摘要
本周学习了机器学习人为攻击的知识点,为了欺骗模型,攻击者会对数据进行处理以此达到目的,本周学习了攻击者是如何进行处理数据的。
abstract
This week, I learned about human-led attacks in machine learning. In order to deceive models, attackers manipulate data to achieve their objectives. This week's study focused on how attackers carry out such data manipulation.
一、人为蒙蔽
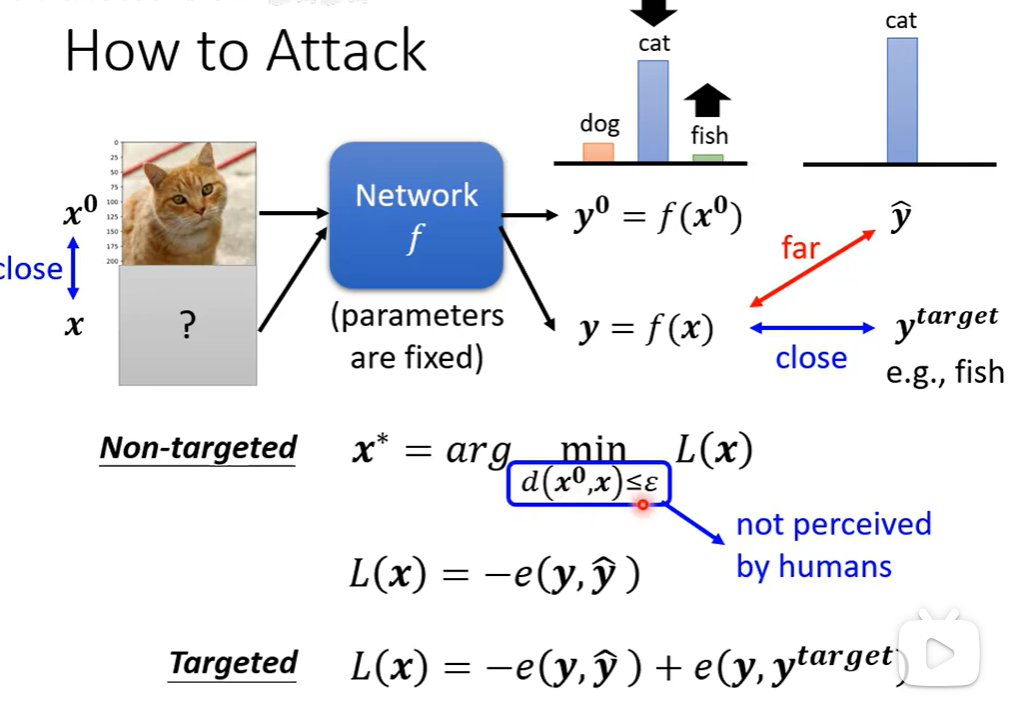
攻击者将一个预先训练好的固定模型看作一个函数,通过精心构造一个与原始输入在人类感知上几乎无差别(即满足距离约束d(x⁰, x) ≤ ε)的扰动样本x,来系统地欺骗模型。其方法被形式化为一个优化问题:攻击者寻求在扰动允许的微小范围内,找到那个能使特定损失函数L(x)最小化的最优对抗样本x*。对于非定向攻击,损失函数旨在最小化模型对原始正确类别的置信度;而对于定向攻击,损失函数则同时追求降低对正确类别的置信度并提高对指定目标类别的置信度。简而言之,它揭示了攻击者如何通过计算导向的梯度优化,在人类难以察觉的细微改动下,将输入样本"推"过模型的决策边界,从而引发其判断失效。
二、图像之间的差异
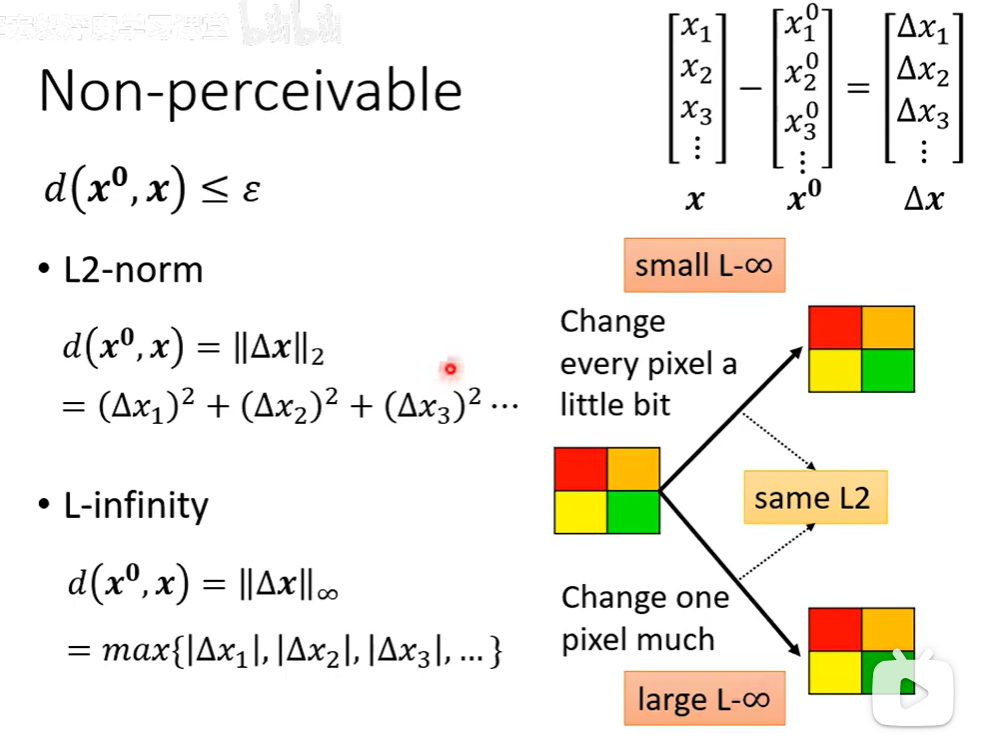
扰动后的图像x与原始图像x⁰之间的距离d(x⁰, x)不超过一个微小阈值ε,这一约束直接关系到人类视觉的感知界限。图中重点对比了两种关键的距离度量方法:L2范数和L∞范数。L2范数计算所有像素变化值的平方和,衡量的是整体扰动的"总能量",它限制的是整张图片的累计变化幅度;L∞范数则只关注所有像素中变化绝对值的最大值,衡量的是局部"最大单点扰动强度",它限制的是任何一个像素点的变化都不能超过上限。
这两种度量标准导向了不同的攻击形态。若以L2为约束,攻击者倾向于将微小的噪声均匀分散到大量甚至全部像素上,使每个像素仅发生细微改变,从而在整体能量可控的情况下实现欺骗;若以L∞为约束,攻击者则会在允许的极限内,集中对关键位置的少数像素进行较大幅度的改动,同时确保没有单个像素的变化超出阈值。下方的示意图直观表明:当每个像素都改变一点点时,L∞距离很小;而当仅一个像素被大幅修改时,L∞距离会变得很大。因此,选择不同的距离范数,本质上决定了对抗性扰动是"全面弥漫"还是"局部突刺"的隐形策略。
三、FGSM
FGSM就是一种快速骗过AI图片识别的方法。它的做法很简单:先让AI看一下原图,然后问它"这张图里每个像素该怎么微调,才会让你最容易认错?"拿到这个"指导"后,就在每个像素上按照它指出的方向(变亮或变暗)加一点极小的改动。这些改动小到人眼看不出来,但组合起来就能让AI把"猫"认成"狗"之类的东西。整个攻击过程非常快,一次就能完成。
