在今天测试的时候,遇到了非常奇怪的问题。
之前的llama推理耗时40-50秒,而今晚的llama推理耗时580-590秒。

llama模型没变,adapter没变,代码没变,唯一的可能就是gpu。我只能怀疑是有什么进程在跑,和我抢占资源。
可是我不运行的时候,发现gpu几乎使用为0。也就说不太可能有其他人和我抢占资源。
我只能继续测试。
我开始运行llama。
实验室的server有4个24GB的gpu
bash
nvidia-smi
watch -n 1 nvidia-smi情况大致如下:
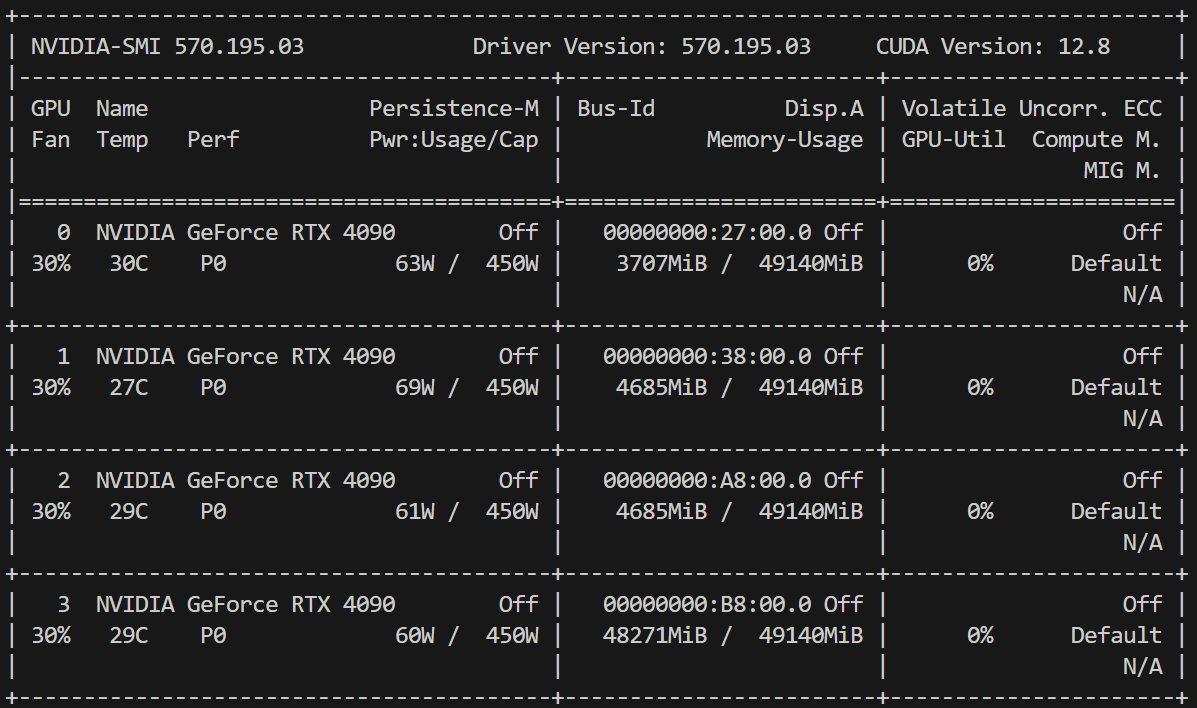
可以看到显存的分布情况是四个GPU都有,并且都占很少的显存。
然后我们发送prompt给llama,此时算力出现变化。
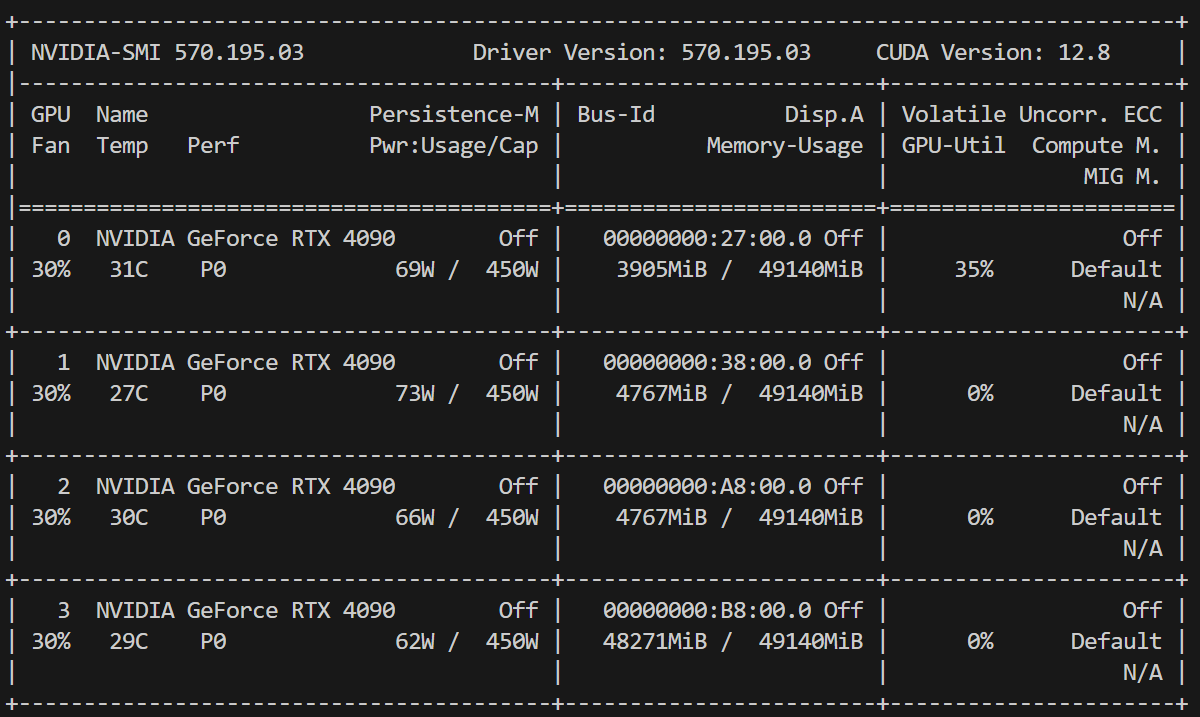
可以看见,虽然分散了,但是llama还是只在其中一个上运行,其他全部都算力为0,而第一个gpu的算力是34%-45%之间跳动。
这个时候的生成耗时为580秒。非常离谱
llama推理时间很慢的情况,网上没找到解决方案(因为我都不知道这样的问题该怎么搜索,除了当事人谁™遇到过这种操蛋事情),大模型也是啥都不知道。
首先怀疑llama是不是跑到cpu运行了(虽然也不太可能,因为cpu90%多idle)。
python
def check_device(self):
"""检查模型实际运行在哪里"""
import torch
print("\n" + "="*60)
print("🔍 设备检查")
print("="*60)
try:
# 检查模型
model = self.chat_model.engine.model
device = next(model.parameters()).device
print(f"📍 模型在: {device}")
if device.type == 'cpu':
print("⚠️⚠️⚠️ 警告:模型在CPU上运行! ⚠️⚠️⚠️")
else:
print(f"✅ 模型在 GPU {device.index} 上")
# 检查CUDA可用性
print(f"\n🎮 CUDA状态:")
print(f" - CUDA可用: {torch.cuda.is_available()}")
print(f" - CUDA版本: {torch.version.cuda}")
print(f" - GPU数量: {torch.cuda.device_count()}")
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
print(f" - GPU {i}: {torch.cuda.get_device_name(i)}")
print(f" 已用内存: {torch.cuda.memory_allocated(i)/1e9:.2f}GB")
except Exception as e:
print(f"❌ 检查失败: {e}")
print("="*60 + "\n")这个代码用来检测llama运行时的模型位置检测,并将这个测试代码的调用放在模型构建后。
python
self.chat_model = ChatModel(args)
print("✅ 模型加载完成!\n")
self.check_device() # 添加这行结果如下。
XML
- GPU 0: NVIDIA GeForce RTX 4090
已用内存: 3.27GB
- GPU 1: NVIDIA GeForce RTX 4090
已用内存: 4.42GB
- GPU 2: NVIDIA GeForce RTX 4090
已用内存: 4.42GB
- GPU 3: NVIDIA GeForce RTX 4090
已用内存: 3.09GB可以看到llama确实运行在gpu上,所以cpu猜想错误。
发给大模型,它认为可能是llama分散使用gpu导致运行效率低下。
于是想尝试之前学到的一个指令:
CUDA_VISIBLE_DEVICES
这个指令是能够直接屏蔽程序发现其他gpu,完全契合visble这个单词。
我输入指令
bash
CUDA_VISIBLE_DEVICES=1 python /root/llama_fine/llama_server.py当我使用了这个visible的时候,我发现cuda的时候情况变得很不一样。
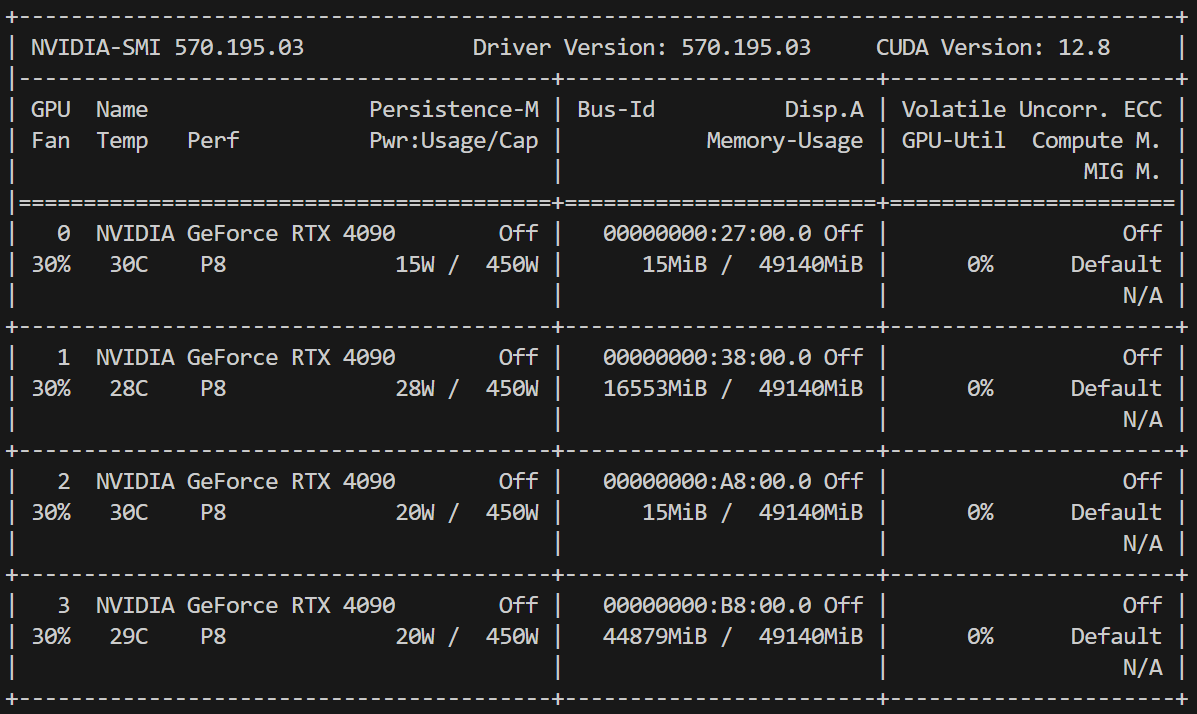
部分cuda的分布直接快接近0了。
而当我发送prompt给llama时,算力的变化尤其大。
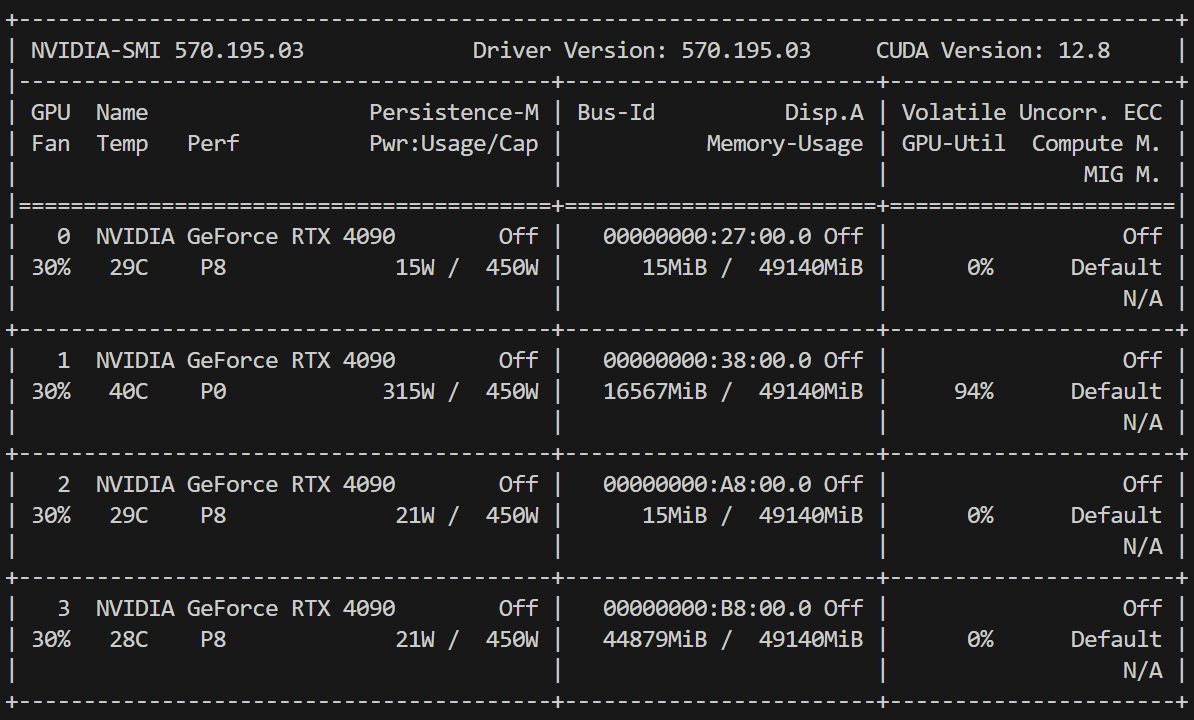
cuda 1的算力快被拉满了。 这是什么,这是希望啊卧槽。
因为算力才是影响快慢的关键,我直到现在也搞不清楚这太服务器的进程数量到底是如何影响算力的。明明cpu22核,为什么开16个进程的时候算力最高就30%的使用率了。这个90%多的算力使用率意味着------
同一个模型,同一个代码,同一个adapter,同一个prompt,运行时间天差地别。

比我之前40-50秒还快。
难道因为当时gpu都有人用,所以llama不得不集中在某几个cuda上,而现在没人和我抢,所以才快?
不理解。
这玩意也没有人开课,大模型也不懂,纯靠人工一个个试出来。