今天给大家演示一个 Flux 多模型组合的 ComfyUI 工作流。这个流程通过整合 flux1-dev 主模型、双文本编码器组合与高质量 VAE 解码器,让图像生成在清晰度、细节与风格一致性上都有更稳的表现。

你可以在同一条链路中完成提示词编码、潜空间生成、随机采样与最终解码,整个过程干净利落,适合想要高质量成片又希望工作流简单可靠的用户。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncodeFlux 多模型文本语义融合](#CLIPTextEncodeFlux 多模型文本语义融合)
- [FluxGuidance 文本嵌入调控](#FluxGuidance 文本嵌入调控)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
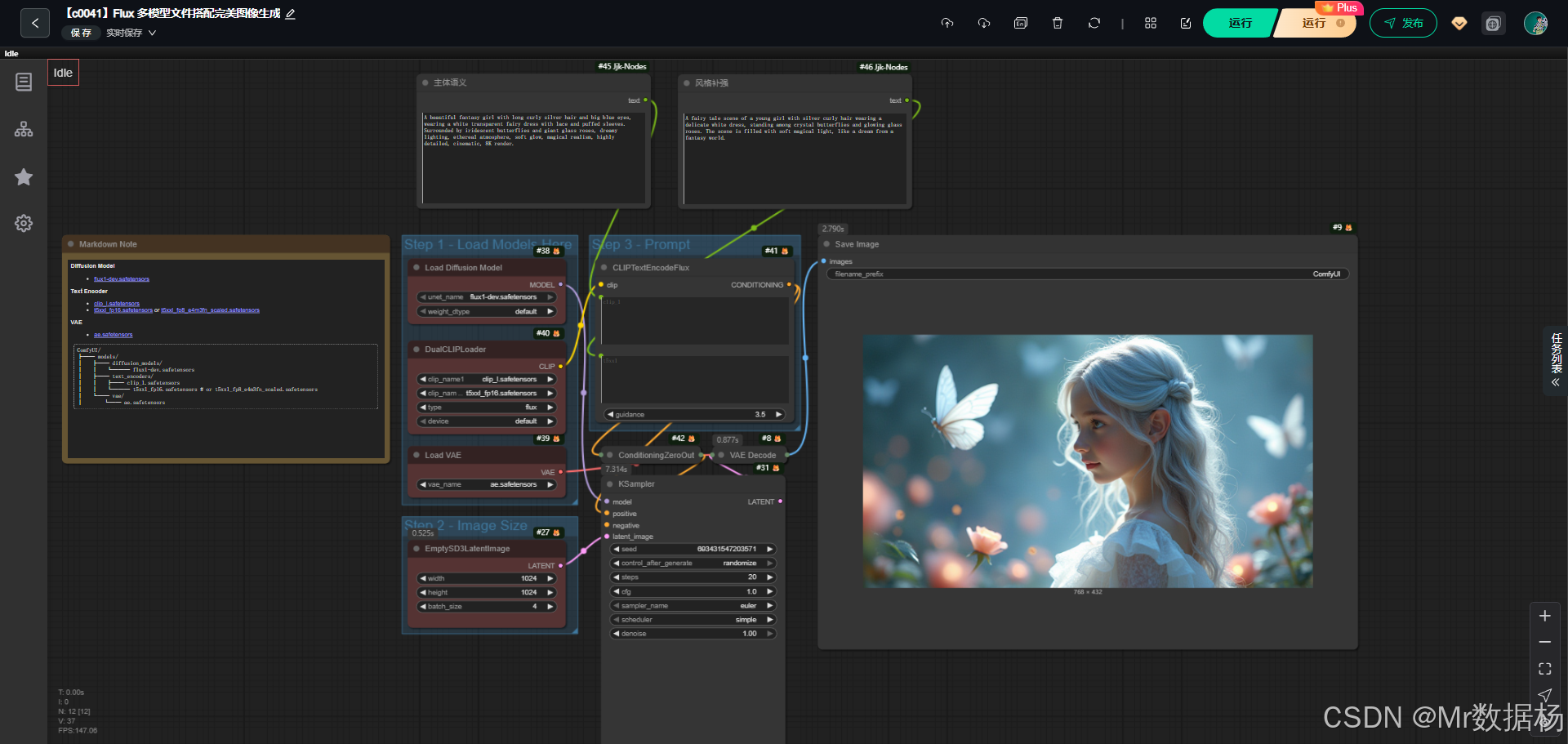
该工作流依赖于 Flux Dev 的完整模型组合,包括扩散模型、文本编码器与VAE解码器的协同配合。扩散模型负责潜空间图像的生成与迭代优化,文本编码器则确保提示语能够被充分解析并转化为条件信息,VAE则在潜空间与真实图像空间间完成映射与解码,保证图像的质量和层次感。通过这些模型的整合,工作流能够在大显存环境下生成具备魔幻写实感的高质量作品。
核心模型
在核心模型层面,该工作流由三类模型构成。扩散模型 flux1-dev.safetensors 作为生成的核心引擎,负责图像的迭代扩散与细节渲染。文本编码器包含 clip_l.safetensors 与 t5xxl_fp16.safetensors,二者分别提供语义理解与长文本处理能力,使提示能够被完整解析。VAE模型 ae.safetensors 则承担潜变量与图像空间的双向转换,从而保证生成结果的清晰度与自然感。这些模型的组合确保了从文本到图像的高保真度与表现力。
| 模型名称 | 说明 |
|---|---|
| flux1-dev.safetensors | 核心扩散模型,用于生成潜空间图像并完成迭代渲染 |
| clip_l.safetensors | 文本编码器,负责基础语义解析 |
| t5xxl_fp16.safetensors | 大规模文本编码器,支持复杂长文本提示的高精度解析 |
| ae.safetensors | VAE解码器,将潜空间图像解码为高分辨率成品图像 |
Node节点
节点设计方面,工作流包含模型加载、文本编码、条件处理、采样生成与图像解码等核心环节。UNETLoader、DualCLIPLoader 和 VAELoader 共同完成模型的加载与初始化,CLIPTextEncodeFlux 将提示语转化为条件向量,ConditioningZeroOut 则在负面提示处理中起到作用。EmptySD3LatentImage 用于生成空的潜空间作为采样起点,KSampler 是扩散采样与细化的核心模块,最终通过 VAEDecode 将潜空间转换为可视化图像,并由 SaveImage 节点完成输出保存。整体结构紧密衔接,形成完整的端到端生成链路。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载扩散模型 flux1-dev,用于潜空间图像生成 |
| DualCLIPLoader | 加载 clip_l 与 t5xxl 文本编码器,解析提示语 |
| VAELoader | 加载 VAE 模型 ae.safetensors,提供潜空间与图像空间的映射 |
| CLIPTextEncodeFlux | 将文本提示转化为条件输入,支持正面与负面提示 |
| ConditioningZeroOut | 处理负面条件,确保提示遵循性 |
| EmptySD3LatentImage | 创建空潜空间,定义输出分辨率与通道 |
| KSampler | 扩散采样与细化,决定生成图像的质量与风格 |
| VAEDecode | 将潜空间图像解码为高清图像 |
| SaveImage | 输出与保存最终生成结果 |
工作流程
该工作流的执行逻辑由模型加载、条件构建、潜空间采样、图像解码与最终保存构成,形成了自洽的闭环。在最初阶段,加载 UNet 主模型、CLIP 文本编码器和 VAE 编解码器,为后续图像生成提供核心计算支撑。接着通过 CLIPTextEncodeFlux 将提示词转化为语义条件,结合 ZeroOut 形成正负向引导,确保画面既能突出主体特征又能避免不良元素。随后由 KSampler 在指定步数、采样器与种子下进行潜空间搜索,生成符合条件的潜图表示。潜图经过 VAE 解码恢复为可视化图像,最后由 SaveImage 节点完成保存与导出。整体流程不仅保证了画质与提示词遵循度,也为复现和批量任务执行提供了清晰路径。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 01 | 模型加载 | 加载 UNet、CLIP 编码器和 VAE,完成基础依赖准备 | UNETLoader、DualCLIPLoader、VAELoader |
| 02 | 条件构建 | 将文本提示转为语义条件,区分正负引导 | CLIPTextEncodeFlux、ConditioningZeroOut |
| 03 | 潜空间采样 | 在设定参数下生成潜图,决定画面构图与细节 | KSampler |
| 04 | 解码输出 | 将潜图通过 VAE 解码为可视化图像 | VAEDecode |
| 05 | 成果保存 | 将最终结果导出到指定目录,便于复现 | SaveImage |
大模型应用
CLIPTextEncodeFlux 多模型文本语义融合
在 Flux 多模型工作流中,CLIPTextEncodeFlux 节点负责将用户提供的多个正向 Prompt 转化为 CLIP 嵌入,并通过权重融合生成最终文本嵌入向量。这些嵌入用于指导生成模型理解复杂的场景、角色和细节组合,实现高保真、多元素融合的图像生成。用户通过多 Prompt 配合和权重设置,可以精确控制图像中的角色特征、光影、环境氛围和细节表现。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncodeFlux | Prompt 1: A beautiful fantasy girl with long curly silver hair and big blue eyes, wearing a white transparent fairy dress with lace and puffed sleeves. Surrounded by iridescent butterflies and giant glass roses, dreamy lighting, ethereal atmosphere, soft glow, magical realism, highly detailed, cinematic, 8K render. Prompt 2: A fairy tale scene of a young girl with silver curly hair wearing a delicate white dress, standing among crystal butterflies and glowing glass roses. The scene is filled with soft magical light, like a dream from a fantasy world. Weight/CFG: 3.5 | 将多条正向 Prompt 转化为 CLIP 嵌入并融合,用于控制生成模型的图像语义和风格,使多元素场景、高细节角色和环境得到精确呈现。 |
FluxGuidance 文本嵌入调控
该节点接收 CLIPTextEncodeFlux 输出嵌入,通过调整 CFG 值控制文本嵌入对生成的影响力,实现语义强化或柔化。Prompt 在此节点主要体现为嵌入权重调节,平衡图像生成的创意自由度与语义精度,使最终图像在多 Prompt 组合下仍保持细节精致和风格一致。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| FluxGuidance | CFG: 3.5 | 控制 CLIP 嵌入在生成模型中的权重影响,确保多 Prompt 组合生成图像时,元素融合自然、细节精致且风格统一。 |
使用方法
Flux 多模型工作流结合多条文本 Prompt、潜在空间采样和 VAE 解码实现高保真图像生成。用户提供多条正向 Prompt,CLIPTextEncodeFlux 转化并融合为嵌入;FluxGuidance 调整嵌入权重后输入 UNET 模型进行潜在空间采样,由 KSampler 生成潜在图像,再通过 VAELoader 和 VAEDecode 解码成最终图像,最后使用 SaveImage 输出。用户可通过更换或调整 Prompt 组合及 CFG 值,实现对图像场景、角色、光影和细节的精确控制,适合生成高复杂度和完美细节的图像场景。
| 注意点 | 说明 |
|---|---|
| 多条 Prompt 要合理组合 | 保证生成图像语义清晰、元素互补而不冲突 |
| CFG 值设置适中 | 影响文本嵌入对生成模型的控制强度,过高会抑制创意自由度,过低语义不准确 |
| 潜变量尺寸与输出匹配 | 确保 VAEDecode 解码后图像比例和清晰度正确 |
| 模型量化与精度 | Fp8 量化节省显存,但细节表现略有下降 |
| 图像细节与光影注意 | 多 Prompt 融合可能导致细节冲突,需通过 CFG 调整平衡 |
应用场景
该工作流的设计具备极强的实用性,既能作为艺术创作与二次设计的工具,也能在教学演示和科研实验中发挥作用。在艺术设计领域,它能快速生成高质量的插画、概念图或角色形象,满足游戏原画、动画分镜或书籍插图的创意需求。在内容创作中,结合灵活的提示词输入,可以稳定生成主题化风格图像,适合自媒体与视觉宣传场景。科研与教育方面,该流程因参数透明、节点直观而成为教学展示模型原理的理想案例。最终输出的图像可直接用于展示、评审或下游任务的数据准备,充分体现了工程化与创意应用的双重价值。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 艺术设计 | 快速生成插画与角色原画 | 插画师、游戏设计师 | 高质量的概念图与角色形象 | 节省手绘时间并提升细节表现力 |
| 内容创作 | 制作宣传图与主题海报 | 自媒体创作者、品牌运营 | 风格化主题图像 | 提高视觉吸引力与传播效果 |
| 教学演示 | 展示扩散模型原理 | 教师、科研人员 | 模型节点与采样流程 | 便于直观理解 AI 绘图机制 |
| 数据准备 | 构建下游训练数据集 | 研究人员、开发者 | 合成高质量样本 | 支撑其他 AI 模型训练与评测 |
| 视觉宣传 | 快速生成定制化素材 | 企业设计团队 | 产品相关图像或广告元素 | 提升市场投放与品牌表达效率 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用