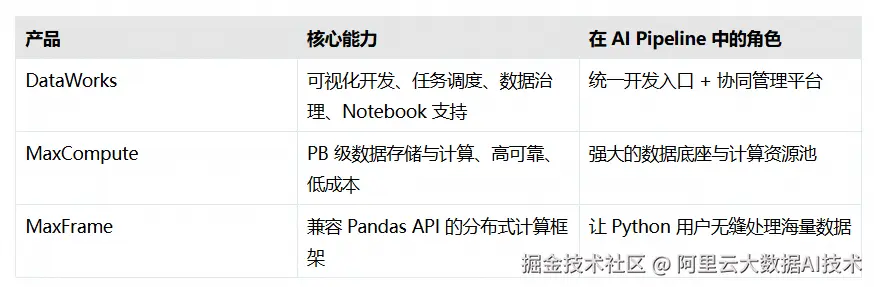
在大模型与 AI 应用快速落地的今天,企业对"数据准备 → 数据处理 → 模型训练"的端到端效率提出了更高要求。阿里云数据开发治理平台 DataWorks 联合云原生大数据计算服务 MaxCompute,为您提供一套开箱即用、安全合规、弹性可扩展的 AI 数据开发环境,特别适合需要处理 TB/PB 级结构化、半/非结构化数据的 AI 工程师、数据科学家与算法团队。
本文将带您快速了解如何基于阿里云两大核心产品------DataWorks(大数据开发与治理平台)、MaxCompute(云原生大数据计算服务)以及MaxFrame(分布式Python计算框架)------ 高效搭建一个支持 Notebook 交互式开发、任务调度与大规模并行计算的一体化 AI 数据处理环境。
为什么选择这套组合?
优势总结:
-
无需自建集群:全托管服务,分钟级开通
-
开发体验友好:Jupyter Notebook 风格,支持 Magic Command 快速连接计算资源
-
安全合规:天然集成 RAM 权限体系、VPC 网络隔离、敏感信息加密
-
成本可控:按量付费 + 包年包月,适合测试与生产混合场景
环境搭建四步走(核心流程)
虽然底层涉及多个服务联动,但对用户而言,只需完成以下四个关键步骤,即可进入开发状态:
第一步:开通 MaxCompute 项目
作为计算与存储的核心,MaxCompute 项目是所有数据作业的资源底座。
-
选择与业务一致的地域(如华东2-上海)
-
推荐使用按量付费模式(新用户可享受免费额度)
-
项目名称建议包含业务标识(如
ai_dedup_01),便于后续管理
第二步:创建 DataWorks 工作空间
DataWorks 提供从开发到运维的完整工具链。
-
选择基础版即可满足 Notebook 开发需求(免费)
-
创建通用型资源组(按量付费),并绑定VPC网络(若需访问 OSS、PAI 等内网服务)
-
指定空间管理员,并添加团队成员(支持 RAM 子账号)
建议开启"新版数据开发(Data Studio)",获得更流畅的 Notebook 体验。
第三步:绑定计算资源
将 MaxCompute 项目"绑定"到 DataWorks 工作空间,实现开发与计算的打通。
-
在工作空间管理页中,一键绑定已创建的 MaxCompute 项目
-
选择合适的资源组(用于任务调度与 Notebook 执行)
-
测试连通性,确保权限与网络配置正确
安全提示:建议使用"阿里云主账号"作为默认执行身份,避免权限不足问题。
第四步:启动个人开发环境
这是您编写代码的"云端工作站"。
-
在 Data Studio 中新建一个个人开发环境实例
-
选择 CPU 规格(如 4 vCPU / 16 GiB)和预置镜像(如 dataworks-maxcompute:py3.11-ubuntu20.04:py3.11-ubuntu20.04-202504-1)
-
实例启动后,即可在 Notebook 中直接连通 MaxFrame 进行分布式计算
注意:实例按CU*时长计费,不使用时请手动停止,避免产生额外费用。
开始开发:用 MaxFrame 处理海量数据
一切就绪后,您可以在 Notebook 中像写 Pandas 一样处理亿级数据:
ini
import maxframe.dataframe as md
import pyarrow as pa
import pandas as pd
from maxframe.lib.dtypes_extension import dict_
# 初始化 MaxFrame 会话(通过 Magic Command 自动连接 MaxCompute)
mf_session = %maxframe
# 构造 DataFrame(实际数据可来自 MaxCompute 表)
col_a = pd.Series(
data=[[("k1", 1), ("k2", 2)], [("k1", 3)], None],
index=[1, 2, 3],
dtype=dict_(pa.string(), pa.int64()),
)
col_b = pd.Series(
data=["A", "B", "C"],
index=[1, 2, 3],
)
df = md.DataFrame({"A": col_a, "B": col_b})
df.execute()
# 自定义函数
def custom_set_item(df):
for name, value in df["A"].items():
if value is not None:
df["A"][name]["x"] = 100
return df
# 调用 apply_chunk 执行分布式计算
result_df = df.mf.apply_chunk(
custom_set_item,
output_type="dataframe",
dtypes=df.dtypes.copy(),
batch_rows=2,
skip_infer=True,
index=df.index,
).execute().fetch()
print(result_df)亮点功能:
-
使用
%maxframeMagic Command,无需明文 AccessKey,快捷连通目标计算资源 -
输出中包含 Logview 链接,一键查看作业 DAG、耗时、失败原因
-
支持将结果写回 MaxCompute 表或导出至 OSS,无缝衔接下游模型训练
最佳实践建议
为了让您的开发更高效、更稳定,推荐关注以下几点:
1. 善用 Logview 2.0
每次执行都会生成可视化作业追踪链接,帮助快速定位性能瓶颈或错误根源。
2. 合理配置资源配额
通过设置 options.session.quota_name 指定后付费/预付费 Quota,按业务需求灵活选择。
3. 敏感信息统一管理
在 DataWorks 工作空间参数中配置 AK/SK 或数据库密码,代码中通过 ${workspace.工作空间参数名} 引用,杜绝明文泄露。
4. 利用数据地图做元数据治理
DataWorks 自动同步 MaxCompute 表结构,支持血缘分析、表预览、生命周期管理,提升团队协作效率。
常见问题快速排查
-
Q:Notebook 中查不到 MaxCompute 表?
A:确认 MaxCompute 项目已绑定到当前 DataWorks 工作空间,并检查账号是否有读权限;可在"数据地图"中手动刷新元数据。
-
Q:无法读写 OSS 数据?
A:确保 RAM 用户拥有对应 Bucket 的读写权限,且个人开发环境实例(开发环境)和通用型资源组(生产环境)与 OSS 在同一 VPC 内(或已配置公网访问)。
下一步行动
现在,您已经拥有了一个安全、弹性、高性能的 AI 数据处理平台。无论是进行数据去重、特征打标、日志清洗,还是为大模型准备高质量训练语料,这套组合都能为您提供强大支撑。