第十一章 数据库恢复技术
11.1 数据库恢复概述
1. 数据库恢复的必要性
- 数据库恢复技术是衡量系统优劣的重要指标,其核心目标是应对各类故障,防止数据丢失或系统瘫痪。
典型故障案例分析:
- 物理灾难 ("911"事件):
- 场景: 极其严重的意外事故,导致物理设施损毁。
- 后果: 没有异地备份的公司数据彻底丢失,导致公司倒闭;拥有异地灾备(如两地三中心)的公司在数小时内恢复服务。
- 启示: 物理备份和容灾机制是底线。
- 运维误操作 (携程网 & 顺丰):
- 携程事件 (2015): 员工错误删除生产服务器执行代码,导致官网和APP瘫痪约12小时。
- 顺丰事件 (2018): 高级工程师在进行运维时选错数据库实例,且忽略弹窗提醒,直接删除了生产数据库,导致OMCS运营监控系统瘫痪约10小时。
- 启示: 人为误操作(逻辑错误)是常见故障源,权限管理和操作规范至关重要。
- 恶意破坏 (微盟删库事件):
- 场景: 运维人员恶意使用Linux文件删除命令,不可逆地删除了自建MySQL数据库的核心业务数据。
- 后果: 业务瘫痪7天7夜,市值缩水30亿,赔付1.5亿。
- 反思: 暴露了数据安全评估不足、缺乏权限分级、缺乏冷备及全量备份等多重管理漏洞。
2. 事务执行的底层机制
基本组件:
- 数据库组织: 数据存储在表空间中,进一步细分为段、区和数据块。
- 缓冲区: 内存中的区域,用于临时存储从磁盘读取的数据页。
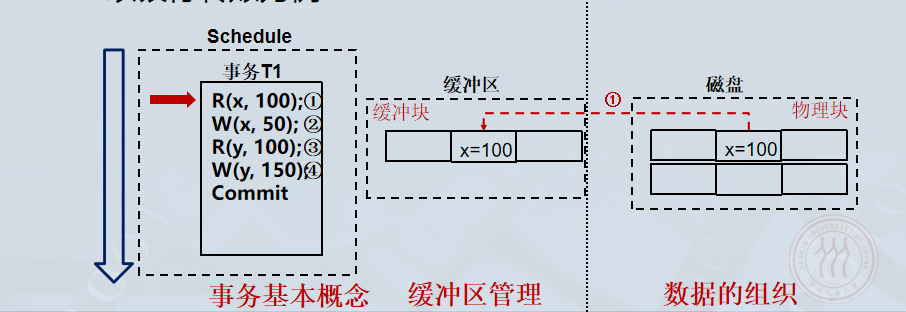
事务读写流程 (以银行转账 x→yx \to yx→y 为例):
-
Read(x): 将数据块 xxx 从磁盘读入缓冲区。
-
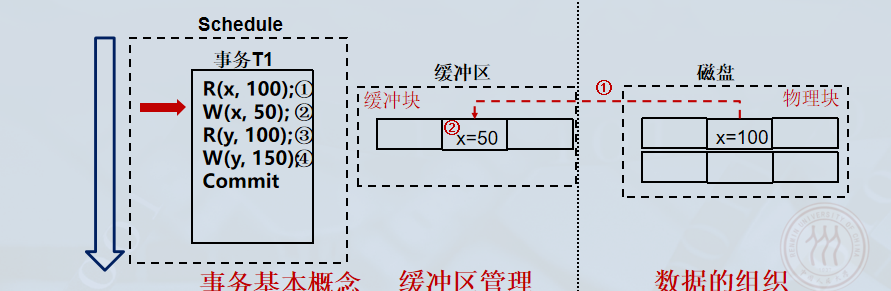
Write(x): 在缓冲区中修改 xxx 的值(例如 100→50100 \to 50100→50),此时缓冲区中的页变为脏页 (Dirty Page) ,但磁盘上仍是旧值。
-
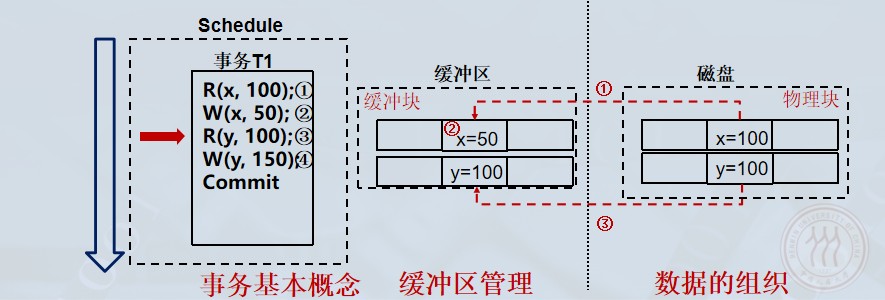
Read(y): 将数据块 yyy 从磁盘读入缓冲区。
-
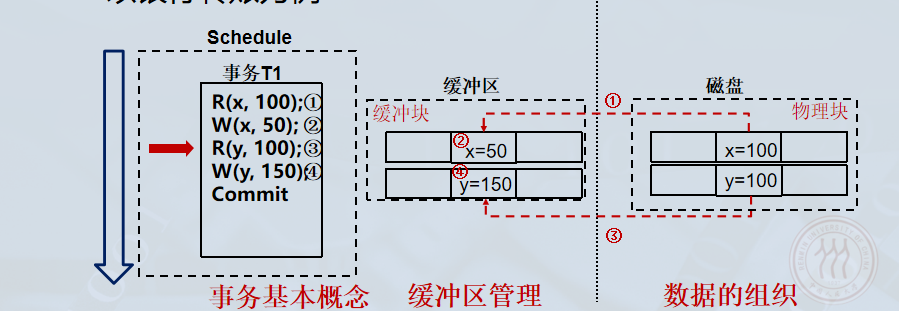
Write(y): 在缓冲区中修改 yyy 的值(例如 100→150100 \to 150100→150),变为脏页。
-
Commit: 事务提交。
3. 数据库恢复的三大核心事实
-
事实 1:事务提交时,脏页不强制刷盘;
-
事实 2:事务运行过程中,脏页有可能被刷盘;
-
事实3:系统提供其他机制,确保事务提交后不会因为故障等原因导致修改的数据项丢失;
4. 数据库恢复技术的定义与分类
-
数据库恢复技术是指数据库管理系统(DBMS)必须具备的,将数据库从错误状态 恢复到某一已知的正确状态(一致状态/完整状态)的功能。
-
故障是不可避免的,主要包括:
- 计算机硬件故障: 磁盘损坏、断电等。
- 软件错误: DBMS自身bug、操作系统崩溃。
- 操作员失误: 误删数据、配置错误。
- 恶意破坏: 黑客攻击、内部人员破坏。
-
故障的影响
-
事务中断: 运行中的事务非正常中断,破坏数据正确性。
-
数据丢失: 全部或部分数据丢失。
-
11.2 故障的种类
1. 事务内部的故障
- 可预期的事务故障(由应用程序处理):
- 定义: 即使是正常的业务逻辑,也可能因为特定条件(如余额不足)导致事务无法完成。
- 处理方式: 这类故障通常由事务程序本身发现并处理。应用程序会显式地调用
ROLLBACK语句,撤销已做的修改,将数据库恢复到正确状态。 - 示例: 银行转账中,如果账户 xxx 余额不足(
BALANCE < 0),程序打印提示并执行ROLLBACK。
- 非预期的事务故障(真正的"事务故障"):
- 定义: 这是一个不能由应用程序处理的意外事件,导致事务没有达到预期的终点(
COMMIT或显式的ROLLBACK)。 - 常见原因:
- 运算溢出。
- 并发事务发生死锁,系统选中该事务进行撤销。
- 违反了完整性限制(如唯一性约束)而被终止。
- 后果: 数据库可能处于不正确的状态。
- 恢复策略:事务撤消 (UNDO)
- 强行回滚(
ROLLBACK)该事务。 - 撤销该事务已经作出的任何修改,使其像根本没有启动一样。
- 强行回滚(
- 定义: 这是一个不能由应用程序处理的意外事件,导致事务没有达到预期的终点(
2. 系统故障
-
系统故障又称为软故障,是指造成系统停止运转,必须重新启动的事件。
-
常见原因:
- 特定类型的硬件错误(如CPU故障)。
- 操作系统故障。
- 数据库管理系统(DBMS)代码错误。
- 系统断电。
-
故障影响:
- 系统的正常运行被突然破坏;
- 所有正在运行的事务非正常终止 ;
- 内存(缓冲区)中的信息全部丢失;
- 关键点: 这种故障不破坏数据库(磁盘上的数据依然存在)。
-
系统重启时,恢复子系统必须执行以下两项操作:
- 撤销 (UNDO) 未完成的事务:
- 故障发生时,某些活跃事务只运行了一部分,但其修改可能已经写入了物理数据库。
- 强行撤消所有未完成事务,回滚其修改。
- 重做 (REDO) 已提交的事务:
- 故障发生时,某些已提交的事务,其更新的数据还在缓冲区中,还没来得及刷写到磁盘,导致更新丢失。
- 重做所有已提交的事务,确保数据持久化。
- 撤销 (UNDO) 未完成的事务:
3. 介质故障
-
介质故障又称为硬故障,指的是外存(磁盘)的物理故障。
-
常见原因:
- 磁盘损坏;
- 磁头碰撞;
- 瞬时强磁场干扰。
-
故障影响:
- 破坏整个数据库或部分数据库;
- 影响正在存取这部分数据的所有事务。
-
特点: 发生的可能性比前两类小得多,但破坏性大得多。
4. 计算机病毒
- 一种人为的故障或破坏,通过恶作剧者研制的程序进行繁殖和传播。
- 已成为计算机系统和数据库系统的主要威胁。
- 一旦被破坏,仍需使用数据库恢复技术进行恢复。
11.3 恢复的实现技术
- 核心思想:建立冗余数据 。利用存储在系统别处的冗余数据来修复被破坏的数据库。
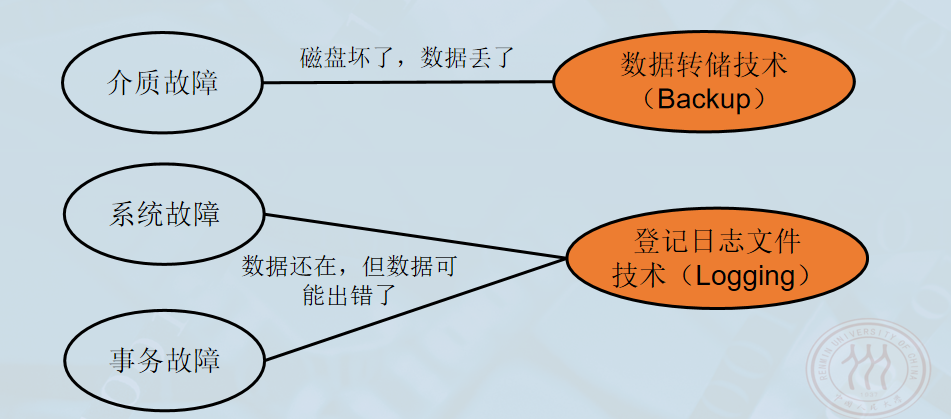
1.数据转储
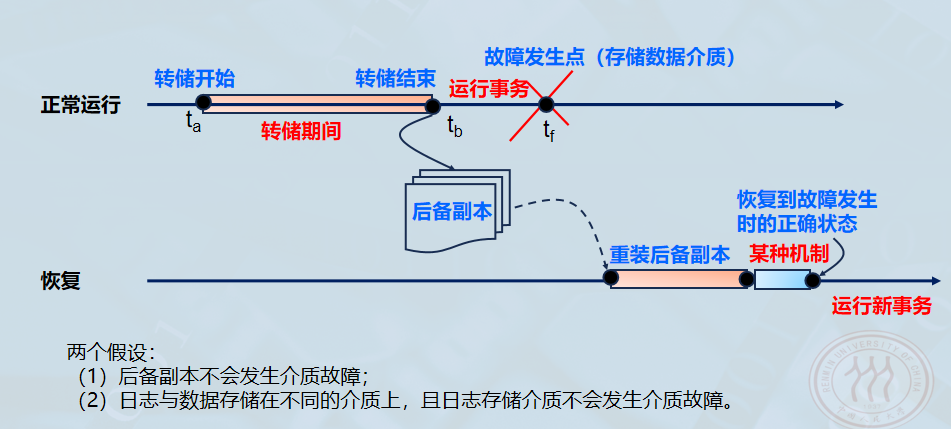
-
定义 :数据库管理员(DBA)定期将整个数据库复制到磁带、磁盘或其他存储介质上保存起来的过程。这些备用数据称为后备副本或后援副本。
-
主要用于介质故障(如磁盘损坏)的恢复。
恢复机制
- 发生介质故障时,重装后备副本。
- 重装后只能将数据库恢复到转储时的状态(该状态不一定是最新的,甚至在动态转储下不一致)。
- 要恢复到故障发生时的正确状态,必须结合日志文件,重新运行自转储以后的所有更新事务。
转储方法分类
转储方法主要从转储状态 (是否允许事务运行)和转储量(全量还是增量)两个维度进行分类。
(1) 按转储状态分类
- 静态转储
- 定义 :在系统中无运行事务时进行的转储操作。
- 特点 :
- 转储期间不允许对数据库进行任何存取、修改活动。
- 得到的一定是一个数据一致性的副本。
- 优缺点 :
- 优点:实现简单。
- 缺点:降低了数据库的可用性(转储时必须等待正在运行的事务结束,新事务必须等待转储结束)。
- 动态转储
-
定义 :转储操作与用户事务并发进行。
-
特点:
- 转储期间允许对数据库进行存取或修改。
- 注意 :转储结束时,后备副本中的数据可能不一致(无效)。
-
数据不一致示例
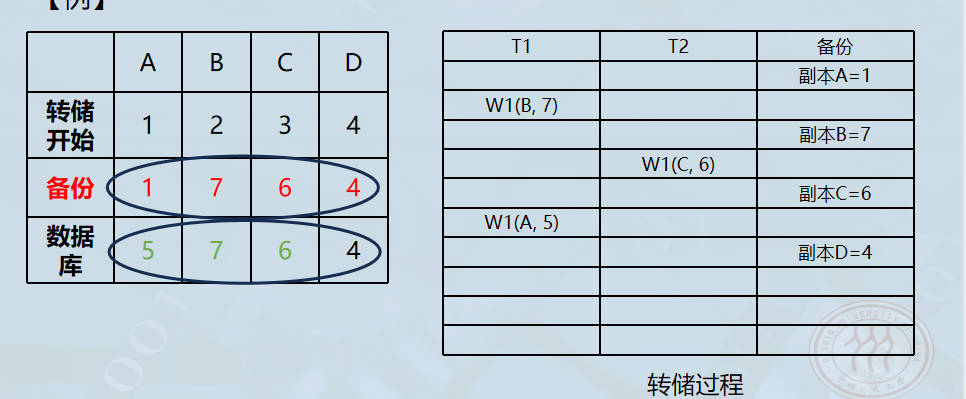
- 动态转储允许在备份操作进行的同时,用户事务(T1, T2)继续对数据库进行读写。这就导致了"读"和"写"的时间差问题:
- 备份A: 转储程序首先读取了 A=1。
- 修改B: 事务 T1 将 B 修改为 7。
- 备份B: 转储程序随后读取了 B=7(读到了新值)。
- 修改C: 事务 T2 将 C 修改为 6。
- 备份C: 转储程序读取了 C=6(读到了新值)。
- 再次修改A: 关键点在这里,事务 T1 回过头来将 A 修改为了 5。
- 备份结束: 此时转储程序已经存好了 A=1,它不会回头去更新 A 的值。
- 动态转储允许在备份操作进行的同时,用户事务(T1, T2)继续对数据库进行读写。这就导致了"读"和"写"的时间差问题:
-
恢复要求 :必须建立日志文件。
- 需要把动态转储期间各事务对数据库的修改活动登记下来。
- 后备副本 + 日志文件 = 某一时刻的正确状态。
-
(2) 按转储量分类
- **海量转储 **
- 每次转储全部数据库。
- 适用:恢复方便,但转储时间长。
- 增量转储
- 只转储上次转储后更新过的数据。
- 适用:如果数据库很大且事务频繁,增量转储更有效。
(3) 方法小结
- 通常配合使用,如:动态海量转储 、静态增量转储等。DBA需根据数据库使用情况确定转储周期。
2. 登记日志文件
-
日志文件 是用来记录事务对数据库更新操作的文件。
-
日志文件主要有两种格式:
-
以记录为单位的日志文件
-
内容:
-
事务开始标记 (
BEGIN TRANSACTION);sqlT1 BEGIN TRANSACTION -
事务结束标记 (
COMMIT或ROLLBACK); -
所有更新操作。
-
-
更新操作记录包含:
- 事务标识(标明是哪个事务);
- 操作类型(插入、删除、修改);
- 操作对象(记录ID、Block NO.);
- 更新前数据的旧值 ,用于
UNDO,对插入操作 而言此项为NULL; - 更新后数据的新值 ,用于
REDO,对删除操作 而言此项为NULL。
SQLT1 U AA 18 20 /*事务 T1 执行了 更新(Update) 操作,把 AA 的值从 18 改为 20 */ T1 I TU 1 /*事务 T1 执行了 插入(Insert) 操作,新插入的数据对象名为 "TU",值为 1 */ T1 D TV 20 /*事务 T1 执行了 删除(Delete) 操作,被删除的数据对象是 "TV",值为 20 */ -
-
以数据块为单位的日志文件
- 内容:事务标识 + 被更新的数据块。
3. 日志文件的作用
-
进行事务故障恢复。
-
进行系统故障恢复。
-
协助后备副本进行介质故障恢复。
-
静态转储 :也可以建立日志文件,利用日志重做已完成事务,撤销未完成事务,避免重新运行已完成的事务程序。
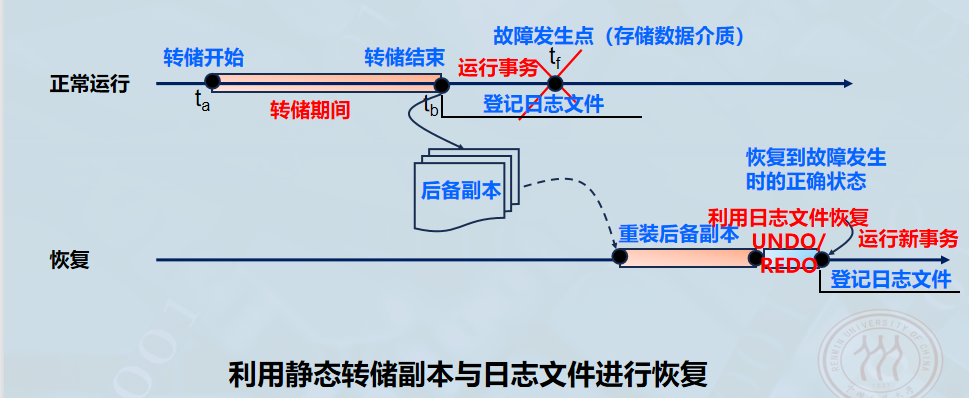
-
动态转储 :必须建立日志文件,否则无法恢复。
4. 登记日志文件的原则
-
为保证数据库是可恢复的,必须遵循两条原则:
- 登记的次序严格按并发事务执行的时间次序。
- 先写日志文件,后写数据库。
-
为什么要先写日志?
-
写数据库和写日志是两个不同的操作,中间可能发生故障。
-
情况A(先写数据库):如果先修改了数据库,但在写日志前发生了故障 → 无法恢复(因为不知道谁修改了数据,无法撤销)。
-
情况B(先写日志):如果先写了日志,但在修改数据库前发生了故障 → 恢复时只会多执行一次不必要的UNDO操作,不影响正确性。
-
11.4 恢复策略
-
恢复目标 :把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)。
-
事务故障 :撤销 (UNDO) 出故障的事务。
-
系统故障 :撤销 (UNDO) 尚未提交的事务,重做 (REDO) 已经提交的事务。
-
介质故障 :重载备份 ,重做 (REDO) 已经提交的事务。
1.事务故障的恢复
-
事务故障:事务在运行至正常终止点前被终止(例如:运算溢出、死锁被选中撤销、违反完整性约束等)。
-
故障导致数据库不一致原因 :未完成事务对数据库的更新可能已经写入数据库。
-
恢复策略
-
由恢复子系统利用日志文件撤消(UNDO)此事务已对数据库进行的修改。
-
特点 :由系统自动完成 ,对用户是透明的,不需要用户干预。
-
-
恢复步骤 (反向扫描,执行逆操作)
-
反向扫描日志文件(从最后向前扫描),查找该事务的更新操作。
-
执行逆操作:对该事务的更新操作执行逆操作(即将日志记录中"更新前的值"写入数据库)。
-
如果是插入操作 → 相当于做删除。
-
如果是删除操作 → 相当于做插入。
-
如果是修改操作 → 用旧值代替新值。
-
-
循环处理:继续反向扫描,查找该事务的其他更新操作并执行逆操作。
-
结束条件 :直至读到此事务的开始标记 (
BEGIN TRANSACTION),恢复完成。
-
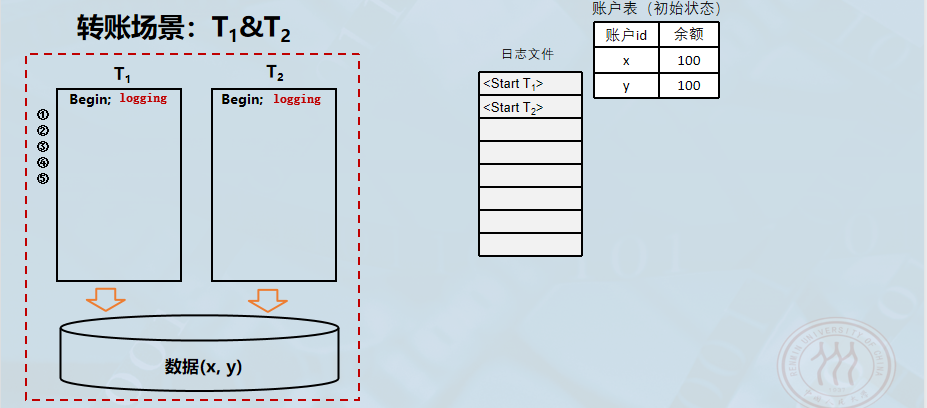
事务故障恢复举例
-
初始状态与正常执行阶段。首先,系统处于正常运行状态,记录了事务的操作过程。
- 初始数据: 账户表中有两个账户,x=100,y=100。
- 事务开始: 日志文件记录了
<Start T1>和<Start T2>,表示两个事务已经启动。 - 数据修改(写操作):
- 步骤 3 (T1T_1T1): 事务 T1T_1T1 将账户 x 的余额从 100 修改为 50。系统在日志中写入记录
<T1 x 100 50>(格式为:事务ID 对象 旧值 新值)。此时数据库进入状态 1 (x=50, y=100)。 - 步骤 4 (T2T_2T2): 事务 T2T_2T2 将账户 y 的余额从 100 修改为 50。日志写入
<T2 y 100 50>。此时数据库进入状态 2 (x=50, y=50)。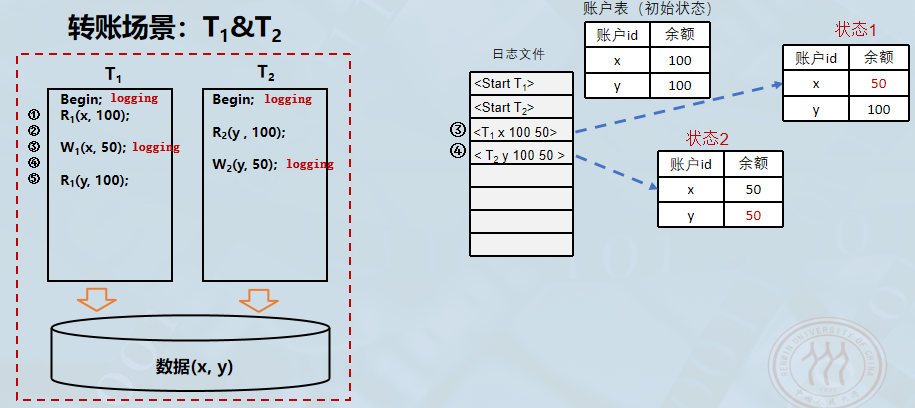
- 步骤 3 (T1T_1T1): 事务 T1T_1T1 将账户 x 的余额从 100 修改为 50。系统在日志中写入记录
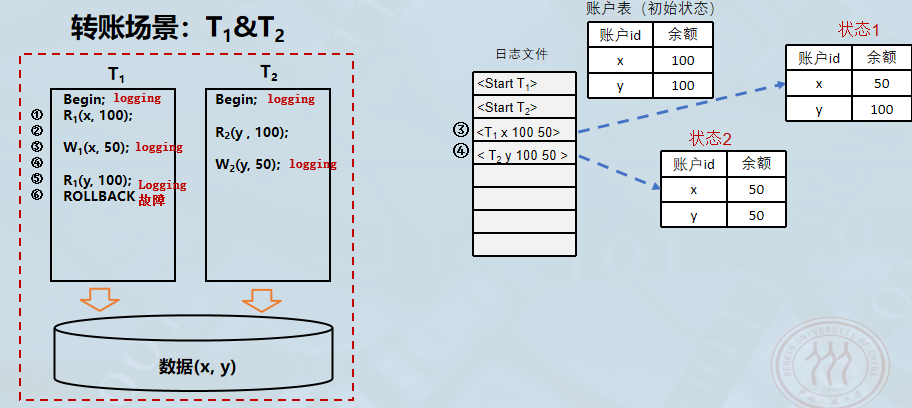
-
事务 T1T_1T1 在执行过程中遇到了问题,执行了 ROLLBACK (回滚)指令。这表示 T1T_1T1 是一个失败的事务,必须撤销它对数据库所做的所有修改,以保证数据的一致性。
-
恢复策略:反向扫描 。系统检测到 T1T_1T1 需要回滚,开始执行恢复算法:
- 反向扫描日志文件 :从最后一条记录开始往前查找该事务(T1T_1T1)的更新操作。
- 定位修改记录 :系统在日志中找到了 T1T_1T1 的更新记录
<T1 x 100 50>。
-
为了确保恢复操作本身也被记录(防止在恢复过程中再次崩溃导致混乱),系统会写入一条新的日志记录。补偿日志
<T1 x 50 100>被写入到日志文件中,这条记录表示:针对 T1T_1T1 修改 x 的操作,系统已经执行了将 x 从 50 改回 100 的操作。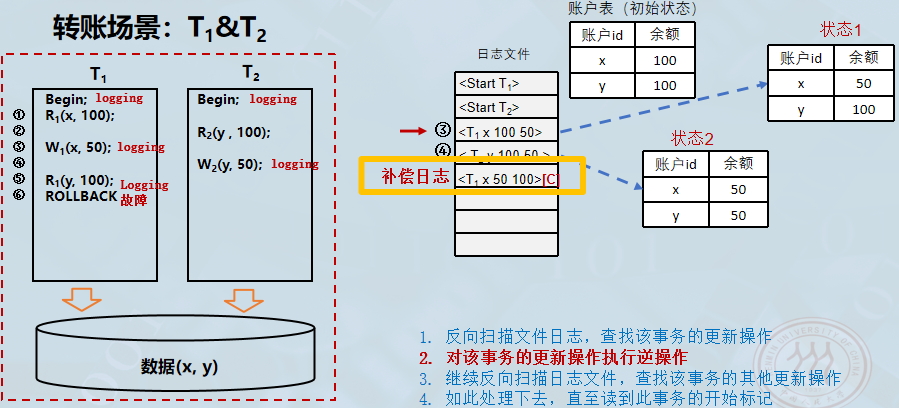
-
为了消除 T1T_1T1 的影响,系统执行逆操作。
- 根据日志记录
<T1 x 100 50>中的旧值(Old Value = 100),系统将 x 的值重新写回 100。 - 红色的 状态 3 表格显示 x 的值已经恢复为 100,而 y 保持 50(因为 T2T_2T2 未回滚)。这表示数据库已经回到了 T1T_1T1 执行前的正确状态。
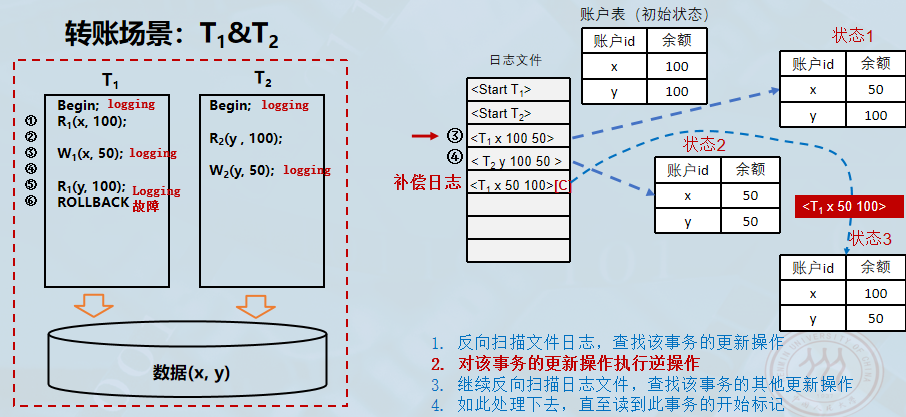
- 根据日志记录
-
继续反向扫描日志文件,查找该事务的其他更新操作,发现T1T_1T1没有更多更新操作。
-
在成功将 xxx 的值从 50 恢复回 100 并写入补偿日志后,系统需要在日志文件中正式标记事务 T1T_1T1 的回滚过程已完全结束。于是系统写入一条
<ABORT T1>记录,这条记录表明 T1T_1T1 的故障恢复处理已完成,数据库关于 T1T_1T1 的部分已经恢复到一致状态。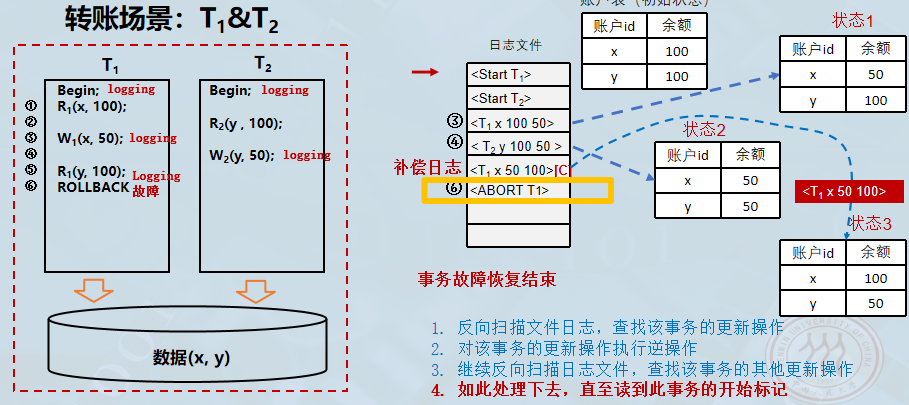
-
在 T1T_1T1 回滚结束后,事务 T2T_2T2 继续执行其剩余的操作。
- 读取数据: T2T_2T2 读取账户 xxx 的余额。
- 关键点: 此时读取到的 xxx 是 100 。这是因为 T1T_1T1 刚刚已经通过回滚操作将 xxx 恢复为初始值了。如果没有之前的恢复步骤,T2T_2T2 可能会读取到错误的脏数据(50)。
- 修改数据: T2T_2T2 将 xxx 的值修改为 150(假设是存入50)。
- 日志记录: 系统写入日志
<T2 x 100 150>,记录这次更新操作:事务 T2T_2T2 将 xxx 从旧值 100 修改为新值 150。 - T2T_2T2 完成了所有操作,发起提交指令,系统写入日志
<COMMIT T2>,这标志着 T2T_2T2 成功结束,其对数据库的所有修改(y=50y=50y=50 和 x=150x=150x=150)被确认为永久有效。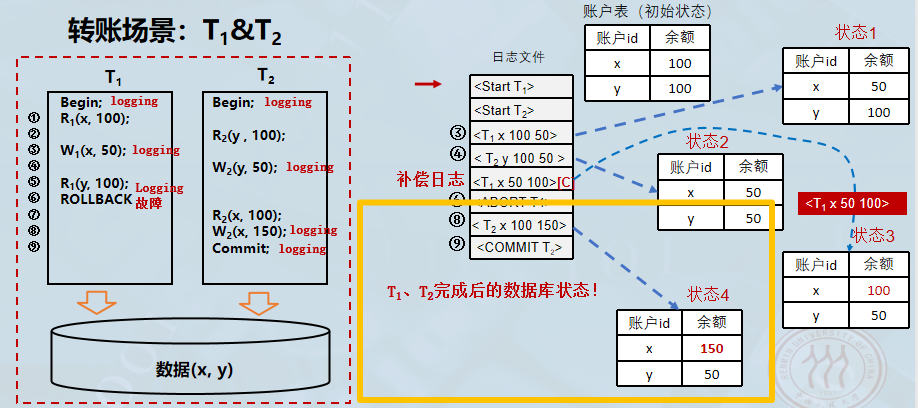
- 读取数据: T2T_2T2 读取账户 xxx 的余额。
-
经过上述所有步骤,数据库达到了最终的 状态 4:
- 账户 x: 最终值为 150 (由 T2T_2T2 最后一次修改决定)。
- 账户 y: 最终值为 50 (由 T2T_2T2 早期修改决定)。
-
2.系统故障的恢复
-
系统故障:系统停止运转(如CPU故障、断电、操作系统崩溃),内存数据丢失,但磁盘数据未受损。
-
系统故障造成数据库不一致的原因
-
未完成事务 对数据库的更新可能已写入数据库(需要 UNDO)。
-
已提交事务 对数据库的更新可能还留在缓冲区,没来得及写入数据库(需要 REDO)。
-
-
恢复策略
-
UNDO 故障发生时未完成的事务。
-
REDO 已完成的事务。
-
-
特点 :由系统在重新启动时自动完成,不需要用户干预。
-
恢复步骤 (先分析,后撤销,再重做)
-
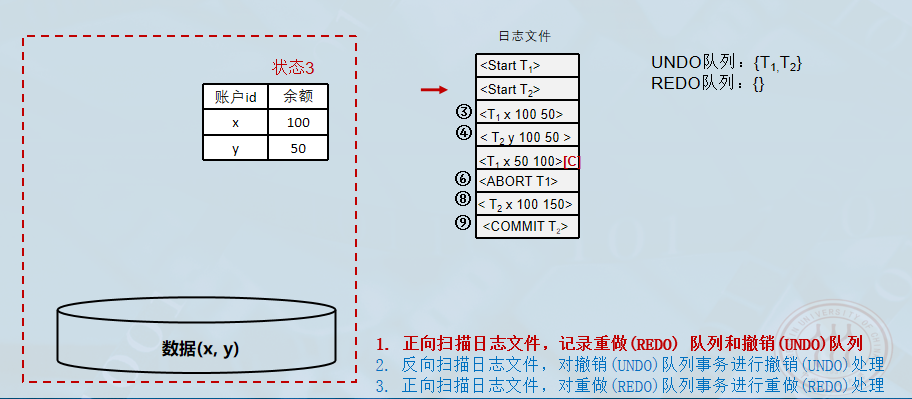
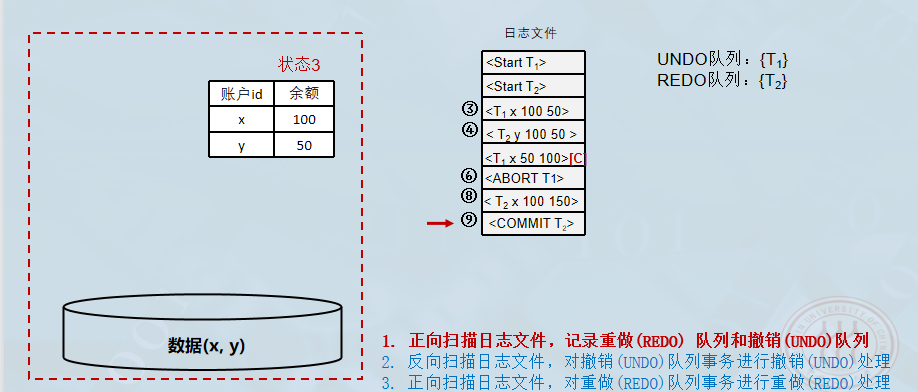
正向扫描日志文件(分析阶段):
- 找出故障发生前已经提交的事务 → 加入 重做 (REDO) 队列 。(有
BEGIN也有COMMIT) - 找出故障发生时尚未完成的事务 → 加入 撤销 (UNDO) 队列 。(只有
BEGIN无COMMIT)
- 找出故障发生前已经提交的事务 → 加入 重做 (REDO) 队列 。(有
-
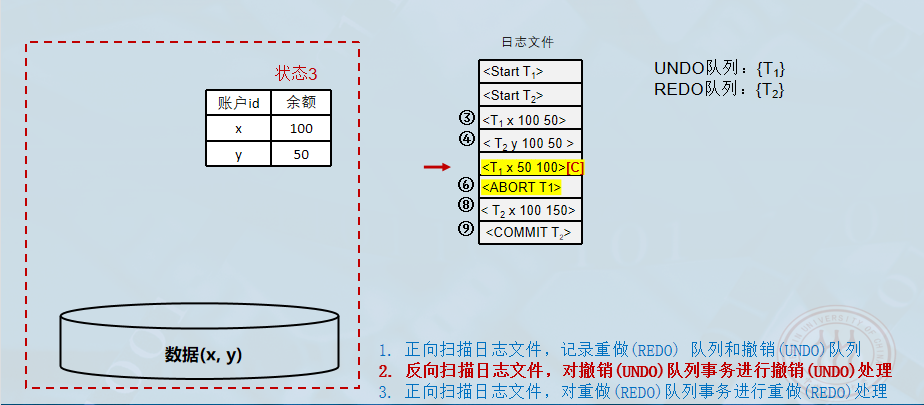
对 UNDO 队列事务进行撤销处理:
- 反向扫描 日志文件,对每个撤销事务的更新操作执行逆操作(写入"更新前的值")。
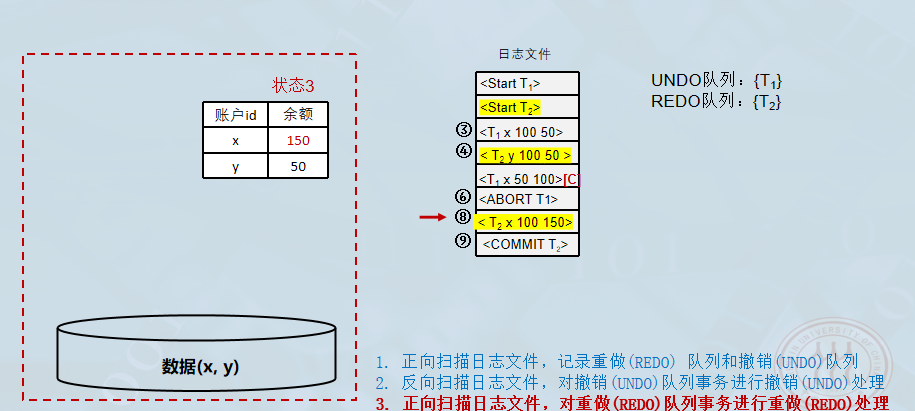
3.对 REDO 队列事务进行重做处理:
- 正向扫描日志文件,对每个重做事务重新执行登记的操作(写入"更新后的值")。
-
-
系统故障恢复举例
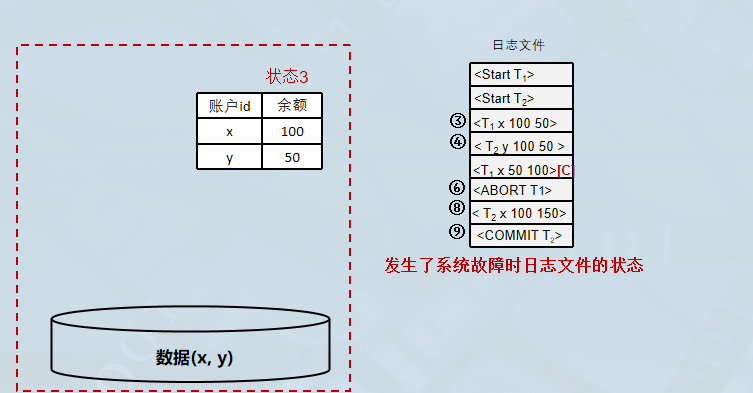
3.介质故障的恢复
-
介质故障:硬件故障(如磁盘损坏、磁头碰撞),导致数据库文件或日志文件丢失。
-
介质故障造成数据不一致的原因:数据库中的数据物理丢失。虽然可能有后备副本和日志副本,但后备副本可能数据不一致(动态转储)或不是最新的。
-
恢复策略
-
重装数据库使其恢复到正确的状态。
-
REDO 已完成的事务。
-
特点 :需要数据库管理员 (DBA) 介入,执行恢复命令。
-
-
恢复步骤 (重装副本 + 追日志)
- 装入最新的后备数据库副本 :
- 使数据库恢复到最近一次转储时的一致性状态。
- 注意 :如果是动态转储的副本,装入后还必须利用转储期间的日志文件进行恢复(UNDO+REDO),才能达到一致性状态。
- 装入有关的日志文件副本 :
- 装入转储结束时刻以后的日志文件。
- 重做已完成的事务 :
- 首先扫描日志文件,找出故障发生时已提交的事务,记入重做队列。
- 正向扫描 日志文件,对重做队列中的所有事务进行重做处理(写入"更新后的值")。
4.恢复策略总结表
| 故障类型 | 故障特征 | 恢复操作 | 执行者 |
|---|---|---|---|
| 事务故障 | 逻辑错误,事务非正常终止 | UNDO (撤销该事务) | 系统自动 |
| 系统故障 | 内存丢失,磁盘完好 | UNDO (未完成事务) + REDO (已提交事务) | 系统重启时自动 |
| 介质故障 | 磁盘损坏,数据丢失 | 重装副本 + REDO (已提交事务) | DBA 介入 |
11.5 具有检查点的恢复技术
1. 问题的提出
- 传统系统故障恢复策略的弊端:在没有检查点的情况下,系统故障恢复需要:
- 正向扫描整个日志文件,区分UNDO和REDO队列。
- 反向扫描UNDO队列进行撤销。
- 正向扫描REDO队列进行重做。
-
存在的问题
-
搜索时间长:日志文件通常很大,搜索整个日志将耗费大量时间。
-
重复执行浪费资源:很多已提交事务的更新其实已经写入了数据库磁盘,重新执行这些已完成的事务(REDO)浪费了大量时间。
-
-
解决方案:引入**检查点(Checkpoint)**技术。
-
在日志文件中增加检查点记录。
-
增加重新开始文件。
-
恢复子系统动态维护日志。
-
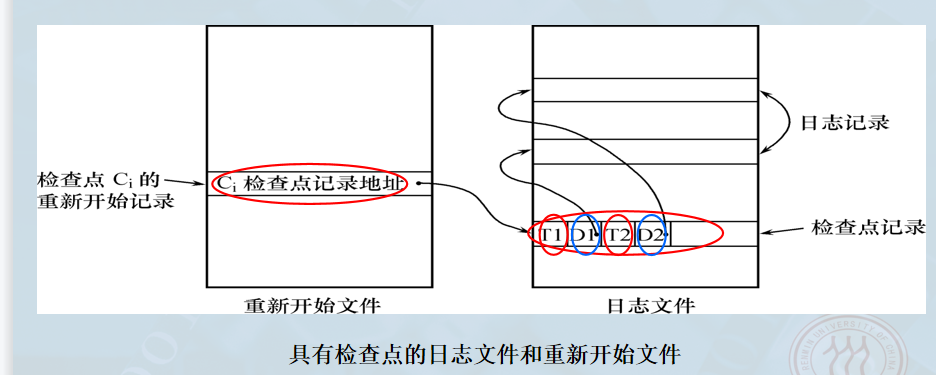
2. 检查点技术详解
-
检查点记录的内容
-
建立检查点时刻,所有正在执行的事务清单。
-
这些事务最近一个日志记录的地址。
-
-
重新开始文件
-
内容 :记录各个检查点记录在日志文件中的地址。
-
作用 :故障恢复时,通过读取重新开始文件,可以快速定位到日志文件中的最后一个检查点。
-
-
动态维护日志的方法 :恢复子系统周期性地执行以下4个步骤,建立检查点,保存数据库状态:
-
将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上。
-
在日志文件中写入一个检查点记录。
-
将当前数据缓冲区的所有数据记录写入磁盘的数据库中。
-
把检查点记录在日志文件中的地址写入重新开始文件。
-
-
建立检查点的时机
-
定期:按照预定的时间间隔(如每隔1小时)。
-
不定期:按照某种规则(如日志文件已写满一半时)。
-
3. 利用检查点的恢复策略
-
使用检查点可以显著改善恢复效率:
-
T1 (检查点前已提交) :如果事务 TTT 在检查点之前提交,说明其修改已写入 数据库(步骤3保证),恢复时无需REDO。
-
T2/T3 (检查点时未完成) :如果事务 TTT 在检查点时还未完成,虽然其部分修改可能已写入,但恢复时需要根据最终状态决定UNDO或REDO。
-
-
事务状态分类与处理
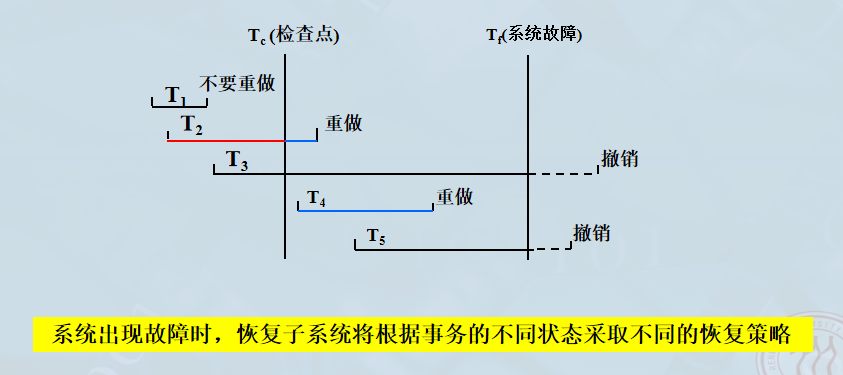
假设 TcT_cTc 为检查点时刻,TfT_fTf 为系统故障时刻:
| 事务类型 | 状态描述 | 恢复策略 |
|---|---|---|
| T1 | 在 TcT_cTc 之前开始,在 TcT_cTc 之前提交 | 不要重做 (数据已在盘上) |
| T2 | 在 TcT_cTc 之前开始,在 TcT_cTc 之后提交 | REDO (重做) |
| T3 | 在 TcT_cTc 之前开始,在 TfT_fTf 时未完成 | UNDO (撤销) |
| T4 | 在 TcT_cTc 之后开始,在 TcT_cTc 之后提交 | REDO (重做) |
| T5 | 在 TcT_cTc 之后开始,在 TfT_fTf 时未完成 | UNDO (撤销) |
4. 具体的恢复步骤
- 定位检查点 : 从重新开始文件中找到最后一个检查点记录在日志文件中的地址,进而找到该检查点记录。
- 初始化队列 :
- 由检查点记录得到正在执行的事务清单 (
ACTIVE-LIST)。 - 将
ACTIVE-LIST暂时全部放入UNDO-LIST队列。 REDO-LIST队列暂为空。
- 由检查点记录得到正在执行的事务清单 (
- 正向扫描日志 (从检查点开始 → 直到结束):
- 如有新开始 的事务 TiT_iTi (如T4, T5),把 TiT_iTi 暂时放入
UNDO-LIST。 - 如有提交 的事务 TjT_jTj (如T2, T4),把 TjT_jTj 从
UNDO-LIST移到REDO-LIST。
- 如有新开始 的事务 TiT_iTi (如T4, T5),把 TiT_iTi 暂时放入
- 执行恢复 :
- 对
UNDO-LIST中的每个事务执行 UNDO 操作。 - 对
REDO-LIST中的每个事务执行 REDO 操作。
- 对
5. 思考题
问题:如果在建立检查点过程中(特别是上述4个步骤没执行完时)发生了系统故障,恢复子系统会如何恢复数据库?
解析:
- 重新开始文件记录的是上一个成功完成的检查点地址。
- 如果当前检查点正在建立过程中崩溃,第4步(写入重新开始文件)尚未执行。
- 因此,系统重启时,会读取到之前的旧检查点。
- 虽然恢复时间会稍长(需要扫描更多的日志),但数据库的正确性和一致性依然可以得到保证。
11.6 数据库镜像
1. 为什么需要数据库镜像?
- 介质故障的影响严重:介质故障(如磁盘损坏)恢复比较费时,会严重影响数据库的可用性。
- 传统方法的局限:传统的"定期转储"虽然能预防,但恢复时需要重装副本和重做日志,停机时间长。
- 目标:提高数据库的可用性,实现快速恢复。
2. 定义与机制
- 定义:数据库管理系统(DBMS)自动把整个数据库或其中的关键数据复制到另一个磁盘上。
- 一致性保证 :DBMS自动保证镜像数据与主数据的一致性。
- 每当主数据库更新时,DBMS自动把更新后的数据复制到镜像数据库。
3. 数据库镜像的用途
(1) 出现介质故障时(高可用性)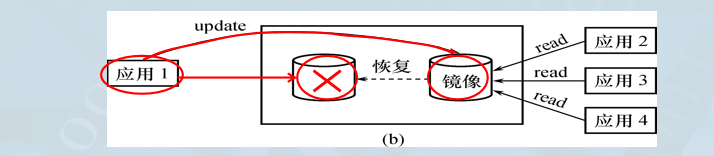
- 无缝切换:可由镜像磁盘继续提供使用,不需要关闭系统和重装数据库副本。
- 自动恢复:DBMS自动利用镜像磁盘数据进行数据库的恢复。
(2) 没有出现故障时(高并发性)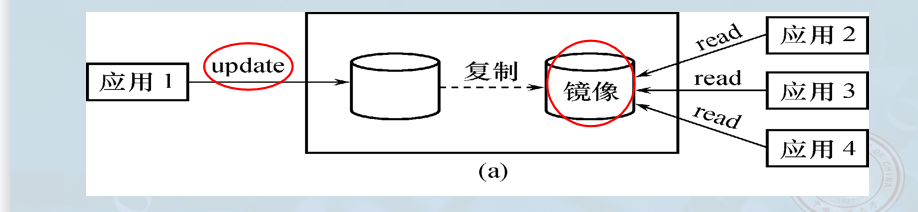
- 负载均衡:可用于并发操作。
- 场景 :当一个用户对主数据库加排他锁(Write Lock)修改数据时,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁。
4. 优缺点与实际应用
- 缺点:频繁地复制数据会降低系统运行效率(写操作变慢)。
- 实际策略 :在实际应用中,用户往往只选择对关键数据 和日志文件进行镜像,而不是对整个数据库进行镜像。
11.7 数据库恢复技术本章总结
1. 核心概念:事务
- 事务是数据库的逻辑工作单位。
- DBMS必须保证事务的ACID性质(原子性、一致性、隔离性、持续性),从而保证数据库处于一致状态。
2. 故障的种类
| 故障类型 | 描述 |
|---|---|
| 事务故障 | 逻辑错误,事务非正常终止 |
| 系统故障 | 内存丢失,磁盘完好 (软故障) |
| 介质故障 | 磁盘损坏 (硬故障) |
| 计算机病毒 | 人为或其他破坏 |
3. 恢复的基本原理
- 冗余 :利用存储在后备副本 、日志文件 和数据库镜像中的冗余数据来重建数据库。
4. 恢复中最常用的实现技术
- 数据转储
- 登记日志文件
5. 针对不同故障的恢复策略 (背诵重点)
- 事务故障 :UNDO (撤销)。
- 系统故障 :UNDO (未完成事务) + REDO (已提交事务)。
- 介质故障 :重装备份 (恢复到一致性状态) + REDO (已提交事务)。
6. 提高恢复效率的技术
- 检查点技术 :
- 显著提高系统故障的恢复效率(减少扫描日志的时间,减少重做的事务量)。
- 在一定程度上提高利用动态转储备份进行介质故障恢复的效率。
- 镜像技术 :
- 改善介质故障的恢复效率(甚至实现零停机)。
7. 复习建议
- 重点:牢固掌握事务的4个性质(ACID)、3种故障对应的恢复策略、以及具有检查点的恢复步骤。
- 难点:日志文件的使用规则(先写日志后写数据库)、系统故障恢复中队列的构建(UNDO队列 vs REDO队列)。