突破跨信道调制分类瓶颈!FSSADA半监督对抗域自适应框架重磅来袭
一、文章题目
面向跨信道场景:融合半监督对抗域自适应调制分类网络
二、摘要
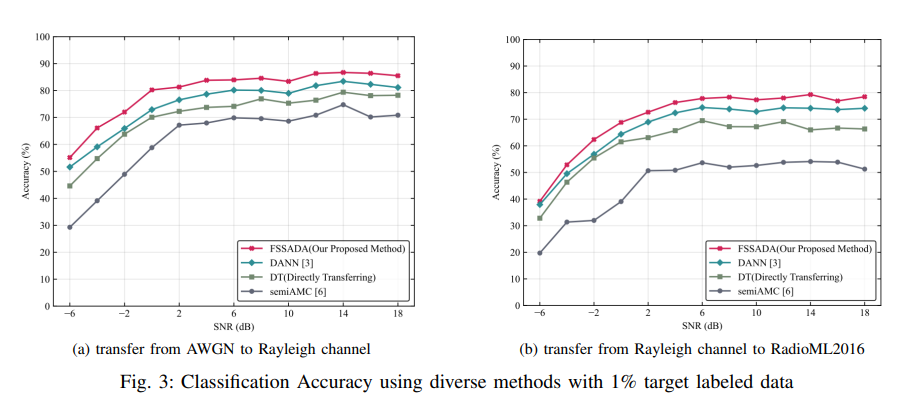
基于深度学习的自动调制分类(AMC)已成为研究热点,具有广泛的实际应用价值。然而,现有深度学习AMC网络在特定信道模型下训练后,在新的信道场景中性能表现不佳。为解决这一问题,本文提出一种对抗性半监督域自适应方法。具体而言,该方法通过三阶段迭代训练策略,联合优化分类精度、聚类敏感性和分布距离。实验结果表明,所提模型在迁移至新信道场景时,仅需少量标记数据即可实现稳健的分类性能。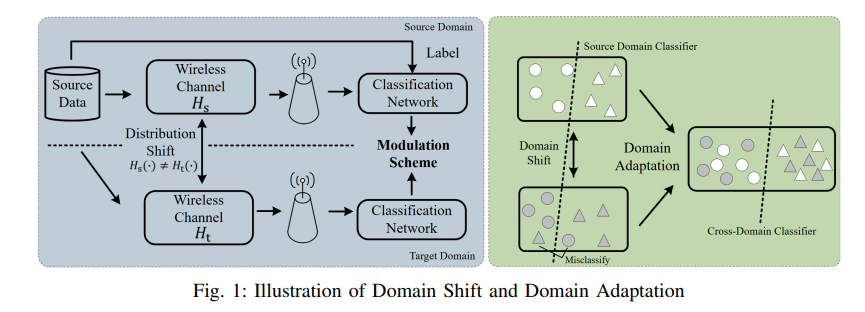
三、引言
自动调制分类(AMC)是第六代(6G)网络频谱感知中的关键技术12。尽管基于深度学习(DL)的AMC方法已取得显著成果,但这类方法依赖海量数据集,在未知信道环境中性能表现不佳3。为应对这一问题,训练过程中需配置包含新发射机参数和信道条件的标记数据集,以确保模型适应新环境。然而,在非协作通信场景中,获取足量标记数据面临巨大挑战。因此,研究焦点转向跨环境模型迁移,并最大化利用有限标记数据来解决该问题。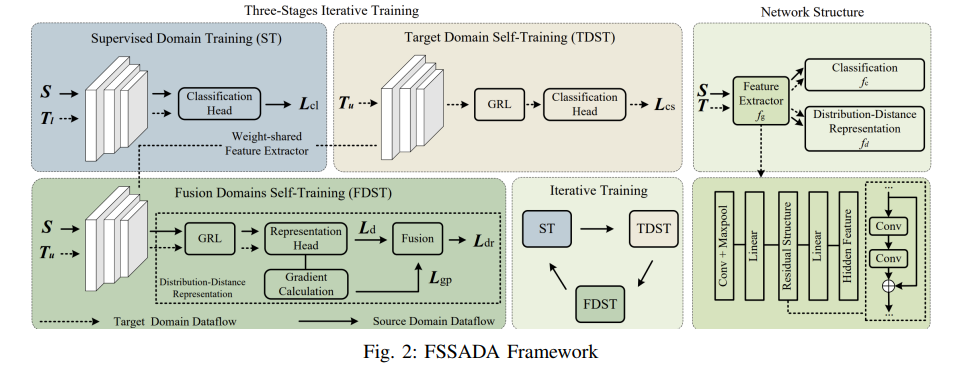
近年来,迁移学习(TL)已成为跨环境知识迁移的新兴方法。Perenda等人3将迁移学习与空间Transformer网络(STN)引入基于ResNeXt的调制分类器,确保模型在未知成形参数(上采样因子、脉冲成形滤波器参数和采样频率)和信道模型(加性高斯白噪声、瑞利、莱斯)下的稳健性。Zhang等人4专注于利用迁移学习提升模型在未知调制方案环境中的泛化能力,提出结合监督对抗域自适应技术与开放集调制识别(OSMR)的开放集域自适应AMC(OSDA-AMC)算法。Zhou等人5和Liang等人6实现了不同AMC数据集(RML2016.10A、RML2016.10C等)间的知识迁移:5中在大规模数据集上复用预训练网络;6提出一种改进的带自注意力机制的域对抗神经网络(DANN),以保留目标域和源域的域特异性特征。然而,当前大多数AMC领域的迁移学习相关研究缺乏对跨信道场景的探讨,而实际应用中,信道环境的分布与训练场景存在显著差异。
半监督学习(SSL)是另一类学习范式,通过结合标记数据和未标记数据训练机器学习模型,可降低数据标记负担,适用于标记数据不足的场景。Liu等人7提出基于自监督对比学习的预训练方法,利用大量未标记数据预训练,再通过少量标记数据微调下游任务。在此基础上,Bai等人8在未标记数据预训练过程中考虑模态级和实例级特征表示,提取更稳健的特征。这两种方法本质上仅在目标域上训练,无法利用不同信道环境间的相关性。Guo等人9提出SemiAMR框架,采用师生模型和伪标签训练方法解决标记不足问题。尽管AMC领域的半监督学习已取得一定进展,但现有多数研究假设训练集和测试集分布一致,而现实场景中数据分布的差异为该领域研究带来新的挑战。
综上,现有基于半监督学习的AMC方法假设训练集与测试集分布相同,而基于迁移学习的研究虽能实现不同分布数据集间的知识迁移,却鲜有针对跨信道场景的研究。为此,半监督域自适应(SSDA)被视为一种可行的解决方案。
在机器学习中,"域"指特定机器学习模型所应用的知识领域;域偏移指模型训练阶段与部署阶段数据分布的统计特性变化。不同信道环境对应不同的域,会引发域偏移。域自适应(DA)是一种机器学习范式,旨在解决从源域(标记数据丰富易获取)到目标域(标记数据稀缺或无)的知识迁移问题?。在跨信道场景中,从已知训练信道环境采样的AMC数据集带有标记,可视为源域;从实际测试信道环境采样的AMC数据集缺乏足够标记,可视为目标域。如图1所示,无线信道的分布偏移会导致域偏移,域自适应可找到一种能有效分类源域和目标域调制方案的分布。半监督域自适应(SSDA)利用目标域中不足的标记数据,是域自适应与半监督学习的结合。
受半监督域自适应相关研究启发,本文提出一种适用于跨信道场景的新型融合半监督对抗域自适应(FSSADA)框架,充分整合标记数据和未标记数据的信息。主要贡献如下:
-
提出一种新颖的三阶段迭代训练方法,通过监督训练和自训练有效融合标记数据和未标记数据;
-
提出一种新型域自适应方法,约束特征空间中源域和目标域的分布:优化聚类敏感性可提高特征空间中相同调制类型样本的相似性,施加分布一致性约束能更好地缩小特征空间中源域和目标域样本的分布差异;
-
在不同信道条件和AMC数据集下验证所提方法,取得了稳健的结果。
四、方法简介
(一)框架整体设计
所提FSSADA框架包含三个迭代训练阶段:监督域训练(ST)阶段,利用源域和标记目标域的AMC数据集进行带标记训练;目标域自训练(TDST)阶段,对未标记目标域数据集进行无标记训练;融合域自训练(FDST)阶段,对源域和目标域数据集进行无标记训练以缩小分布差异。框架网络由共享特征提取模块 fgf_gfg 、分类模块 fcf_cfc 和分布距离表示模块 fdf_dfd 组成,对应的参数分别为 θg\theta_gθg 、 θc\theta_cθc 和 θd\theta_dθd 。
(二)核心训练阶段
- 监督域训练(ST):利用源域和目标域的标记数据集优化模型性能,计算两类域的分类损失(交叉熵损失),公式如下:
Lcl=−1N∑i=1N∑c=1Kyi(c)logP(c∣xi;θg,θc)L_{c l}=-\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{K} y_{i}(c) log P\left(c | x_{i} ; \theta_{g}, \theta_{c}\right)Lcl=−N1∑i=1N∑c=1Kyi(c)logP(c∣xi;θg,θc)
其中, yi(c)y_i(c)yi(c) 为样本 iii 是否属于类别 ccc 的二元指示符(0或1), P(c∣xi;θc,θg)P(c|x_i;\theta_c,\theta_g)P(c∣xi;θc,θg) 为给定模型参数时样本 iii 属于类别 ccc 的预测概率, NNN 为源域和目标域的所有标记样本总数。
- 目标域自训练(TDST):引入聚类敏感性约束目标域分布,聚类敏感性损失通过熵定义,公式如下:
Lcs=−E(x,y)∈Tu∑i=1Kp(y=i∣x)logp(y=i∣x)L_{c s}=-\mathbb{E}{(x, y) \in T{u}} \sum_{i=1}^{K} p(y=i | x) log p(y=i | x)Lcs=−E(x,y)∈Tu∑i=1Kp(y=i∣x)logp(y=i∣x)
其中, KKK 为调制类别数, p(y=i∣x)p(y=i|x)p(y=i∣x) 为未标记样本预测概率分布 pup_upu 的第 iii 个元素。该阶段采用对抗训练机制,特征提取模块作为生成器,分类模块作为判别器,通过极小极大优化目标函数提升聚类性能。
- 融合域自训练(FDST):结合源域和目标域训练,利用沃尔什-田口距离(Wasserstein Distance)衡量源域和目标域隐藏特征的分布距离,并引入梯度惩罚确保函数满足K-Lipschitz连续性约束。分布距离损失和梯度惩罚损失联合优化,缩小源域和目标域的分布差异,目标函数如下:
minθgmaxθdVFDST(θg,θd)=Ld−γLgp\operatorname* {min}_{\theta {g}}\operatorname* {max}{\theta {d}}V{FDST}(\theta {g},\theta {d})=L{d}-\gamma L{gp}minθgmaxθdVFDST(θg,θd)=Ld−γLgp
(三)网络模块细节
-
特征提取模块 fgf_gfg :采用ResNet-18网络作为核心,提取隐藏特征;
-
分类模块 fcf_cfc :为单层分类头;
-
分布距离表示模块 fdf_dfd :包含梯度反转层(GRL)和三层全连接层,梯度反转层在对抗训练反向传播时反转梯度,常规训练时关闭。
五、结论
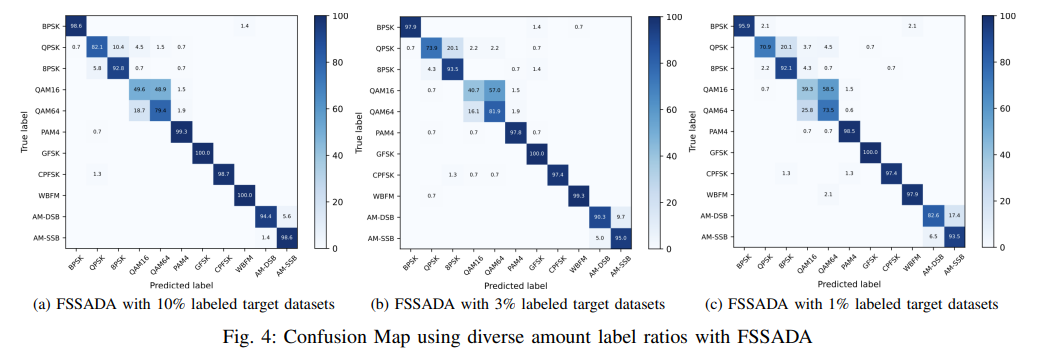
本文提出一种半监督域自适应框架,用于解决跨信道自动调制分类场景中的问题。该方法通过融合分布距离表示与分类聚类敏感性,在跨信道场景中的性能优于其他对比方法。然而,该领域仍有诸多值得探索的方向,例如如何利用更少的数据快速适应未知信道,将是未来的研究重点。