wrf_preprocessor 详解-目录
- 输入/输出文件概览
- 代码详解
-
- [配置文件 config.yaml](#配置文件 config.yaml)
- 函数1:vprm_preprocessor_new.py
- 输出文件可视化
-
- [读取 VPRM 植被类别覆盖率](#读取 VPRM 植被类别覆盖率)
- [读取 VPRM 生成的 EVI、LSWI 指数文件](#读取 VPRM 生成的 EVI、LSWI 指数文件)
- 参考
GitHub 上的 Python 包 pyVPRM
本博客对 pyVPRM_examples 中 案例1:生成 WRF 模型输入(wrf_preprocessor)进行详细解释,pyVPRM的安装可参考另一博客-【WRF-Chem工具】pyVPRM 计算大气与陆地植被之间的 CO₂ 交换通量 。
克隆示例仓库:
bash
git clone https://github.com/tglauch/pyVPRM_examples.git示例目录说明:
| 文件夹 | 功能 |
|---|---|
./wrf_preprocessor |
生成 WRF 模型输入 |
./vprm_predictions |
生成 GPP / NEE 通量预测 |
./fit_vprm_parameters |
拟合 VPRM 参数 |
./sat_data_download |
下载 MODIS / VIIRS 数据 |
用于脚本的数据已经预处理过 ,目的是为了节省内存空间(可能是裁剪、下采样、压缩等)。
输入/输出文件概览
外部数据准备
使用以下 3 类主要外部数据:
| 数据类型 | 数据来源 | 格式 | 用途 |
|---|---|---|---|
| 1. 卫星遥感数据 | MODIS 或 VIIRS | .hdf |
提取植被指数(EVI、LSWI)、用于 VPRM 输入 |
| 2. 土地覆盖地图 | Copernicus Land Cover | GeoTIFF 或 NetCDF | 提供植被类型(森林、农田、草地等) |
| 3. WRF 地理网格文件 | WRF 模型(geo_em)输出 | .nc (NetCDF) |
获取模拟区域的网格经纬度信息,用于裁剪和重投影 |
区域范围 :聚焦于 亚马逊地区的 ATTO 塔(Amazon Tall Tower Observatory)周围区域。
数据来源:
- MODIS 卫星数据:提供遥感植被参数(如 NDVI、EVI、LAI 等)。
- Copernicus 地表覆盖图(Land Cover Map):提供土地利用/覆盖类型(如森林、草地、农田等)的空间分布信息。
在命令行中运行这个脚本:
bash
source activate pyvprm_env
python vprm_preprocessor_new.py --year 2022 --config ./config/preprocessor_config.yaml需要说明的是,代码需要需要 Github-copernicus_land_cover_wrf.yaml 文件,下载后上传至 $HOME/miniconda3/envs/pyvprm_env/lib/python3.9/site-packages/pyVPRM/vprm_configs/ 文件夹。
运行成功,如下:
生成的文件如下:
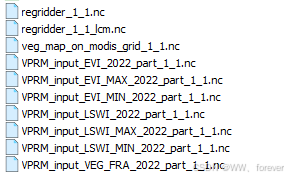
输出文件总览
输出文件的可视化可以参考另一博客-【WRF-VPRM 预处理器第五期】基于Python读取并可视化生成的 EVI、LSWI 指数文件。
| 文件名 | 内容 | 是否用于 WRF-VPRM | 说明 |
|---|---|---|---|
VPRM_input_EVI_2022_part_1_1.nc |
主动植被指数(EVI)时间序列 | ✅ | 每个时间步对应一个 EVI 图层 |
VPRM_input_EVI_MAX_2022_part_1_1.nc |
年度最大 EVI | ✅ | 用于归一化 |
VPRM_input_EVI_MIN_2022_part_1_1.nc |
年度最小 EVI | ✅ | 用于归一化 |
VPRM_input_LSWI_2022_part_1_1.nc |
LSWI 时间序列(湿度相关) | ✅ | 与水分胁迫相关 |
VPRM_input_LSWI_MAX_2022_part_1_1.nc |
年度最大 LSWI | ✅ | 用于计算水分胁迫函数 |
VPRM_input_LSWI_MIN_2022_part_1_1.nc |
年度最小 LSWI | ✅ | 同上 |
VPRM_input_VEG_FRA_2022_part_1_1.nc |
植被覆盖率(vegetation fraction) | ✅ | 类似于 WRF 的 VEGFRA,用于调节 VPRM 通量强度 |
⚙️ regridder_1_1.nc |
重投影转换矩阵(xESMF regridder) | ❌ | 缓存文件,可删除或保留加速重投影 |
⚙️ regridder_1_1_lcm.nc |
土地覆盖图的重投影矩阵 | ❌ | 同上,用于 Copernicus 重采样 |
⚙️ veg_map_on_modis_grid_1_1.nc |
MODIS 网格上的土地覆盖图 | ❌ | 中间产品,可用于检查处理正确性 |
所有 VPRM 输入文件遵循以下命名格式:
VPRM_input_<VAR>_<YEAR>_part_<chunk_x>_<chunk_y>.nc<VAR>:变量名,如EVI,LSWI,VEG_FRA,EVI_MAX, 等<YEAR>:年份(你运行脚本时指定的--year参数)part_<chunk_x>_<chunk_y>:表示 WRF 网格被分块处理的编号(用于大网格并行处理)
代码详解
为 WRF 模型(Weather Research and Forecasting)生成 VPRM 模型的输入数据。
配置文件 config.yaml
preprocessor_config.yaml 内容如下:
bash
years:
- 2022
satellite: modis
sat_image_path: ./data/modis/
copernicus_path: ./data/copernicus/
out_path: ./out/
geo_em_file: ./data/geo_em.d04.nc
n_chunks: 1
hvs:
- [12,9] 文件路径通常是相对路径或绝对路径,需确保文件存在,否则脚本会报错或跳过处理。
函数1:vprm_preprocessor_new.py
vprm_preprocessor_new.py 结合卫星遥感数据(MODIS 或 VIIRS)和土地覆盖数据(Copernicus),生成多个 NetCDF 文件供 WRF-VPRM 模型读取。
text
┌────────────────────┐
│ 读取命令行参数和配置 │
└────────┬───────────┘
▼
┌──────────────────────┐
│ 读取WRF网格和MODIS tile │
└────────┬─────────────┘
▼
┌────────────────────────────┐
│ 读取遥感数据(MODIS/VIIRS) │
└────────┬───────────────────┘
▼
┌───────────────────────────────┐
│ 添加到VPRM实例 + 平滑 + 裁剪 │
└────────┬──────────────────────┘
▼
┌───────────────────────────────┐
│ 加载 Copernicus 地表覆盖图 │
└────────┬──────────────────────┘
▼
┌───────────────────────────────┐
│ 重投影到WRF网格 + 输出NetCDF │
└───────────────────────────────┘一、导入模块
python
import os
import pyVPRM
...- 基本库 :
os,glob,argparse,time,datetime,numpy,xarray,yaml - 遥感处理库 :
pyVPRM(自定义库,核心处理逻辑)、shapely,geopandas,pyproj - pyVPRM模块说明 :
sat_managers.modis: 读取 MODIS 数据sat_managers.viirs: 读取 VIIRS 数据sat_managers.copernicus: 读取 Copernicus 地表覆盖图lib.functions: 一些辅助函数,如经纬度转 MODIS tile 等VPRM.vprm_preprocessor: 主处理类,构建 VPRM 输入
二、命令行参数解析
python
p = argparse.ArgumentParser(...)
p.add_argument("--config", type=str)
p.add_argument("--year", type=int)
p.add_argument("--n_cpus", type=int, default=1)
p.add_argument("--chunk_x", type=int, default=1)
p.add_argument("--chunk_y", type=int, default=1)
args = p.parse_args()- 读取运行参数:
--config: YAML 配置文件路径--year: 处理哪一年的数据(如 2022)--n_cpus: 并行使用的 CPU 核心数--chunk_x,--chunk_y: 用于分块处理 WRF 网格(节省内存)
三、读取配置文件 + 创建输出目录
python
with open(args.config, "r") as stream:
cfg = yaml.safe_load(stream)- 读取 YAML 配置,包含:
- 输入路径(MODIS/VIIRS 数据、Copernicus 数据)
- 输出路径
- WRF 地理网格文件路径(geo_em.d0X.nc)
四、读取 WRF 网格并确定 MODIS Tiles
python
out_grid = parse_wrf_grid_file(cfg['geo_em_file'], ...)
hvs = np.unique([...lat_lon_to_modis(...)])- 使用
WRF geo_em 文件读取目标模拟区域的网格信息(lat/lon) - 利用
lat_lon_to_modis函数确定该区域覆盖的 MODIS tile 编号(h, v)
五、逐个 MODIS tile 加载数据
python
for i in hvs:
file_collections = glob.glob(...)
new_inst = vprm_preprocessor(...)
for fpath in file_collections:
handler = modis(...) 或 VIIRS(...)
handler.load()- 遍历每个 tile,对应的
.hdf文件逐个加载(MODIS 或 VIIRS) - 每个 tile 创建一个
vprm_preprocessor实例 - 加载遥感数据后,裁剪到 WRF 区域(使用 shapely
box及crop_box())
六、添加遥感数据到 VPRM 实例
python
new_inst.add_sat_img(...)- 添加遥感波段数据:
- MODIS:
b_nir,b_red,b_blue,b_swir - VIIRS: 波段命名不同
- MODIS:
- 自动计算 NDVI、EVI、LSWI 等植被指数
- 可选项:去除云、坏像元、裁剪波段
七、数据处理(时序平滑、裁剪)
python
new_inst.sort_and_merge_by_timestamp()
new_inst.lowess(...)
new_inst.clip_values(...)- 合并所有影像数据,按时间排序
- 使用 LOWESS 平滑(局部加权回归)对 EVI 和 LSWI 时间序列进行去噪
- 限定
evi和lswi的取值范围,移除异常值
八、添加土地覆盖图(Copernicus)
python
handler_lt = copernicus_land_cover_map(...)
handler_lt.load()
handler_lt.crop_to_polygon(...)
vprm_inst.add_land_cover_map(...)- 加载 Copernicus 地图(GeoTIFF 或 NetCDF)
- 对其裁剪到遥感图像覆盖区域
- 若土地覆盖图已存在,直接加载;否则重新生成并保存
九、将 VPRM 数据重投影到 WRF 网格
python
wrf_op = vprm_inst.to_wrf_output(out_grid, driver='xESMF', ...)- 使用 xESMF 进行网格重采样(卫星网格 → WRF 网格)
- 支持并行处理(但此处未启用 MPI)
十、保存为 NetCDF 文件
python
for key in wrf_op.keys():
wrf_op[key].to_netcdf(...)-
输出变量包括:
EVI,EVI_MAX,EVI_MINLSWI,LSWI_MAX,LSWI_MINVEG_FRA(植被覆盖率)
-
文件命名格式:
VPRM_input_<VAR>_<YEAR>_part_<chunk_x>_<chunk_y>.nc
十一、完成提示
python
print('Done. In order to inspect the output use evaluate_wrf_input.ipynb')- 提示用户使用 notebook 脚本进行可视化检查输出结果。
输出文件可视化
读取 VPRM 植被类别覆盖率
VPRM 类别(共 8 类;Function Types)
| VPRM类别编号 | 类别名称 | 描述 |
|---|---|---|
| 1 | Trees evergreen | 常绿树(全年绿色) |
| 2 | Trees deciduous | 落叶树(季节性掉叶) |
| 3 | Trees mixed | 混合林(常绿+落叶) |
| 4 | Trees and shrubs | 树木+灌木混合区 |
| 5 | Trees and grasses | 树木+草地混合 |
| 6 | Trees and crops | 树木+农作物混合 |
| 7 | Grasses | 草地或草原 |
| 8 | Barren, Urban, Snow, Ice | 荒地、城市、雪、冰 |
绘制的图形如下:

对应 Python 代码如下:
bash
import os
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from matplotlib.colors import LinearSegmentedColormap
# 设置字体
plt.rcParams['font.family'] = 'Times New Roman'
# VPRM 类别映射表(class_index 从 0 开始)
vprm_classes = {
0: "Trees evergreen",
1: "Trees deciduous",
2: "Trees mixed",
3: "Trees and shrubs",
4: "Trees and grasses",
5: "Trees and crops",
6: "Grasses",
7: "Barren, Urban, Snow, Ice"
}
def get_custom_colormap(class_index):
"""
根据植被类型返回对应的颜色映射。
"""
if class_index == 7:
# 第8类:白 -> 深黄
return LinearSegmentedColormap.from_list("yellow_map", ["white", "gold", "darkorange"])
else:
# 其余类型:白 -> 浅绿 -> 深绿
return LinearSegmentedColormap.from_list("green_map", ["white", "lightgreen", "darkgreen"])
def plot_variable(
data,
var_name,
lons,
lats,
output_path,
title='',
lon_range=(65, 100),
lat_range=(5, 40),
cmap=None
):
fig = plt.figure(figsize=(10, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.set_extent([*lon_range, *lat_range], crs=ccrs.PlateCarree())
ax.add_feature(cfeature.COASTLINE, linewidth=0.8)
ax.add_feature(cfeature.BORDERS, linestyle=':', linewidth=0.6)
ax.add_feature(cfeature.LAND, edgecolor='black', linewidth=0.3)
gl = ax.gridlines(draw_labels=True, linewidth=0.5, color='gray', alpha=0.5)
gl.top_labels = False
gl.right_labels = False
gl.xlabel_style = {'size': 13}
gl.ylabel_style = {'size': 13}
# 使用 xarray 方式裁剪区域
data_sub = data.where(
(data['lon'] >= lon_range[0]) & (data['lon'] <= lon_range[1]) &
(data['lat'] >= lat_range[0]) & (data['lat'] <= lat_range[1]),
drop=True
)
im = ax.pcolormesh(
data_sub['lon'],
data_sub['lat'],
data_sub,
cmap=cmap,
shading='auto',
vmin=0,
vmax=1
)
cbar = plt.colorbar(im, ax=ax, orientation='vertical', fraction=0.046, pad=0.04)
cbar.set_label("Fraction", fontsize=15)
cbar.ax.tick_params(labelsize=13)
plt.title(title, fontsize=16)
plt.savefig(output_path, dpi=500, bbox_inches='tight')
plt.close()
print(f"✅ Saved: {output_path}")
def plot_all_veg_classes(
file_path=r"D:\0 DataBase\WRF-VPRM\VPRM_input_VEG_FRA_2020.nc",
output_dir=r"D:\0 DataBase\WRF-VPRM\Figures",
lon_range=(65, 100),
lat_range=(5, 40)
):
os.makedirs(output_dir, exist_ok=True)
ds = xr.open_dataset(file_path)
var_name = [v for v in ds.data_vars if 'fraction' in v][0]
var = ds[var_name]
lons = ds['lon'].values
lats = ds['lat'].values
for class_index in range(var.shape[0]):
class_name = vprm_classes.get(class_index, f"Class {class_index + 1}")
data = var.isel(vprm_classes=class_index)
title = f"Vegetation Fraction | {class_name}"
filename = f"{os.path.splitext(os.path.basename(file_path))[0]}_{var_name}_c{class_index}.png"
output_path = os.path.join(output_dir, filename)
custom_cmap = get_custom_colormap(class_index)
plot_variable(
data=data,
var_name=var_name,
lons=lons,
lats=lats,
output_path=output_path,
title=title,
lon_range=lon_range,
lat_range=lat_range,
cmap=custom_cmap
)
# 执行
if __name__ == "__main__":
plot_all_veg_classes(
file_path=r"D:\0 DataBase\VPRM_input_VEG_FRA_2022.nc",
output_dir=r"D:\0 DataBase\WRF-VPRM\Figures",
lon_range=(-59.2, -58.7),
lat_range=(-2.4, -1.9)
)读取 VPRM 生成的 EVI、LSWI 指数文件
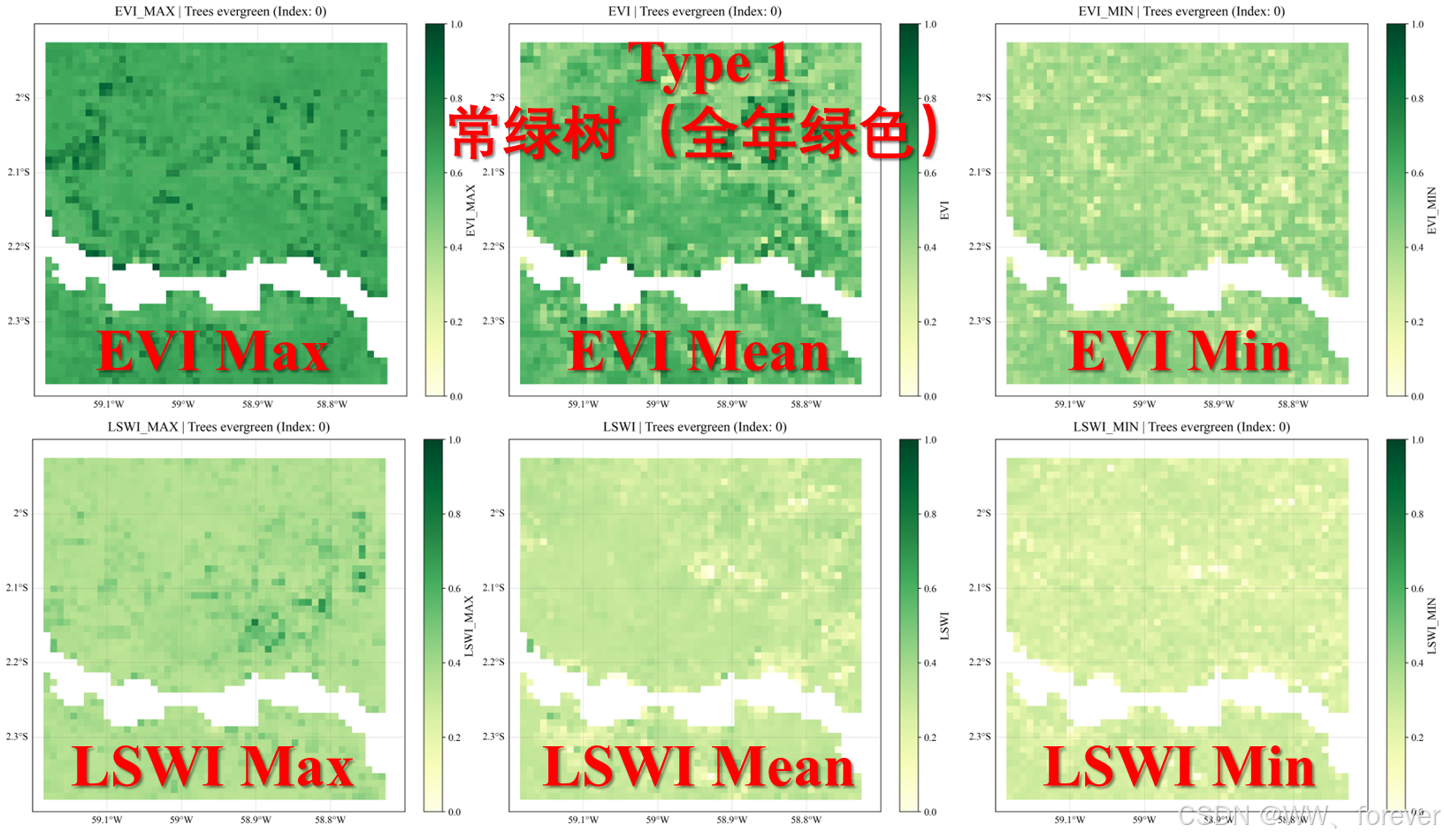
绘制以下三个变量的空间分布图(EVI / LSWI):
EVI,EVI_MAX,EVI_MINLSWI,LSWI_MAX,LSWI_MIN
每个文件都包含 8 个植被类别(vprm_classes) ,沿维度 vprm_classes。
绘制的图形如下:
对应 Python 代码如下:
bash
import os
import xarray as xr
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import numpy as np
# ================= 配置区域 =================
# 1. 设置输入输出路径
BASE_DIR = r"D:\0 DataBase\WRF-VPRM"
OUTPUT_DIR = r"D:\0 DataBase\WRF-VPRM\Figures"
# 2. 文件映射 (Key: 标识符, Value: 文件名)
FILE_MAP = {
"evi": "VPRM_input_EVI_2022_part_1_1.nc",
"evi_max": "VPRM_input_EVI_MAX_2022_part_1_1.nc",
"evi_min": "VPRM_input_EVI_MIN_2022_part_1_1.nc",
"lswi": "VPRM_input_LSWI_2022_part_1_1.nc",
"lswi_max": "VPRM_input_LSWI_MAX_2022_part_1_1.nc",
"lswi_min": "VPRM_input_LSWI_MIN_2022_part_1_1.nc",
}
# 3. 类别名称定义 (用于标题)
VPRM_CLASSES = {
0: "Trees evergreen",
1: "Trees deciduous",
2: "Trees mixed",
3: "Trees and shrubs",
4: "Trees and grasses",
5: "Trees and crops",
6: "Grasses",
7: "Barren/Urban/Snow"
}
# 4. 绘图设置
# 自定义绘制第几个 frame (对应类别索引 0-7)
TARGET_CLASS_INDEX = 0
# 经纬度范围 (West, East, South, North)
LON_RANGE = (-59.2, -58.7)
LAT_RANGE = (-2.4, -1.9)
# 字体设置
plt.rcParams['font.family'] = 'Times New Roman'
# ================= 功能函数 =================
def get_coord_names(ds):
"""尝试自动获取经纬度坐标的名称"""
lat_name, lon_name = None, None
# 常见命名列表
lat_candidates = ['lat', 'latitude', 'XLAT', 'XLAT_M']
lon_candidates = ['lon', 'longitude', 'XLONG', 'XLONG_M']
for lat in lat_candidates:
if lat in ds.coords or lat in ds.data_vars:
lat_name = lat
break
for lon in lon_candidates:
if lon in ds.coords or lon in ds.data_vars:
lon_name = lon
break
return lat_name, lon_name
def plot_vprm_variable(file_key, file_name, class_index, lon_range, lat_range):
file_path = os.path.join(BASE_DIR, file_name)
if not os.path.exists(file_path):
print(f"❌ File not found: {file_path}")
return
try:
with xr.open_dataset(file_path) as ds:
# 1. 动态获取主变量名 (假设文件中除经纬度时间外只有一个主变量)
# 排除常见的坐标变量名
exclude_vars = ['Times', 'vprm_classes', 'time', 'lat', 'lon', 'XLAT', 'XLONG']
data_vars = [v for v in ds.data_vars if v not in exclude_vars]
if not data_vars:
# 如果过滤太严格,回退到取第一个变量,或者尝试匹配文件名中的关键字
# 这里尝试匹配 file_key (如 evi)
candidates = [v for v in ds.data_vars if file_key.lower() in v.lower()]
if candidates:
var_name = candidates[0]
else:
var_name = list(ds.data_vars)[0] # 最后的手段
else:
var_name = data_vars[0]
da = ds[var_name]
# 2. 维度处理 (Time 和 Class)
# 处理 Time 维度
if "time" in da.dims:
da = da.isel(time=0)
# 处理 Class 维度 (vprm_classes)
# 注意:有些文件可能维度名叫 'vprm_classes',有些可能是 'z' 或其他,这里主要依赖名称
if "vprm_classes" in da.dims:
if class_index >= da.sizes['vprm_classes']:
print(
f"⚠️ Index {class_index} out of bounds for {file_key}. Max is {da.sizes['vprm_classes'] - 1}.")
return
da = da.isel(vprm_classes=class_index)
else:
# 尝试检查是否是第3维 (假设顺序是 time, class, lat, lon 或 class, lat, lon)
# 如果维度数量 > 2 (lat, lon),且没有显式的 vprm_classes
if len(da.dims) >= 3 and da.shape[0] == 8: # 假设8个类别
print(f"ℹ️ Implicit class dimension found for {file_key}, selecting index {class_index}")
da = da[class_index, :, :]
# 3. 坐标识别与裁剪
lat_name, lon_name = get_coord_names(ds)
if not lat_name or not lon_name:
print(f"❌ Could not identify lat/lon coordinates in {file_key}")
return
# 使用 where 进行裁剪 (比 sel 更通用,因为 WRF 可能是非规则网格)
# 注意:如果数据很大,这里可能会慢。对于规则网格可以用 .sel(lon=slice(...))
mask = (
(ds[lon_name] >= lon_range[0]) & (ds[lon_name] <= lon_range[1]) &
(ds[lat_name] >= lat_range[0]) & (ds[lat_name] <= lat_range[1])
)
# 提取数据值和坐标值用于绘图
# 注意:对于非规则网格,需要保留二维坐标
da_masked = da.where(mask)
# 为了绘图范围准确,我们需要裁剪掉全为 NaN 的边缘 (可选,但推荐)
# 这里简单处理:直接绘图,通过 set_extent 控制视野
# 4. 绘图
fig = plt.figure(figsize=(10, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.set_extent([lon_range[0], lon_range[1], lat_range[0], lat_range[1]], crs=ccrs.PlateCarree())
# 添加地图要素
ax.add_feature(cfeature.COASTLINE, linewidth=0.8)
ax.add_feature(cfeature.BORDERS, linestyle=':', linewidth=0.6)
# ax.add_feature(cfeature.LAND, edgecolor='black', linewidth=0.3, facecolor='none') # 可选
# 网格线
gl = ax.gridlines(draw_labels=True, linewidth=0.5, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False
gl.right_labels = False
gl.xlabel_style = {'size': 12, 'family': 'Times New Roman'}
gl.ylabel_style = {'size': 12, 'family': 'Times New Roman'}
# 绘制数据
# 使用 pcolormesh,注意 x 和 y 应该是二维的如果这是 WRF 输出
im = ax.pcolormesh(
ds[lon_name], ds[lat_name], da_masked,
cmap='YlGn',
shading='auto',
vmin=0, vmax=1, # EVI/LSWI 通常在 0-1 之间,可根据需要调整
transform=ccrs.PlateCarree()
)
# 色标
cbar = plt.colorbar(im, ax=ax, orientation='vertical', fraction=0.046, pad=0.04)
cbar.set_label(var_name.upper(), fontsize=14)
cbar.ax.tick_params(labelsize=12)
# 标题
class_name = VPRM_CLASSES.get(class_index, f"Class {class_index}")
title_str = f"{file_key.upper()} | {class_name} (Index: {class_index})"
plt.title(title_str, fontsize=16, pad=10)
# 保存
os.makedirs(OUTPUT_DIR, exist_ok=True)
save_name = f"{file_key}_class_{class_index}.png"
save_path = os.path.join(OUTPUT_DIR, save_name)
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"✅ Saved: {save_name}")
except Exception as e:
print(f"❌ Error processing {file_key}: {str(e)}")
import traceback
traceback.print_exc()
# ================= 主程序 =================
if __name__ == "__main__":
print(f"Starting plot generation for Class Index: {TARGET_CLASS_INDEX}")
print(f"Output Directory: {OUTPUT_DIR}")
for key, filename in FILE_MAP.items():
plot_vprm_variable(
file_key=key,
file_name=filename,
class_index=TARGET_CLASS_INDEX,
lon_range=LON_RANGE,
lat_range=LAT_RANGE
)
print("All tasks completed.")参考
1、GitHub 上的 Python 包 pyVPRM