https://youtu.be/ZrpB0gLteUI?si=_HP-eNX0vB4DO-WV
00:00:01
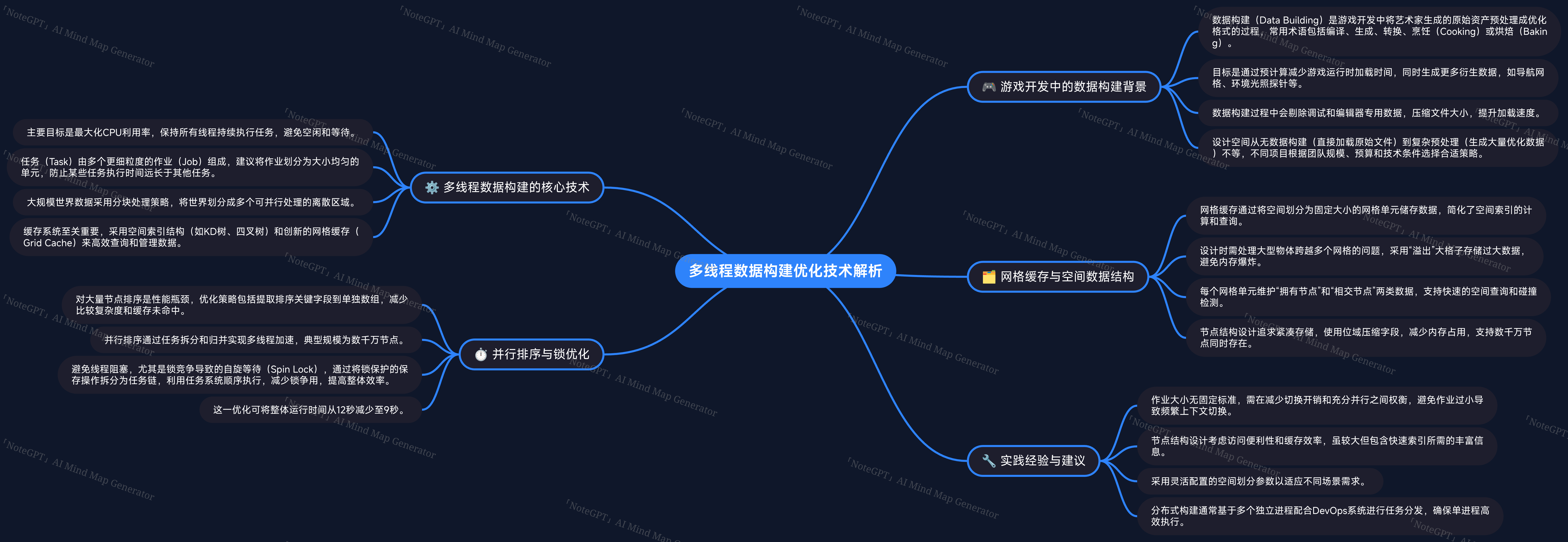
讲座主题与内容概览
本次讲座聚焦于游戏开发中多线程数据构建的优化技术,特别强调数据构建过程本身,而非图像、纹理转换等细节。讲者从事游戏开发多年,拥有丰富的C++及AAA级游戏行业经验,分享了针对游戏数据构建的实用方法与技术思路,涵盖从基础概念到具体实现的多个方面。
00:00:45
讲座结构
- 背景介绍:什么是游戏中的数据构建、与游戏代码的差异以及相关概念
- 技术讲解:具体优化技术及实现细节
- 问答环节及后续交流
00:01:18
讲者背景
- 编程起步于高中,2005年起专业从事C++开发
- 领域涵盖医疗设备、国防、Web开发等,2013年进入AAA游戏行业
- 本讲座内容基于个人经验和记忆,非特定公司立场
00:01:59
游戏数据构建定义
- 通常称为编译、生成或转换资产,游戏中常用"烘焙(cooking)"或"烘烤(baking)"术语
- 主要目标是提前计算游戏运行时需要的数据,提升加载速度和运行效率
- 过程包括从艺术家编辑数据生成更多派生内容(如导航网格、环境光探针、全局光照数据等)
- 优化数据,去除调试和编辑器专用内容,压缩成更高效的格式
- 过去还会针对硬盘和光盘的寻道时间优化数据排列,现因SSD普及此项需求大幅减少
00:04:05
数据构建设计空间
- 极简模式:无数据构建,直接加载原始文件(如PNG、FBX、JSON等),多见于独立游戏
- 极致优化模式:大量预处理生成高度优化格式,常见于大型AAA项目
- 折中方案:部分生成和压缩数据,结合团队资源、预算和技术需求灵活选择
00:05:25
游戏代码 vs 数据构建代码差异
- 游戏代码关注最小化帧时间,提高帧率和用户体验,避免帧间波动导致卡顿
- 数据构建通常在游戏启动前离线运行,关注减少总耗时以加快开发迭代速度
- 数据构建代码对并发和资源管理的需求与游戏运行时大不相同
00:06:43
复用游戏代码时的常见问题
- 单例模式、依赖帧处理逻辑、全局状态假设等设计不适用于数据构建环境
- 可能导致内存溢出、状态不一致、数据加载失败等问题
00:07:21
数据构建优化目标与策略
- 核心目标:最小化处理所需时间
- 仅构建必要数据,依赖检测不仅基于时间戳,还要基于文件内容哈希
- 多层缓存机制:程序内缓存和已构建内容缓存,避免重复生成
- 允许"作弊"策略:部分数据过期可暂时忽略,例如导航网格不即时更新,减少无谓重构
- 并行处理:充分利用多核CPU,保持线程和内存始终处于满载状态
00:09:50
讲座假设与环境说明
- 数据构建系统基于任务或作业(job/task)系统
- 运行环境为现代PC,内存和存储通常不是瓶颈(NVMe SSD普及)
- 示例使用16物理核心(32逻辑核心)、C++17/20标准
- 术语说明:job为最小不可再分单位,task为执行特定功能的job集合
00:11:13
优化技术之一:均衡作业大小保持线程忙碌
- 将任务拆分成大小均衡的作业,避免长任务阻塞
- 便于线程间均匀分配,减少等待和空闲时间
- 长函数需拆分成多个作业
00:12:32
大型开放世界数据构建策略
- 分块处理(Divide and Conquer):将大世界拆分为离散任务,实现并行处理
- 设计大型缓存避免各任务重复读取公共资源(如网格、光源、实体、音效发射器等)
- 不同区域数据量差异大,中心城市区域任务处理时间显著长于边缘区域
00:13:11
处理异常长任务的应对
- 某些任务可能异常耗时(数小时),原因包括数据错误、算法缺陷或代码bug
- 解决方法:预先生成并上传缓存数据,后续构建时直接下载使用,绕过耗时计算
00:15:15
缓存数据结构设计:网格缓存(Grid Cache)
- 采用空间划分的数据结构存储静态共享数据,支持快速查询
- 常用结构包括KD树、四叉树和八叉树
- 自创"网格缓存"结构:将数据分布到固定尺寸的多维格子中,非空格子存入映射表(flat_map或hash_map)
- 优点:简化数学逻辑,便于定位和查询元素
| 缓存结构 | 特点 | 适用场景 |
|---|---|---|
| KD树 | 轴向划分,适合高维空间 | 通用 |
| 四叉树 | 平面划分,适合较平坦的世界 | 多数开放世界地形 |
| 网格缓存 | 均匀划分空间,固定格子大小 | 高效快速查询,简化实现 |
00:19:53
大型元素处理策略
- 对于跨越过大区域的元素(如覆盖整个世界的光源),设定特殊"溢出格子"存储
- 避免因过度划分导致内存爆炸,提升缓存稳定性
00:21:29
网格缓存存储两类节点
- Owned Nodes:节点中心在格子内,适合划分任务和分桶处理
- Intersecting Nodes:节点包围盒与格子相交,适合几何查询如碰撞检测等
00:22:07
节点数据结构设计原则
- 节点数量庞大,需保证数据结构紧凑,避免无效填充
- 采用位域压缩字段,尽可能靠近32字节对齐以提升缓存效率
- 包含必要的定位、类型、资源引用等信息
00:23:30
节点排序优化
- 标准排序函数存在编译和运行性能瓶颈,尤其在调试模式下表现明显
- 优化方法:将复杂比较拆分成两步
- 关键字段内联比较快速判定排序结果
- 复杂字段通过函数调用延后处理
- 增加"排序顺序"字段保证完全相同元素的稳定排序
00:25:29
大量元素排序优化策略
- 数据规模达数千万节点,排序成本显著
- 优化方法:先抽取排序关键字段和原始索引构成小型数组排序,减少比较复杂度
- 排序完成后根据索引重排原数组,整体性能提升明显
00:29:52
并行排序性能分析
- 利用16核心CPU并行拆分排序任务,显著减少排序时间
- 线程数过多(如32线程)可能因硬件限制或调度瓶颈无明显加速
00:31:25
避免线程阻塞与锁竞争
- 阻塞式同步(互斥锁、Spin锁、IO阻塞)会导致线程闲置,降低资源利用率
- 隐藏锁(如日志、打印系统)也可能引发性能问题
- 解决方案:利用任务系统调度,将被保护操作拆分为依赖链任务,避免显式锁
00:33:00
案例分析:序列化操作引发Spin锁阻塞
- Spin锁导致所有线程忙等,CPU 100%占用但无实际进展
- 替换为互斥锁后CPU占用减少至单线程等待,但整体效率不佳
00:36:26
任务依赖链优化实践
- 将序列化操作封装为单独任务,依赖链确保串行执行
- 任务系统自动调度,无需显式锁保护节省大量等待时间
- 实际构建时间由12秒降至9秒,效率提升约25%
00:39:53
讲座总结
- 努力实现并行处理,保持线程持续忙碌
- 任务拆分均衡,避免长尾作业阻塞
- 广泛使用缓存,尤其针对大型开放世界
- 优化排序操作,减少数据访问和比较复杂度
- 避免线程阻塞,使用任务依赖链代替锁竞争
00:41:31
典型作业大小与调度策略
- 作业大小无严格限制,范围跨度从毫秒到数百秒不等
- 数据构建作业通常比游戏帧内作业更长,避免过短以减少调度开销
- 任务系统优先考虑多线程利用率,容忍一定调度开销
00:44:14
节点结构设计原因详解
- 节点结构较大(约128字节)因包含丰富信息(包围盒、变换矩阵、资源名称哈希、类型标识等)
- 设计为自包含,方便同一进程加载、查询及跨模块复用
- 分散存储(结构体数组)在多线程处理不同数据类型时更灵活
00:48:14
关于整除和位运算优化的讨论
- 索引计算采用整除和取模,存在性能开销
- 位移优化未广泛采用,因设计保持灵活,格子大小和数量可动态调整
- 讲者认同位运算可能提升性能,但受限于项目时间和需求
00:48:58
分布式计算与多机器构建
- 大规模构建任务曾在3040台机器集群上运行,耗时23天
- 设计目标是单机高效完成任务,分布式由构建系统调度管理,简化核心程序复杂度
00:50:44
空间划分设计原则补充
- 网格缓存以立方体为空间划分单位,尺寸为2的幂次方,且原点对称
- 这样设计简化数学运算和边界处理,避免偏移和特殊情况
00:51:24
结束感谢与问答环节总结
- 讲者对团队、配偶致谢
- 详细回答了关于作业大小、数据结构设计、性能优化等现场提问
- 通过真实案例和代码片段展示了多线程数据构建中的实用技巧与思考
总结:
本讲座深入探讨了游戏开发中多线程数据构建的关键技术,强调了任务拆分均衡、缓存设计、排序优化及锁竞争避免等方面的最佳实践。通过结合具体的架构设计与代码实现,提供了宝贵的经验和解决方案,适合从事大型游戏项目数据构建及性能优化的工程师参考学习。
视频大纲与内容总结
1. 引言与背景介绍
-
00:00:01 \~ 00:01:27
本次演讲主题是关于游戏开发中多线程数据构建的优化技术,重点聚焦于数据构建过程本身,而非图像、纹理等细节转换。演讲者强调其经验来自AAA级游戏开发,内容适合对大型游戏数据预处理感兴趣的听众。
-
00:00:45 \~ 00:01:50
演讲分为三大部分:背景介绍(解释游戏中的数据构建及其区别)、具体优化技术、最后是答疑环节。演讲者愿意在主讲结束后进行更深入的讨论。
-
00:01:18 \~ 00:02:40
演讲者个人背景:从高中开始编程,2005年起专业从事C++,跨足医疗设备、防务、网页开发等领域,2013年进入AAA游戏开发行业。演讲内容基于自身经验和记忆,非代表任何公司。
2. 数据构建的定义与重要性
-
00:01:59 \~ 00:04:10
数据构建(Data Building)也称为"编译"、"生成"或"烹饪(Cooking)",是预计算游戏运行时所需数据的过程。目的在于加快游戏加载速度,提升运行效率。数据构建会生成比原始艺术资源更多的内容,如导航网格(Nav Mesh)、环境探针、全局光照等辅助数据。
-
00:03:28 \~ 00:04:44
数据构建还会优化数据体积和结构,剔除调试信息,压缩格式,从而减少磁盘占用和加载时间。过去为了减少硬盘寻址时间,会对数据物理布局做优化,但SSD普及后寻址时间趋近于零,布局优化的重要性降低。
-
00:04:05 \~ 00:05:59
数据构建设计有一个光谱:从简单的无数据构建(直接加载原始资源,如png、fbx、json)到复杂的预处理(生成高度优化格式且数据量大)。多数游戏处于中间状态,结合生成和压缩。选择依据技术能力、团队规模和预算决定。
3. 游戏代码与数据构建代码的差异
-
00:05:25 \~ 00:07:22
游戏代码重点是减少单帧时间,提升帧率,避免帧时间峰值造成体验抖动。而数据构建代码运行在离线模式,目标是减少总耗时以加快开发迭代速度。
游戏代码假设帧循环存在,而数据构建不依赖帧概念,常遇到的问题包括错误假设游戏系统持续运行、内存溢出等。
-
00:06:43 \~ 00:08:42
优化数据构建的基本策略与编译优化类似:只构建必要内容,跟踪依赖(不仅时间戳还用内容哈希),多层缓存(内存和磁盘缓存)以避免重复构建。
游戏开发中也会"作弊",如允许设计师工作时数据不完全同步,只在必要时重新构建。
最重要的是多线程并行处理,保持CPU和内存利用率高。
4. 假设与技术背景
-
00:09:50 \~ 00:11:58
假设数据构建基于现代作业(job)或任务(task)系统,运行于具有多核CPU的现代PC,内存和存储不是瓶颈。演讲中使用16物理核心、32逻辑核心的家用电脑做示例。开发语言主要是C++17/20。
术语说明:Job是不可分割的最小工作单元,Task是由多个Job组成完成特定功能的集合。
5. 多线程优化技术
-
00:11:13 \~ 00:13:19
核心原则是保持所有线程忙碌且做有用工作,避免空转等待。通过将作业划分为大小均匀的Job,防止因某些任务过长导致线程阻塞。长任务需要拆分成多个Job。
大型开放世界构建需"分而治之",将地图划分为离散单元以便并行处理。构建大缓存避免重复读取公共资源。
某些任务可能异常漫长,需特殊处理,如预生成数据上传缓存,执行时直接下载跳过构建。
6. 缓存设计和空间查询结构
-
00:14:24 \~ 00:18:20
缓存存储静态数据,如网格、光源、实体和音频发射器。常用空间数据结构包括KD树、四叉树和八叉树。
演讲者提出了一种"网格缓存(Grid Cache)"新结构:将空间划分为固定大小的网格单元,元素分配到相应单元中,非空单元存储于映射结构(flat_map或hash_map)中。
选择数据结构时,flat_map适合内存紧张场合,hash_map则有更快的查找但更高内存开销。
该结构支持快速范围查询和大区域查询,且通过固定大小立方体简化计算。
-
00:19:10 \~ 00:22:45
设计中加入"大型网格单元"用于存放超大范围元素(如跨越整个世界的光源),避免内存爆炸。
网格单元内部同时维护"拥有节点"(节点中心在单元内)和"交叉节点"(节点与单元边界相交),分别支持不同的几何查询需求。
节点设计紧凑,利用位域和压缩技术减少内存占用,因节点数量巨大,节省内存十分关键。
7. 排序优化
-
00:23:30 \~ 00:29:18
节点排序是数据构建中频繁操作,排序算法开销大。使用标准排序(std::tie)存在编译和运行时效率问题。
优化方法是将排序关键字段提取到单独数组,先对该数组排序,再根据排序结果重排列主数组。这样简化比较函数,减少内存访问,提高缓存命中率。
此方法大幅减少排序时间,尤其是在处理千万级节点时效果显著。
演示了用16核机器进行并行排序的性能提升,对比图显示优化后排序时间几乎减半。
8. 避免线程阻塞与锁竞争
-
00:31:25 \~ 00:39:06
避免使用阻塞同步机制(如互斥锁mutex、旋转锁spinlock),因为它们会导致线程等待,浪费CPU资源,降低整体并行效率。
举例说明spinlock导致的CPU资源浪费,所有线程忙等待锁释放,造成"CPU满载却无有效工作"现象。
将spinlock替换为mutex后,虽然CPU占用降低,但仍有线程阻塞,造成等待。
最佳方案是利用作业系统的依赖调度机制,拆分任务,将串行部分作为单独作业依赖链处理,彻底避免锁竞争。
这样做后,CPU利用率高且无阻塞,整体构建时间缩短约25%。
9. 演讲总结
-
00:39:53 \~ 00:41:25
总结主要优化思路: - 尽可能并行处理所有任务,保持线程高效利用。
- 任务大小均匀,避免长短不一导致负载不平衡。
- 大量使用多级缓存,提升数据访问速度。
- 设计高效空间缓存结构(如网格缓存)加速查询和处理。
- 减少排序数据量,提升排序效率。
- 避免线程阻塞和锁竞争,利用作业系统调度解决同步问题。
感谢团队和家人的支持。
10. 问答环节亮点
-
00:41:31 \~ 00:44:15
关于作业大小:没有严格标准,长度从数毫秒到数百秒不等。太小任务频繁切换带来高开销,太大任务影响并行度。一般数据构建任务较游戏运行时任务更大。 -
00:44:14 \~ 00:48:55
关于空间节点结构较大:节点包含丰富信息(包围盒、变换矩阵、资源名称哈希、类型、指针等),以支持快速查找和多种查询需求。虽然结构较"胖",但减少索引查找带来的复杂性。多类型任务同时进行时,统一结构简化管理。 -
00:48:14 \~ 00:50:07
关于整数除法和取模的优化:出于灵活配置和时间压力,未使用位运算优化。设计中网格大小为立方体且边长为2的幂次方,简化数学计算。 -
00:48:58 \~ 00:50:38
关于为何不采用分布式构建:本地多线程处理简单且可重复运行,分布式部分由构建系统调度多台机器执行独立任务,数据汇总由DevOps负责,避免复杂分布式开发工作。 -
00:50:44 \~ 00:52:06
关于网格缓存设计细节:设计注重简化数学运算,立方体边长为2的幂次方,方便计算和坐标对齐。
总结
本演讲系统介绍了游戏开发中多线程数据构建的背景、挑战与优化技术,涵盖:
- 数据构建的定义与作用
- 与游戏代码的区别与设计思路
- 多线程作业划分和负载均衡
- 创新空间缓存结构(网格缓存)
- 大规模数据排序优化
- 避免线程阻塞和锁竞争的实践
- 作业大小选择和系统架构考量
演讲结合实战经验和代码示例,详细讲解如何在现代硬件和作业系统基础上显著提升游戏数据构建效率,适合游戏开发者和系统工程师深入学习借鉴。