去年的今天,我还在奋笔疾书地写着 VS Code + Roo Cline 的评测心得:个人评测 | Cursor 免费平替:Roo Cline + DeepSeek-v3/Gemini-2.0 + RepoPrompt AI 辅助编程 。当时的我没有想过:在 2025 年, Roo Cline 会被我迅速淘汰,我也成为了 Cursor 这类 Vibe Coding 工具的稳定用户之一。
站在 2026 年伊始的节点上,审视自己的工作流,发现已经完全被锚定在了如下工具链上:
- 对话工具: ChatGPT 5.2 + Gemini 3 Pro
- Vibe Coding : 工作用 Cursor ,个人学习用 Trae 国际版 + CodeX ,辅以 VS Code + GitHub Copliot
其中我仅为 ChatGPT 和 Trae 付过费( ChatGPT 赠送 CodeX 订阅), GitHub Copliot 使用的免费额度(每个月可调用次数不多)。
本文中,我把 2025 年一年的经验总结成十条,希望能够引起讨论,共同交流学习。
(一)聊天 AI 没有被淘汰,某些情况下,它们更好用
很多朋友在拿到 Cursor 或 Trae 这种 IDE 后,容易养成一种习惯:一头扎进具体的代码文件中,试图用 Tab 和 CMD+K 解决所有问题。但经过这一年的实践,我发现网页版的聊天型 AI 和 IDE 调用的 API 模型是有本质区别的。
首先是模型的可控性。IDE 接入的模型往往为了代码生成做过微调,但在逻辑深度上,ChatGPT 5.2 的 Thinking Extended Thinking 模式或者 Gemini 3 Pro 的推理模式,显然比 Cursor 的 Agent 更加深思熟虑。
更关键的是上下文的管理。当你需要进行宏观架构设计时,IDE 的 RAG 检索有时会显得过于碎片化。我的做法是,利用 git archive --format=zip HEAD -o project.zip 将项目打包。这个命令的好处在于它只打包 Git 追踪的文件,自动排除了 node_modules 和临时数据。把这个压缩包扔给 ChatGPT,它现在的虚拟机能力非常强,可以自行解压、有选择地阅读文件。
相比于在 IDE 里敲敲打打,ChatGPT 这类工具更适合做"顶层设计"。比如技术选型和开发路线制定,它的 Web Searching 能力比 IDE 的 Agent 更广更深;再比如项目初始化,你可以直接让它生成一个包含完整目录结构的 zip 包,甚至顺便画出 mermaid 流程图。
而在数学计算和复杂算法推导上,聊天 AI 更是降维打击。我自己研究油气管道调度问题时,就常把原始数据打包上传,利用 ChatGPT 的超长思考时间,结合"分支聊天"策略,同时探索整数规划、动态规划和强化学习三条路线。这种工程实践的第一步,目前的 IDE 还做不到这么好。
(二)善于使用 workspace 概念,不要浪费类 Cursor 工具的 RAG index
Cursor 和 Trae 这类工具的核心优势在于云端索引(Index)。简单来说,它们把你的代码"读"了一遍并建立了一个向量数据库。这意味着在 Agent Chat 中,你不需要笨拙地把第 1 行到第 50 行代码复制进去,只需 @ 一下相关文件,Agent 就能通过索引理解上下文,既高效又节省 tokens。
但在 Cursor / Trae 似乎忽略了 VS Code 祖传的 workspace 功能,导致 IDE 无法理解多模块项目的关系。Cursor 如果找不到明确的 root 目录,搜索和索引的效果就会大打折扣。
我现在的习惯是构建一个"手动的 workspace"。即使是前后端分离的项目,我也会把它们放在同一个目录下,比如创建一个 _workspace 文件夹,里面包含 .cursorrules、frontend、backend 和 openapi 目录。
不要单独打开 frontend 写前端,直接用 Cursor 打开 _workspace。这样在进行前后端联调时,Cursor 能够同时索引两端的代码,理解接口定义和业务逻辑的关联。你可以在 .cursorrules 中明确这是一个 monorepo,告诉 AI 前端用 pnpm,后端用 Python 3.12,甚至写明"调试前请运行 source ./backend/env/bin/activate"。这些环境上下文的注入,能让 AI 少问很多傻问题,极大地提升一次性代码通过率。
(三)MCP 、 Rule 还是 Skill ?模型越来越强,这类技术在被淘汰,适合项目的才是最好的
记得 2024 年末,MCP(Model Context Protocol) 概念火得一塌糊涂。而现在, Claude 也在推广 Skill 。但到了现在,你会发现这些复杂的技巧正在被边缘化。本质原因是模型本身变强了,强到不再需要那么多拐杖。
MCP 虽然可以安全地连接数据库(比如限制只读权限等等),但配置起来依然繁琐,且生态本身的安全性也并非无懈可击。数次尝试后,我发现最朴素的方案反而是最有效的:让 AI 基于你的业务代码,写一套 Python 或 Shell 脚本工具。
比如,与其配置复杂的 MCP 去查询订单,不如让 AI 写一个 scripts/get_order_info.py。这样做的好处显而易见:你自己能用,AI 也能用。当你需要进行复杂测试时,直接告诉 AI:"你可以并行调用 scripts/send_test_orders.py 和 scripts/listen_mock_executions.py"。这其实就是一种定制化的、低成本的 MCP,而且完全掌握在你自己的代码仓库里。当然,记得在运行前检查一下 AI 生成的脚本,安全意识不能丢。
(四)给出具体的任务, AI 不是我们偷懒的借口,而是我们效率的乘数
分享一个真实的翻车案例:前段时间有朋友把一份 Word 格式的简历扔给 Cursor,模型选的 Claude Opus 4.5,只给了一句指令:"帮我转成 HTML"。
结果 AI 搞得一团糟。因为它不理解这个 HTML 是要用来做静态展示,还是要部署到某个具体服务中。为了"完成任务",AI 甚至不知道从哪搞来了一个公有云对象存储的 Token ,把简历里的照片上传到了某个不知名的 OSS 上,想删都删不掉,简直令人啼笑皆非。
这个教训告诉我们,AI 只是工具,决策还得靠人。正确的方式应该是先明确需求:这个 HTML 要放在哪里?是单页静态应用还是嵌入式组件?然后,利用 PLAN 模式或者先问 Chat AI:"我想把 Word 转 HTML,目前有哪些成熟工具?latex2html 还是 pandoc?或者先转 Markdown 再生成 HTML?"
当我们明确了技术路径(比如 Word -> Markdown -> HTML)后,再让 IDE 去执行。AI 是我们效率的乘数,它能把 1 变成 100,但如果我们给出的基数是 0 甚至负数(错误的决策),那结果只能是灾难。Cursor 的 PLAN 模式和 Trae 的 SOLO 模式(生成 .docs/xxx.md)都是很好的辅助思考工具,别为了省事直接蛮干。
(五)不要过度提示,你说的每个字 AI 都很上心
在 Prompt Engineering 刚兴起时,我们习惯写一大堆提示词。但在 2025 年,面对更聪明的模型,过度提示反而成了累赘。
比如在中文语境下,我看到很多人喜欢在结尾加一句"请结合上下文修改代码"。这对人类来说是一句废话,但对 AI 来说可能是个干扰。它可能会死板地理解为"结合上面的代码和下面的代码",然后去运行 grep -C 10 强行读取代码的物理上下行,反而忽略了原本高效的 RAG 索引逻辑。
现在的模型已经足够智能,能理解你的意图。简洁、清晰地描述需求,往往比堆砌"提示词魔法"效果更好。说得越多,模型"幻觉"的空间反而越大。
(六)提供充足的 context ,还包括操作系统环境和命令行日志
虽然我们不该啰嗦,但在提供客观事实(Context)上,一定要大方。很多时候 AI 写出的代码跑不通,是因为它根本不知道你在什么环境下运行。
我有一个习惯,在开启复杂任务前,会先把终端里的环境信息甩给它:
bash
uname -a
cat /etc/os-release
# 如果有报错日志
tail -20f /tmp/dev/server-error.log将这些 Terminal 的输出直接粘贴到 Chat 框里,几乎不费什么功夫,消耗的 token 也可以忽略不计,但这对 AI 来说是极其关键的"地面实况"。
虽然 Cursor 宣称会读取 Terminal 输出,但具体的读取时机和触发规则是个黑盒。与其猜它读没读,不如主动喂给它。特别是在处理编译错误或环境依赖问题时,一份完整的日志远比你描述"它报错了"要管用一万倍。
(七)没有一蹴而就,别人的 rule / prompt 可能并不适合你
网上流传着各种"神级 Prompt"和"万能 Rule",但我建议你谨慎复制。模型在进化,工具在迭代,上个月好用的技巧,下个月可能就因为模型权重调整而失效了。
Rule 并不是越复杂越好。你没必要在 Rule 里把常识再强调一遍,比如写上"使用 pnpm 管理项目"就足够了,不需要再废话一句"具体命令请参考 package.json",模型都懂。
更重要的是,如果你想教会 AI 使用某种内部框架,与其在 Rule 里用自然语言喋喋不休,不如直接把框架的核心代码放进 workspace 里,让它成为索引的一部分。代码本身就是最好的说明书。你的 Rule 应该是随着开发过程动态生长的,而不是一开始就塞进去一堆你自己都没读完的规则。
(八)无论是模型还是工具,时刻保留多套方案
在 2025 年,唯一不变的就是变化。我们见证过模型突然"降智",也遇到过支付渠道突然被切断的情况。
永远不要把所有希望寄托在单一模型上。某些模型就是有它的局限性,比如我有一次遇到一个棘手的前端 CSS 层叠上下文问题,在 ChatGPT 5.2 和 Gemini 3 Pro 上折腾了半天没解决,它们给出的方案总是在原地打转。最后我切到 GitHub Copilot 里的 Claude Opus 4.5,它一眼就看出了问题所在。
无论是 Cursor、Trae 还是 VS Code,无论是 OpenAI 还是 Google,保持工具链的冗余度,是你按时交付的最后一道防线。
(九)数据安全很重要,记得脱敏重要数据
AI 行业竞争这么激烈,你很难保证这些 AI 公司为了活下去,不会拿你的数据去"炼丹"。所以,关于 Token、密钥(Secret Key)这类敏感信息,绝对不能交给 AI。
凡是你不敢提交到公共 Git 仓库的内容,也同样不要发给 AI。善用 .cursorignore 等配置文件,把存放密钥的文件屏蔽掉。
但开发又离不开这些密钥,怎么兼顾安全和方便呢?我的做法是让 AI 把所有敏感配置都提取成环境变量,而在 Codespace 之外的地方(比如本地的 ~/.bashrc)去实际赋值。如果某个工具必须通过命令行传参(比如 --token xxx),我就让 AI 把这串命令封装成 run.sh,脚本里只写变量名。这样 AI 看到的只是 $MY_SECRET_TOKEN,而真实的密钥永远躺在你本地的硬盘里。你也不想你的 Token 在未来出现在某个糊涂蛋开源项目的 Prompt 示例里吧?
(十)大力不能出奇迹,不要陷入"只和 AI 聊天"就能解决所有问题的误区
最后一条,也是最重要的一条:如果 AI 反复几次都解决不了一个问题,请立刻停止对话,动用你自己的脑子。
很多时候,我们容易陷入一种"赌徒心理",觉得下一次 Prompt 就能修好了。举个我最近开发 Tauri 桌面应用(Rust + Vue3 + Vite)的例子:我在开发环境下(dev),点击按钮可以正常弹出模态框(Modal);但打包安装后(build),按钮点击就毫无反应。
我换了三个模型,尝试了改 CSS z-index、查 Webview2 兼容性、对比 build/dev 环境变量,甚至让 Agent 在代码里到处打 log,折腾了一晚上都无解。Log 显示逻辑流转一切正常。
最后我实在没招了,在 dev 模式下主动打开了 Webview2 的控制台(Console)。一眼就看到了一个 Main Window 里的报错:i18n 报警,提示某个翻译占位符不能用 @,必须用 {'@'} 转义。这个错误在 dev 模式下只是个 Warning,不影响交互;但在 build 后的生产环境下,它直接阻断了后续 JS 的执行。
这个报错不在后端 Log 里,也不在显眼的终端输出里,AI 自然"看"不到。这提醒我们:AI 再强也只是辅助,作为工程师,排查问题的基本功(比如亲自看一眼控制台)永远不能丢。
2025 年年初,我还写了一篇关于 AI 的使用心得,除了发在咱国内的平台上,还发在了海外的技术论坛 dev.to 上,没有什么反响。
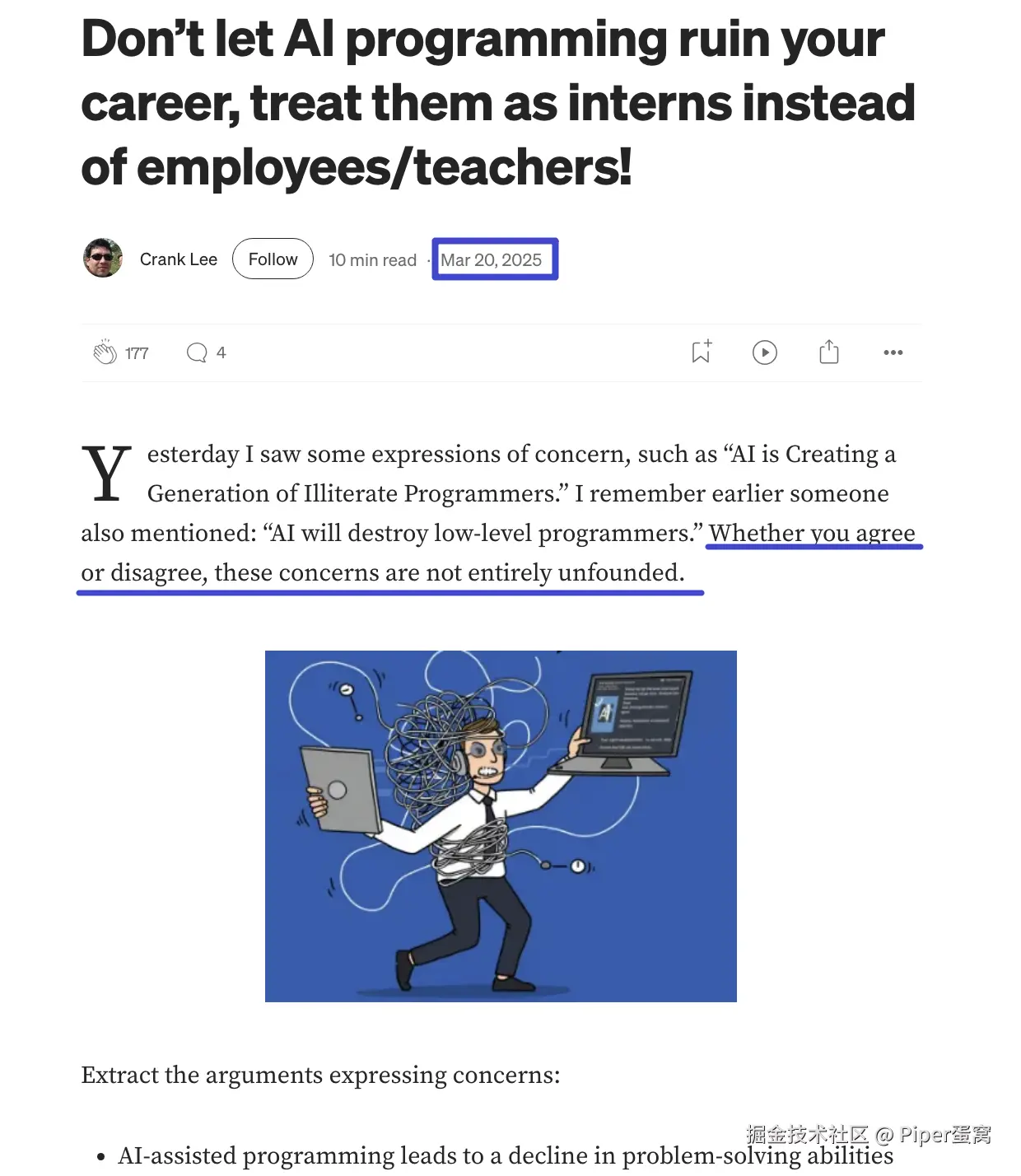
结果我发现,这篇文章被人洗稿了,并且绝大部分内容是原封不动地抄袭过去的。我是在 2025 年 2 月 21 日首发在 dev.to 上,它是在 2025 年 3 月 20 日把文章洗稿发到 generativeai.pub 上的。
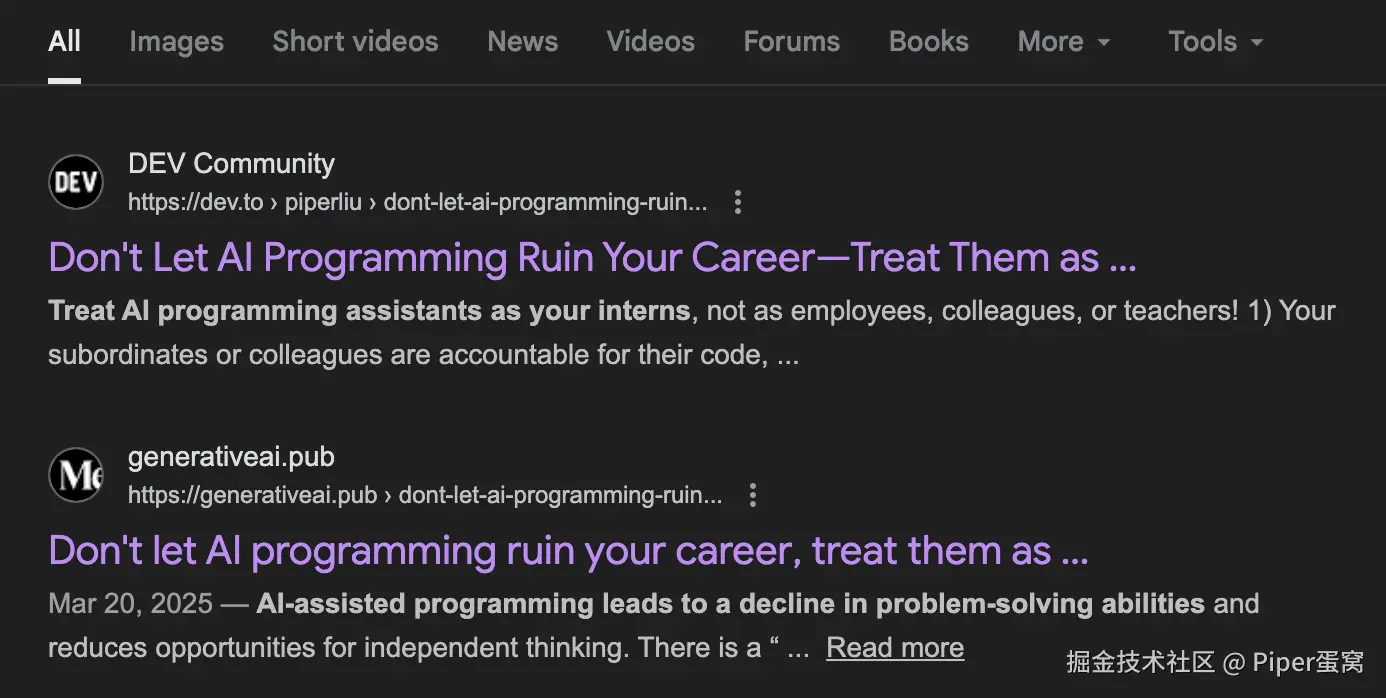
除了开头做了微小改动,剩下的正文部分内容基本一致。
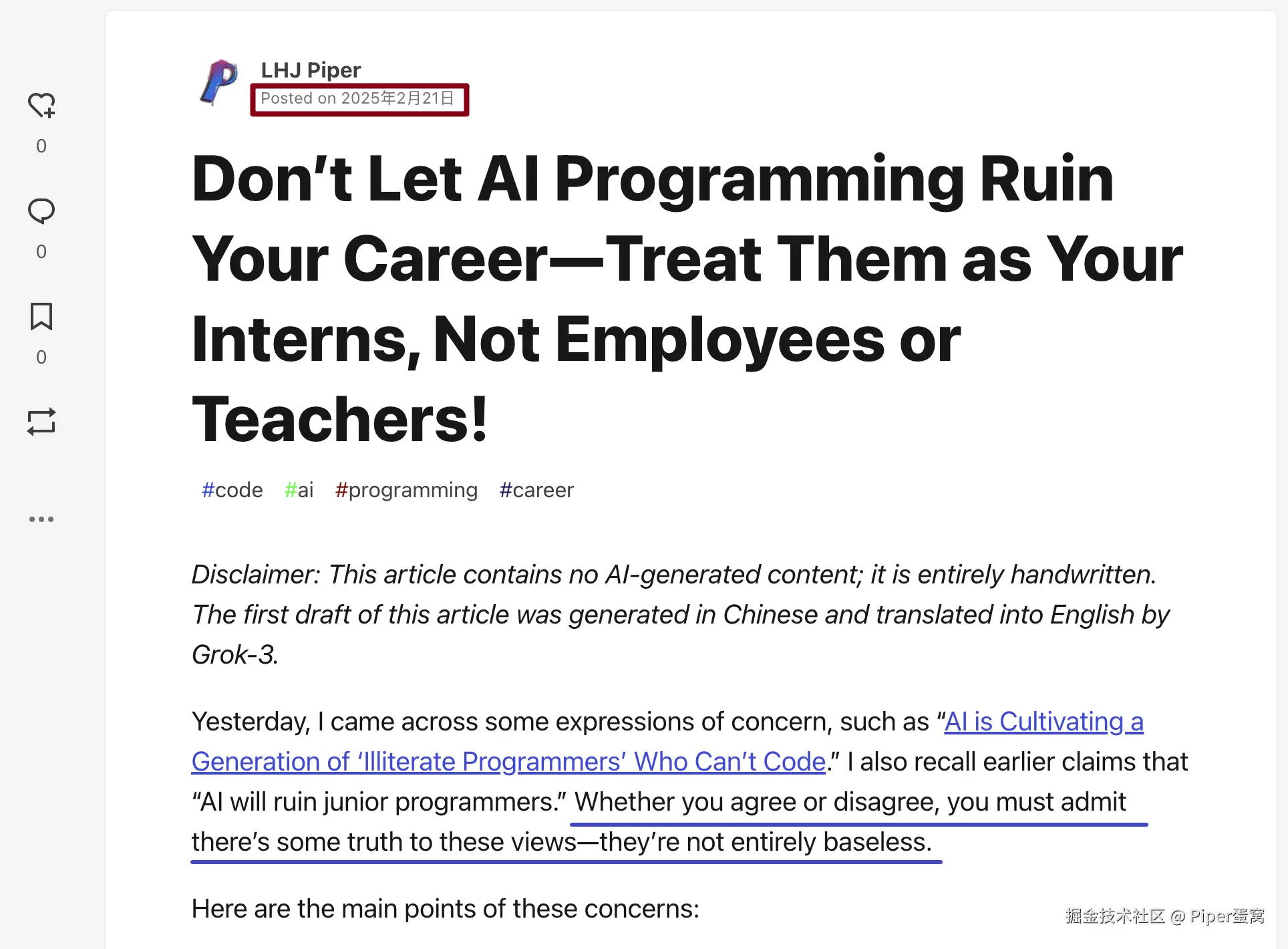
原文链接:
抄袭者链接:
好消息是:抄袭者的文章有许多点赞与评论,看来我写的文章还是有一定参考价值的。
坏消息是:都说中文互联网是垃圾堆,看起来英文互联网也没有好到哪里去。这对我这个 Hacker News 老读者的冲击有些大。
准备投诉/维权试一试,看看这些国际平台是否真的那么尊重原创与版权。
欢迎关注我,之后有结果了我也会把经历汇总成一篇文章。