目录
[5.模式(Schema )](#5.模式(Schema ))
[5.1.创建 Schema](#5.1.创建 Schema)
[5.4.1.添加 VARCHAR 字段](#5.4.1.添加 VARCHAR 字段)
[5.6.1.定义 JSON 字段](#5.6.1.定义 JSON 字段)
[步骤 1:创建多个 AnnSearchRequest 实例](#步骤 1:创建多个 AnnSearchRequest 实例)
[步骤 2:配置 Rerankers 策略](#步骤 2:配置 Rerankers 策略)
[步骤 3:执行混合搜索](#步骤 3:执行混合搜索)
[11.1.BM25 实施](#11.1.BM25 实施)
[11.2.创建 Collections](#11.2.创建 Collections)
[11.3.定义 BM25 函数](#11.3.定义 BM25 函数)
Schema :模式(可理解成约束)
5.模式(Schema )
Schema 定义了 Collections 的数据结构。在创建一个 Collection 之前,你需要设计出它的 Schema。
设计良好的 Schema 至关重要,因为它抽象了数据模型,并决定能否通过搜索实现业务目标。此外,由于插入 Collections 的每一行数据都必须遵循 Schema,因此有助于保持数据的一致性和长期质量。从技术角度看,定义明确的 Schema 会带来组织良好的列数据存储和更简洁的索引结构,从而提升搜索性能。
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。下图说明了如何将文章映射到模式字段列表。
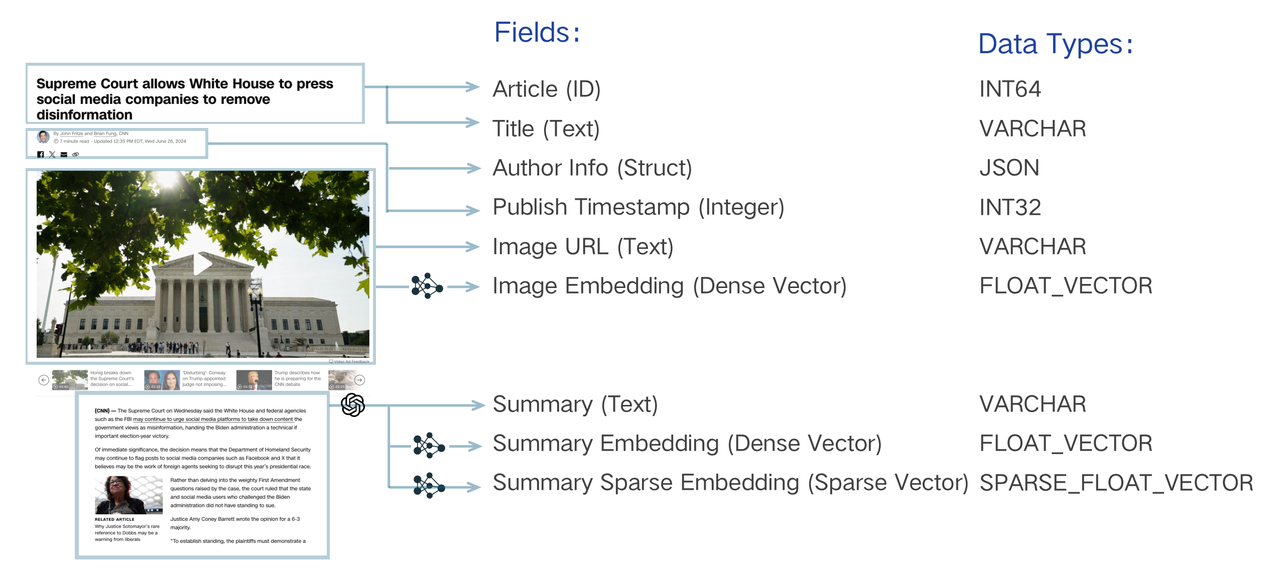
5.1.创建 Schema
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()1.添加主键
Collections 中的主字段唯一标识一个实体。它只接受Int64 或VarChar值
python
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
# highlight-start
is_primary=True,
auto_id=False,
# highlight-end
)2.添加向量
向量字段接受各种稀疏和密集向量嵌入。
python
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
# highlight-next-line
dim=5
)3.添加标量
在常见情况下,您可以使用标量字段来存储存储在 Milvus 中的向量嵌入的元数据,并通过元数据过滤进行 ANN 搜索,以提高搜索结果的正确性。
python
#字符串
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
# highlight-next-line
max_length=512
)
#数字
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)
#布尔0/1
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)
#json
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)
#数组
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)5.2.主键
Milvus 支持两种分配主键值的模式。
| 模式 | 描述 | 建议 |
|---|---|---|
| 自动 ID | Milvus 自动为插入或导入的实体生成唯一标识符。 | 不需要手动管理 ID 的大多数情况。 |
| 手动 ID | 在插入或导入数据时,您自己提供唯一 ID。 | 当 ID 必须与外部系统或已有数据集保持一致时。 |
1.自动ID
在主字段定义中启用auto_id=True 。Milvus 将自动处理 ID 生成。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema()
schema.add_field(
field_name="id", # Primary field name
is_primary=True,
auto_id=True, # Milvus generates IDs automatically; Defaults to False
datatype=DataType.INT64
)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=4) # Vector field
schema.add_field(field_name="category", datatype=DataType.VARCHAR, max_length=1000) # Scalar field of the VARCHAR type
if client.has_collection("demo_autoid"):
client.drop_collection("demo_autoid")
client.create_collection(collection_name="demo_autoid", schema=schema)插入数据:
**重要:**不要在数据中包含主字段列。Milvus 会自动生成 ID。
python
data = [
{"embedding": [0.1, 0.2, 0.3, 0.4], "category": "book"},
{"embedding": [0.2, 0.3, 0.4, 0.5], "category": "toy"},
]
res = client.insert(collection_name="demo_autoid", data=data)
print("Generated IDs:", res.get("ids"))2.手动ID
python
schema.add_field(
field_name="product_id",
is_primary=True,
auto_id=False, # You'll provide IDs manually at data ingestion
datatype=DataType.VARCHAR,
max_length=100 # Required when datatype is VARCHAR
)您必须在每次插入操作中包含主字段列。
python
data = [
{"product_id": "PROD-001", "embedding": [0.1, 0.2, 0.3, 0.4], "category": "book"},
{"product_id": "PROD-002", "embedding": [0.2, 0.3, 0.4, 0.5], "category": "toy"},
]
res = client.insert(collection_name="demo_manual_ids", data=data)
print("Generated IDs:", res.get("ids"))5.3.密集向量
密集向量是广泛应用于机器学习和数据分析的数值数据表示法。它们由包含实数的数组组成,其中大部分或所有元素都不为零。与稀疏向量相比,密集向量在同一维度上包含更多信息,因为每个维度都持有有意义的值。这种表示方法能有效捕捉复杂的模式和关系,使数据在高维空间中更容易分析和处理。密集向量通常有固定的维数,从几十到几百甚至上千不等,具体取决于具体的应用和要求。
密集向量主要用于需要理解数据语义的场景,如语义搜索和推荐系统。在语义搜索中,密集向量有助于捕捉查询和文档之间的潜在联系,提高搜索结果的相关性。在推荐系统中,密集矢量有助于识别用户和项目之间的相似性,从而提供更加个性化的建议。
密集向量通常表示为具有固定长度的浮点数数组,如[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5] 。这些向量的维度通常从数百到数千不等,如 128、256、768 或 1024。每个维度都能捕捉对象的特定语义特征,通过相似性计算使其适用于各种场景。
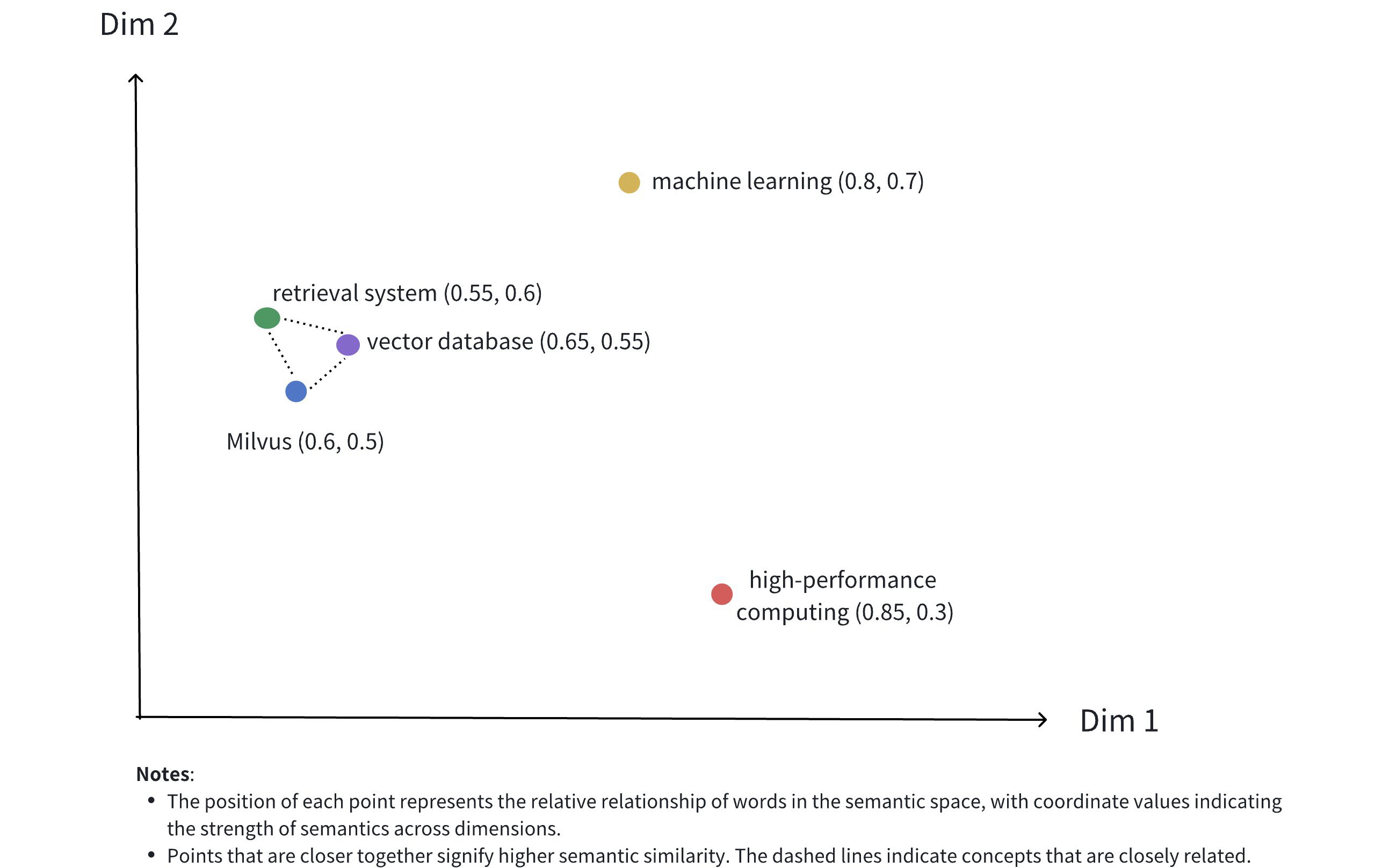
上图展示了密集向量在二维空间中的表现形式。虽然实际应用中的密集向量通常具有更高的维度,但这种二维插图有效地传达了几个关键概念:
-
多维表示: 每个点代表一个概念对象(如Milvus 、向量数据库 、检索系统等),其位置由其维度值决定。
-
**语义关系:**点之间的距离反映了概念之间的语义相似性。距离较近的点表示语义关联度较高的概念。
-
聚类效应: 相关概念(如Milvus 、向量数据库 和检索系统)在空间中的位置相互靠近,形成语义聚类。
下面是一个代表文本"Milvus is an efficient vector database" 的真实稠密向量示例:
python
[
-0.013052909,
0.020387933,
-0.007869,
-0.11111383,
-0.030188112,
-0.0053388323,
0.0010654867,
0.072027855,
// ... more dimensions
]稠密向量可使用各种嵌入模型生成,如用于图像的 CNN 模型(如ResNet、VGG)和用于文本的语言模型(如BERT、Word2Vec)。这些模型将原始数据转化为高维空间中的点,捕捉数据的语义特征。此外,Milvus 还提供便捷的方法,帮助用户生成和处理密集向量,详见 Embeddings。
一旦数据被向量化,就可以存储在 Milvus 中进行管理和向量检索。下图显示了基本流程。
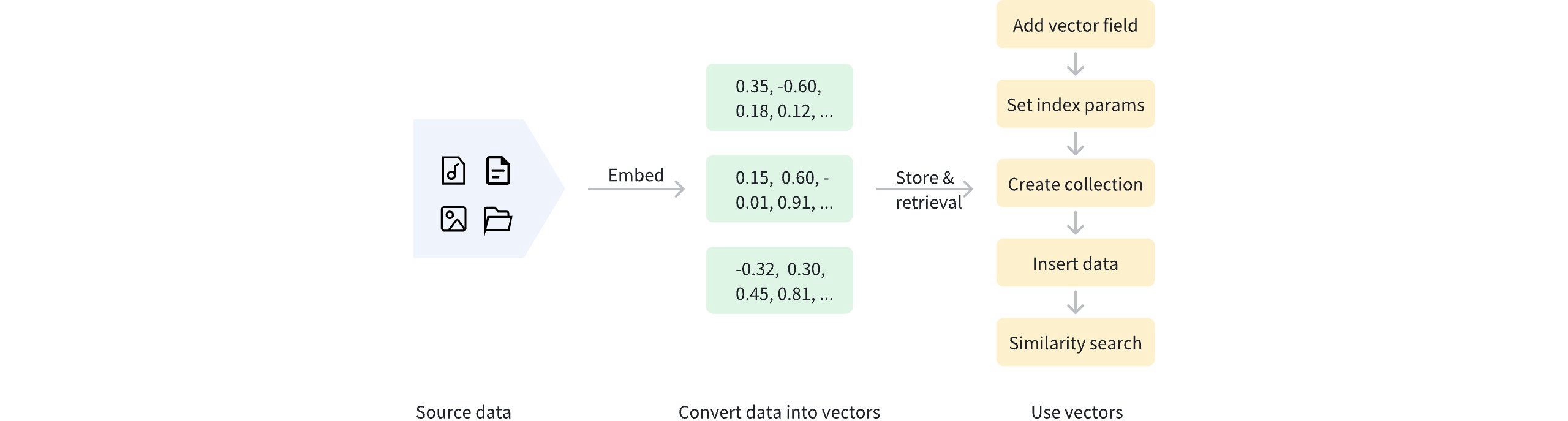
5.3.1.添加向量场
要在 Milvus 中使用密集向量,首先要在创建 Collections 时定义一个用于存储密集向量的向量场。这一过程包括
-
将
datatype设置为支持的密集向量数据类型。有关支持的密集向量数据类型,请参阅数据类型。 -
使用
dim参数指定密集向量的维数。
在下面的示例中,我们添加了一个名为dense_vector 的向量字段来存储密集向量。字段的数据类型为FLOAT_VECTOR ,维数为4 。
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="dense_vector", datatype=DataType.FLOAT_VECTOR, dim=4)5.3.2.设置索引参数
为了加速语义搜索,必须为向量字段创建索引。索引可以大大提高大规模向量数据的检索效率。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense_vector",
index_name="dense_vector_index",
index_type="AUTOINDEX",
metric_type="IP"
)在上面的示例中,使用AUTOINDEX 索引类型为dense_vector 字段创建了名为dense_vector_index 的索引。metric_type 设置为IP ,表示将使用内积作为距离度量。
Milvus 提供多种索引类型,以获得更好的向量搜索体验。AUTOINDEX 是一种特殊的索引类型,旨在平滑向量搜索的学习曲线。
5.3.3.插入数据
完成密集向量和索引参数设置后,就可以创建包含密集向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的集合。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)创建集合后,使用insert 方法添加包含密集向量的数据。确保插入的密集向量的维度与添加密集向量字段时定义的dim 值相匹配。
python
data = [
{"dense_vector": [0.1, 0.2, 0.3, 0.7]},
{"dense_vector": [0.2, 0.3, 0.4, 0.8]},
]
client.insert(
collection_name="my_collection",
data=data
)5.3.4.执行相似性搜索
基于密集向量的语义搜索是 Milvus 的核心功能之一,可以根据向量之间的距离快速找到与查询向量最相似的数据。要执行相似性搜索,请准备好查询向量和搜索参数,然后调用search 方法。
python
# 定义向量搜索的参数
# nprobe 控制在近似最近邻搜索(ANN)中查询时探索的聚类中心数量;
# 值越大,搜索越精确但速度越慢;值越小,速度越快但可能牺牲精度。
search_params = {
"params": {"nprobe": 10}
}
# 定义查询向量,这是一个四维浮点数列表,代表要搜索的嵌入向量(embedding)
query_vector = [0.1, 0.2, 0.3, 0.7]
# 执行向量相似性搜索
res = client.search(
collection_name="my_collection", # 指定要搜索的集合(collection)名称
data=[query_vector], # 输入的查询向量需包装在列表中(支持批量查询)
anns_field="dense_vector", # 指定用于 ANN 搜索的向量字段名
search_params=search_params, # 传入搜索参数(如 nprobe)
limit=5, # 返回最相似的前 5 个结果
output_fields=["pk"] # 指定返回哪些字段,此处只返回主键(primary key)
)
# 打印搜索结果
print(res)后面的二进制向量和稀疏向量就不再赘述了


5.4.字符串字段
在 Milvus 中,VARCHAR 是用于存储字符串数据的数据类型。
定义VARCHAR 字段时,有两个参数是必须的:
-
将
datatype设置为DataType.VARCHAR。 -
指定
max_length,它定义了VARCHAR字段可存储的最大字节数。max_length的有效范围为 1 至 65,535 字节。
5.4.1.添加 VARCHAR 字段
要在 Milvus 中存储字符串数据,请在 Collections Schema 中定义一个VARCHAR 字段。下面是一个定义了两个VARCHAR 字段的 Collections 模式的示例:
-
varchar_field1VARCHAR:最多存储 100 字节,允许空值,默认值为"Unknown"。 -
varchar_field2:字段最多存储 200 字节,允许空值,但没有默认值。
python
from pymilvus import MilvusClient, DataType
SERVER_ADDR = "http://localhost:19530"
client = MilvusClient(uri=SERVER_ADDR)
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="varchar_field1", datatype=DataType.VARCHAR, max_length=100, nullable=True, default_value="Unknown")
schema.add_field(field_name="varchar_field2", datatype=DataType.VARCHAR, max_length=200, nullable=True)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)5.4.2.设置索引参数
索引有助于提高搜索和查询性能。在 Milvus 中,对于向量字段必须建立索引,但对于标量字段可选。
下面的示例使用AUTOINDEX 索引类型为向量字段embedding 和标量字段varchar_field1 创建了索引。使用这种类型,Milvus 会根据数据类型自动选择最合适的索引。您还可以自定义每个字段的索引类型和参数。详情请参阅 "索引说明"。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="varchar_field1",
index_type="AUTOINDEX",
index_name="varchar_index"
)
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX", # Use automatic indexing to simplify complex index settings
metric_type="COSINE" # Specify similarity metric type, options include L2, COSINE, or IP
)5.4.3.插入数据
定义好 Schema 和索引后,创建一个包含字符串字段的 Collection。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
python
data = [
{"varchar_field1": "Product A", "varchar_field2": "High quality product", "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"varchar_field1": "Product B", "pk": 2, "embedding": [0.4, 0.5, 0.6]}, # varchar_field2 field is missing, which should be NULL
{"varchar_field1": None, "varchar_field2": None, "pk": 3, "embedding": [0.2, 0.3, 0.1]}, # `varchar_field1` should default to `Unknown`, `varchar_field2` is NULL
{"varchar_field1": "Product C", "varchar_field2": None, "pk": 4, "embedding": [0.5, 0.7, 0.2]}, # `varchar_field2` is NULL
{"varchar_field1": None, "varchar_field2": "Exclusive deal", "pk": 5, "embedding": [0.6, 0.4, 0.8]}, # `varchar_field1` should default to `Unknown`
{"varchar_field1": "Unknown", "varchar_field2": None, "pk": 6, "embedding": [0.8, 0.5, 0.3]}, # `varchar_field2` is NULL
{"varchar_field1": "", "varchar_field2": "Best seller", "pk": 7, "embedding": [0.8, 0.5, 0.3]}, # Empty string is not treated as NULL
]
client.insert(
collection_name="my_collection",
data=data
)5.4.4.过滤表达式检索
使用query 方法检索与指定过滤表达式匹配的实体。
搜索--向量,检索--标量
1.要检索varchar_field1 与字符串"Product A" 匹配的实体:
python
filter = 'varchar_field1 == "Product A"'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)Example output: # data: [
"{'varchar_field1': 'Product A', 'varchar_field2': 'High quality product', 'pk': 1}"
]
2.检索varchar_field2 为空的实体:
python
# Filter entities where `varchar_field2` is null
filter = 'varchar_field2 is null'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)
# Example output:
# data: [
# "{'varchar_field1': 'Product B', 'varchar_field2': None, 'pk': 2}",
# "{'varchar_field1': 'Unknown', 'varchar_field2': None, 'pk': 3}",
# "{'varchar_field1': 'Product C', 'varchar_field2': None, 'pk': 4}",
# "{'varchar_field1': 'Unknown', 'varchar_field2': None, 'pk': 6}"
# ]3.要检索varchar_field1 的值为"Unknown" 的实体,请使用下面的表达式。
由于varchar_field1 的默认值是"Unknown" ,因此预期结果应包括将varchar_field1 明确设置为"Unknown" 或将varchar_field1 设置为空的实体。
python
# Filter entities with `varchar_field1` with value `Unknown`
filter = 'varchar_field1 == "Unknown"'
res = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["varchar_field1", "varchar_field2"]
)
print(res)
# Example output:
# data: [
# "{'varchar_field1': 'Unknown', 'varchar_field2': None, 'pk': 3}",
# "{'varchar_field1': 'Unknown', 'varchar_field2': 'Exclusive deal', 'pk': 5}",
# "{'varchar_field1': 'Unknown', 'varchar_field2': None, 'pk': 6}"
# ]5.4.5.过滤表达式进行搜索
除了基本的标量字段筛选外,您还可以将向量相似性搜索与标量字段筛选结合起来。例如,下面的代码展示了如何在向量搜索中添加标量字段过滤器:
python
filter = 'varchar_field2 == "Best seller"'
res = client.search(
collection_name="my_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["varchar_field1", "varchar_field2"],
filter=filter
)
print(res)5.5.数字字段
数字字段是一种存储数值的标量字段。这些数值可以是整数(整数 )或十进制数**(浮点数**)。它们通常用于表示数量、测量值或任何需要进行数学处理的数据。
5.5.1.添加数字字段
要存储数值数据,请在 Collections Schema 中定义一个数字字段。下面是一个包含两个数字字段的 Collections 模式示例:
-
age:存储整数数据,允许空值,默认值为18。 -
price:存储浮点数据,允许空值,但没有默认值。
python
from pymilvus import MilvusClient, DataType
SERVER_ADDR = "http://localhost:19530"
client = MilvusClient(uri=SERVER_ADDR)
schema = client.create_schema(
auto_id=False,
enable_dynamic_fields=True,
)
schema.add_field(field_name="age", datatype=DataType.INT64, nullable=True, default_value=18)
schema.add_field(field_name="price", datatype=DataType.FLOAT, nullable=True)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)5.5.2.设置索引参数
索引有助于提高搜索和查询性能。在 Milvus 中,对于向量字段必须建立索引,但对于标量字段可选。
下面的示例使用AUTOINDEX 索引类型为向量字段embedding 和标量字段age 创建了索引。使用这种类型,Milvus 会根据数据类型自动选择最合适的索引。您还可以自定义每个字段的索引类型和参数。有关详情,请参阅索引说明。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="age",
index_type="AUTOINDEX",
index_name="age_index"
)
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX", # Use automatic indexing to simplify complex index settings
metric_type="COSINE" # Specify similarity metric type, options include L2, COSINE, or IP
)5.5.3.插入数据
定义好 Schema 和索引后,创建一个包含数字字段的 Collection。
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)创建 Collections 后,插入与 Schema 匹配的实体。
python
data = [
{"age": 25, "price": 99.99, "pk": 1, "embedding": [0.1, 0.2, 0.3]},
{"age": 30, "pk": 2, "embedding": [0.4, 0.5, 0.6]}, # `price` field is missing, which should be null
{"age": None, "price": None, "pk": 3, "embedding": [0.2, 0.3, 0.1]}, # `age` should default to 18, `price` is null
{"age": 45, "price": None, "pk": 4, "embedding": [0.9, 0.1, 0.4]}, # `price` is null
{"age": None, "price": 59.99, "pk": 5, "embedding": [0.8, 0.5, 0.3]}, # `age` should default to 18
{"age": 60, "price": None, "pk": 6, "embedding": [0.1, 0.6, 0.9]} # `price` is null
]
client.insert(
collection_name="my_collection",
data=data
)5.5.4.过滤表达式检索
python
#检索age 大于 30 的实体:
filter = 'age > 30'
res = client.query(
collection_name="my_collection",
filter=filter,#这里是过滤条件,标量
output_fields=["age", "price", "pk"]
)
print(res)
#除了基本的数字字段过滤外,您还可以将向量相似性搜索与数字字段过滤器结合起来
filter = "25 <= age <= 35"
res = client.search(
collection_name="my_collection",
data=[[0.3, -0.6, 0.1]],
limit=5,
search_params={"params": {"nprobe": 10}},
output_fields=["age","price"],
filter=filter
)
print(res)5.6.Json字段
在构建产品目录、内容管理系统或用户偏好引擎等应用程序时,您往往需要在存储向量 Embeddings 的同时存储灵活的元数据。产品属性因类别而异,用户偏好随时间演变,文档属性具有复杂的嵌套结构。Milvus 中的 JSON 字段解决了这一难题,允许您在不牺牲性能的情况下存储和查询灵活的结构化数据。
JSON 字段是 Milvus 中的一种 Schema 定义数据类型 (DataType.JSON),用于存储结构化的键值数据。与传统的刚性数据库列不同,JSON 字段可容纳嵌套对象、数组和混合数据类型,同时提供多种索引选项,以实现快速查询。
python
{
"metadata": {
"category": "electronics",
"brand": "BrandA",
"in_stock": true,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
}在这个示例中,metadata 是一个单一的 JSON 字段,包含平面值(如category,in_stock )、数组 (tags) 和嵌套对象 (supplier) 的混合数据。
5.6.1.定义 JSON 字段
要使用 JSON 字段,请在创建 Collection 时在模式 Schema 中明确定义该字段。下面的示例演示了如何创建一个带有metadata 类型字段**DataType.JSON** 的 Collections:
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530") # Replace with your server address
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="product_id", datatype=DataType.INT64, is_primary=True) # Primary field
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5) # Vector field
schema.add_field(field_name="metadata", datatype=DataType.JSON, nullable=True)
client.create_collection(
collection_name="product_catalog",
schema=schema
)5.6.2.插入数据
创建 Collections 后,在指定的 JSON 字段中插入包含结构化 JSON 对象的实体。数据格式应为字典列表。
python
entities = [
{
"product_id": 1,
"vector": [0.1, 0.2, 0.3, 0.4, 0.5],
# highlight-start
"metadata": { # JSON field
"category": "electronics",
"brand": "BrandA",
"in_stock": True,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
# highlight-end
}
]
client.insert(collection_name="product_catalog", data=entities)5.6.3.过滤操作符
在对 JSON 字段执行过滤操作前,请确保
-
您已在每个向量字段上创建了索引。
-
Collections 已加载到内存中。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX",
index_name="vector_index",
metric_type="COSINE"
)
client.create_index(collection_name="product_catalog", index_params=index_params)
client.load_collection(collection_name="product_catalog")#加载数据表1.使用 JSON 路径语法进行筛选
要查询特定键,请使用括号符号访问 JSON 键:json_field_name["key"] 。对于嵌套键,可将它们串联起来:json_field_name["key1"]["key2"] 。
要过滤category 是"electronics" 的实体:
python
filter = 'metadata["category"] == "electronics"'
client.search(
collection_name="product_catalog", # Collection name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector (must match collection's vector dim)
limit=5, # Max. number of results to return
# highlight-next-line
filter=filter, # Filter expression
output_fields=["product_id", "metadata"] # Fields to include in the search results
)2.使用特定于 JSON 的操作符进行过滤
Milvus 还提供特殊操作符,用于查询特定 JSON 字段键上的数组值。例如
-
json_contains(identifier, expr):检查 JSON 数组中是否存在特定元素或子数组 -
json_contains_all(identifier, expr):确保指定 JSON 表达式的所有元素都存在于字段中 -
json_contains_any(identifier, expr):过滤字段中至少存在一个 JSON 表达式成员的实体
查找tags 关键字下具有"summer_sale" 值的产品:
python
filter = 'json_contains(metadata["tags"], "summer_sale")'
res = client.search(
collection_name="product_catalog", # Collection name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector (must match collection's vector dim)
limit=5, # Max. number of results to return
# highlight-next-line
filter=filter, # Filter expression
output_fields=["product_id", "metadata"] # Fields to include in the search results
)
print(res)查找在tags 关键字下至少有一个"electronics" 、"new" 或"clearance" 值的产品:
python
filter = 'json_contains_any(metadata["tags"], ["electronics", "new", "clearance"])'
res = client.search(
collection_name="product_catalog", # Collection name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector (must match collection's vector dim)
limit=5, # Max. number of results to return
# highlight-next-line
filter=filter, # Filter expression
output_fields=["product_id", "metadata"] # Fields to include in the search results
)
print(res)5.6.4.json索引
JSON 字段为在 Milvus 中存储结构化元数据提供了一种灵活的方式。如果没有索引,对 JSON 字段的查询需要全 Collection 扫描,随着数据集的增长,扫描速度也会变慢。JSON 索引通过在 JSON 数据中创建索引来实现快速查询。
JSON 索引适用于
-
具有一致、已知键的结构化 Schema
-
特定 JSON 路径上的等价和范围查询
-
需要精确控制索引键的情况
-
对目标查询进行高效存储加速
创建 JSON 索引时,需要指定
-
JSON 路径:要索引的数据的确切位置
-
数据类型:如何解释和存储索引值
-
可选类型转换:如果需要,在索引过程中转换数据
python
# 创建 Milvus 客户端所需的索引参数配置对象
index_params = MilvusClient.prepare_index_params()
# 为指定的 JSON 字段添加索引配置
index_params.add_index(
field_name="<json_field_name>", # JSON 类型字段的名称(集合中定义的字段名)
index_type="AUTOINDEX", # 索引类型,对于 JSON 字段必须为 "AUTOINDEX" 或 "INVERTED"
index_name="<unique_index_name>", # 为此索引指定一个唯一名称,便于管理和识别
params={
# 指定 JSON 数据内部要建立索引的具体键路径(例如:("$.user.age"))
"json_path": "<path_to_json_key>",
# 指定该 JSON 键对应值在索引时应被解释为何种数据类型(如 "int64"、"string"、"double" 等)
"json_cast_type": "<data_type>",
# (可选)指定一个转换函数,在索引时将该键的值转换为目标类型(例如处理字符串转数字等)
# "json_cast_function": "<cast_function>"
}
)JSON 结构示例
python
{
"metadata": {
"category": "electronics",
"brand": "BrandA",
"in_stock": true,
"price": 99.99,
"string_price": "99.99",
"tags": ["clearance", "summer_sale"],
"supplier": {
"name": "SupplierX",
"country": "USA",
"contact": {
"email": "support@supplierx.com",
"phone": "+1-800-555-0199"
}
}
}
}1.基本设置
在创建任何 JSON 索引之前,请准备好索引参数:
python
index_params = MilvusClient.prepare_index_params()2.索引一个简单的 JSON 键
在category 字段上创建索引,以便按产品类别快速筛选:
python
index_params.add_index(
field_name="metadata",
# highlight-next-line
index_type="AUTOINDEX", # Must be set to AUTOINDEX or INVERTED for JSON path indexing
index_name="category_index", # Unique index name
# highlight-start
params={
"json_path": 'metadata["category"]', # Path to the JSON key
"json_cast_type": "varchar" # Data cast type
}
# highlight-end
)3.索引嵌套键
在深度嵌套的email 字段上创建索引,用于搜索供应商联系人:
python
index_params.add_index(
field_name="metadata",
# highlight-next-line
index_type="AUTOINDEX", # Must be set to AUTOINDEX or INVERTED for JSON path indexing
index_name="email_index", # Unique index name
# highlight-start
params={
"json_path": 'metadata["supplier"]["contact"]["email"]', # Path to the nested JSON key
"json_cast_type": "varchar" # Data cast type
}
# highlight-end
)4.索引时转换数据类型
有时,数字数据会被错误地存储为字符串。使用STRING_TO_DOUBLE 转换功能进行正确转换和索引:
python
index_params.add_index(
field_name="metadata",
# highlight-next-line
index_type="AUTOINDEX", # Must be set to AUTOINDEX or INVERTED for JSON path indexing
index_name="string_to_double_index", # Unique index name
params={
"json_path": 'metadata["string_price"]', # Path to the JSON key to be indexed
"json_cast_type": "double", # Data cast type
# highlight-next-line
"json_cast_function": "STRING_TO_DOUBLE" # Cast function; case insensitive
}
)5.索引整个对象
索引整个 JSON 对象,以便对其中的任何字段进行查询。使用json_cast_type="JSON" 时,系统会自动
-
使 JSON 结构扁平化:将嵌套对象转换为扁平路径,以实现高效索引
-
推断数据类型:根据每个值的内容自动将其归类为数值、字符串、布尔值或日期值
-
创建全面的覆盖范围:对象中的所有键和嵌套路径均可搜索
对于上述示例 JSON 结构,可对整个metadata 对象进行索引:
python
index_params.add_index(
field_name="metadata",
index_type="AUTOINDEX",
index_name="metadata_full_index",
params={
# highlight-start
"json_path": "metadata",
"json_cast_type": "JSON"
# highlight-end
}
)6.应用索引配置
定义好所有索引参数后,将其应用到 Collections 中:
python
MilvusClient.create_index(
collection_name="your_collection_name",
index_params=index_params
)后面的数组、结构体数组、几何领域就不说了
6.插入和删除数据
Collections 中的实体是指共享同一组字段的数据记录。每条数据记录中的字段值构成一个实体。本页介绍如何在 Collections 中插入实体。
如果在创建 Collections 后动态添加新字段,并且在插入实体时没有为这些字段指定值,Milvus 会自动用定义的默认值填充它们,如果没有设置默认值,则填充 NULL。有关详细信息,请参阅向现有 Collections 添加字段。
-
创建 Collections 后添加的字段 :如果在创建后向 Collections 添加新字段,并且在插入时没有指定值,Milvus 会自动用定义的默认值填充它们,如果没有设置默认值,则填充 NULL。有关详情,请参阅向现有 Collections 添加字段。
-
重复处理 :标准
insert操作符不会检查主键是否重复。使用现有主键插入数据会创建具有相同键的新实体,从而导致数据重复和潜在的应用问题。要更新现有实体或避免重复,请使用upsert操作符。有关详细信息,请参阅 "更新实体"。
6.1.将实体插入Collections
在插入数据之前,需要根据Schema 将数据组织到字典列表中,每个字典代表一个实体,并包含 Schema 中定义的所有字段。如果 Collection 启用了动态字段,每个字典还可以包含 Schema 中未定义的字段。
本节将向以快速设置方式创建的 Collection 中插入实体。以这种方式创建的 Collection 只有两个字段,分别名为id 和向量 。此外,该 Collections 启用了动态字段,因此示例代码中的实体包含一个名为color的字段,该字段未在 Schema 中定义。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
data=[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
]
res = client.insert(
collection_name="quick_setup",
data=data
)
print(res)将实体插入分区
您还可以将实体插入指定的分区。以下代码片段假定您的 Collections 中有一个名为PartitionA的分区。
python
data=[
{"id": 10, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 11, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 12, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 13, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 14, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 15, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 16, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 17, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 18, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 19, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
]
res = client.insert(
collection_name="quick_setup",
# highlight-next-line
partition_name="partitionA",
data=data
)
print(res)6.2.删除实体
您可以通过筛选条件或主键删除不再需要的实体。
1.通过筛选条件删除实体
批量删除共享某些属性的多个实体时,可以使用过滤表达式。下面的示例代码使用in 操作符批量删除了所有颜色 字段设置为红色 和紫色的 实体。你也可以使用其他操作符来构建符合你要求的过滤表达式。有关过滤表达式的更多信息,请参阅《过滤详解》。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.delete(
collection_name="quick_setup",
# highlight-next-line
filter="color in ['red_7025', 'purple_4976]"
)
print(res)2.通过主键删除实体
在大多数情况下,主键唯一标识一个实体。你可以通过在删除请求中设置实体的主键来删除实体。下面的示例代码演示了如何删除主键为18 和19 的两个实体。
python
res = client.delete(
collection_name="quick_setup",
# highlight-next-line
ids=[18, 19]
)
print(res)3.从分区中删除实体
您还可以删除存储在特定分区中的实体。以下代码片段假定您的 Collection 中有一个名为PartitionA的分区。
python
res = client.delete(
collection_name="quick_setup",
ids=[18, 19],
partition_name="partitionA"
)
print(res)7.索引
索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和 RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要)。因此,本文将解释如何最大限度地减少使用索引的成本,同时最大限度地提高索引的效益。
如下图所示,Milvus 中的索引类型由三个核心部分组成,即数据结构 、量化 和细化器。量化和精炼器是可选的,但由于收益大于成本的显著平衡而被广泛使用。

| 类别 | 类型/方法 | 原理与机制 | 适用场景 |
|---|---|---|---|
| 数据结构 | 反转文件(IVF) | 将向量聚类到以中心点为标识的"桶"中;查询时仅搜索中心点接近查询向量的桶,大幅减少需计算的向量数量。 | 大规模数据集,要求高吞吐量、可接受适度精度损失的场景。 |
| 基于图的结构(如 HNSW) | 构建多层图结构,上层稀疏、下层稠密;查询从顶层开始,逐层向下导航至最近邻。实现近似对数时间复杂度的高效搜索。 | 高维向量、低延迟查询需求(如实时推荐、语义搜索)。 | |
| 量化 | 标量量化(SQ8) | 将每个浮点维度压缩为 8 位整数(1 字节),内存占用减少 75%(相比 FP32),精度损失较小。 | 内存受限但需保持较高精度的通用场景。 |
| 乘积量化(PQ) | 将向量切分为子向量,对每个子空间使用聚类编码本进行压缩;可实现 4--32 倍压缩率,但召回率略有下降。 | 极端内存受限环境,可容忍一定召回率损失的大规模部署。 | |
| 精炼器 | FP32 精炼器等 | 对量化索引返回的 Top-K'(K' > K)候选结果,使用原始高精度(如 FP32)重新计算距离,从中选出最终 Top-K 结果,补偿量化带来的精度损失。 | 对结果质量敏感的应用(如语义搜索、推荐系统),需在效率与精度间取得平衡。 |
7.1.建立索引
FLAT索引是最简单、最直接的浮点向量索引和搜索方法之一。它依赖于一种 "蛮力 "方法,即直接将每个查询向量与数据集中的每个向量进行比较,而无需任何高级预处理或数据结构。这种方法保证了准确性,由于对每个潜在匹配都进行了评估,因此可提供 100% 的召回率。
不过,这种穷举式搜索方法也有代价。FLAT 索引是最慢的索引选项,因为每次查询都要对数据集进行一次全面扫描。因此,它并不适合海量数据集的环境,因为在这种环境中,性能是个问题。FLAT 索引的主要优点是简单可靠,因为它不需要训练或复杂的参数配置。
要在 Milvus 中的向量场上建立FLAT 索引,请使用add_index() 方法,为索引指定index_type 和metric_type 参数。
python
from pymilvus import MilvusClient
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="FLAT", # Type of the index to create
index_name="vector_index", # Name of the index to create
metric_type="L2", # Metric type used to measure similarity
params={} # No additional parameters required for FLAT
)7.2.在索引上搜索
建立索引并插入实体后,就可以在索引上执行相似性搜索。
python
res = MilvusClient.search(
collection_name="your_collection_name", # Collection name
anns_field="vector_field", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
limit=3, # TopK results to return
search_params={"params": {}} # No additional parameters required for FLAT
)8.搜索
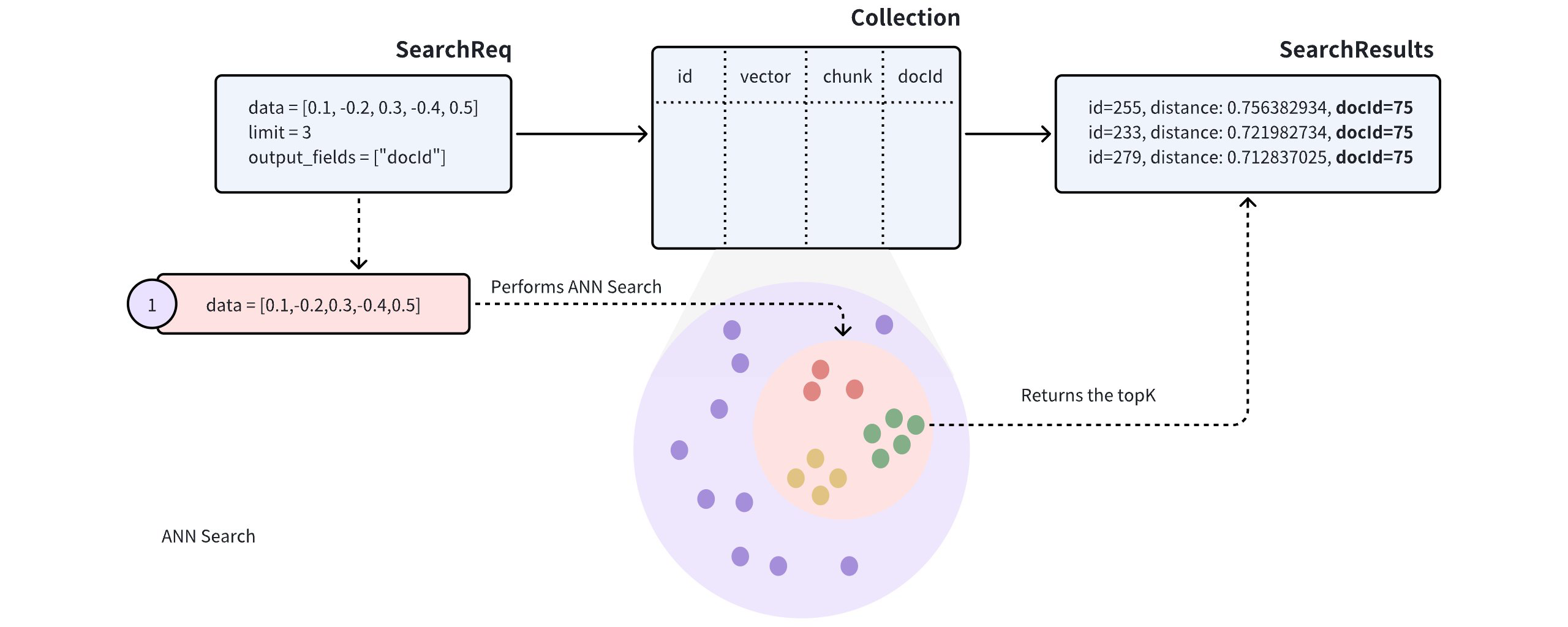
近似近邻(ANN)搜索以记录向量嵌入排序顺序的索引文件为基础 ,根据接收到的搜索请求中携带的查询向量查找向量嵌入子集,将查询向量与子群中的向量进行比较,并返回最相似的结果。通过 ANN 搜索,Milvus 提供了高效的搜索体验。本页将帮助您了解如何进行基本的 ANN 搜索。
ANN 搜索依赖于预建索引,搜索吞吐量、内存使用量和搜索正确性可能会因选择的索引类型而不同。您需要在搜索性能和正确性之间取得平衡。
8.1.单向量搜索
在 ANN 搜索中,单向量搜索指的是只涉及一个查询向量的搜索。根据预建索引和搜索请求中携带的度量类型,Milvus 将找到与查询向量最相似的前 K 个向量。
本节将介绍如何进行单向量搜索。搜索请求携带单个查询向量,要求 Milvus 使用内积(IP)计算查询向量与 Collections 中向量的相似度,并返回三个最相似的向量。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="quick_setup",
anns_field="vector",
data=[query_vector],
limit=3,
search_params={"metric_type": "IP"}
)
for hits in res:
for hit in hits:
print(hit)8.2.过滤搜索
ANN 搜索能找到与指定向量嵌入最相似的向量嵌入。但是,搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件的实体。

python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
# highlight-start
filter='color like "red%" and likes > 50',
output_fields=["color", "likes"]
# highlight-end
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)8.3.范围搜索
范围搜索可将返回实体的距离或得分限制在特定范围内,从而提高搜索结果的相关性。本页将帮助您了解什么是范围搜索以及进行范围搜索的步骤。
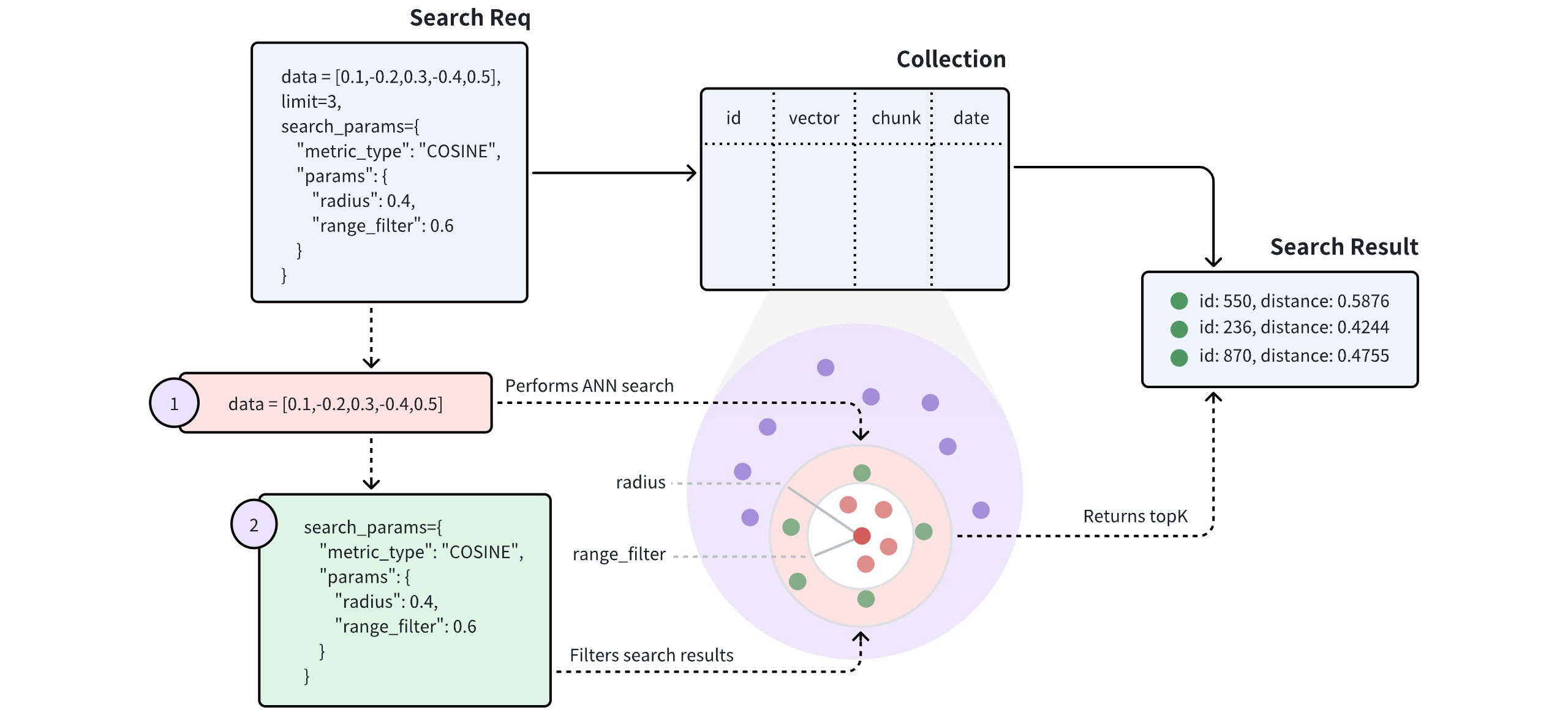
上图显示,范围搜索请求包含两个参数:半径 和range_filter。收到范围搜索请求后,Milvus 会执行以下操作:
-
使用指定的度量类型**(COSINE**)查找与查询向量最相似的所有向量嵌入。
-
过滤与查询向量的距离 或得分 在半径 和range_filter参数指定范围内的向量嵌入。
-
从筛选出的实体中返回前 K个实体。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=3,
search_params={
# highlight-start
"params": {
"radius": 0.4,
"range_filter": 0.6
}
# highlight-end
}
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)8.4.分组搜索
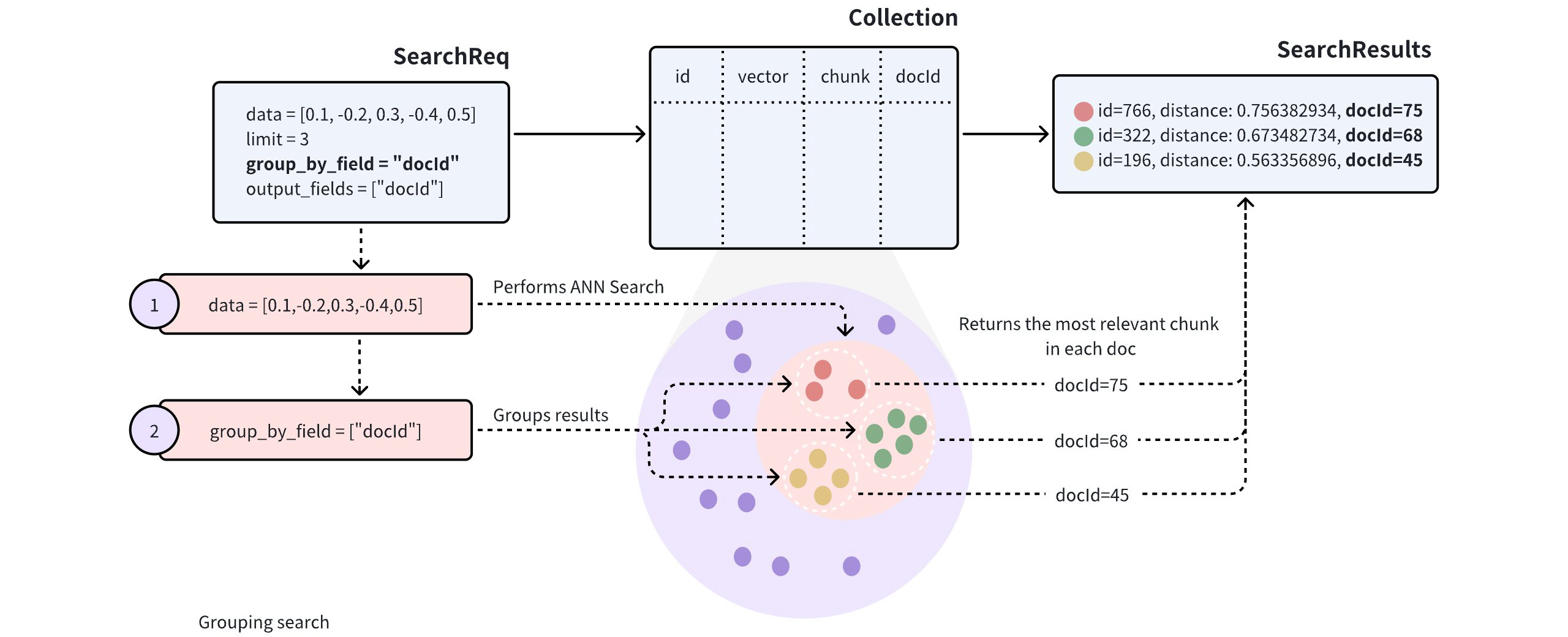
分组搜索允许 Milvus 根据指定字段的值对搜索结果进行分组,以便在更高层次上汇总数据。例如,您可以使用基本的 ANN 搜索来查找与手头的图书相似的图书,但也可以使用分组搜索来查找可能涉及该图书所讨论主题的图书类别。本主题将介绍如何使用分组搜索以及主要注意事项。
当搜索结果中的实体在标量字段中共享相同值时,这表明它们在特定属性上相似,这可能会对搜索结果产生负面影响。
假设一个 Collections 存储了多个文档(用docId 表示)。在将文档转换成向量时,为了尽可能多地保留语义信息,每份文档都会被分割成更小的、易于管理的段落(或块),并作为单独的实体存储。即使文档被分割成较小的段落,用户通常仍希望识别哪些文档与他们的需求最相关。
python
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
]在搜索请求中,将group_by_field 和output_fields 都设置为docId 。Milvus 将根据指定字段对结果进行分组,并从每个分组中返回最相似的实体,包括每个返回实体的docId 值。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vectors = [
[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]
res = client.search(
collection_name="my_collection",
data=query_vectors,
limit=3,
group_by_field="docId",
output_fields=["docId"]
)
doc_ids = [result['entity']['docId'] for result in res[0]]在上面的请求中,limit=3 表示系统将从三个组中返回搜索结果,每个组都包含与查询向量最相似的单个实体。
8.5.混合搜索
在许多应用中,可以通过标题和描述等丰富的信息集或文本、图像和音频等多种模式来搜索对象。例如,如果文本或图片与搜索查询的语义相符,就可以搜索包含一段文本和一张图片的推文。混合搜索将这些不同领域的搜索结合在一起,从而增强了搜索体验。Milvus 允许在多个向量场上进行搜索,同时进行多个近似近邻(ANN)搜索,从而支持这种搜索。如果要同时搜索文本和图像、描述同一对象的多个文本字段或密集和稀疏向量以提高搜索质量,多向量混合搜索尤其有用。
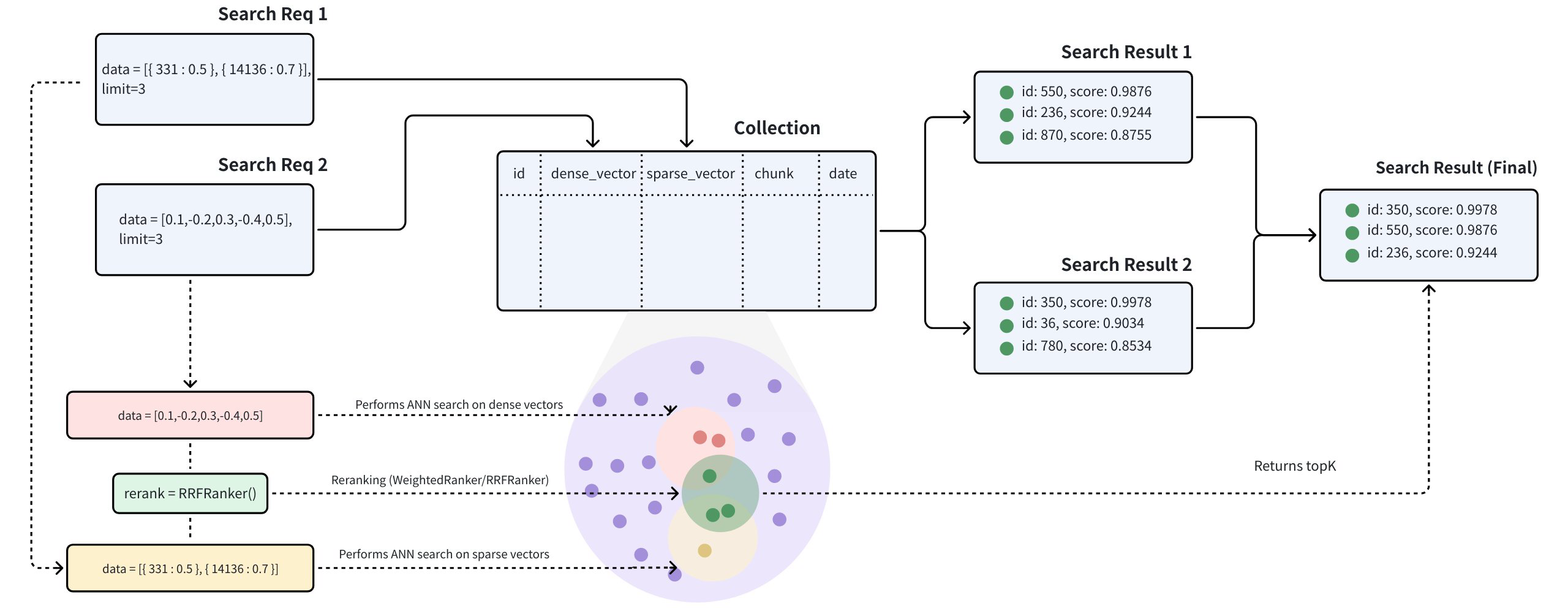
让我们考虑一个真实世界的使用案例,其中每个产品都包含文字描述和图片。根据可用数据,我们可以进行三种类型的搜索:
-
语义文本搜索: 这涉及使用密集向量查询产品的文本描述。可以使用BERT和Transformers等模型或OpenAI 等服务生成文本嵌入。
-
全文搜索 :在这里,我们使用稀疏向量的关键词匹配来查询产品的文本描述。BM25等算法或BGE-M3或SPLADE等稀疏嵌入模型可用于此目的。
-
多模态图像搜索: 这种方法使用带有密集向量的文本查询对图像进行查询。可以使用CLIP 等模型生成图像嵌入。
本指南将引导您通过一个结合上述搜索方法的多模态混合搜索示例,给出产品的原始文本描述和图像嵌入。我们将演示如何存储多向量数据并使用 Rerankers 策略执行混合搜索。
1.创建具有多个向量场的 Collections
此示例将以下字段纳入 Schema 模式:
-
id:作为存储文本 ID 的主键。该字段的数据类型为INT64。 -
text:用于存储文本内容。该字段的数据类型为VARCHAR,最大长度为 1000 字节。enable_analyzer选项设置为True,以便于全文检索。 -
text_dense:用于存储文本的密集向量。该字段的数据类型为FLOAT_VECTOR,向量维数为 768。 -
text_sparse:用于存储文本的稀疏向量。该字段的数据类型为SPARSE_FLOAT_VECTOR。 -
image_dense:用于存储产品图像的密集向量。该字段的数据类型为FLOAT_VETOR,向量维数为 512。
python
from pymilvus import (
MilvusClient, DataType, Function, FunctionType
)
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema(auto_id=False)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, description="product id")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, description="raw text of product description")
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense embedding")
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse embedding auto-generated by the built-in BM25 function")
schema.add_field(field_name="image_dense", datatype=DataType.FLOAT_VECTOR, dim=512, description="image dense embedding")
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"],
output_field_names=["text_sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)2.创建索引
定义完 Collections Schema 后,下一步就是配置向量索引并指定相似度指标。在给出的示例中
-
text_dense_index:为文本密集向量字段创建了AUTOINDEX类型的索引,其度量类型为IP。 -
text_sparse_index:为文本稀疏向量场创建了SPARSE_INVERTED_INDEX类型的索引,其度量类型为BM25。 -
image_dense_index:为图像密集向量场创建了AUTOINDEX类型的索引,其公制类型为IP。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"inverted_index_algo": "DAAT_MAXSCORE"}, # or "DAAT_WAND" or "TAAT_NAIVE"
)
index_params.add_index(
field_name="image_dense",
index_name="image_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)3.插入数据
python
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
python
import random
def generate_dense_vector(dim):
return [random.random() for _ in range(dim)]
data=[
{
"id": 0,
"text": "Red cotton t-shirt with round neck",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 1,
"text": "Wireless noise-cancelling over-ear headphones",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 2,
"text": "Stainless steel water bottle, 500ml",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
}
]
res = client.insert(
collection_name="my_collection",
data=data
)4.混合检索
步骤 1:创建多个 AnnSearchRequest 实例
混合搜索是通过在hybrid_search() 函数中创建多个AnnSearchRequest 来实现的,其中每个AnnSearchRequest 代表一个特定向量场的基本 ANN 搜索请求。因此,在进行混合搜索之前,有必要为每个向量场创建一个AnnSearchRequest 。
此外,通过在AnnSearchRequest 中配置expr 参数,可以为混合搜索设置过滤条件。请参阅过滤搜索和过滤说明。
为了演示各种搜索向量字段的功能,我们将使用一个示例查询构建三个AnnSearchRequest 搜索请求。在此过程中,我们还将使用其预先计算的密集向量。搜索请求将针对以下向量场:
-
text_dense语义文本搜索,允许基于意义而非直接关键词匹配进行上下文理解和检索。 -
text_sparse全文搜索或关键词匹配,侧重于文本中精确匹配的单词或短语。
image_dense多模态文本到图片搜索,根据查询的语义内容检索相关产品图片。
python
from pymilvus import AnnSearchRequest
query_text = "white headphones, quiet and comfortable"
query_dense_vector = generate_dense_vector(768)
query_multimodal_vector = generate_dense_vector(512)
search_param_1 = {
"data": [query_dense_vector],
"anns_field": "text_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_1 = AnnSearchRequest(**search_param_1)
search_param_2 = {
"data": [query_text],
"anns_field": "text_sparse",
"param": {"drop_ratio_search": 0.2},
"limit": 2
}
request_2 = AnnSearchRequest(**search_param_2)
search_param_3 = {
"data": [query_multimodal_vector],
"anns_field": "image_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_3 = AnnSearchRequest(**search_param_3)
reqs = [request_1, request_2, request_3]参数limit 设置为 2 时,每个AnnSearchRequest 会返回 2 个搜索结果。在本示例中,创建了 3 个AnnSearchRequest 实例,总共产生了 6 个搜索结果。
步骤 2:配置 Rerankers 策略
要对 ANN 搜索结果集进行合并和重新排序,选择适当的重新排序策略至关重要。Milvus 提供多种重排策略。有关这些重排机制的更多详情,请参阅加权排名器或RRF 排名器。
在本例中,由于没有特别强调特定的搜索查询,我们将采用 RRFRanker 策略。
python
ranker = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)步骤 3:执行混合搜索
hybrid:a.混合
在启动混合搜索之前,请确保已加载 Collections。如果集合中的任何向量字段缺少索引或未加载到内存中,执行混合搜索方法时就会出错。
python
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)"\['id: 1, distance: 0.006047376897186041, entity: {}', 'id: 2, distance: 0.006422005593776703, entity: {}'\]"
9.查询
除 ANN 搜索外,Milvus 还支持通过查询过滤元数据。本页将介绍如何使用查询、获取和查询迭代器来执行元数据过滤。
Collections 可以存储各种类型的标量字段。你可以让 Milvus 根据一个或多个标量字段过滤实体。Milvus 提供三种类型的查询:查询、获取和查询迭代器。下表比较了这三种查询类型。
| 获取 | 查询 | 查询迭代器 |
|------|-----------------------|-----------------------------------|----------------------------------------|
| 适用情况 | 查找持有指定主键的实体。 | 查找符合自定义筛选条件的所有实体或指定数量的实体 | 在分页查询中查找满足自定义筛选条件的所有实体。 |
| 过滤方法 | 通过主键 | 通过过滤表达式 | 通过过滤表达式 |
| 必填参数 | * Collections 名称 * 主键 | * Collections 名称 * 过滤表达式 | * Collections 名称 * 过滤表达式 * 每次查询返回的实体数量 |
| 可选参数 | * 分区名称 * 输出字段 | * 分区名称 * 要返回的实体数量 * 输出字段 | * 分区名称 * 要返回的实体总数 * 输出字段 |
| 返回值 | 返回指定集合或分区中持有指定主键的实体。 | 返回指定集合或分区中符合自定义筛选条件的所有实体或指定数量的实体。 | 通过分页查询返回指定集合或分区中符合自定义过滤条件的所有实体。 |
9.1.获取-get
当需要通过主键查找实体时,可以使用Get 方法。以下代码示例假定在 Collections 中有三个字段,分别名为id 、vector 和color 。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"},
]
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.get(
collection_name="my_collection",
ids=[0, 1, 2],
output_fields=["vector", "color"]
)
print(res)9.2.查询-query
当您需要通过自定义过滤条件查找实体时,请使用Query 方法。以下代码示例假定有三个字段,分别名为id 、vector 和color ,并返回从red 开始持有color 值的实体的指定数目。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.query(
collection_name="my_collection",
filter="color like \"red%\"",
output_fields=["vector", "color"],
limit=3
)9.3.分区中的查询
您还可以通过在 Get、Query 或 QueryIterator 请求中包含分区名称,在一个或多个分区中执行查询。以下代码示例假定 Collections 中有一个名为PartitionA的分区。
python
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.get(
collection_name="my_collection",
# highlight-next-line
partitionNames=["partitionA"],
ids=[10, 11, 12],
output_fields=["vector", "color"]
)
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
res = client.query(
collection_name="my_collection",
# highlight-next-line
partitionNames=["partitionA"],
filter="color like \"red%\"",
output_fields=["vector", "color"],
limit=3
)
from pymilvus import connections, Collection
connections.connect(
uri="http://localhost:19530",
token="root:Milvus"
)
collection = Collection("my_collection")
iterator = collection.query_iterator(
# highlight-next-line
partition_names=["partitionA"],
batch_size=10,
expr="color like \"red%\"",
output_fields=["color"]
)
results = []
while True:
result = iterator.next()
if not result:
iterator.close()
break
print(result)
results += result10.过滤
Milvus 提供强大的过滤功能,可精确查询数据。过滤表达式允许你针对特定的标量字段,用不同的条件细化搜索结果。本指南介绍如何在 Milvus 中使用过滤表达式,并以查询操作符为例。您还可以在搜索和删除请求中应用这些过滤器。
10.1.基本操作符
Milvus 支持几种用于过滤数据的基本操作符:
-
比较操作符 :
==,!=,>,<,>=, 和<=允许基于数字或文本字段进行筛选。 -
范围过滤器 :
IN和LIKE可帮助匹配特定的值范围或集合。 -
算术操作符 :
+,-,*,/,%, 和**用于涉及数字字段的计算。 -
逻辑操作符 :
AND,OR, 和NOT将多个条件组合成复杂的表达式。 -
IS NULL 和 IS NOT NULL 操作符 :
IS NULL和IS NOT NULL操作符用于根据字段是否包含空值(无数据)来筛选字段。有关详细信息,请参阅基本操作符。
要在标量字段color 中查找具有三原色(红色、绿色或蓝色)的实体,请使用以下过滤表达式:
filter='color in ["red", "green", "blue"]'Milvus 允许在 JSON 字段中引用键。例如,如果您有一个带有键price 和model 的 JSON 字段product ,并想查找具有特定模型且价格低于 1,850 的产品,请使用此过滤表达式:
filter='product["model"] == "JSN-087" AND product["price"] < 1850'如果有一个数组字段history_temperatures ,其中包含自 2000 年以来各观测站报告的平均气温记录,要查找 2009 年(第 10 次记录)气温超过 23°C 的观测站,请使用此表达式:
filter='history_temperatures[10] > 23'11.全文搜索
全文搜索是一种在文本数据集中检索包含特定术语或短语的文档,然后根据相关性对结果进行排序的功能。该功能克服了语义搜索的局限性(语义搜索可能会忽略精确的术语),确保您获得最准确且与上下文最相关的结果。此外,它还通过接受原始文本输入来简化向量搜索,自动将您的文本数据转换为稀疏嵌入,而无需手动生成向量嵌入。
该功能使用 BM25 算法进行相关性评分,在检索增强生成 (RAG) 场景中尤为重要,它能优先处理与特定搜索词密切匹配的文档。
11.1.BM25 实施
Milvus 提供由 BM25 相关性算法驱动的全文搜索,BM25 是信息检索系统中广泛采用的评分功能,Milvus 将其集成到搜索工作流中,以提供准确的相关性排名文本结果。
Milvus 的全文搜索遵循以下工作流程:
-
原始文本输入:插入文本文档或使用纯文本提供查询,无需嵌入模型。
-
文本分析 :Milvus 使用分析器将您的文本处理成可索引和搜索的有意义术语。
-
BM25 函数处理:一个内置函数可将这些术语转换为针对 BM25 评分优化的稀疏向量表示。
-
Collections 存储:Milvus 将生成的稀疏嵌入存储在一个 Collections 中,以便快速检索和排序。
-
BM25 相关性评分:在搜索时,Milvus 应用 BM25 评分函数计算文档相关性,并返回与查询词最匹配的排序结果。

要使用全文搜索,请遵循以下主要步骤:
-
创建 Collections:设置所需字段并定义 BM25 函数,将原始文本转换为稀疏嵌入。
-
插入数据:将原始文本文档输入 Collections。
-
执行搜索:使用自然语言查询文本,根据 BM25 相关性检索排序结果。
11.2.创建 Collections
要启用 BM25 支持的全文搜索,您必须准备一个包含所需字段的 Collections,定义一个 BM25 函数来生成稀疏向量,配置索引,然后创建 Collections。
您的 Collections Schema 必须包含至少三个必填字段:
-
主字段:唯一标识 Collections 中的每个实体。
-
文本字段 (
VARCHAR):存储原始文本文档。必须设置enable_analyzer=True,以便 Milvus 处理文本,进行 BM25 相关性排序。默认情况下,Milvus 使用 standard分析器进行文本分析。要配置不同的分析器,请参阅分析器概述。 -
稀疏向量场 (
SPARSE_FLOAT_VECTOR):存储由 BM25 函数自动生成的稀疏嵌入。
python
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors在前面的配置中、
-
id: 作为主键,由auto_id=True自动生成。 -
text:存储原始文本数据,用于全文搜索操作符。数据类型必须是VARCHAR,因为VARCHAR是用于文本存储的 Milvus 字符串数据类型。 -
sparse:一个向量字段,用于存储内部生成的稀疏嵌入,以进行全文搜索操作。数据类型必须是SPARSE_FLOAT_VECTOR。
11.3.定义 BM25 函数
BM25 函数将标记化文本转换为支持 BM25 评分的稀疏向量。
python
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
# highlight-next-line
function_type=FunctionType.BM25, # Set to `BM25`
)
schema.add_function(bm25_function)| 参数 | 参数 |
|---|---|
name |
函数名称。该函数将text 字段中的原始文本转换为 BM25 兼容的稀疏向量,这些稀疏向量将存储在sparse 字段中。 |
input_field_names |
需要将文本转换为稀疏向量的VARCHAR 字段的名称。对于FunctionType.BM25 ,该参数只接受一个字段名称。 |
output_field_names |
存储内部生成的稀疏向量的字段名称。对于FunctionType.BM25 ,该参数只接受一个字段名称。 |
function_type |
要使用的函数类型。必须为FunctionType.BM25 。 |
11.4.配置索引
在定义了包含必要字段和内置函数的 Schema 后,请为您的 Collections 设置索引。
python
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
)11.5.插入文本数据
现在使用定义的 Schema 和索引参数创建 Collections。
python
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)设置好集合和索引后,就可以插入文本数据了。在此过程中,您只需提供原始文本。我们之前定义的内置函数会为每个文本条目自动生成相应的稀疏向量。
python
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])11.6.执行全文搜索
将数据插入 Collections 后,就可以使用原始文本查询执行全文检索了。Milvus 会自动将您的查询转换为稀疏向量,并使用BM25 算法对匹配的搜索结果进行排序 ,然后返回 topK (limit) 结果。
python
search_params = {
'params': {'drop_ratio_search': 0.2},
}
client.search(
collection_name='my_collection',
# highlight-start
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
# highlight-end
limit=3,
search_params=search_params
)12.文本匹配
Milvus 的文本匹配功能可根据特定术语精确检索文档 。该功能主要用于满足特定条件的过滤搜索,并可结合标量过滤功能来细化查询结果,允许在符合标量标准的向量内进行相似性搜索。
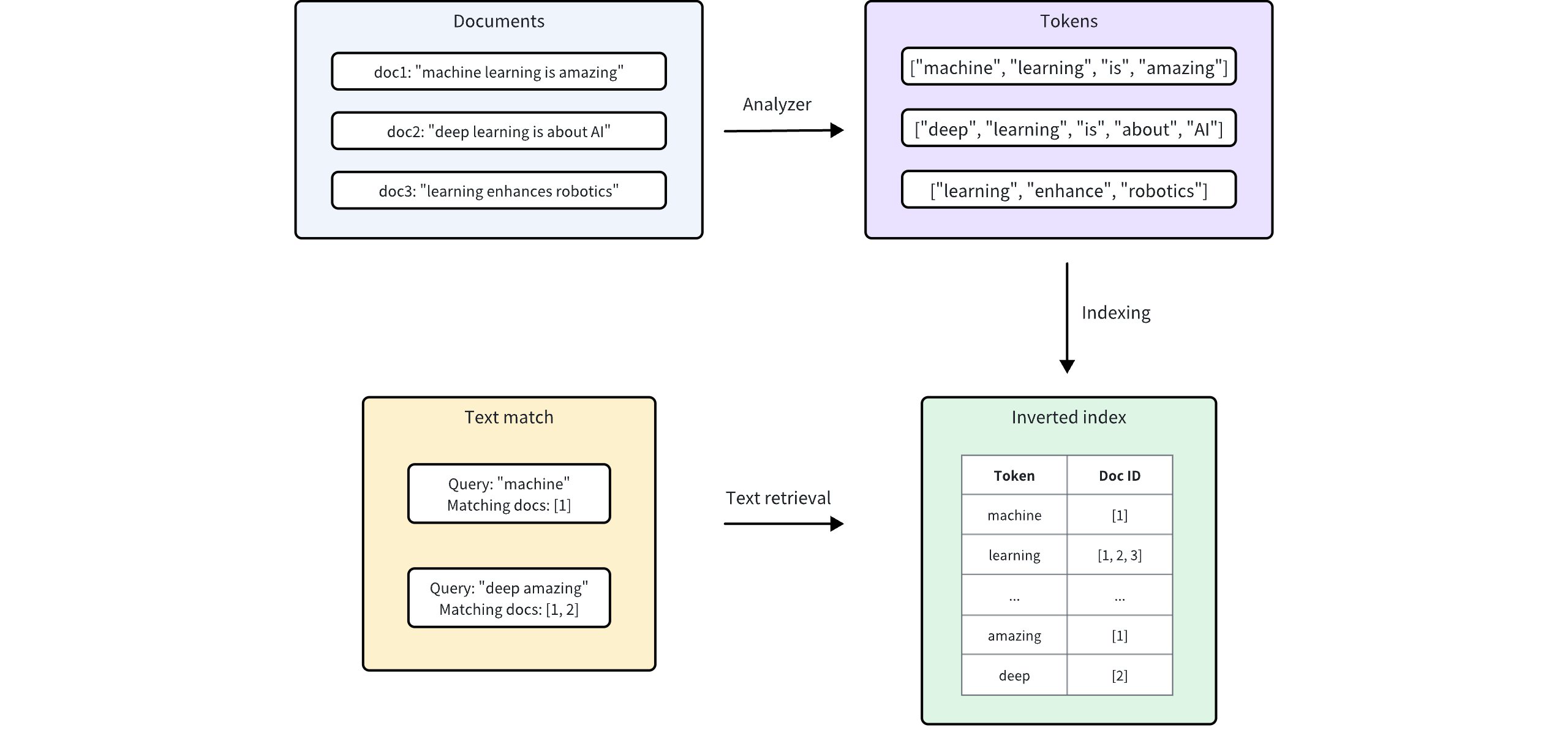
Milvus 整合了Tantivy来支持其底层的倒排索引和基于术语的文本搜索。对于每个文本条目,Milvus 都会按照以下程序建立索引:
-
分析器:分析器将输入文本标记化为单个词或标记,然后根据需要应用过滤器。这样,Milvus 就能根据这些标记建立索引。
-
编制索引:文本分析完成后,Milvus 会创建一个倒排索引,将每个独特的标记映射到包含该标记的文档。
当用户进行文本匹配时,倒排索引可用于快速检索包含该术语的所有文档。这比逐个扫描每个文档要快得多。
关键词匹配
12.1.启用文本匹配
文本匹配适用于VARCHAR 字段类型,它本质上是 Milvus 中的字符串数据类型。要启用文本匹配,请将enable_analyzer 和enable_match 都设置为True ,然后在定义 Collections Schema 时选择性地配置分析器进行文本分析。
要启用特定VARCHAR 字段的文本匹配,请在定义字段 Schema 时将enable_analyzer 和enable_match 参数设置为True 。这将指示 Milvus 对文本进行标记化处理,并为指定字段创建反向索引,从而实现快速高效的文本匹配。
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True, # Whether to enable text analysis for this field
enable_match=True # Whether to enable text match
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)可选:配置分析器
关键词匹配的性能和准确性取决于所选的分析器。不同的分析器适用于不同的语言和文本结构,因此选择正确的分析器会极大地影响特定用例的搜索结果。
默认情况下,Milvus 使用standard 分析器,该分析器根据空白和标点符号对文本进行标记,删除长度超过 40 个字符的标记,并将文本转换为小写。应用此默认设置无需额外参数。更多信息,请参阅标准。
如果需要不同的分析器,可以使用**analyzer_params** 参数进行配置。例如,应用english 分析器处理英文文本:
python
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params = analyzer_params,
enable_match = True,
)12.2.使用文本匹配
为 Collections Schema 中的 VARCHAR 字段启用文本匹配后,就可以使用TEXT_MATCH 表达式执行文本匹配。
TEXT_MATCH 表达式用于指定要搜索的字段和术语。其语法如下:
python
TEXT_MATCH(field_name, text)-
field_name:要搜索的 VARCHAR 字段的名称。 -
text:要搜索的术语。根据语言和配置的分析器,多个术语可以用空格或其他适当的分隔符分隔。
默认情况下,TEXT_MATCH 使用OR 匹配逻辑,这意味着它会返回包含任何指定术语的文档。例如,要搜索text 字段中包含machine 或deep 的文档,请使用以下表达式:
python
filter = "TEXT_MATCH(text, 'machine deep')"您还可以使用逻辑操作符组合多个TEXT_MATCH 表达式来执行AND匹配。
1.要搜索text 字段中同时包含machine 和deep 的文档,请使用以下表达式:
python
filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"2.要搜索text 字段中同时包含machine 和learning 但不包含deep 的文档,请使用以下表达式:
python
filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"12.3.使用文本匹配搜索
文本匹配可与向量相似性搜索结合使用,以缩小搜索范围并提高搜索性能。通过在向量相似性搜索前使用文本匹配过滤 Collections,可以减少需要搜索的文档数量,从而加快查询速度。
在这个示例中,filter 表达式过滤了搜索结果,使其只包含与指定术语keyword1 或keyword2 匹配的文档。然后在这个过滤后的文档子集中执行向量相似性搜索。
python
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
result = client.search(
collection_name="my_collection", # Your collection name
anns_field="embeddings", # Vector field name
data=[query_vector], # Query vector
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=10, # Max. number of results to return
output_fields=["id", "text"] # Fields to return
)文本匹配查询
文本匹配也可用于查询操作中的标量过滤。通过在query() 方法的expr 参数中指定TEXT_MATCH 表达式,可以检索与给定术语匹配的文档。
下面的示例检索了text 字段包含keyword1 和keyword2 这两个术语的文档。
python
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["id", "text"]
)-
为字段启用术语匹配会触发反向索引的创建,从而消耗存储资源。在决定是否启用此功能时,请考虑对存储的影响,因为它根据文本大小、唯一标记和所使用的分析器而有所不同。
-
在 Schema 中定义分析器后,其设置将永久适用于该 Collections。如果您认为不同的分析器更适合您的需要,您可以考虑删除现有的 Collections,然后使用所需的分析器配置创建一个新的 Collections。
-
filter表达式中的转义规则:-
表达式中用双引号或单引号括起来的字符被解释为字符串常量。如果字符串常量包含转义字符,则必须使用转义序列来表示转义字符。例如,用
\\表示\,用\\t表示制表符\t,用\\n表示换行符。 -
如果字符串常量由单引号括起来,常量内的单引号应表示为
\\',而双引号可表示为"或\\"。 示例:'It\\'s milvus'。 -
如果字符串常量由双引号括起来,常量中的双引号应表示为
\\",而单引号可表示为'或\\'。 示例:"He said \\"Hi\\""。
-
13.短语匹配
短语匹配可让您搜索包含精确短语查询词的文档。默认情况下,单词必须以相同的顺序出现,并且彼此直接相邻。例如,"机器人机器学习 " 的查询会匹配"...典型的机器人机器学习模型... " 这样的文本,其中**"机器人"、** " 机器 " 和**"学习 "**依次出现,中间没有其他词。
然而,在现实世界中,严格的短语匹配可能过于死板。您可能希望匹配的文本是*"......机器人技术中广泛采用的机器学习模型.* ....."。在这种情况下,相同的关键词会出现,但不会并排出现,也不会按照原来的顺序排列。为了处理这种情况,短语匹配支持一个slop 参数,从而增加了灵活性。slop 的值定义了短语中的词语之间允许多少次位置移动。例如,当slop 为 1 时,"机器学习 " 查询可以匹配*"......机器深度学习...... "* 这样的文本,其中一个单词(**"deep")**分隔了原始术语。
13.1.概述
短语匹配由Tantivy搜索引擎库提供支持,通过分析文档中单词的位置信息来实现。下图说明了这一过程:
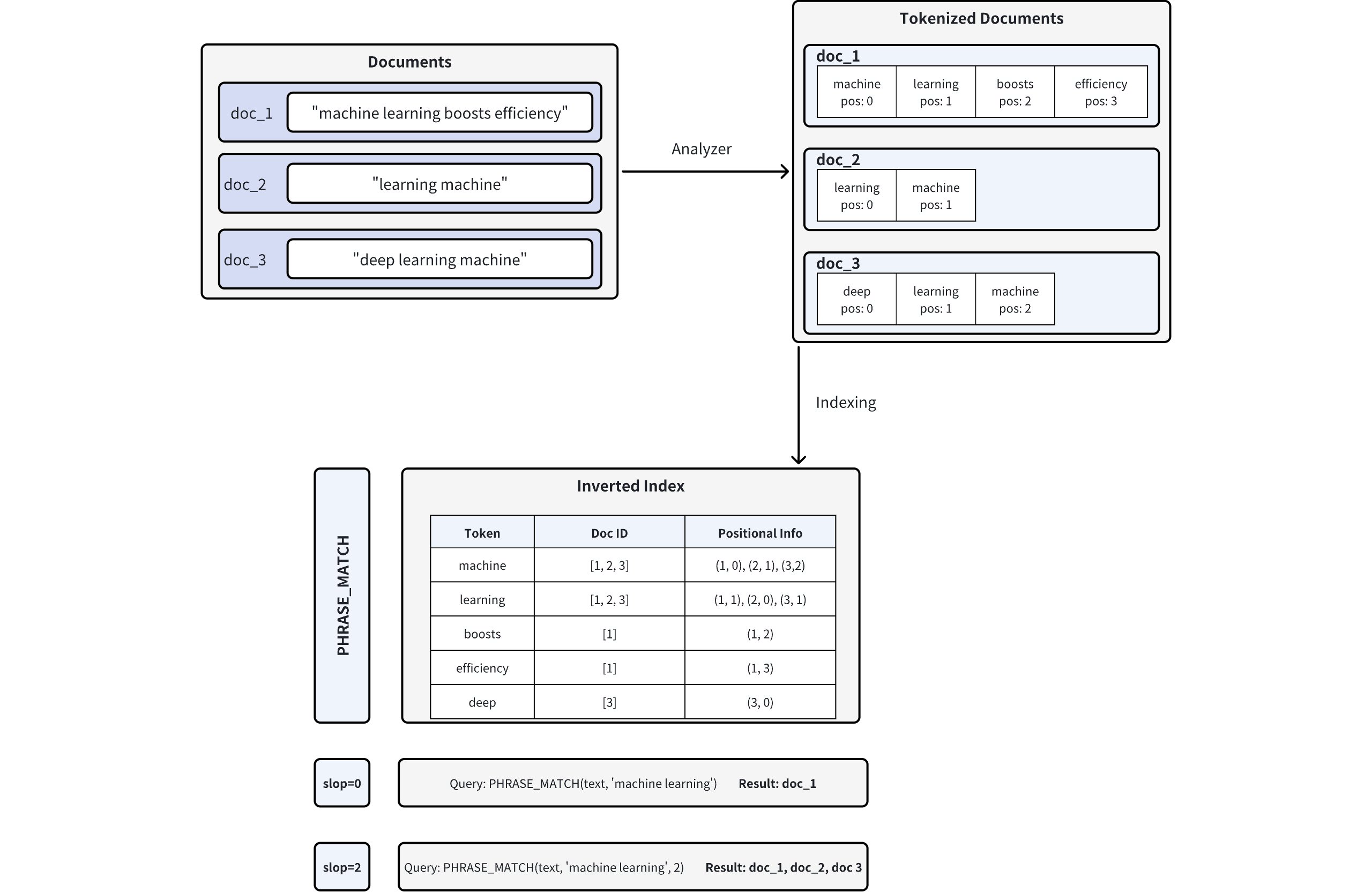
短语匹配工作流程
-
文档标记化 :将文档插入 Milvus 时,使用分析器将文本分割成标记(单个词或术语),并记录每个标记的位置信息。例如,doc_1 被标记为**"machine" (pos=0), "learning" (pos=1), "boosts" (pos=2), "efficiency" (pos=3)** 。有关分析器的更多信息,请参阅分析器概述。
-
反向索引创建:Milvus 建立一个倒排索引,将每个标记映射到出现该标记的文档以及标记在这些文档中的位置。
-
短语匹配 :当执行短语查询时,Milvus 会查找倒排索引中的每个标记,并检查它们的位置,以确定它们是否以正确的顺序和相邻关系出现。
slop参数控制匹配标记之间允许的最大位置数:-
slop = 0 表示词组必须以完全相同的顺序 出现**,并且紧邻**(即中间没有多余的字)。
- 在本例中,只有doc_1 ("machine " 在位置 0 ,"learning " 在位置 1)完全匹配。
-
slop = 2允许匹配词之间最多有两个位置的灵活性或重新排列。
-
这就允许颠倒顺序(**"学习机器")**或在词组之间留出小间隙。
-
因此,doc_ 1 、doc_2 ("learning " 在位置=0 ,"machine " 在位置=1 )和doc_3 ("learning " 在位置=1 ,"machine " 在位置=2)全部匹配。
-
-
13.2.启用短语匹配
短语匹配适用于VARCHAR 字段类型,即 Milvus 中的字符串数据类型。要启用短语匹配,请配置您的 Collections Schema,将enable_analyzer 和enable_match 参数都设置为True ,类似于文本匹配。
设置enable_analyzer 和enable_match
要启用特定VARCHAR 字段的短语匹配,请在定义字段 Schema 时将enable_analyzer 和enable_match 参数设置为True 。该配置指示 Milvus 对文本进行标记化,并创建一个具有位置信息的反向索引,以实现高效的短语匹配。
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text', # Name of the field
datatype=DataType.VARCHAR, # Field data type set as VARCHAR (string)
max_length=1000, # Maximum length of the string
enable_analyzer=True, # Enables text analysis (tokenization)
enable_match=True # Enables inverted indexing for phrase matching
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)可选:配置分析器
短语匹配的准确性在很大程度上取决于用于标记文本数据的分析器。不同的分析器适用于不同的语言和文本格式,会影响标记化和定位的准确性。根据具体使用情况选择合适的分析器,可以优化短语匹配结果。
默认情况下,Milvus 使用标准分析器,根据空白和标点符号对文本进行标记化,删除长度超过 40 个字符的标记,并将文本转换为小写。默认用法不需要额外参数。详情请参阅标准分析器。
如果您的应用程序需要特定的分析器,请使用analyzer_params 参数进行配置。例如,以下是如何配置english 分析器,用于英文文本中的短语匹配:
python
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text', # Name of the field
datatype=DataType.VARCHAR, # Field data type set as VARCHAR
max_length=1000, # Maximum length of the string
enable_analyzer=True, # Enables text analysis
analyzer_params=analyzer_params, # Specifies the analyzer configuration
enable_match=True # Enables inverted indexing for phrase matching
)Milvus 支持针对不同语言和用例定制的多种分析器。有关详细信息,请参阅分析器概述。
13.3.使用短语匹配
为 Collections Schema 中的VARCHAR 字段启用匹配后,就可以使用PHRASE_MATCH 表达式执行短语匹配。
PHRASE_MATCH 表达式不区分大小写。可以使用PHRASE_MATCH 或phrase_match 。
搜索时,使用PHRASE_MATCH 表达式指定字段、短语和可选的灵活性 (slop)。语法如下
python
PHRASE_MATCH(field_name, phrase, slop)-
field_name: 执行短语匹配的VARCHAR字段名称。 -
phrase**:**要搜索的确切短语。 -
slop(可选)**:**一个整数,指定匹配标记中允许的最大位置数。-
0(默认):只匹配精确短语。例如机器学习 " 过滤器将精确匹配**"** machine learning" ,但不匹配**"machine boosts learning "** 或**"learning machine"。** -
1:允许细微变化,例如多一个词或位置上的细微变化。例如机器学习 " 过滤器将匹配**"machine boosts learning"** ("machine " 和**"learning "** 之间有一个标记**)** ,但不匹配**"learning machine"**(术语颠倒)。 -
2:允许更多的灵活性,包括术语顺序颠倒或最多在两个词组之间。例如机器学习 " 过滤器将匹配**"学习机器"** (词序颠倒)或**"机器快速促进学习"** ("机器 " 和**"学习 "** 之间有两个词组**)**。
-
数据集示例
假设您有一个名为tech_articles 的Collections,其中包含以下五个实体:
doc_id |
text |
|---|---|
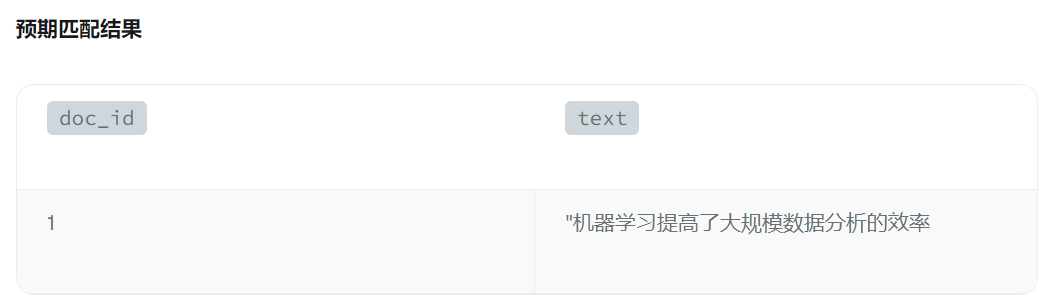
| 1 | "机器学习提高了大规模数据分析的效率 |
| 2 | "学习基于机器的方法对现代人工智能的发展至关重要" 3 |
| 3 | "深度学习机器架构优化了计算负荷" |
| 4 | "机器迅速提高持续学习的模型性能" |
| 5 | "学习先进的机器算法,扩展人工智能能力 |
13.4.短语匹配查询
使用query() 方法时,PHRASE_MATCH 充当标量过滤器。只有包含指定短语的文档才会返回(取决于允许的斜率)。
示例:slop = 0(精确匹配)
此示例返回包含精确短语**"machine learning "**的文档,中间不包含任何额外标记。
python
filter = "PHRASE_MATCH(text, 'machine learning')"
result = client.query(
collection_name="tech_articles",
filter=filter,
output_fields=["id", "text"]
)
使用短语匹配进行搜索
在搜索操作中,PHRASE_MATCH用于在应用向量相似性排序之前过滤文档。这种两步法首先通过文本匹配缩小候选集的范围,然后根据向量嵌入重新对这些候选集进行排序。
示例:斜率 = 1
这里,我们允许斜率为 1。该过滤器适用于包含**"学习机 "**短语的文档,并略有灵活性。
python
filter_slop1 = "PHRASE_MATCH(text, 'learning machine', 1)"
result_slop1 = client.search(
collection_name="tech_articles",
anns_field="embeddings",
data=[query_vector],
filter=filter_slop1,
search_params={"params": {"nprobe": 10}},
limit=10,
output_fields=["id", "text"]
)
-
为字段启用短语匹配会触发倒排索引的创建,从而消耗存储资源。在决定是否启用此功能时,请考虑对存储的影响,因为它根据文本大小、唯一标记和所使用的分析器而有所不同。
-
在 Schema 中定义分析器后,其设置将永久适用于该 Collections。如果您认为不同的分析器更适合您的需要,可以考虑删除现有的 Collections,然后使用所需的分析器配置创建一个新的 Collections。
-
短语匹配性能取决于文本标记化的方式。在将分析器应用到整个 Collections 之前,请使用
run_analyzer方法查看标记化输出。有关详细信息,请参阅分析器概述。 -
filter表达式中的转义规则:-
表达式中用双引号或单引号括起来的字符被解释为字符串常量。如果字符串常量包含转义字符,则必须使用转义序列来表示转义字符。例如,用
\\表示\,用\\t表示制表符\t,用\\n表示换行符。 -
如果字符串常量由单引号括起来,常量内的单引号应表示为
\\',而双引号可表示为"或\\"。 示例:'It\\'s milvus'。 -
如果字符串常量由双引号括起来,常量中的双引号应表示为
\\",而单引号可表示为'或\\'。 示例:"He said \\"Hi\\""。
-