官方文档
https://milvus.io/docs/zh/overview.md
1: 面向列存储的优势
传统行式存储 vs 列式存储
假设你有一张表存储向量数据:
行式存储:
Row 1: [id=1, name="doc1", vector=[0.1,0.2,0.3], timestamp=xxx]Row 2: [id=2, name="doc2", vector=[0.4,0.5,0.6], timestamp=yyy]
列式存储:
id列: [1, 2, ...]name列: ["doc1", "doc2", ...]vector列: [[0.1,0.2,0.3], [0.4,0.5,0.6], ...]timestamp列: [xxx, yyy, ...]
两个关键优势
1.减少数据访问量
当你执行查询时,比如"搜索相似向量",你只需要:
- 行式存储:读取整行数据(id + name + vector + timestamp)
- 列式存储:只读取vector列 1
这大大减少了I/O开销,因为你跳过了不需要的字段 1。
2.向量化操作
列式存储让数据在内存中连续排列,可以利用CPU的SIMD指令一次处理多个值
向量列: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, ...] ↓ 一次性对整列执行操作结果: [处理后的值...]
而不是逐个处理每一行 1。
性能提升
这种设计使Milvus在大多数情况下比其他向量数据库快2-5倍 1,因为它充分利用了硬件能力(AVX512、SIMD等) 1。
2:架构说明
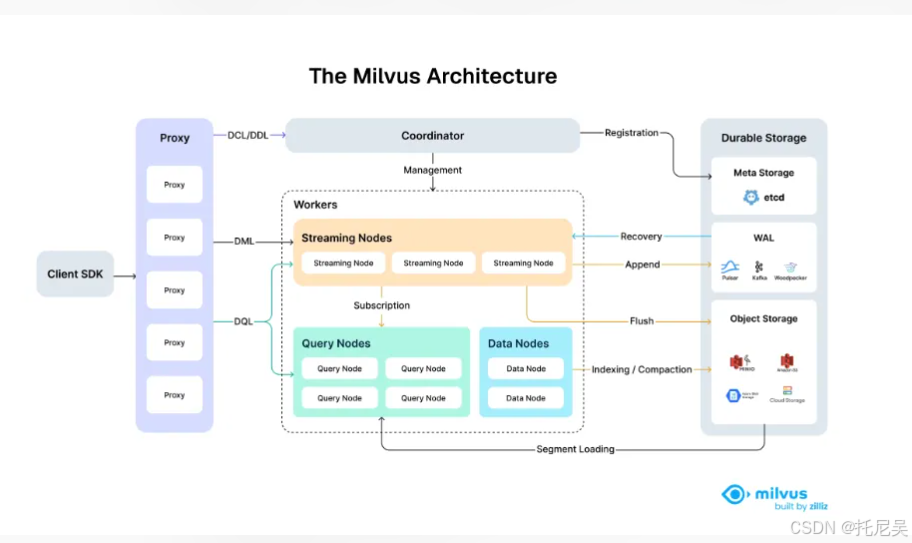 1.Client SDK
1.Client SDK
- 用户通过编程语言(Python、Java 等)调用 Milvus 的 API。
- 负责封装请求并发送到 Milvus 集群。
2.Proxy(代理层)
- 多个 Proxy 实例组成负载均衡层。
- 功能:
- 接收来自客户端的请求(DCL/DDL、DML、DQL)
- 将请求转发给正确的后端节点
- 支持高可用与横向扩展
✅ 请求类型说明:
- DCL/DDL:数据控制语言 / 数据定义语言(如创建集合、修改表结构)
- DML:数据操作语言(如插入、删除数据)
- DQL:数据查询语言(如向量相似性搜索)
3.Coordinator(协调器)
- 核心管理节点,负责全局调度和元信息管理。
- 主要职责:
- 注册 & 管理所有 Worker 节点
- 处理 DCL/DDL 操作(如建表、分区)
- 分配任务给 Streaming Node 和 Query Node
- 维护集群状态
⚠️ 它不直接处理数据,而是"大脑"级别的控制中心。
4.Workers(工作节点)
这是 Milvus 的核心计算层,包含三种类型节点:
✅ a)Streaming Nodes(流式节点)
- 负责接收实时写入的数据(DML 写入)。
- 使用消息队列(如 Kafka、Pulsar)进行异步处理。
- 将数据按"Segment"组织,并分发给 Data Node 或 Query Node。
- 支持高吞吐写入,适合流式数据场景。
✅ b)Query Nodes(查询节点)
- 执行向量相似性搜索(ANN 搜索)。
- 从 Data Node 加载索引段(Segment)。
- 支持多路并行查询,提升检索性能。
✅ c)Data Nodes(数据节点)
- 存储原始向量数据和索引文件。
- 负责:
- 数据持久化(Flush 到对象存储)
- 索引构建(Indexing)
- 数据压缩(Compaction)
- 与 Object Storage 同步数据。
💡 注意: Query Node 和 Data Node 可以独立扩展,实现读写分离。
5.Durable Storage(持久化存储)
Milvus 不将数据存于内存中,而是依赖外部存储保证数据安全和可恢复性。
✅ a)Meta Storage(元数据存储)
- 使用 etcd 存储集群元数据(如集合结构、分区信息、节点状态)。
- 提供强一致性,支持故障恢复。
✅ b)WAL(Write-Ahead Log)
- 写前日志,确保数据不丢失。
- 支持多种后端:Pulsar、Kafka、Woolpecker(Zilliz 自研)。
- 用于在崩溃后恢复未提交的数据。
✅ c)Object Storage(对象存储)
- 存放实际的向量数据和索引文件。
- 支持主流云服务:
- AWS S3
- MinIO
- Azure Blob
- GCP Cloud Storage
- 支持跨地域复制、冷热数据分层。
3:Attu-Milvus向量数据库可视化工具
Attu是一款专为Milvus向量数据库打造的开源数据库管理工具,提供了便捷的图形化界面,极大地简化了对Milvus数据库的操作与管理流程。阿里云Milvus集成了Attu,以便更加高效地管理数据库、集合(Collection)、索引(Index)和实体(Entity)等的管理。
gitcode地址
https://gitcode.com/gh_mirrors/at/attu/tree/v2.6.3
github地址
https://github.com/zilliztech/attu
支持window和mac本地安装
https://github.com/zilliztech/attu/releases/tag/v2.6.4
 4: Milvus 和 Pinecone向量数据库解决方案进行比较
4: Milvus 和 Pinecone向量数据库解决方案进行比较
| 特征 | Pinecone | Milvus | 备注 |
|---|---|---|---|
| 部署模式 | 纯 SaaS | Milvus Lite、On-prem Standalone & Cluster、Zilliz Cloud Saas & BYOC | Milvus 提供更灵活的部署模式。 |
| 支持的 SDK | Python、JavaScript/TypeScript | Python、Java、NodeJS、Go、Restful API、C#、Rust | Milvus 支持更广泛的编程语言。 |
| 开源状态 | 已关闭 | 开源 | Milvus 是一个流行的开源向量数据库。 |
| 可扩展性 | 仅向上/向下扩展 | 向外/向内扩展和向上/向下扩展 | Milvus 采用分布式架构,增强了可扩展性。 |
| 可用性 | 可用区域内基于 Pod 的架构 | 可用区域故障切换和跨区域 HA | Milvus CDC(变更数据捕获)支持主备模式,以提高可用性。 |
| 性能成本(每百万次查询收费) | 中型数据集 0.178 美元起,大型数据集 1.222 美元起 | Zilliz Cloud 中型数据集的起价为 0.148 美元,大型数据集的起价为 0.635 美元;提供免费版本 | 请参阅 成本排名报告。 |
| GPU 加速 | 不支持 | 支持英伟达™(NVIDIA®)GPU | GPU 加速可大幅提升性能,通常可提升几个数量级。 |