目录
[3.1 缓冲池(Buffer Pool)](#3.1 缓冲池(Buffer Pool))
[3.2 变更缓冲区(Change Buffer)](#3.2 变更缓冲区(Change Buffer))
[3.3 日志缓冲区(Log Buffer)](#3.3 日志缓冲区(Log Buffer))
[3.4 自适应哈希索引(Adaptive Hash Index)](#3.4 自适应哈希索引(Adaptive Hash Index))
一、引言
InnoDB是当前MySQL的默认存储引擎, 但是一开始并不是它,而是MyISAM。下面将介绍InnoDB是靠什么来取代MyISAM上位的。
二、InnoDB宏观架构
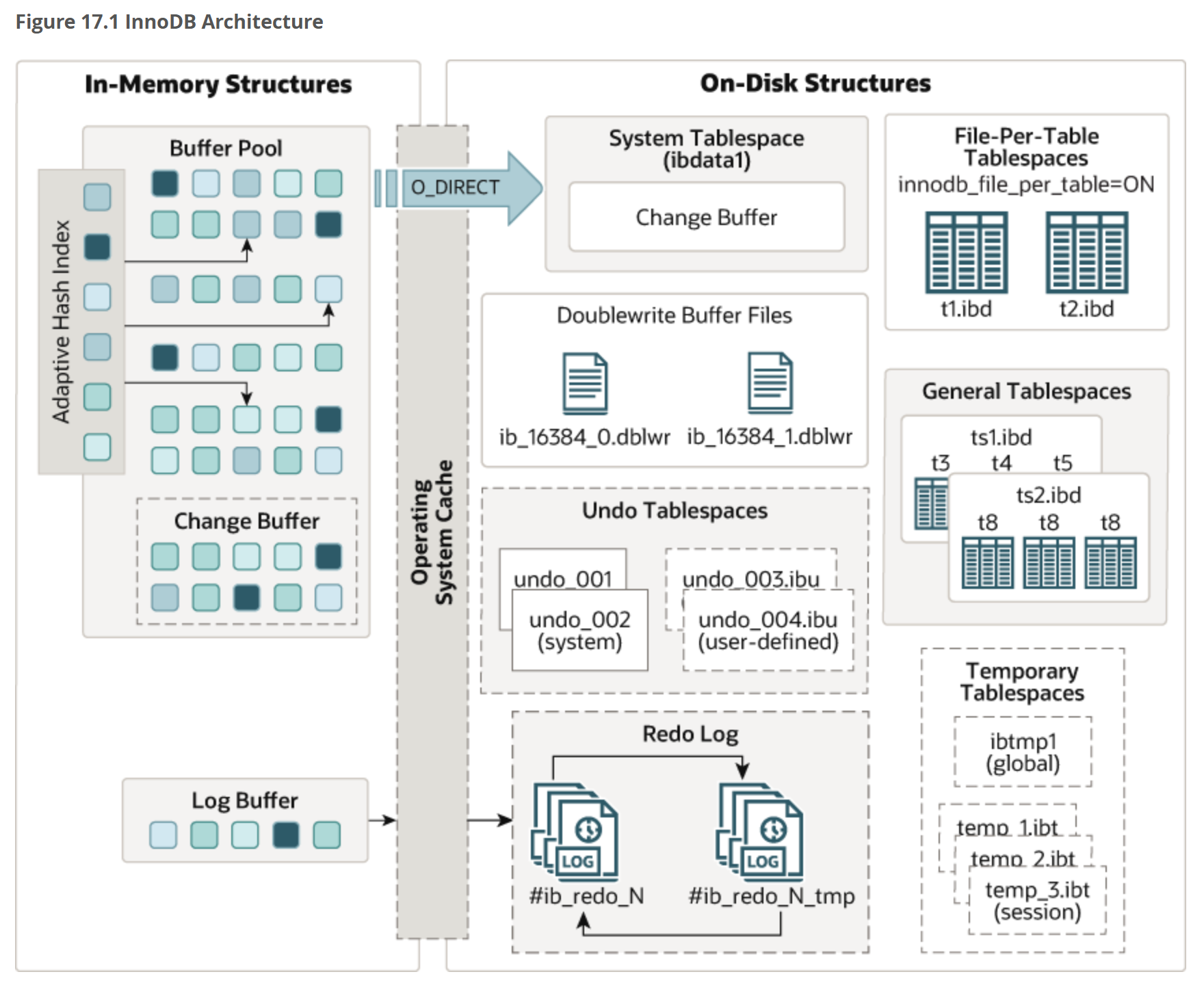
这张图是截自MySQL官网的,可以看到InnoDB主要包括内存结构和磁盘结构,下面将展开聊聊它的内存结构。
三、内存结构
InnoDB的内存结构包括4个部分,缓冲池、变更缓冲区、日志缓冲区和自适应哈希索引。这些结构都是InnoDB存储引擎的关键性能所在,有必要好好聊一聊。
3.1 缓冲池(Buffer Pool)
缓冲池本质上就是内存中的一块连续区域,作为磁盘的缓存,缓存磁盘上的数据页、索引页和其他关键的数据结构。目的就是为了减少磁盘IO,提升读写性能。
3.1.1 缓冲池的核心作用
1)缓存热点数据和索引
数据库的读写操作,优先访问缓冲池。
在读取数据时,如果目标数据或者索引在缓冲池中,也就是缓存命中,那么直接从内存中读取数据,不用访问磁盘,也就是减少了磁盘IO。如果目标数据或者索引不在缓冲池中,也就是说缓存失效,那么就需要访问磁盘,将磁盘中的数据页加载到内存中的缓冲区,然后再返回结果。
如果是写操作,那么将先修改缓冲区中的数据页,被修改的数据页被称为脏页,然后再有后台的异步线程进行刷盘,后台线程不是说修改数据后就立即将数据页刷盘,而是选择在MySQL比较空闲的时候再进行统一刷盘,可能一刷就是更新好几个数据页,避免了频繁的磁盘IO。
2)降低磁盘IO开销
降低磁盘IO开销是InnoDB存储引擎缓存热点数据和索引的结果。磁盘的随机IO是数据库的性能瓶颈,通过缓存热点数据,将大部分随机IO转换为内存操作,大幅提升了吞吐量。
3.2.1 缓冲池的内部结构
缓冲池内部,分布着很多的缓冲页,缓冲页是缓冲池中最小的存储单位,默认大小是16KB,和InnoDB磁盘数据页的大小是一致的。因为缓冲池的空间有限,所以不可能装下访问过的所有数据页,必然要淘汰一部分的数据页。因此,缓冲池中就引入了空闲列表(Free List)、LRU列表(LRU List)和Flush列表(Flush List)来管理这些数据页。
1)空闲列表(Free List)
管理缓冲池中空闲的内存页,当需要从磁盘加载一个新的数据页到缓冲池时,InnoDB 会从 Free List 中取出一个空闲的页框,然后将磁盘上的页内容读入到这个页框中。
2)LRU列表(LRU List)
LRU就是最近最少使用的意思。它的机制就是将新加载的数据页或者说最新访问的数据页移动到链表的头部,当空间不足时,淘汰掉链表尾部的数据页。这就是传统LRU机制,但是这种设计在MySQL中会遇到以下两个问题:
- 预读失效:InnoDB会主动预读相邻的页(比如读取一页时,预读后面的几页),如果预读的页没有被访问,会占据缓冲池空间,污染热点数据。
- 全表扫描污染:执行全表扫描时,会加载大量冷数据到LRU头部,把真正的热点数据挤到尾部并淘汰,导致性能骤降。
所以,InnoDB采用的是改进的LRU策略。
InnoDB将链表分为young区(新生代)和old区(老年代),并引入了中点插入策略,从磁盘加载的新的数据页(包括预读取的数据页)不直接插入到young区的头部,而是插入到old区的头部,只有当该页在指定时间内被再次访问时,才会被移动到young区头部,成为热点数据。若未被再次访问,会随着链表移动到old区尾部,最终被淘汰,避免了预读和全表扫描的污染。
3)Flush列表(Flush List)
管理所有被修改过但是尚未写回磁盘的页------脏页(Dirty Page)。缓冲池中的数据页,一旦被修改,那么它就是脏页,就会被链入到Flush列表中,等待被刷到磁盘。
实际上,缓冲池被划分为多个区域,每个区域就是一个实例。每个实例都有自己独立的Free List、LRU List、Flush List和相关的锁,这样一来就可以减少锁的竞争,提高并发性能。
每一个实例,在物理上又被进一步划分为多个"块",每一个块本质上就是一段连续的内存空间,包含固定数量的页。
InnoDB通过控制块来管理数据页。控制块与数据页之间一一对应,控制块中包含指向对应数据页的指针,还有指向前一个控制块的prev指针和指向下一个控制块的next指针,控制块之间通过双向链表组织起来,通过遍历控制块链表就可以实现对数据页的遍历。
看到这里,你是不是觉得,有Free List、Flush List 和LRU List,为什么还需要控制块来管理数据页,所有的数据页不都被管理在这些链表中了吗?
其实,直接用数据页作为节点,是不行的。这些链表中存的其实是数据页对应的控制块。如果链表中是数据页,那么遍历、插入等的代价就太大了,因为数据页的体积很大。而且,一个数据页是没办法挂载到多个链表上的。比如,一个刚修改过的数据页,那么它就是脏页,需要挂载到Flush List上,同时它也是刚被访问过的数据页,也需要挂载到LRU List上。而控制块就可以通过操作指针很轻松的将自己链入这两个链表当中。
3.2 变更缓冲区(Change Buffer)
变更缓冲区是用来缓存对二级索引的修改,当要修改的数据页没有被加载到内存时(也就是缓存失效),先将修改缓存起来,等到其他查询发生,把数据页加载到内存以后,再把修改合并到缓冲池,从而达到减少磁盘IO的目的。
为什么是二级索引,主键索引不行吗?
主键索引还真不行。更确切的说,只要是唯一键索引列都不行。
基于非主键列创建的索引,就叫做二级索引。如果缓存对主键修改,想象一下:事务A插入一条id = 100的记录,如果这个插入操作缓存起来而没有被应用到主键索引树上,那么事务B试图也插入id = 100的记录时,去检查主键树,发现id = 100不存在,从而允许插入。这样,主键的唯一性就遭到了破坏。其他的唯一键索引也同理,不能缓存修改。
如果断电,变更缓冲区中的修改会不会丢失?
不会丢失。因为InnoDB会将修改先记录到redo log中,写入后立即刷盘,然后再将修改缓存到变更缓冲区中,等待数据页加载到内存然后合并。
如果缓存在变更缓冲区中的修改,对应的数据页自始至终都没有加载到内存,怎么办?
InnoDB内置了专门的后台合并线程,定期扫描变更缓冲区,主动处理那些长期未被访问的索引页对应的修改记录。除此之外,当变更缓冲区的空间不足时,会触发强制合并。它会暂定接收新的记录写入到变更缓冲区,然后主动加载对应的数据页进行合并。释放出一定的空间后,再恢复接收新的修改。
3.3 日志缓冲区(Log Buffer)
日志缓冲区的核心作用是缓存事务产生的redo log 和undo log,减少磁盘IO的频率。
如果没有日志缓冲区,那么每次产生的redo log日志,都要直接写入磁盘,频繁的随机磁盘IO会拖慢事务的速度。有了日志缓冲区,产生的redo log可以先缓存在内存中,当满足触发条件时,再批量写到磁盘的redo log文件。将多次小IO合并为一次大IO,大幅提升性能。
缓存undo log日志,当需要回滚时,直接从日志缓冲区中读取数据,恢复到修改前的状态,减少了磁盘IO。
redo log不立即刷盘,那么断电时,会不会丢失数据?
取决于 innodb_flush_log_at_trx_commit 参数的配置。
1) innodb_flush_log_at_trx_commit = 1(默认安全配置)
每一次事务提交时,InnoDB会强制日志缓冲区中该事务对应的redo log,同步写入磁盘redo log文件。所以不会丢失已经提交的事务修改。
2) innodb_flush_log_at_trx_commit = 0
事务提交时,不会触发redo log刷盘,只是把redo log写入日志缓冲区,后台线程每隔1秒,批量将缓冲区中的redo log刷到磁盘。所以,最多会丢失最后1秒的修改。
3.4 自适应哈希索引(Adaptive Hash Index)
自动对频繁访问的索引页构建哈希索引,加快等值查询的效率。
四、关键特性与机制
InnoDB关键的特性与机制就是支持事务和行级锁了。下面这篇博客中有相关介绍:
五、InnoDB和MyISAM的区别
|--------------|------------|------------|
| 机制 | InnoDB | MyISAM |
| 是否支持事务 | 是 | 否 |
| 是否支持外键 | 是 | 否 |
| 是否支持行级锁 | 是 | 否 |
| 是否支持聚簇索引 | 是 | 否 |
InnoDB支持聚簇索引,主键索引的叶子节点直接存储数据,无需二次查找。而MyISAM的叶子结点存储的是数据的物理地址,找到数据的地址后,还需通过地址才能拿到数据。InnoDB相较于MyISAM,数据安全性更高。InnoDB在数据库崩溃后,可以通过redo log和undo log来进行恢复,而MyISAM无恢复机制,数据库崩溃后可能会导致数据丢失。
六、InnoDB存储引擎的优势
- 完整的事务支持。事务是数据库处理复杂业务逻辑的核心,InnoDB 是 MySQL 中首个实现完整 ACID 特性的存储引擎。
- 数据库崩溃(如掉电、进程异常退出)是常见风险,InnoDB 通过 redo log(重做日志) 和 undo log(回滚日志) 实现可靠的崩溃恢复,确保数据不丢失、一致性不破坏。
- 为了保持数据完整性, InnoDB 支持 FOREIGN KEY (外键)约束。在进行插入、更新和删除数据 时确保相关表之间的⼀致性。
- InnoDB 将磁盘上的表数据和索引缓存到内存的 "缓冲池" 中,后续查询优先从内存读取,减少磁盘 I/O。
- 支持行级锁,有效避免锁冲突,提高并发量。
- 自适应哈希索引:InnoDB 会自动分析高频查询的索引,将其构建为哈希索引,提升查询的速度。
- InnoDB表优化了基于主键的查询,每个InnoDB表都有⼀个称为聚簇索引的主键索引,通过最少的磁盘I/O完成对主键的查找。
以上优势,就是InnoDB能够取代MyISAM上位的主要原因。
七、结语
今天是元旦,祝大家元旦快乐~
完