在 https://huggingface.co/models 中有很多模型。一般会将此类模型转换为onnx,然后通过OpenCV DNN、ONNX Runtime等供项目调用。
这里以目标检测模型facebook/detr-resnet-50为例,给出将其转换为onnx的过程。
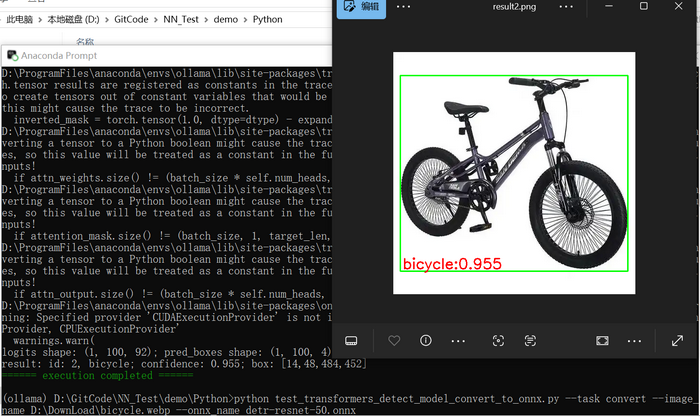
以下是通过facebook/detr-resnet-50模型直接进行推理的实现:
python
def inference(pretrained_model, image_name, threshold):
model = AutoModelForObjectDetection.from_pretrained(pretrained_model)
processor = AutoImageProcessor.from_pretrained(pretrained_model)
bgr = cv2.imread(image_name)
if bgr is None:
raise FileNotFoundError(colorama.Fore.RED + f"unable to load image: {image_name}")
rgb = cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)
inputs = processor(images=rgb, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([rgb.shape[:2]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=threshold)
result = results[0] # single image
for score, label, box in zip(result["scores"], result["labels"], result["boxes"]):
box = [int(i) for i in box.tolist()] # boxes are the original image size
print(f"result: id: {label}; label: {model.config.id2label[label.item()]}; confidence: {round(score.item(), 3)}; box: {box}")
cv2.rectangle(bgr, (box[0], box[1]), (box[2], box[3]), (0,255,0), 2)
cv2.putText(bgr, f"{model.config.id2label[label.item()]},{round(score.item(), 3)}", (box[0]+2, box[3]-2), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0,0,255), 2)
cv2.imwrite("../../data/result.png", bgr)以上是直接使用transformers中的类AutoModelForObjectDetection和AutoImageProcessor,执行结果如下图所示:
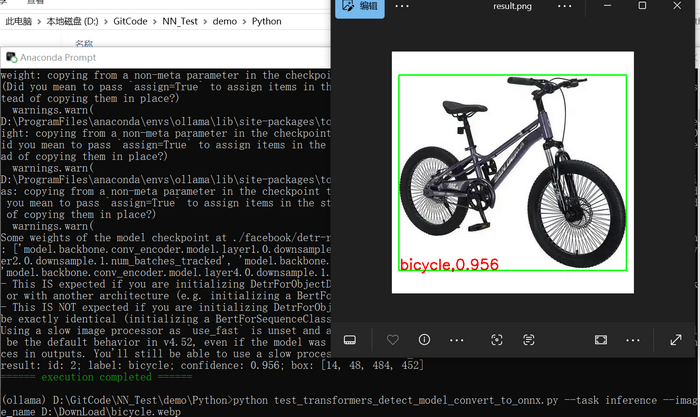
以下是将原始模型转换为onnx,然后调用onnx进行预测的实现:
python
def _letterbox(img, image_size):
original_shape = img.shape[:2] # h,w
target_shape = [image_size, image_size]
scale = min(target_shape[0] / original_shape[0], target_shape[1] / original_shape[1])
new_unpad = int(round(original_shape[1] * scale)), int(round(original_shape[0] * scale))
dw, dh = target_shape[1] - new_unpad[0], target_shape[0] - new_unpad[1]
dw /= 2
dh /= 2
x_offset = int(dw)
y_offset = int(dh)
if original_shape[::-1] != new_unpad:
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
return img, original_shape, target_shape, x_offset, y_offset, scale
def _str2tuple(value):
if not isinstance(value, tuple):
value = ast.literal_eval(value) # str to tuple
return value
def _preprocess(image_name, image_size, mean, std):
bgr = cv2.imread(image_name)
if bgr is None:
raise FileNotFoundError(colorama.Fore.RED + f"unable to load image: {image_name}")
bgr, original_shape, target_shape, x_offset, y_offset, scale = _letterbox(bgr, image_size)
rgb = cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)
mean = _str2tuple(mean)
std = _str2tuple(std)
blob = (rgb / 255.0 - mean) / std
blob = blob.transpose(2, 0, 1) # (h,w,c) --> (c,h,w)
blob = np.expand_dims(blob, axis=0).astype(np.float32)
return blob, original_shape, target_shape, x_offset, y_offset, scale
def _postprocess(logits, pred_boxes, threshold, original_shape, target_shape, x_offset, y_offset, scale):
probs = torch.softmax(torch.from_numpy(logits[0]), dim=-1)
boxes = pred_boxes[0]
scores = []
filtered_boxes = []
class_ids = []
for i in range(boxes.shape[0]):
max_prob, class_id = torch.max(probs[i, :-1], dim=0) # :-1 : remove no-object
if max_prob > threshold:
cx, cy, w, h = boxes[i]
cx = cx * target_shape[1]
cy = cy * target_shape[0]
w = w * target_shape[1]
h = h * target_shape[0]
x1 = cx - w / 2
y1 = cy - h / 2
x2 = cx + w / 2
y2 = cy + h / 2
x1 = max(0, x1 - x_offset)
y1 = max(0, y1 - y_offset)
x2 = max(0, x2 - x_offset)
y2 = max(0, y2 - y_offset)
x1 = x1 / scale
y1 = y1 / scale
x2 = x2 / scale
y2 = y2 / scale
x1 = max(0, min(x1, original_shape[1]))
y1 = max(0, min(y1, original_shape[0]))
x2 = max(0, min(x2, original_shape[1]))
y2 = max(0, min(y2, original_shape[0]))
if x2 > x1 and y2 > y1:
scores.append(float(max_prob))
filtered_boxes.append([x1, y1, x2, y2])
class_ids.append(int(class_id))
if not scores:
return [], [], []
scores = np.array(scores)
filtered_boxes = np.array(filtered_boxes)
class_ids = np.array(class_ids)
boxes_xywh = []
for box in filtered_boxes:
x1, y1, x2, y2 = box
boxes_xywh.append([x1, y1, x2 - x1, y2 - y1])
boxes_xywh = np.array(boxes_xywh)
indices = cv2.dnn.NMSBoxes(
bboxes=boxes_xywh.tolist(),
scores=scores.tolist(),
score_threshold=threshold,
nms_threshold=0.5
)
if len(indices) == 0:
return [], [], []
if hasattr(indices, 'shape'):
indices = indices.flatten()
return boxes_xywh[indices], scores[indices], class_ids[indices]
def convert(pretrained_model, image_name, threshold, onnx_name, image_size, mean, std):
class_names = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'street sign',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'hat', 'backpack',
'umbrella', 'shoe', 'eye glasses', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'plate', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'mirror', 'dining table', 'window',
'desk', 'toilet', 'door', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'blender',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
model = AutoModelForObjectDetection.from_pretrained(pretrained_model)
model.eval()
dummy_input = torch.randn(1, 3, image_size, image_size)
torch.onnx.export(
model,
dummy_input,
onnx_name,
export_params=True,
opset_version=17,
do_constant_folding=True,
input_names=["pixel_values"],
output_names=["logits", "pred_boxes"],
dynamic_axes={
"pixel_values": {0: "batch_size"},
"logits": {0: "batch_size"},
"pred_boxes": {0: "batch_size"},
}
)
blob, original_shape, target_shape, x_offset, y_offset, scale = _preprocess(image_name, image_size, mean, std)
session = ort.InferenceSession(onnx_name, providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: blob})
logits = outputs[0]
pred_boxes = outputs[1]
print(f"logits shape: {logits.shape}; pred_boxes shape: {pred_boxes.shape}")
boxes, scores, class_ids =_postprocess(logits, pred_boxes, threshold, original_shape, target_shape, x_offset, y_offset, scale)
bgr = cv2.imread(image_name)
for _, (box, score, class_id) in enumerate(zip(boxes, scores, class_ids)):
if class_id < len(class_names):
label = class_names[class_id]
else:
raise ValueError(colorama.Fore.RED + f"id out of bounds: {class_id}:{len(class_names)}")
x1, y1 = int(box[0]), int(box[1])
x2, y2 = int(box[0] + box[2]), int(box[1] + box[3])
print(f"result: id: {class_id}, {label}; confidence: {score:.3f}; box: [{x1},{y1},{x2},{y2}]")
cv2.rectangle(bgr, (x1, y1), (x2, y2), (0,255,0), 2)
cv2.putText(bgr, f"{label}:{score:.2f}", (x1+5, y2-5), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0,0,255), 2)
cv2.imwrite("../../data/result2.png", bgr)注:
-
前处理(_preprocess)和后处理(_postprocess)需要自己实现。
-
使用PyTorch中的torch.onnx.export转换为onnx。
-
不能使用OpenCV DNN,因为其不支持facebook/detr-resnet-50中的Resize算子。
-
以上代码中给出的class_names要与facebook/detr-resnet-50中config.json给出的id2label保持一致。
-
在_postprocess函数中要注意max_prob, class_id = torch.max(probsi, :-1, dim=0)语句,需要是torch.max(probsi, :-1, dim=0),而不能是torch.max(probsi, dim=0),需要移除"N/A"。
支持的输入参数如下:
python
def parse_args():
parser = argparse.ArgumentParser(description="transformers train object detect test code")
parser.add_argument("--task", required=True, type=str, choices=["inference", "convert"], help="specify what kind of task")
parser.add_argument("--pretrained_model", type=str, default="./facebook/detr-resnet-50", help="pretrained model loaded during training")
parser.add_argument("--image_name", type=str, help="image name")
parser.add_argument("--image_size", type=int, default=800, help="image sizes supported by network")
parser.add_argument("--mean", type=str, default="(0.485,0.456,0.406)", help="image mean")
parser.add_argument("--std", type=str, default="(0.229,0.224,0.225)", help="image standard deviation")
parser.add_argument("--threshold", type=float, default=0.9, help="threshold")
parser.add_argument("--onnx_name", type=str, help="input/output onnx name")
args = parser.parse_args()
return args执行结果如下图所示:检测位置与原始模型推理结果相同