今天给大家演示一个 FluxKontext 高保真服装语义提取的 ComfyUI 工作流。它的作用是从人物图像中提取服装结构,并把衣服内容以平铺方式清晰展示。整个流程依靠 Flux 系列模型、Kontext 图像尺度处理、参考潜空间、文本编码和引导控制来完成。从加载原图到处理潜空间,再到语义抽离与最终输出,整个链路保持高精度,适合做服装解析、设计参考和生产素材采集。
本文会先概述工作流程,再分阶段说明核心模型和节点作用,帮助你快速理解这个工作流的完整逻辑。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode 提取服装语义的核心指令入口](#CLIPTextEncode 提取服装语义的核心指令入口)
- [FluxGuidance 语义强化与生成方向控制](#FluxGuidance 语义强化与生成方向控制)
- [KSampler 基于 Prompt 的最终生成执行器](#KSampler 基于 Prompt 的最终生成执行器)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
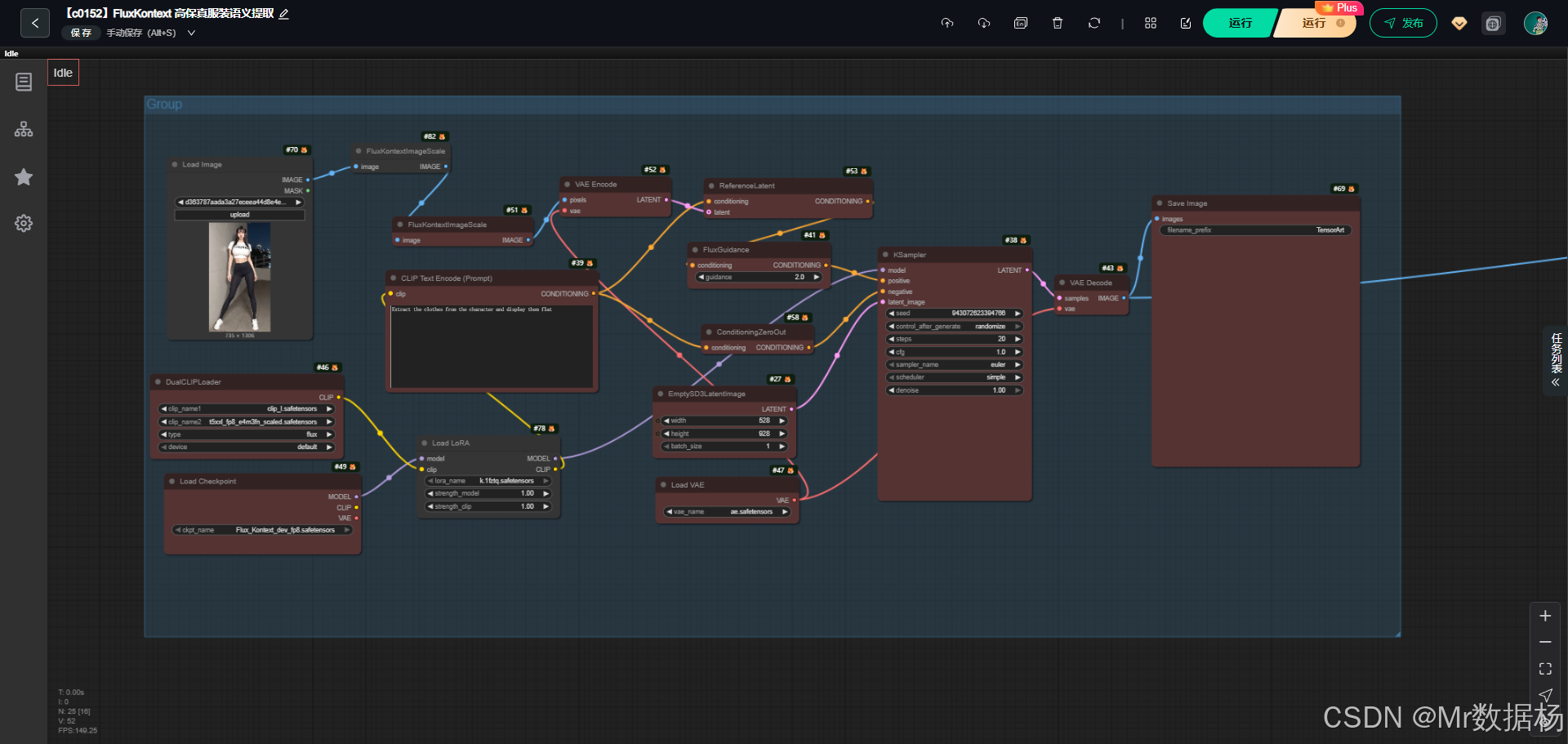
这个工作流围绕人物服装内容的"抽离、平铺、还原"展开。它以 Flux_Kontext 模型为中心,结合双 CLIP 文本编码、参考潜空间和 FluxGuidance 来精准锁定服装语义,同时通过 VAE 编码解码和 ImageScale 节点保证图像尺寸稳定。模型部分负责生成逻辑,Node 节点负责图像输入、潜空间处理、服装语义引导与最后的高清放大。各表格内容将共同说明这一整套结构如何配合输出干净、细节保留度高的服装平铺图。
核心模型
本工作流以 Flux_Kontext_dev_fp8 作为主模型,它能在服装语义抽离上保持细节清晰和结构稳定。DualCLIPLoader 负责文字指令的理解,结合 LoraLoader 加强服装提取能力。VAE 在潜空间与图像之间架起桥梁,让服装结构被准确编码与解码。Upscale 模型则用于最终画面的高保真放大。它们共同构成了"识别语义、抽离服装、平铺呈现"的基础能力。
| 模型名称 | 说明 |
|---|---|
| Flux_Kontext_dev_fp8.safetensors | 核心生成模型,负责服装语义抽离与结构还原 |
| clip_l.safetensors / t5xxl_fp8_e4m3fn_scaled.safetensors | 文本编码模型,解析语义指令 |
| k.1fztq.safetensors(LoRA) | 增强服装抽离与结构识别能力 |
| ae.safetensors(VAE) | 将图像与潜空间互相转换,保持细节与颜色稳定 |
| 4x_NMKD-Siax_200k.pth | 高清放大模型,提高最后输出分辨率 |
Node节点
这些节点承担图像输入、潜空间处理、文本引导、服装抽离与最终输出。LoadImage 提供原始图。FluxKontextImageScale 稳定输入尺寸。VAEEncode/Decode 负责潜空间的进出。ReferenceLatent 锁定图像特征,避免偏移。CLIPTextEncode + FluxGuidance 提供语义方向,让模型知道要"提取服装并平铺展示"。KSampler 执行最终生成。Upscale 模块处理清晰度输出。整个节点链路紧密结合模型,实现高保真服装提取。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 读取输入人物图像 |
| FluxKontextImageScale | 调整输入图像比例与尺寸,适配 FluxKontext |
| VAEEncode / VAEDecode | 在图像与潜空间之间转换 |
| ReferenceLatent | 锁定参考潜空间特征,保持服装结构一致 |
| CLIPTextEncode | 对文本指令编码为语义向量 |
| FluxGuidance | 控制语义引导力度,提升服装提取准确性 |
| ConditioningZeroOut | 清理多余条件,保持模型专注服装语义 |
| KSampler | 执行采样并生成抽离后的服装平铺图 |
| UltimateSDUpscale | 最终放大输出,提升清晰度 |
| SaveImage | 保存成品图像 |
工作流程
整个流程从输入图像开始,先通过尺度处理和 VAE 编码进入潜空间,再结合文本语义与参考潜空间锁定服装信息。随后由 KSampler 根据模型与引导指令执行生成,产出的图像会交给高清放大模块修整细节,最后导出干净平铺的服装图。流程中的每一步都在为服装语义的精确抽离服务,从输入、理解、生成到增强形成完整闭环。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入与预处理 | 加载人物图像并统一尺度,使图像适配后续潜空间结构 | LoadImage、FluxKontextImageScale |
| 2 | 编码阶段 | 将预处理后的图像转为潜空间,同时加载主模型、CLIP 和 LoRA | VAEEncode、CheckpointLoaderSimple、DualCLIPLoader、LoraLoader |
| 3 | 语义构建 | 对指令编码并生成参考潜空间,引导模型专注服装抽离 | CLIPTextEncode、ReferenceLatent、FluxGuidance、ConditioningZeroOut |
| 4 | 采样生成 | 基于模型、语义与潜空间执行服装平铺生成 | KSampler |
| 5 | 解码与高清增强 | 将潜空间结果解码成图像并进行高清放大处理 | VAEDecode、UltimateSDUpscale |
| 6 | 输出 | 保存最终的平铺服装图 | SaveImage |
大模型应用
CLIPTextEncode 提取服装语义的核心指令入口
CLIPTextEncode 节点承担整个工作流的语义驱动任务。它负责读取 Prompt,将文本内容编码成条件向量,使模型明确"要生成什么"。在本工作流中,它直接决定服装提取的方式、结构还原的准确度,以及结果画面的风格倾向。Prompt 在这里是唯一的语义源头,模型会完全按照 Prompt 的语言描述执行,因此任何风格变化、结构强调或细节指令都必须在 Prompt 中给出。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode | Extract the clothes from the character and display them flat | 将 Prompt 编码为语义向量,引导模型完成服装抽离与平铺任务。 |
FluxGuidance 语义强化与生成方向控制
FluxGuidance 节点不负责解析文本,但它决定文本语义在生成过程中的"力度"。它的任务是根据 Prompt 形成的条件向量,调整模型在服装抽离时的执行强度,使提取过程更加稳定、干净并保持语义一致。Prompt 的描述越明确,FluxGuidance 在此基础上的引导越有效,能够强化服装平铺结构与细节表现,避免图像偏移与语义漂移。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| FluxGuidance | 来自 CLIPTextEncode 的全部 Prompt 语义 (无额外文本输入) | 强化 Prompt 的语义执行力度,使模型在生成过程中遵循文本描述,保持结构稳定。 |
KSampler 基于 Prompt 的最终生成执行器
KSampler 是最终的图像生成执行单元,它依靠前序节点提供的 Prompt 语义、参考潜空间与模型参数完成实际画面采样。Prompt 在这里决定服装的平铺方式、抽离精度、细节走向和整体画面干净度。KSampler 会严格按照 Prompt 的内容与 FluxGuidance 的强度来进行迭代采样,因此 Prompt 写法对结果影响最大。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| KSampler | 来自 CLIPTextEncode 的全部 Prompt 语义 (无额外文本输入) | 执行最终采样,根据 Prompt 和引导条件生成服装平铺图。 |
使用方法
这个工作流的运行逻辑很简单。用户只需提供人物图像,工作流会自动完成图像加载、尺寸适配、潜空间编码、Prompt 语义解析、服装抽离、平铺生成、高清放大以及最终输出。所有的 AI 生成过程都会根据 Prompt 设定好的语义方向自动运行,无需额外操作。
如果用户想替换素材,只需要更换输入图像,工作流会重新解析新的服装纹理、结构和色彩并重新生成平铺图。Prompt 决定提取规则,图像提供原始服装信息,两者结合即为完整生成条件。
角色图提供服装的来源,Prompt 决定要如何抽离和展示,模型会自动执行编码、采样与输出,整个流程保持全自动化并适配各种人物图像与服装类型。
| 注意点 | 说明 |
|---|---|
| 保持 Prompt 语义明确 | 直接写出"要做什么",避免模糊描述,影响模型对服装结构的理解。 |
| 输入图尽量清晰 | 服装的纹理、褶皱、轮廓越清楚,平铺图越准确。 |
| 避免背景复杂干扰 | 虽然模型能抽离服装,但简单背景能减少误识别。 |
| 不要删除关键节点 | CLIPTextEncode、FluxGuidance、ReferenceLatent 是语义与稳定性的核心。 |
| 尽量保持默认比例与尺度 | FluxKontextImageScale 已处理适配,不建议随意更改以免失真。 |
应用场景
这个工作流主要面向需要从人物图像中提取服装结构的用户,不论是设计、生产还是内容创作都能直接受益。它能够快速把服装独立抽离并平铺展示,让布料纹理、结构线条和细节图案清晰呈现。无论是做服装素材库、设计打版、跨平台电商展示、AI 换装资料准备,或者需要制作高保真服装图的创意场景,都能用这一流程完成。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 服装平铺素材制作 | 获取干净稳定的服装结构图 | 服装设计师、制版师 | 衣服形状、纹理、色块、细节 | 形成可直接使用的平铺素材 |
| 电商展示图生成 | 从模特图中分离衣物用于展示或搭配图 | 电商、运营 | 服装单品平铺展示 | 减少拍摄成本,提高展示效率 |
| AI 换装数据准备 | 为换装模型准备标准化服装素材 | AI 创作者、模型训练者 | 单件服装平铺图 | 提升换装模型识别度与泛化性 |
| 视觉创作与重绘 | 生成服装设计草图或二改原素材 | 插画师、内容创作者 | 清晰结构的服装平铺稿 | 保留细节,易于二次加工 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用