如果说前几年我是在"捡 API、抄 Demo、补锅",那 2025 就是我开始"写自己的框架"的一年。
我不追热点、不卷新概念。
我更像是在给自己搭一个"能复用、能解释、能传给别人"的技术体系。
这一年,我围绕 Kotlin 协程、并发模型、Flow、架构设计、工程实践 写了点文章。
🧭 一、协程与并发:从"会用"到"吃透"
今年我最大的突破,是终于把协程从"工具"理解成"范式"。
1. 协程解决的不是"怎么开线程",而是"怎么组织并发工作流"。
我写了多篇文章,从底层解释协程的本质:
- 协程是挂起式,不阻塞线程 Kotlin协程优雅打印奇偶数
- 调度是协作式,而不是抢占式 深入理解 Kotlin 协程的挂起与恢复机制
- suspend 是"可暂停的函数",不是"异步"深入理解 Kotlin 协程的挂起与恢复机制
- 协程能从根本上降低死锁风险 并发编程的新篇章:以Kotlin协程告别JUC的重锁与死锁风险
我甚至写了一个"奇偶打印"和"非阻塞优先级队列" 的示例,用代码证明:
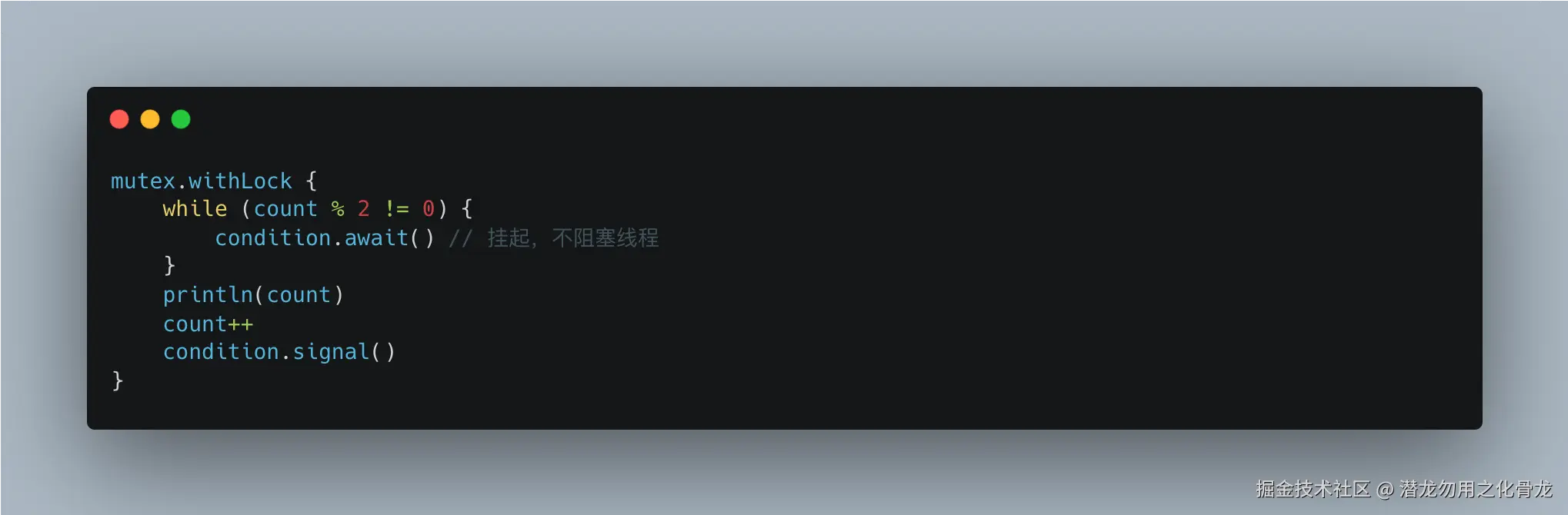
这段代码只跑在一个线程上,却能实现并发协作。
2. 告别 JUC:协程替代传统并发模型
今年我系统性地对比了协程与 JUC:
| JUC | 协程 |
|---|---|
| ReentrantLock | Mutex |
| BlockingQueue | Channel |
| CompletableFuture | Deferred |
| ThreadPool | CoroutineDispatcher |
我不仅能替代,还能解释为什么协程更安全:
- 不阻塞线程
- 可取消
- 结构化并发自动清理资源
- 不会因为线程被占满导致死锁
这是我今年最有体系的一组文章 并发编程的新篇章:以Kotlin协程告别JUC的重锁与死锁风险
3. 协程异常体系:从"try-catch 不生效"到彻底理解
今年我终于搞懂了:
- 为什么外层 try-catch 捕获不到协程内部异常
- coroutineScope 会让兄弟协程一起失败
- supervisorScope 可以隔离失败
- Repository 层统一处理异常后,协程作用域的差异会被弱化
这些理解让我在架构层面能更稳地设计协程模型 详情请见 协程异常处理使用策略
🧱 二、架构思维:从"我能写"到"我能讲清楚"
今年我不仅写代码,还开始"写体系"。
1. Clean Architecture:从 PPT 到真正落地
以前我理解的 Clean Architecture 是"分层"。
今年我终于意识到,它不仅仅是一张结构图,更是一套行为准则 。
它要求我们在复杂系统里保持边界清晰,让每一段逻辑都有明确的归宿。
我不再追求炫技式的抽象,而是回到业务本质:
业务逻辑必须被收敛,而不是散落在 ViewModel、Repository、Utils 各个角落。
"轻量化" UseCase:业务动作的最小单位
在遵循 Clean Architecture 原则的基础上,我对 UseCase 的实践进行了精简。我主张回归 UseCase 作为'业务意图载体'的本质,不再追求繁琐的继承体系或过度模板化,而是确保逻辑严谨地收敛于领域层。
每一个 UseCase 都应聚焦于单一业务主题,通过清晰的边界管理,实现复杂业务步骤的有序编排。
例如登录流程,我会这样写:
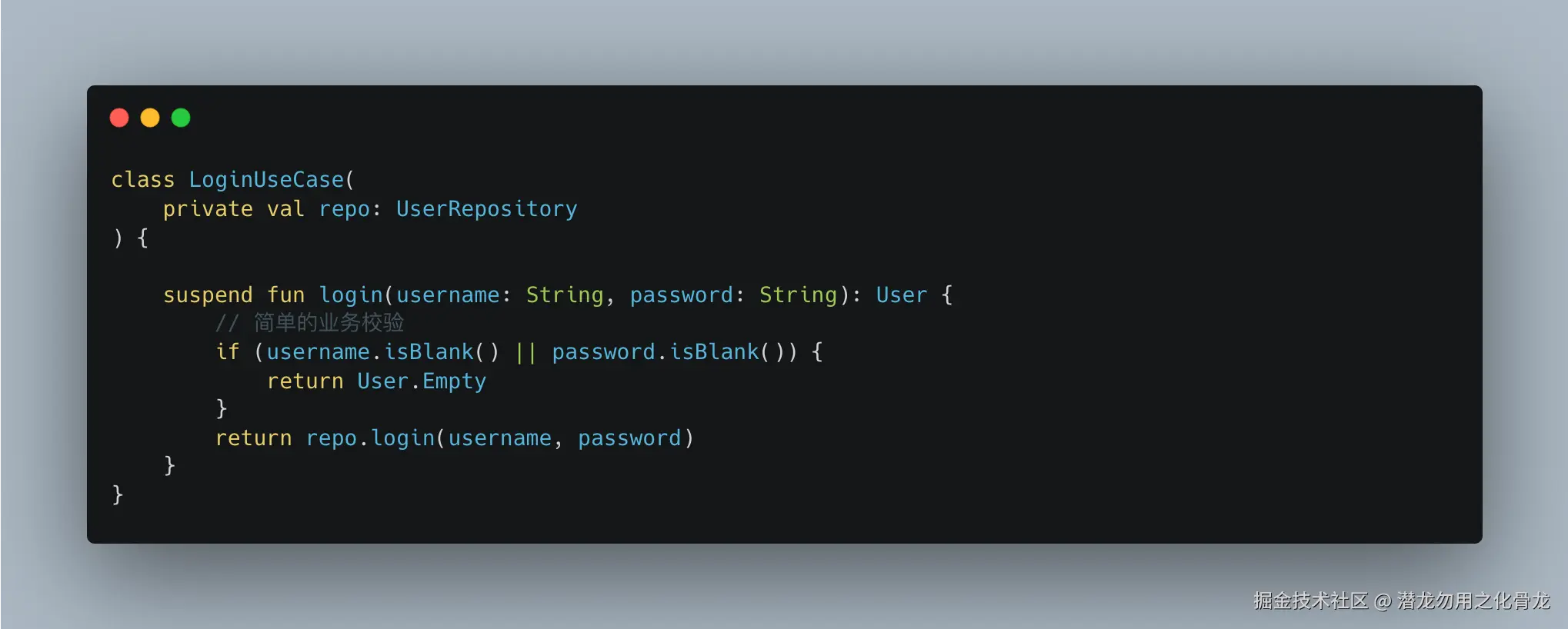
调用端非常自然:

当然这代码示例过于简单,仅供参考。
UseCase 就是一个"可注入的业务动作集合",
它让业务逻辑从 UI 层和数据层中被抽离出来,形成一个可复用、可测试、可复述的独立单元。
总结:架构的本质是"确定性"
这套体系根治了协作中'逻辑乱飞'的顽疾。好的架构不应是开发的阻碍,而是提速的基石。 我们追求的是'开发体验'与'代码直观性'的统一:当代码写起来顺畅、读起来清晰,架构规范便能真正内化为团队的行为准则。
2. Data 层四条红线:年度架构实践的核心沉淀
今年我总结了 Data 层的四条底线:
接口契约化:Repository 接口必须强制使用 suspend 或 Flow。
拒绝阻塞:严禁在数据流中使用阻塞队列(Blocking Queue)。
并发轻量化:禁止使用 Java 原生重型锁,全面拥抱协程并发原语。
响应纯粹性:确保 suspend 函数内部实现必须为"真异步"逻辑。
这四条红线,让我在团队里第一次把"协程架构规范"讲清楚了。
3. Repository 不应该启动协程
今年我重构了大量代码,把这种写法:
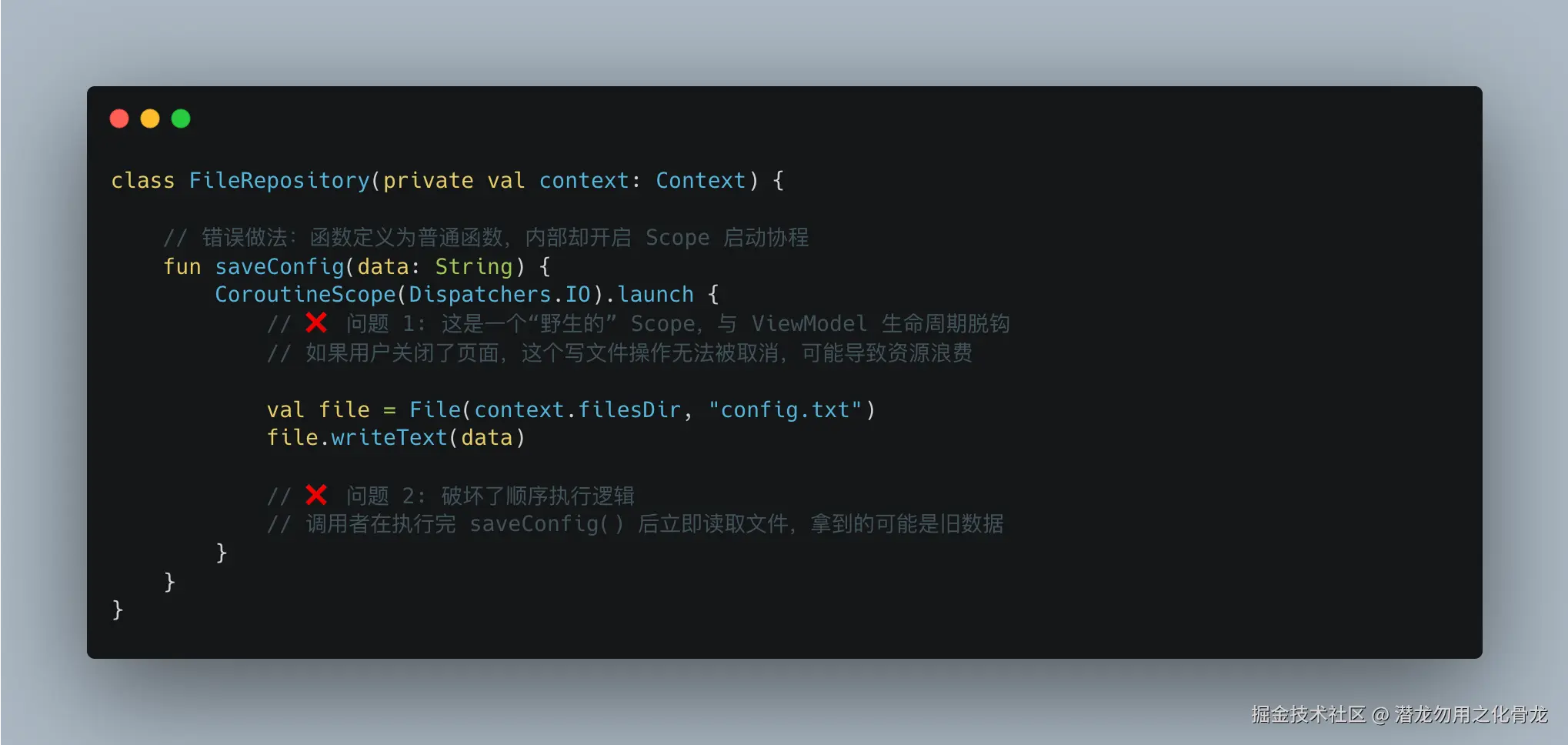
改成:
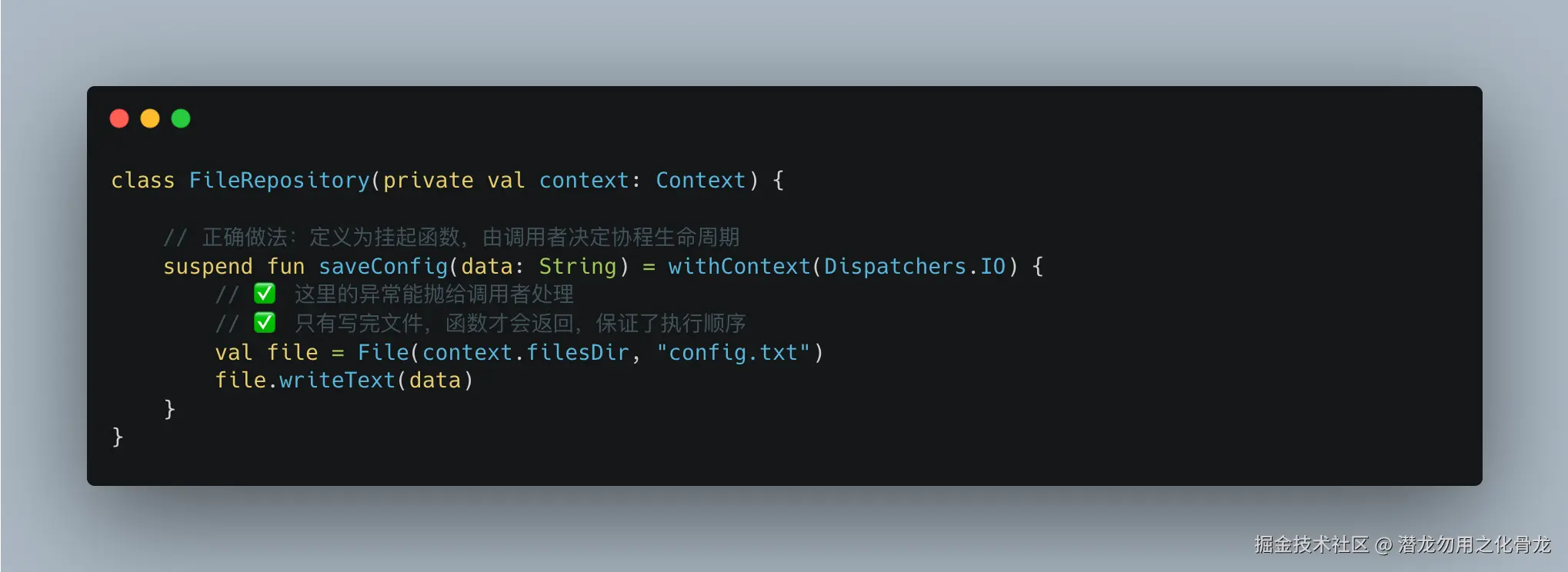
当然如果repo层发起了网络请求(retrofit)或者操作数据库(room),那么withContext(Dispatchers.IO) 也省了。如下:
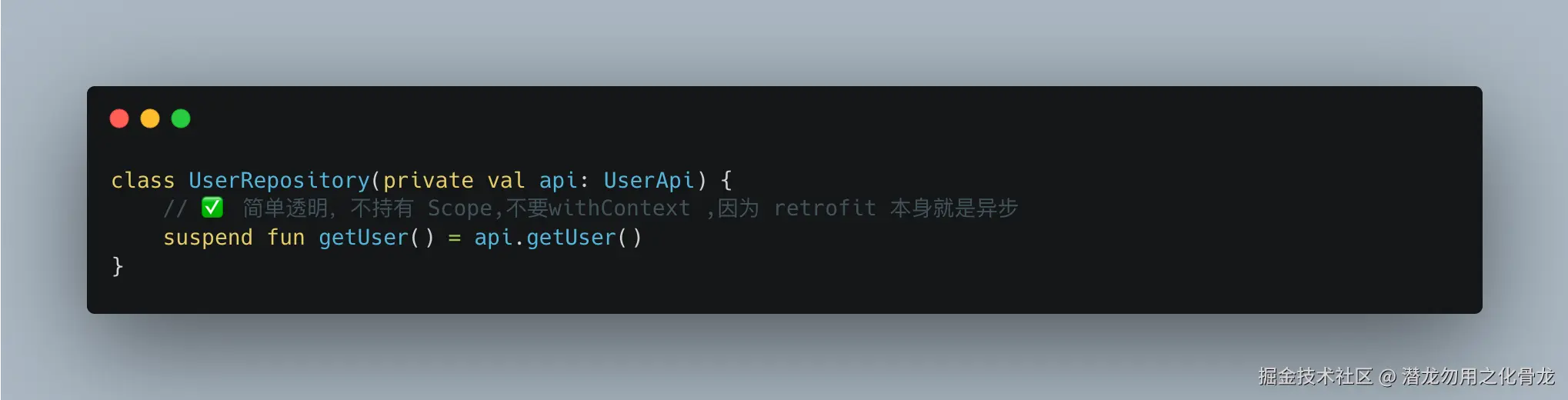
协程作用域交给 ViewModel 管理,生命周期更清晰,测试也更简单。
⚙️ 三、工程能力:从"能解决问题"到"能搭体系"
今年我在工程实践上做了几件让我自己很满意的事情:
不只是把问题解决掉,而是把它们沉淀成可复用、可推广的工程能力。
1. 非阻塞优先级队列:从 Java 阻塞模型到协程模型
在并发编程里,队列是最基础也最关键的数据结构,尤其是在生产者-消费者模型中。
Java 的阻塞队列(如 ArrayBlockingQueue、PriorityBlockingQueue)虽然成熟,但它们依赖线程阻塞与唤醒,意味着:
- 线程会被挂起
- 需要 OS 调度
- 上下文切换成本高
在高并发场景下,这种模型往往会成为瓶颈。
今年我尝试把这个问题换一种方式解决:
用 Kotlin 协程实现一个真正意义上的"非阻塞优先级队列"。
协程的挂起不会阻塞线程,因此可以让队列在"空"或"满"时挂起协程,而不是挂起线程。
这带来的好处非常明显:
- 没有线程阻塞
- 没有线程唤醒
- 没有上下文切换
- 并发吞吐量更高
是核心实现请看 基于Kotlin协程的非阻塞优先级队列设计与实现
这种能力在实际场景中非常有价值,例如:
- 任务调度系统
- 实时系统
- 多优先级任务处理
- 车载系统、IoT 等高并发但线程资源有限的场景
它让我第一次真正感受到:
协程不是"轻量线程",而是另一种并发模型。
2. 深入理解 runBlocking:协程世界与阻塞世界的"唯一桥梁"
runBlocking 是协程里最容易被误用的 API。
它的作用很直接:启动一个协程,并阻塞当前线程直到协程执行完毕。
它的存在意义非常明确:
在阻塞世界与协程世界之间搭桥。
它的本质是:
把挂起函数变成阻塞调用,让非协程环境也能使用协程能力。
典型场景包括:
- Java 代码调用 Kotlin 挂起函数
- Retrofit 拦截器需要同步获取 token
- 基于 HandlerThread 的旧架构需要串行执行挂起任务
Android 中 runBlocking其实只有一种使用场景
但即便如此,也应该优先考虑纯协程方案,runBlocking 只是兜底手段。
4. Kotlin 协程的五大常见错误用法及最佳实践
🧩 四、文档:从"写文档"到"做知识产品"
今年我写的文档比写代码还多。
原因很简单: 我有强烈的分享欲,也习惯把一切做成可复用的规范。比如:
Kotlin 协程的五大常见错误用法及最佳实践
Repository 方法设计:suspend 与 Flow 的决选择指南(以朋友圈为例)
Android Data 层设计的四条红线:为什么必须坚持、如何落地
所以我开始用更"产品化"的方式沉淀知识:
用图把架构讲得一目了然
用类比把复杂逻辑讲得人人能懂
用模板把新人 onboarding 的成本降到最低
前阵子我给团队做了一份"错误处理流程图", 大家看完后的第一句话是:"终于懂了。"
那一刻我更确定: 文档不是记录,而是团队的知识基础设施。
🤝 五、AI:从工具到"第二大脑"
2025,我真正学会了和 AI 合作。
我用它:
生成架构图
写文档
验证设计
做知识树
当思考伙伴
这一年,我不再把 AI 当成工具,而是把它当成随时在线的第二大脑。
🚀 六、2026:从"积累"到"影响力"
明年我想做三件事:
1. 把技术体系补全
包括:
- clean 架构
- Compose 最佳实践
- 工程化与并发模型
2. 输出更多"别人能直接用"的东西
比如:
- 模板
- 图示
- 代码骨架
- 体系化知识
3. 让 AI 成为真正的合作者
继续探索:
- AI 如何参与架构设计
- AI 如何生成文档
- AI 如何融入学习系统
结语:2025,是我技术生涯的"结构化元年"
这一年,我不再盲目追求技术栈的"增量",而开始深耕知识的"质量"。我时刻复盘这五个维度: