开启的(JDK 1.8 及以上),如果要手动验证 / 调整,可以用以下 JVM 参数:
bash
# 开启逃逸分析(默认开启)
-XX:+DoEscapeAnalysis
# 开启标量替换(默认开启)
-XX:+EliminateAllocations
# 打印标量替换的日志(验证优化是否生效)
-XX:+PrintEliminateAllocations三、逃逸分析与标量替换的关联
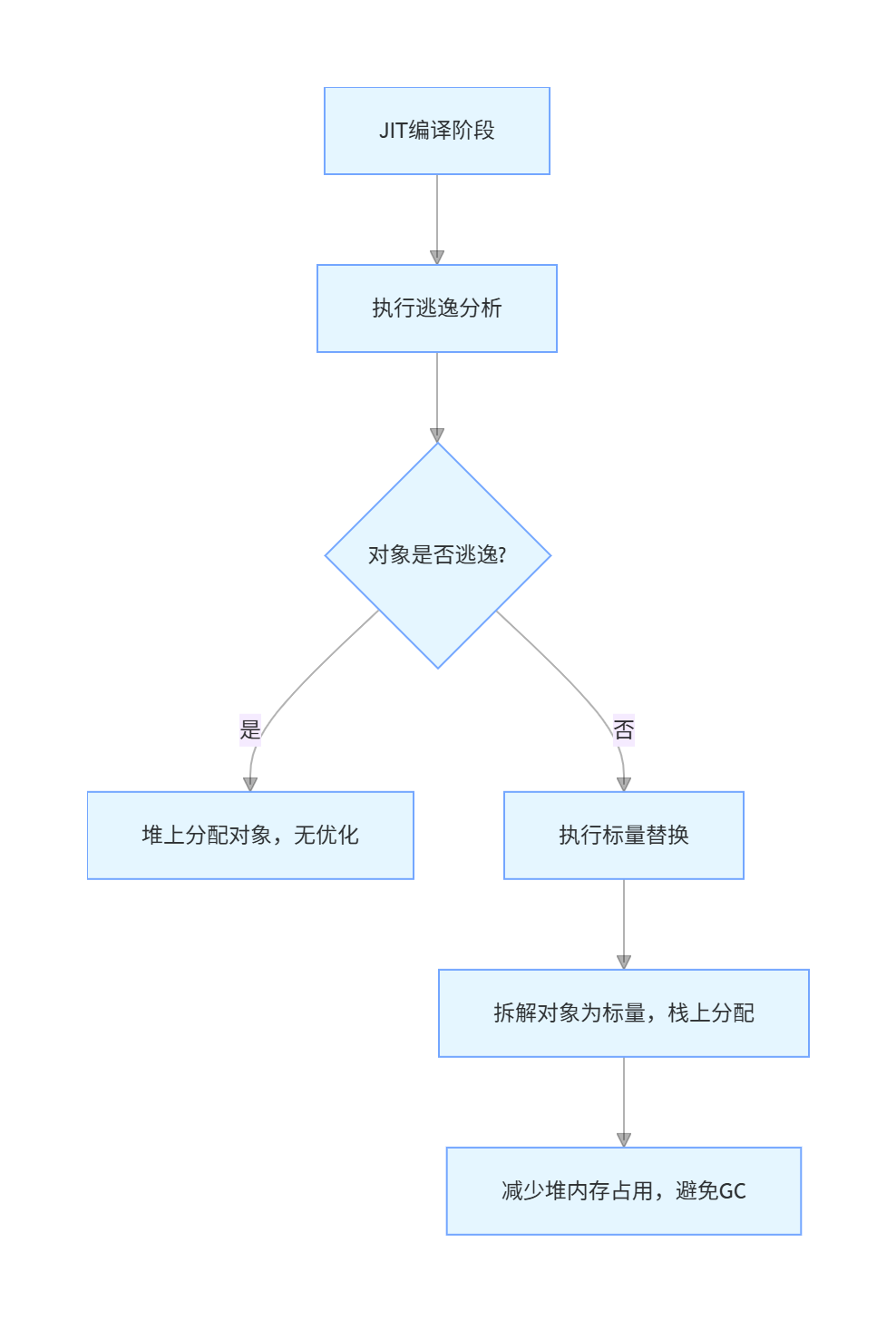
- 逃逸分析是基础:核心是判断对象是否逃出方法 / 线程作用域,是标量替换的前提;
- 标量替换是优化手段 :基于 "对象无逃逸" 的结论,将聚合量对象拆解为标量,栈上分配,核心价值是减少堆对象创建、降低 GC 压力;
- 核心收益:两者结合能显著提升程序性能,尤其是创建大量短期小对象的场景(比如循环中创建临时对象)。
四、栈上分配
1. 栈上分配(Stack Allocation)------ 优化 "目标 / 结果"
栈上分配是 JVM 的内存分配优化目标 :把原本要在堆 上分配的内存,转移到线程私有的栈上分配。
- 堆的特点:所有线程共享,对象分配后需要 GC(垃圾回收)清理,开销大;
- 栈的特点:线程私有,随方法调用入栈、方法结束出栈自动回收,无需 GC,效率极高。
但栈有一个关键局限:栈只能直接分配 "标量"(int、long、引用等最小数据单元),无法直接分配 "聚合量"(对象) ------ 因为对象是复合结构,大小 / 生命周期在编译期可能不固定,不符合栈内存 "固定大小、生命周期明确" 的分配规则。
2. 标量替换 ------ 实现目标的 "手段 / 方法"
标量替换是 JVM 为了实现 "对象的栈上分配" 而设计的核心技术手段:因为栈不能直接存对象,所以 JVM 先把无逃逸的对象(聚合量)拆解成标量,再把这些标量分配到栈上 ------ 变相实现了 "对象在栈上分配" 的效果。