我们在一些书上文章上看到过一级二级三级高速缓存,或者大家学习链表和数组的时候了解到过缓存利用率
一级二级三级高速缓存
在CPU和内存之间还有一级二级三级高速缓存,都嵌入在CPU之中和核心之间,因此CPU向其访问数据的速度极快。CPU访问一级是CPU访问内存速度的百倍,二级是三十到百倍,三级是十到三十倍。因此只要数据在三级高速缓存里面,那么综合起来的速度会极其快。
一级缓存一般有几KB到几十KB的内存,二级可以有几百KB到几MB
缓存利用率
缓存利用率和CPU的一级二级三级有关。我们知道,当数据/指令 加载到高速缓存的时候,并不是只将要读的数据/指令加载入内存,而是将同内存周围一块区域全部加载至一级二级三级缓存里面,因为用户可能会访问这块区域的其他内存;或者地址加载到高速缓存的时候,及时预留存储,以防下次还会访问
数据缓存
首先我们要了解CPU一次缓存多少数据
CPU缓存行
CPU缓存行就是CPU一次读取后缓存多少数据到高速缓存里面,现在普遍是以64字节作为缓存行,这是实践得出来的结果,目前硬件传输速率等影响,64字节是最合适的。它类似分页系统的页,将地址分成一块一块的,缓存行也是一样的,将地址分为一块一块,例如000-040(第一个64),一直增加。
当要读取某个地址的时候,会查看是哪个缓存行,然后将缓存行的数据加载到高速缓存中(不是以当前地址往后64字节,不要弄混了)
地址缓存
地址缓存利用率就是当有个逻辑地址转为物理地址后,会将这个映射加载缓存里,这个高速缓存叫TLB,也叫快表。当下次要转换地址的时候先去快表查一下,如果有那么就直接获取即可。
这个对于程序员的优化操作就比较少,不多讲。
指令缓存
指令缓存,当读取进程的代码段时,可能会读取几条指令。这个我们也操作不了,也不多讲,了解即可。
缓存利用率就是CPU从高速缓存里面获取数据能命中的占比。
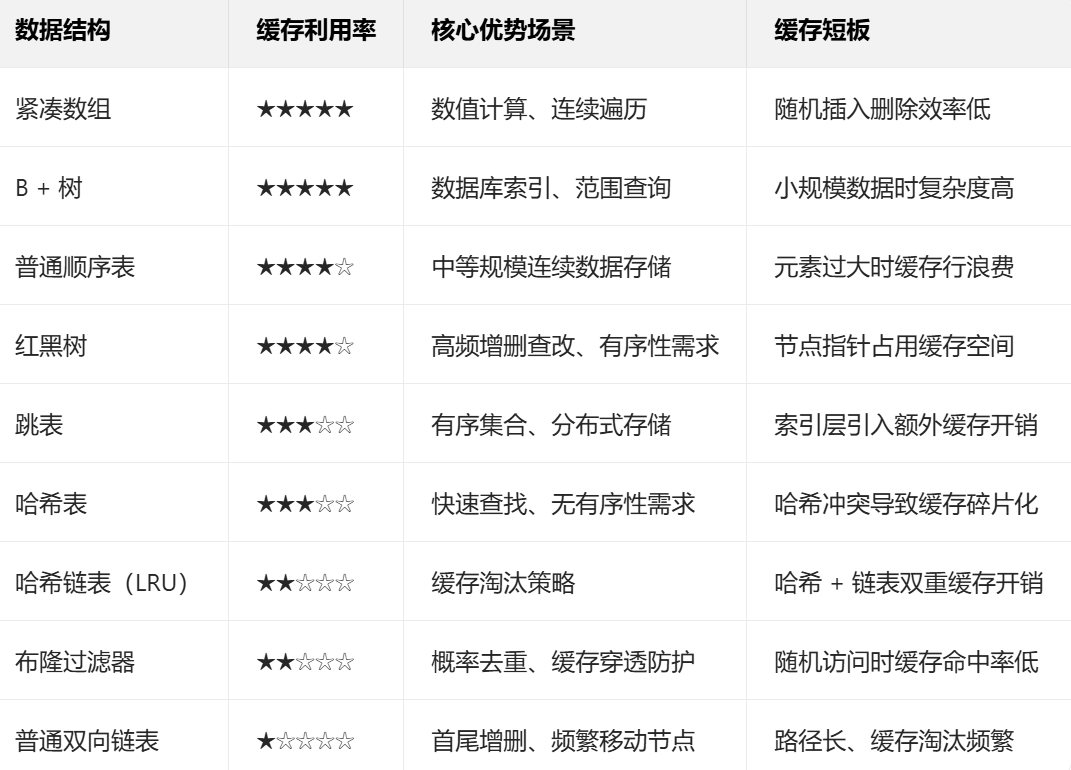
不同数据结构的缓存利用率
从上到下和缓存利用率越来越低
紧凑数组>(B+树&顺序表)>跳表>平衡二叉树>哈希表>链表
紧凑数组
紧凑数组就是C式的数组,它完全匹配高速缓存,内存连续,缓存利用率极高,基本是100%的缓存利用率
**B+树&**顺序表
B+数因为层数少加上每层都是长数组,导致和紧凑数组是差不多的,缓存利用率也高。
顺序表和优化
顺序表内部存储的是begin cur end的三个指针,当访问顺序表的时候,需要加加载三个指针,再加载堆内存,涉及到两次未命中,而紧凑数组只有一次未命中。所以有差距。
一般设计到一下几点,我们看它和C数组的区别以及如何优化
顺序读取
顺序读取和C几乎没差别,因为编译器可以做很大的激进优化,比如将堆数组常驻,直接操作堆指针等,这样就免去加载查找对指针的步骤了
cpp
void test_sequential_speed(int N) {
// 准备数据
std::vector<int> vec(N, 1);
int* arr = vec.data(); // 与vector共享相同内存
// 测试C数组风格(使用.data())
auto start = std::chrono::high_resolution_clock::now();
int sum1 = 0;
for (int i = 0; i < N; i++) sum1 += arr[i];
auto time_array = std::chrono::high_resolution_clock::now() - start;
// 测试vector[i]风格
start = std::chrono::high_resolution_clock::now();
int sum2 = 0;
for (int i = 0; i < vec.size(); i++) sum2 += vec[i];
auto time_vector = std::chrono::high_resolution_clock::now() - start;
std::cout << "数组: " << time_array.count() / 1e6 << " ms\n";
std::cout << "vector: " << time_vector.count() / 1e6 << " ms\n";
std::cout << "差异: "
<< (time_vector.count() * 100.0 / time_array.count() - 100)
<< "%\n";
}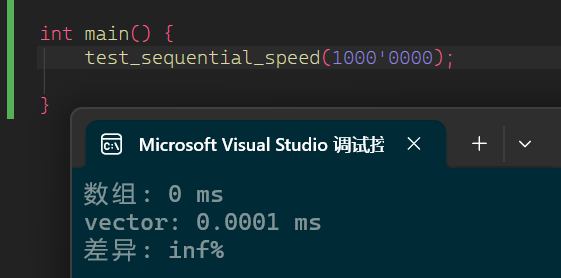
release下几乎没差别
顺序写
我们在看有写的
cpp
void benchmark(int N) {
const int ITER = 10;
// 使用相同类型!都使用float
std::vector<float> vec(N, 1.0f);
float* carr = new float[N];
std::fill_n(carr, N, 1.0f);
// 测试1: vector[i]
auto t1 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
for (size_t i = 0; i < vec.size(); i++) {
vec[i] = vec[i] * 1.001f + 0.001f;
}
}
auto t2 = std::chrono::high_resolution_clock::now();
// 测试2: .data()
auto t3 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
float* data = vec.data();
size_t n = vec.size();
for (size_t i = 0; i < n; i++) {
data[i] = data[i] * 1.001f + 0.001f;
}
}
auto t4 = std::chrono::high_resolution_clock::now();
// 测试3: C数组(修正类型)
auto t5 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
for (size_t i = 0; i < N; i++) {
carr[i] = carr[i] * 1.001f + 0.001f;
}
}
auto t6 = std::chrono::high_resolution_clock::now();
delete[] carr;
auto time_vec = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1);
auto time_data = std::chrono::duration_cast<std::chrono::milliseconds>(t4 - t3);
auto time_carr = std::chrono::duration_cast<std::chrono::milliseconds>(t6 - t5);
std::cout << "vec[i]方式: " << time_vec.count() << " ms\n";
std::cout << ".data()方式: " << time_data.count() << " ms\n";
std::cout << ".carr方式: " << time_carr.count() << " ms\n";
std::cout << "加速: " << (time_vec.count() * 100.0 / time_data.count() - 100) << "%\n";
std::cout << "加速: " << (time_data.count() * 100.0 / time_carr.count() - 100) << "%\n";
}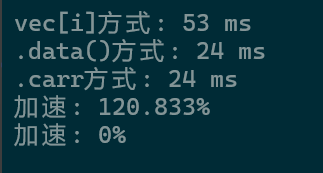
我测试了几组,基本多是100以上。因此取平均值可以说速度提升了一倍之多,且和紧凑数组的效率几乎一样(一会data快一会C数组快)
随机读写
随机读写更不用说了,我们来看三者区别
cpp
void benchmark_random_access(int N, int access_count) {
const int ITER = 10;
// 准备数据 - 使用堆分配避免栈溢出
std::vector<float> vec(N, 1.0f);
float* carr = new float[N];
std::fill_n(carr, N, 1.0f);
// 生成随机访问索引(避免cache line友好模式)
std::vector<size_t> random_indices(access_count);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<size_t> dis(0, N - 1);
for (int i = 0; i < access_count; i++) {
random_indices[i] = dis(gen);
}
// 预热缓存(不计时)
volatile float warmup = 0;
for (int i = 0; i < 1000; i++) warmup += vec[i % N];
std::cout << "测试配置: N=" << N << ", 随机访问次数=" << access_count
<< ", 迭代=" << ITER << "次\n";
// 测试1: vector[i] 随机访问
auto t1 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
for (size_t idx : random_indices) {
vec[idx] = vec[idx] * 1.001f + 0.001f;
}
}
auto t2 = std::chrono::high_resolution_clock::now();
// 测试2: .data() 随机访问
auto t3 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
float* data = vec.data();
for (size_t idx : random_indices) {
data[idx] = data[idx] * 1.001f + 0.001f;
}
}
auto t4 = std::chrono::high_resolution_clock::now();
// 测试3: C数组 随机访问
auto t5 = std::chrono::high_resolution_clock::now();
for (int iter = 0; iter < ITER; iter++) {
for (size_t idx : random_indices) {
carr[idx] = carr[idx] * 1.001f + 0.001f;
}
}
auto t6 = std::chrono::high_resolution_clock::now();
auto time_vec = std::chrono::duration_cast<std::chrono::microseconds>(t2 - t1);
auto time_data = std::chrono::duration_cast<std::chrono::microseconds>(t4 - t3);
auto time_carr = std::chrono::duration_cast<std::chrono::microseconds>(t6 - t5);
std::cout << "\n=== 随机访问测试结果 ===\n";
std::cout << "vector[i]: " << time_vec.count() << " us\n";
std::cout << ".data(): " << time_data.count() << " us\n";
std::cout << "C数组: " << time_carr.count() << " us\n";
std::cout << "\n=== 性能比较 ===\n";
std::cout << ".data() 比 vector[i] 快: "
<< (time_vec.count() * 100.0 / time_data.count() - 100) << "%\n";
std::cout << "C数组 比 .data() 快: "
<< (time_data.count() * 100.0 / time_carr.count() - 100) << "%\n";
std::cout << "C数组 比 vector[i] 快: "
<< (time_vec.count() * 100.0 / time_carr.count() - 100) << "%\n";
// 验证结果一致性
float sum_vec = 0, sum_carr = 0;
for (int i = 0; i < std::min(100, N); i++) {
sum_vec += vec[i];
sum_carr += carr[i];
}
std::cout << "\n验证: vec总和=" << sum_vec << ", carr总和=" << sum_carr << "\n";
delete[] carr;
}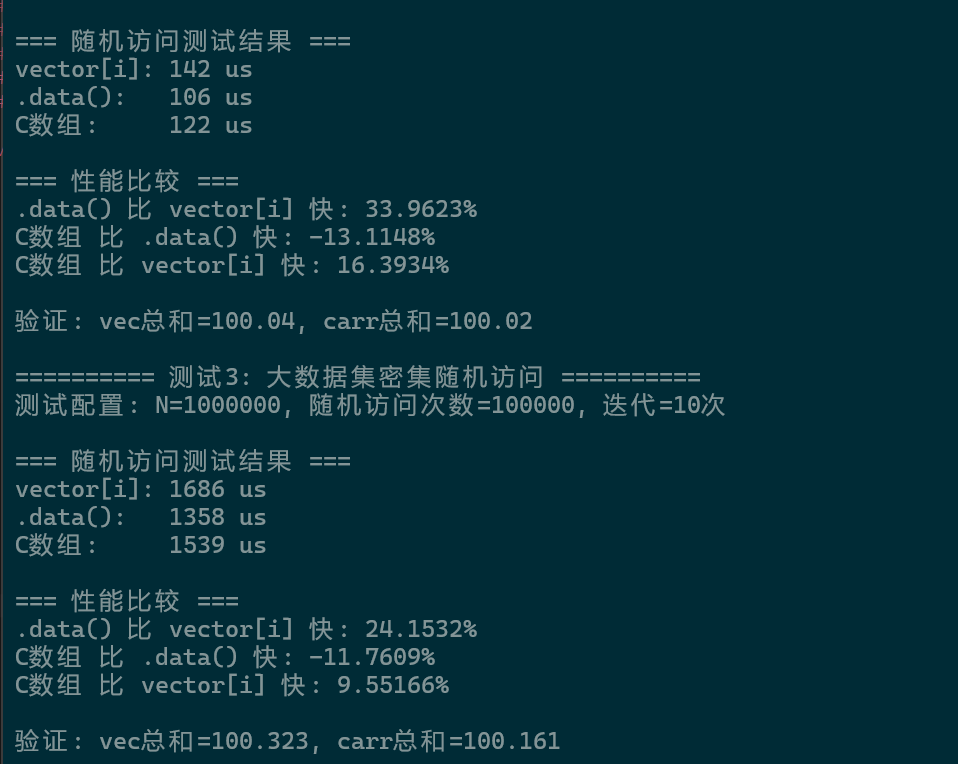
可以看出data是很耐打的,甚至比C更快,可能是编译器对vector有优化,例如内存对齐等原因
多vector读写
因为多vector,多C数组都会有内存跨度大导致的缓存命中率差不多
跳表
跳表结构是多层链表,从上往下查找,层数少,导致往下到最底层时,上层的缓存并未被覆盖。下次查找依然有顶层的缓存。
平衡二叉树
平衡二叉树和跳表都是O(logN)的时间复杂度,因为二叉树每个节点有两个子节点,存在命中一半的情况。而跳表是单个路径不是二叉树的左右子树,因此缓存利用率更高。另外在STL里面,会通过内存池 让节点的内存靠的比较近,然后就是会将小成员变量声明到搞地址这样可以降低内存对齐让节点变小,容纳更多的节点到缓存内部
哈希表
哈希表因为查找的随机下标导致缓存失效,例如第一个找1,后面一个找100,那么就很容易缓存失效。但是事无绝对,如果哈希表桶数只有几十个到一百多个,可能一下可以将所有桶加载到缓存内部,那么缓存利用率就和二叉树、跳表差不多。但是在同样大数据下,哈希表是不能打的。
链表
当数据量大时,链表无法加载全部的节点到缓存内部,可能前面加载A,B,C,D节点,后面加载E,F,G,H的时候,缓存已经满了,那么就会将A,B,C,D又覆盖,导致缓存利用率很低。本质原因是链表查找时访问的节点很多导致的,塞满了很多无用的节点,而二叉树跳表无用的节点就很少,因为走的层数很矮,加载到缓存的节点数不多。
当链表长度小于10时和红黑树甚至和数组差别不是特别大
总结
提高缓存利用率的方式
数据布局
我们把经常访问的数据叫热数据 ,不经常访问的数据叫冷数据。
SOA & AOS
SOA:Structure of Arrays AOS:Array of Structures
cpp
// AOS
struct Particle {
Vec3 position; // 热数据(频繁访问)
Vec3 velocity; // 热数据
char name[32]; // 冷数据(很少访问)
Texture* tex; // 冷数据
};
Particle particles[10000];
// SOA
struct ParticleSystem {
alignas(64) Vec3 positions[10000]; // 热数据连续
alignas(64) Vec3 velocities[10000]; // 热数据连续
// 冷数据分开存储
std::vector<std::string> names;
std::vector<Texture*> textures;
};这里我们什么时候选AOS什么时候选SOA呢?
当我们要修改一个类里面绝大部分数据的时候,选用AOS,因为AOS是多数据并在一起的,可以被缓存行一起调走;如果要修改一个类里面的几个变量,那么就用SOA,因为SOA是单种数据并在一起的,一次缓存行可以调取多个数据。
并且SOA可以使用SIMD来提升性能,SIMD是可以并行计算多个值,例如本来只能算一个的,现在可以算8个。
紧凑到一个缓存行
因为缓存加载是按缓存行来的,因此我们尽可能将数据放在一个缓存行内,而不是一头在A缓存行,一头在B缓存行,这是不好的,因此我们可以声明当前类型在创建时需要对齐。
这里可以使用alignas来强制编译器让内存以N的倍数地址对齐。这里是64就按64倍数对其,刚好可以和缓存行成块。当然是32、16、8、4、2也是可以的,这样就是加载多个类到缓存行,例如32可以加载两个,16可以加载4个
cpp
// ❌ 浪费缓存行
struct Bad {
int hot_data;
char padding[60]; // 87.5%浪费!
};
// ✅ 填充热数据
struct Good {
int hot1, hot2, hot3, hot4; // 16字节
float values[12]; // 48字节
// 总共64字节,一个缓存行,利用率100%
};
// ✅ 对齐到缓存行(避免伪共享)
struct alignas(64) ThreadData {
std::atomic<int> counter;
// 自动填充到64字节
};冷热数据分离
cpp
// ❌ 混合存储
class GameObject {
Transform transform; // 热数据(每帧访问)
PhysicsState physics; // 热数据
std::string description; // 冷数据(很少访问)
Texture* icon; // 冷数据
};
// ✅ 热冷分离
struct HotComponents {
Transform transform;
PhysicsState physics;
// 总共可能32-48字节,缓存友好
};
struct ColdComponents {
std::string description;
Texture* icon;
// 不频繁访问,放一起
};
class GameObject {
HotComponents hot;
ColdComponents* cold; // 可共享或延迟加载
};避免线程伪共享
当一个CPU写一个缓存行时,如果有另一个CPU也在用这个缓存行,那么另一个CPU会重新刷新缓存行导致缓存行失效。因此要避免多线程两个线程共用一个缓存行
cpp
// ❌ 伪共享:不同线程修改同一缓存行的不同变量
struct SharedData {
std::atomic<int> counter1; // 线程1写
std::atomic<int> counter2; // 线程2写
// 可能在同一缓存行,互相使缓存无效
};
// ✅ 缓存行对齐
struct alignas(64) ThreadLocal {
std::atomic<int> counter;
char padding[64 - sizeof(std::atomic<int>)];
};
ThreadLocal thread_data[16]; // 每个线程独立缓存行内存池
内存池每次向堆是一页一页申请的,导致我们向内存池申请的内存普遍是靠近的,就算是链表也可以拿到很近的地址。这样就可以增大缓存命中的概率