论文题目:Unified Modality Separation: A Vision-Language Framework for Unsupervised Domain Adaptation(无监督领域自适应的视觉语言框架)
期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI)
摘要:无监督域适应(UDA)使在标记源域上训练的模型能够处理新的未标记域。最近,预训练的视觉语言模型(VLMs)通过利用语义信息来促进目标任务,显示出有前途的零样本学习性能。通过对齐视觉和文本嵌入,vlm在弥合领域差距方面取得了显著的成功。然而,情态之间自然存在着固有的差异,这种差异被称为情态差距。我们的研究结果表明,存在模态差距的直接UDA只传递模态不变的知识,导致次优目标性能。为了解决这个限制,我们提出了一个统一的模态分离框架,它可以容纳模态特定组件和模态不变组件。在训练过程中,将不同的模态分量从VLM特征中分离出来,分别进行统一处理。在测试时,自动确定模态自适应集成权重,以最大化不同组件的协同作用。为了评估实例级模态特征,我们设计了一个模态差异度量,将样本分为模态不变、模态特定和不确定三种。利用模态不变的样本来促进跨模态对齐,而对不确定样本进行注释以增强模型能力。基于即时调优技术,我们的方法实现了高达9%的性能增益和9倍的计算效率。对各种主干、基线、数据集和适应设置的广泛实验和分析证明了我们设计的有效性。
UniMoS++:通过模态分离实现高效视觉-语言模型域适应
引言
想象一下,你训练了一个AI模型来识别艺术画作中的物体,现在你希望它也能识别真实照片中的物体。这就是域适应 (Domain Adaptation)要解决的问题。随着CLIP等大规模视觉-语言模型的出现,我们似乎找到了解决这个问题的强大工具。但是,最新研究发现了一个关键问题:模态间隙(Modality Gap)正在阻碍这些模型发挥最佳性能。
今天,我们将深入探讨来自电子科技大学的研究团队在IEEE TPAMI 2025上发表的论文:"Unified Modality Separation: A Vision-Language Framework for Unsupervised Domain Adaptation" (UniMoS++)。这项工作提出了一个创新的解决方案,不是试图消除模态间隙,而是巧妙地绕过它。
问题背景:模态间隙到底是什么?
CLIP的工作原理
首先,让我们简单回顾一下CLIP(Contrastive Language-Image Pre-training)的工作方式:
- CLIP在4亿个图像-文本对上进行训练
- 通过对比学习,将匹配的图像和文本拉近,不匹配的推远
- 结果是一个强大的多模态表示空间
理论上,这应该让图像和文本特征完美对齐。但现实并非如此。
模态间隙的发现
研究人员发现,即使经过大规模预训练,视觉特征和文本特征仍然分布在不同的区域。这种现象被称为"模态间隙"。
更重要的是 ,这个间隙并非缺陷,而是反映了每个模态包含的独特信息:
- 视觉模态:擅长捕捉视觉细节、纹理、形状等
- 文本模态:擅长理解语义概念、抽象含义等
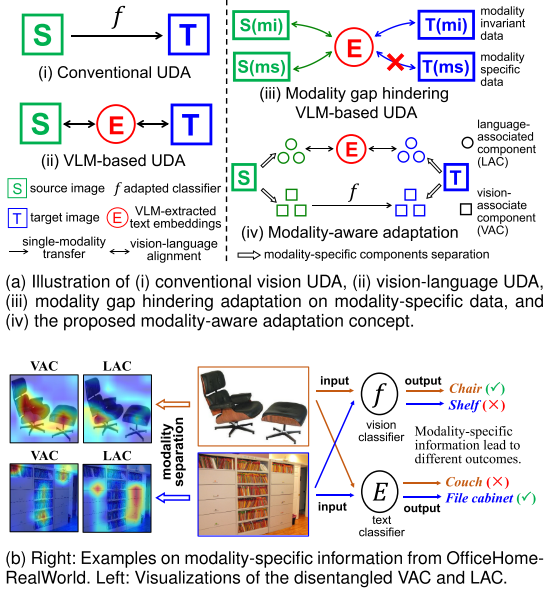
论文中给出了一个生动的例子(图1b):
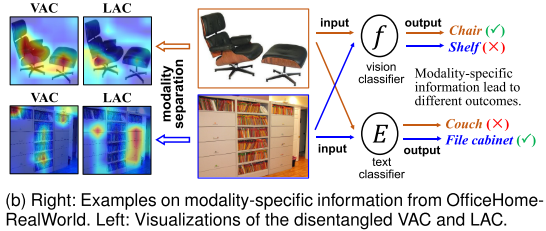
- 对于一把椅子的图片,视觉分类器表现更好(因为形状很直观)
- 对于一个文件柜的图片,文本分类器表现更好(因为需要语义理解)
现有方法的局限
当前的VLM域适应方法主要通过优化跨模态相似度来进行分类:
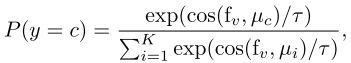
问题在于:
- 强制对齐会丢失模态特定信息
- 只转移模态不变知识,忽视了两个模态的互补优势
- 对所有样本采用相同策略,没有考虑样本级差异
UniMoS++的核心思想:分离而非对齐
与其试图消除模态间隙,UniMoS++提出:拥抱差异,分而治之。
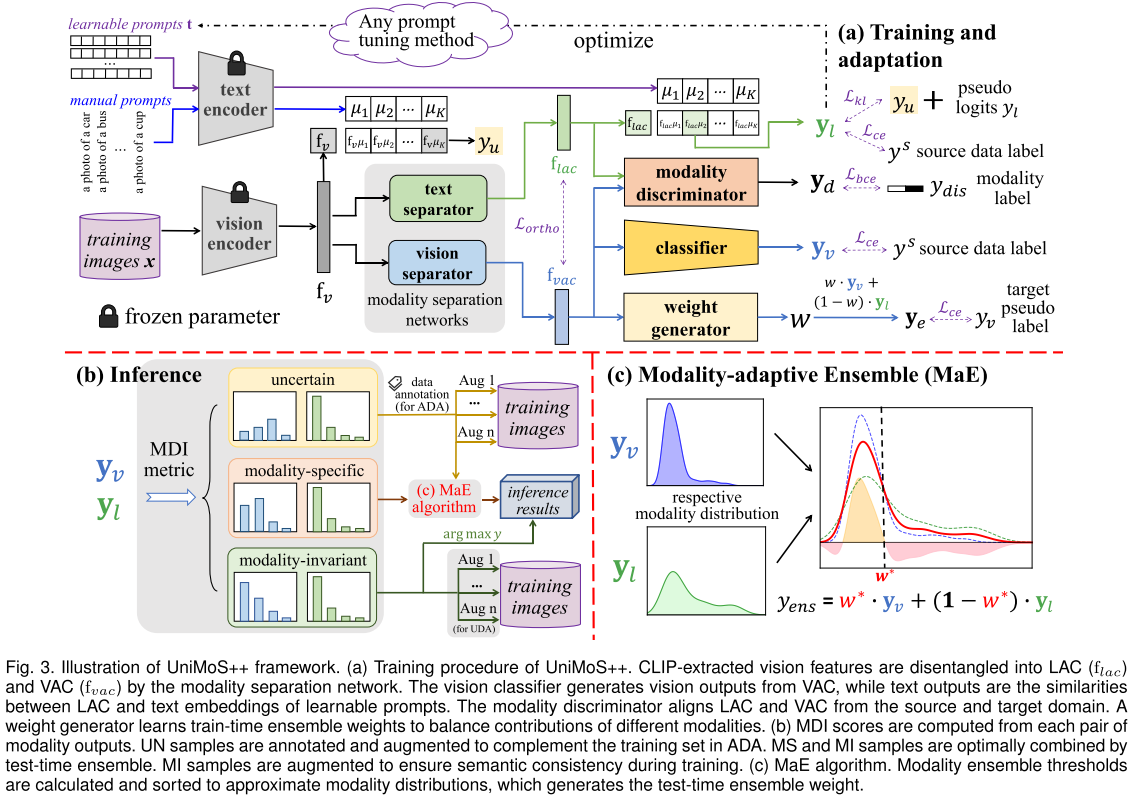
整体架构
UniMoS++的工作流程可以分为三个阶段:
1. 模态分离阶段
将CLIP提取的视觉特征f_v分解为两个组件:
-
VAC (Vision-Associated Component):视觉关联组件
-
LAC (Language-Associated Component):语言关联组件
f_vac = Q_v(f_v) # 视觉分离器
f_lac = Q_t(f_v) # 文本分离器
为了确保两个组件真正分离,引入正交损失:
L_ortho = ||diag(F_lac * F_vac^T)||²这确保了VAC和LAC在特征空间中正交,从而捕获不同的信息。
2. 模态感知训练阶段
对于LAC(语言关联组件):
-
使用CLIP的零样本预测作为教师知识
-
通过知识蒸馏优化:
L_lac = KL(y_l|x, y_u) + α * CE(y_l, y_source)
对于VAC(视觉关联组件):
-
使用K-means聚类生成视觉伪标签
-
引入可学习的训练时集成权重w:
y_e = w · y_v + (1-w) · y_l
为什么需要训练时集成? 论文提供了梯度分析:
∂L_vac/∂θ_v = [P_yv(y_e) - 1] · w · ∂y_v/∂θ_v这里的关键洞察是:
- 第一项 P_yv(y_e) - 1: 集成误差引导学习
- 第二项 w: 动态控制两个模态的重要性
- 在语言特定样本上,文本知识帮助平滑优化,而不强制破坏性的跨模态对齐
模态对齐: 使用模态判别器D分别对齐源域和目标域的VAC和LAC:
L_d = E[L_bce(D(x_source), label_modality)] +
E[L_bce(D(x_target), label_modality)]3. 测试时自适应集成(MaE)
这是UniMoS++相比原版UniMoS的重大改进。
问题: 如何自动确定最优集成权重w*?
解决方案: MaE算法
假设集成结果与视觉或文本输出一致,定义集成阈值:
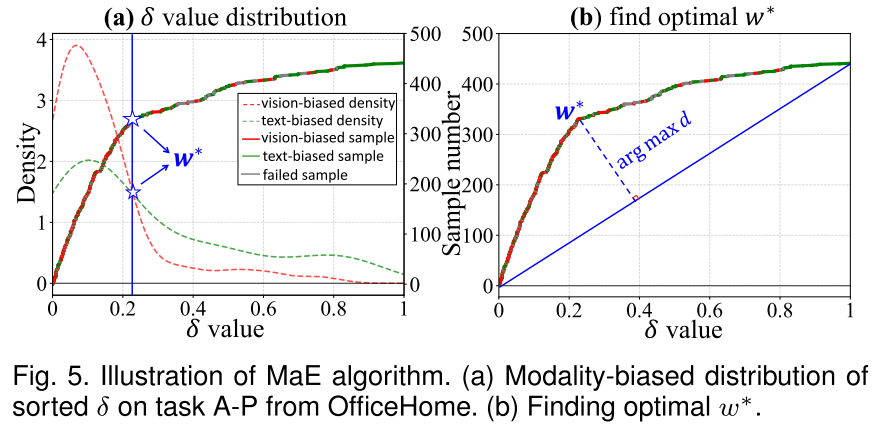
δ = (l_j - l_i) / (Δ_i - Δ_j)其中:
- 如果 w* > δ: 视觉模态占主导
- 如果 w* < δ: 文本模态占主导
关键思想:在排序后的δ值曲线中找到偏离直线最远的点,这个点近似最优的w*。
为什么这样有效?
- 视觉偏向样本和文本偏向样本的δ分布形成凸曲线
- 最大偏离点正是两种分布密度曲线的交点
- 这个点代表了最佳的模态平衡
MDI度量:理解样本的模态特性
UniMoS++的另一个重要贡献是模态差异指标(MDI),它实现了实例级的模态特性评估。
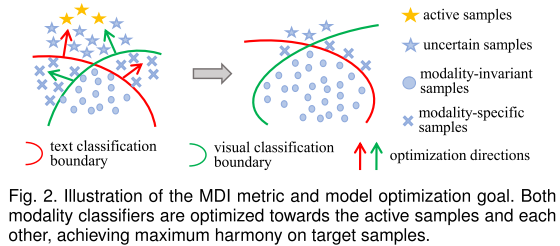
三种样本类型
1. 模态不变(MI)样本
定义: 跨模态预测一致的样本
T_MI = {x | top1(y_v) = top1(y_l)}MI分数: 综合考虑一致性和置信度
MI(y_v, y_l) = val1(y_v)·val1(y_l) - val2(y_v)·val2(y_l)作用:
- 这些样本要么很简单,要么已被很好学习
- 用于数据增强,确保预测一致性
- 避免"模态坍塌"(两个模态产生过度相似的错误结果)
2. 模态特定(MS)样本
定义: 对称的模态预测
T_MS = {x | top1(y_v) = top2(y_l) AND top2(y_v) = top1(y_l)}特点:
- 包含丰富的模态特定信息
- 在某个模态下更容易识别
示例:

- 一张台球桌的图片:视觉上是桌子,但语义上很特殊
- 这类样本在不同模态下有不同的"最佳解读"
处理策略: 使用MaE自动找到最优权重,强调"正确"的模态
3. 不确定(UN)样本
定义: 既非MI也非MS的样本
UN分数: 衡量不确定性
UN(y_v) = val1(y_v) - val2(y_v) # 越低越不确定细分:
- UN-a (UN-annotate): 完全不同的跨模态结果 → 优先标注
- UN-e (UN-ensemble): 其他不确定样本 → 通过集成改进
在主动学习中的作用:
- 传统方法(如基于能量的方法)可能选择已经学好的样本
- MDI能识别真正需要标注的难样本
- 实验显示:MDI选择的样本准确率比Energy方法低19.5%,说明更具信息量
MDI的实际效果
论文图4展示了真实案例(Mini-DomainNet, clp→rel):
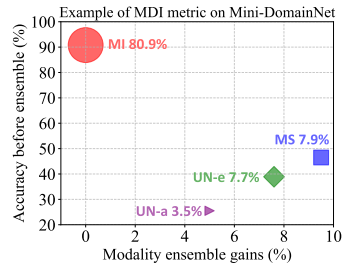
- MI样本: 80.9%,占大多数,准确率高
- MS样本: 7.9%,集成效果最显著(+7.9%)
- UN-a样本: 3.5%,准确率最低(~25%),最需要标注
- UN-e样本: 7.7%,介于两者之间
实验结果:全面的性能验证
1. 无监督域适应(UDA)
OfficeHome数据集 (4个域,65类):
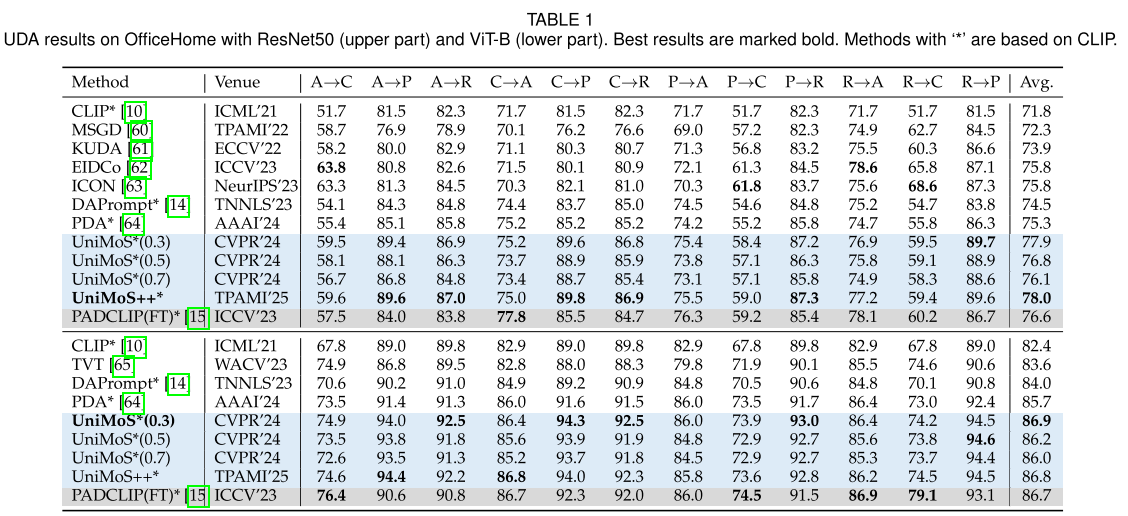
- ResNet50: 78.0% (vs. 最佳基线75.8%)
- ViT-B: 86.8% (与完全微调的PADCLIP持平,但效率高9倍)
关键观察: 不同的固定权重w*导致性能波动:
- w*=0.3: 77.9%
- w*=0.5: 76.8%
- w*=0.7: 76.1%
- MaE(自动): 78.0% ✓
DomainNet数据集 (6个域,345类):
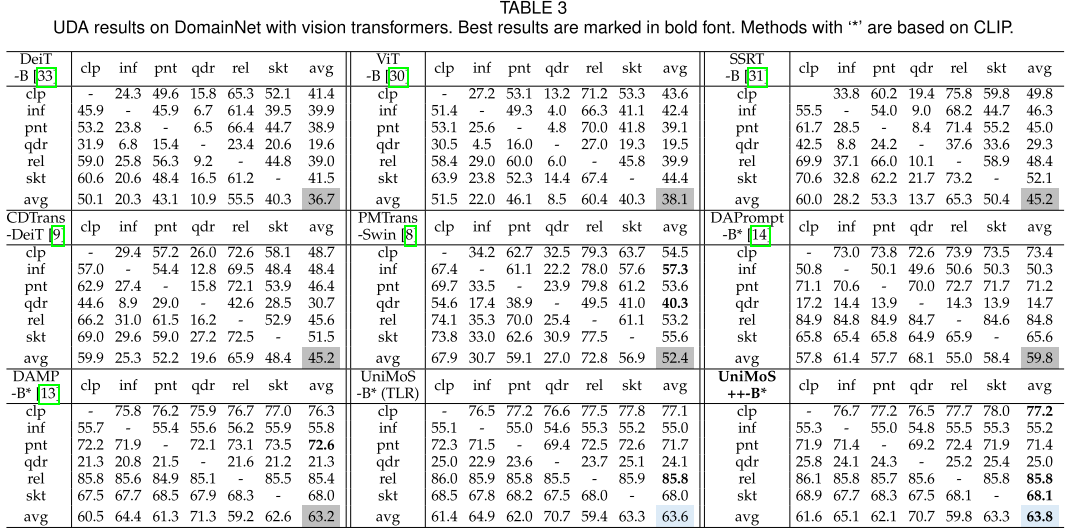
- 平均准确率: 63.8%
- 最难的quickdraw域: 25.0% (vs. DAMP的21.3%)
- 相比DAMP提升0.6个百分点
VisDA-2017 (合成→真实):
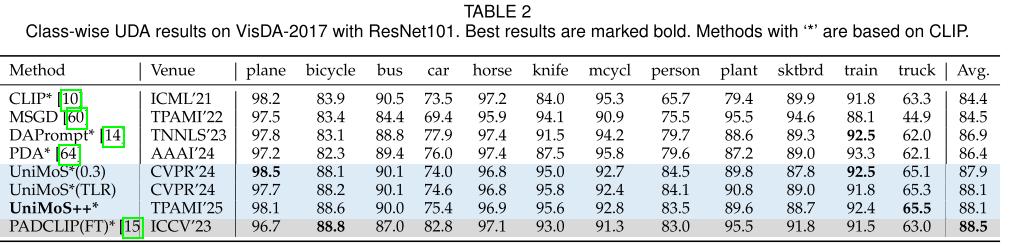
- 88.1%,在多数类别上最佳
- 略低于完全微调的PADCLIP(88.5%),但计算成本低得多
2. 主动域适应(ADA)
这是UniMoS++表现最亮眼的场景!
OfficeHome (5%标注预算):
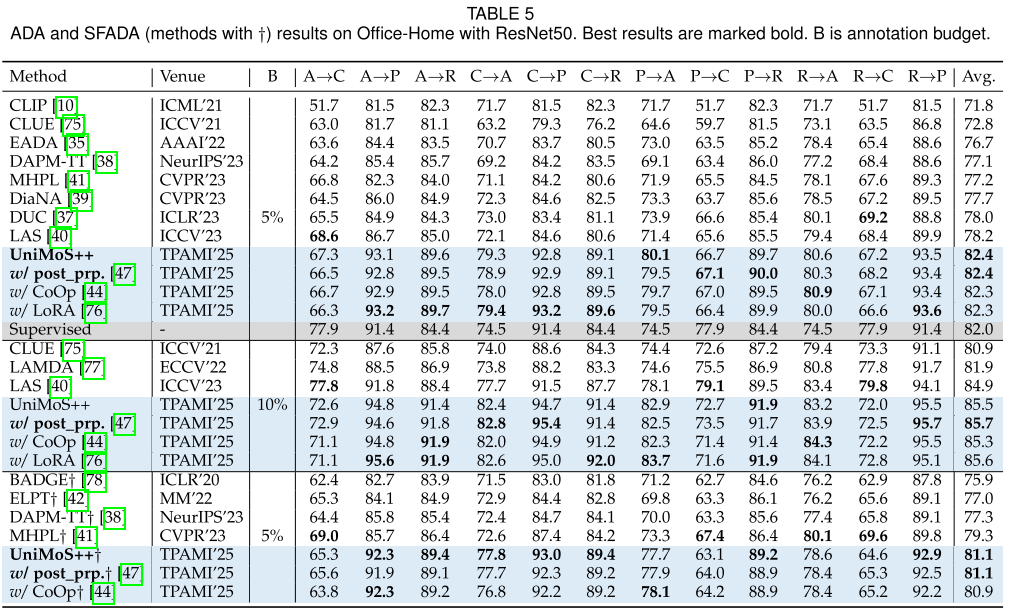
- 82.4% vs. 最佳基线77.7%(LAS)
- 提升4.7个百分点
- 甚至超过完全监督(82.0%)!
不同标注预算的对比(图7a):
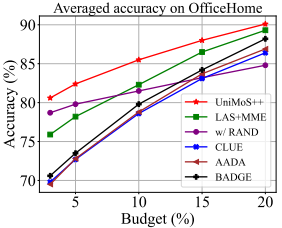
Mini-DomainNet (5%标注):
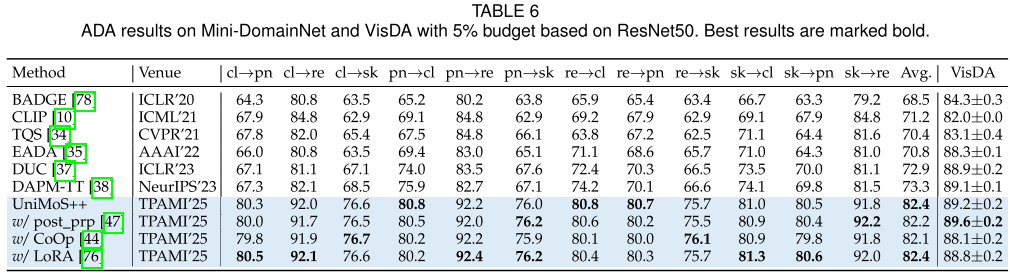
- 82.4% vs. 73.3%(DAPM-TT)
- 提升9.1个百分点 - 这是最显著的改进!
VisDA (5%标注):
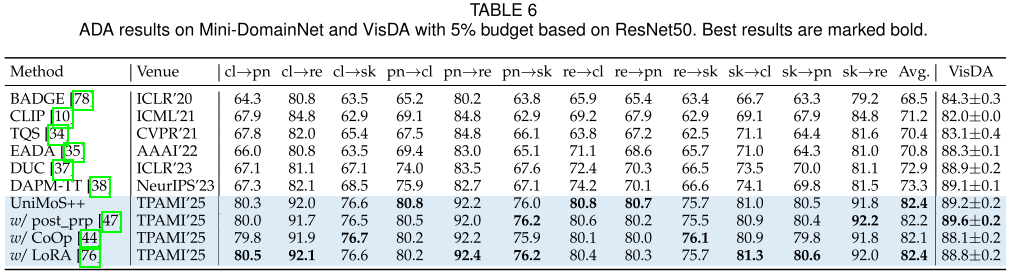
- 89.2±0.2%,超越所有基线
与不同提示调优方法的兼容性:
方法 OfficeHome (5%)
UniMoS++ 82.4%
+ DenseCLIP 82.4%
+ CoOp 82.3%
+ LoRA 82.3%3. 多源域适应(MSDA)
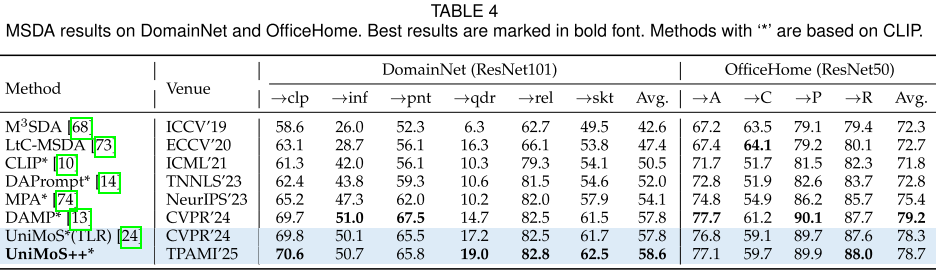
DomainNet:
- 58.6%,在所有6个目标域上超越现有方法
- MaE能够动态适应混合源域分布
4. 计算效率分析
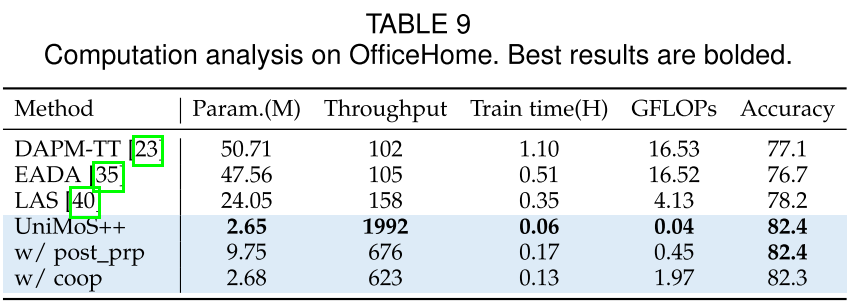
这可能是最令人印象深刻的结果:
| 方法 | 参数量(M) | 训练时间(H) | 吞吐量 | FLOPs(G) | 准确率 |
|---|---|---|---|---|---|
| DAPM-TT | 50.71 | 1.10 | 102 | 16.53 | 77.1% |
| EADA | 47.56 | 0.51 | 105 | 16.52 | 76.7% |
| LAS | 24.05 | 0.35 | 158 | 4.13 | 78.2% |
| UniMoS++ | 2.65 | 0.06 | 1992 | 0.04 | 82.4% |
关键数字:
- 参数量仅为DAPM-TT的5%
- 训练时间仅为EADA的12%
- 吞吐量是LAS的13倍
- FLOPs仅为LAS的1%
- 同时准确率最高!
5. 消融研究
论文表8提供了全面的消融分析:
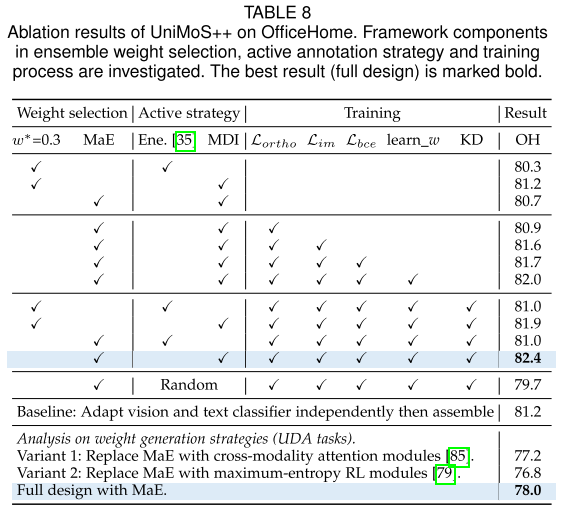
基准(无任何正则化):
- MDI + 固定w*=0.3: 80.9%
逐步添加组件:
+ L_ortho → 81.6% (+0.7%)
+ L_im → 81.7% (+0.1%)
+ L_bce (模态判别器) → 82.0% (+0.3%)
+ learn_w (可学习训练权重) → 81.0% (-1.0%, 说明需要配合其他组件)
+ KD (知识蒸馏) → 81.9% (+0.9%)
+ MaE (自适应集成) → 82.4% (+0.5%)完整配置: 82.4%
有趣的发现:
- 单独去掉MaE → 81.0%,说明MaE贡献0.5%
- 单独去掉MDI → 81.0%,说明MDI贡献0.5%
- 使用随机选择替代MDI → 79.7%,说明MDI选择策略很重要
对比独立训练基线: 81.2%
- 说明跨模态交互训练确实有帮助(+1.2%)
对比其他权重生成策略:
- 基于注意力的模块: 77.2% (需要源域监督,泛化差)
- 基于强化学习的模块: 76.8% (忽视模态信息)
- MaE (UniMoS++): 78.0% ✓
可视化分析:直观理解UniMoS++
特征分布可视化(图6)

论文使用t-SNE提供了丰富的可视化:
(a) CLIP原始特征:
- 源域(绿)和目标域(蓝)特征分离
- 文本特征(粉)形成独立的簇
- 明显的域间隙和模态间隙
(e) 分离后的VAC和LAC:
- VAC(紫)和LAC(蓝)形成清晰边界
- 证明模态分离网络有效工作
(b,c) MDI选择的主动样本:
- VAC和LAC中的主动样本(红点)分布在不确定区域
- 正确捕获了模型未学好的样本
(f,g) Energy方法选择的主动样本:
- 许多红点落在密集簇中(框出部分)
- 这些是已经学好的样本,标注价值低
(d) 训练后对齐的特征:
- 源域和目标域特征紧密对齐
- 结构紧凑,证明有效的域适应
(h) 训练后的主动样本:
- 与(b)对比,大部分主动样本已被学好
- 证明标注发挥了作用
MDI示例(图7d)
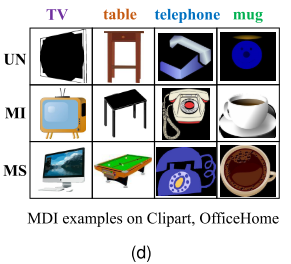
来自OfficeHome Clipart域的真实样本:
模态不变(MI):
- 电视、桌子、电话、杯子
- 视觉和语义都很典型,容易识别
模态特定(MS):
- 显示器、绿色桌子、复杂图案盘子、带木纹的杯子
- 视觉细节丰富但语义可能模糊,或相反
不确定(UN):
- 模糊的显示屏、黑暗中的桌子、侧面的电话、奇怪角度的杯子
- 即使对人类也具有挑战性
技术深度:关键设计决策
1. 为什么要正交约束?
L_ortho确保VAC和LAC真正捕获不同的信息:
# 伪代码
F_vac = separate_vision(features) # [B, d]
F_lac = separate_text(features) # [B, d]
# 计算批内样本的VAC-LAC相似度矩阵
similarity = F_lac @ F_vac.T # [B, B]
# 只惩罚对角线(配对的VAC-LAC)
L_ortho = ||diag(similarity)||²为什么不惩罚所有配对?
- 论文设计只约束配对的VAC-LAC正交
- 允许不同样本间的VAC或LAC相似(保持语义结构)
- 这比域分离网络56的完全解耦更温和
2. 训练时集成的梯度分析
论文提供了详细的梯度分析,解释为什么训练时集成有效:
对于视觉分支 (方程21):
∂L/∂θ_v = [P_yv(y_e) - 1] · w · ∂y_v/∂θ_v三个关键项:
- P_yv(y_e) - 1 : 集成误差
- 当集成预测错误时,梯度大
- 引导学习向正确方向
- w : 动态权重
- 在不确定伪标签时,小w减轻负面影响
- 自适应控制学习强度
- ∂y_v/∂θ_v: 标准梯度项
对于权重生成器 (方程22):
∂L/∂θ_w = [P_yv(y_e) - 1] · [y_v - y_l] · ∂w/∂θ_w关键洞察:
- y_v - y_l: 模态差异
- 当两个模态预测差异大(MS或UN样本)时,梯度大
- 学习给正确的模态更大权重
3. MaE算法的数学基础
核心不等式:
如果集成结果应该与视觉一致:
w*·v_i + (1-w*)·l_i > w*·v_j + (1-w*)·l_j
w*·(v_i - l_i) + l_i > w*·(v_j - l_j) + l_j
w*·(Δ_i - Δ_j) > l_j - l_i
w* > δ = (l_j - l_i) / (Δ_i - Δ_j)几何解释:
- δ是一个阈值,划分视觉主导和文本主导区域
- 所有样本的δ值排序后形成曲线
- 视觉偏向和文本偏向样本的分布密度曲线交点 = 最优w*
- 找到偏离直线最远的点来近似这个交点
实现:
def find_optimal_weight(vision_logits, text_logits):
# 计算每个样本的δ
i = torch.argmax(vision_logits, dim=1)
j = torch.argmax(text_logits, dim=1)
delta_i = vision_logits[i] - text_logits[i]
delta_j = vision_logits[j] - text_logits[j]
delta_l = text_logits[j] - text_logits[i]
delta = delta_l / (delta_i - delta_j + 1e-8)
# 排序
sorted_delta, indices = torch.sort(delta)
# 找到最大偏离点
N = len(delta)
deviations = []
for k in range(N):
# 计算点(sorted_delta[k], k)到直线的距离
deviation = distance_to_line(sorted_delta[k], k, N)
deviations.append(deviation)
k_star = torch.argmax(deviations)
w_star = sorted_delta[k_star]
return w_star4. 为什么MDI分数设计成乘积形式?
MI分数:
MI(y_v, y_l) = val1(y_v)·val1(y_l) - val2(y_v)·val2(y_l)设计理由:
-
第一项 val1(y_v)·val1(y_l):
- 两个模态最高置信度的乘积
- 同时考虑双模态的确定性
- 避免"一个模态自信但另一个不确定"的情况
-
第二项 val2(y_v)·val2(y_l):
- 第二置信度的乘积
- 衡量其他类别的干扰
- 更大的gap = 更可靠的预测
-
为什么不用和或平均?
- 和: 可能被单个高置信度主导
- 平均: 缺乏对双模态一致性的强调
- 乘积: 自然地要求两个模态都自信
示例:
情况A: y_v=[0.9, 0.05, ...], y_l=[0.9, 0.05, ...]
MI = 0.9*0.9 - 0.05*0.05 = 0.8075 ← 高分,应选择
情况B: y_v=[0.9, 0.05, ...], y_l=[0.6, 0.3, ...]
MI = 0.9*0.6 - 0.05*0.3 = 0.525 ← 中等分
情况C: y_v=[0.6, 0.35, ...], y_l=[0.6, 0.35, ...]
MI = 0.6*0.6 - 0.35*0.35 = 0.2375 ← 低分,虽然一致但不确定局限性与未来方向
当前局限
-
OOD泛化: 在WILDS的iWildCam任务上表现不佳(32.4% vs. VDPG的30.1%)
- 需要更专业的领域知识
-
完全合成域: VisDA上略低于完全微调方法
- 极端域间隙可能需要更深度的适应
-
超参数: 虽然α, β在0.01, 1范围内相对鲁棒,但仍需调整
未来方向
-
更强的专家领域适应
- 结合领域特定先验知识
- 探索few-shot学习与MDI的结合
-
动态模态分离
- 当前VAC/LAC比例是固定的
- 可以学习实例级的分离比例
-
扩展到其他VLM
- 当前主要基于CLIP
- 探索ALIGN、BLIP等模型
-
多模态主动学习理论
- MDI为多模态AL提供了新视角
- 值得深入理论分析
实践建议
如果你想在自己的项目中使用UniMoS++,这里有一些建议:
1. 何时使用UniMoS++?
推荐场景:
- ✅ 有预训练VLM(如CLIP)
- ✅ 计算资源有限(不能全参数微调)
- ✅ 源域和目标域差异明显
- ✅ 可以获得少量目标域标注(ADA)
不推荐场景:
- ❌ 从零训练模型
- ❌ 源域和目标域非常相似(简单方法可能就够了)
- ❌ 需要实时在线适应(虽然推理快,但需要离线训练)
2. 超参数设置
基于论文的实验:
# 通用设置(适用于大多数任务)
config = {
'alpha': 1.0, # 源域LAC权重
'beta': 1.0, # 源域VAC权重
'gamma': 0.01, # 正则化权重
'learning_rate': 3e-3,
'batch_size': 32,
'epochs': 60, # OfficeHome, DomainNet
# 'epochs': 10, # VisDA
'bottleneck_dim': 256,
'MI_threshold': 0.9, # top 10% MI samples
}
# 如果源域质量较差(如VisDA合成数据)
config_synthetic = {
'alpha': 0.01, # 降低源域权重
'beta': 0.01,
# 其他同上
}3. 实现检查清单
实现UniMoS++时,确保:
- CLIP特征只提取一次,保存备用
- 模态分离网络使用线性层(轻量)
- 正交损失只约束配对的VAC-LAC
- 训练时集成使用detach(yl)
- MaE每3个epoch更新一次
- MDI分类在每个epoch重新计算
- MI样本用于数据增强
- UN样本优先标注(ADA)
4. 调试技巧
如果性能不佳:
-
检查模态分离:
# VAC和LAC应该有明显差异 similarity = F.cosine_similarity(F_vac, F_lac, dim=1) print(f"VAC-LAC平均相似度: {similarity.mean()}") # 期望: < 0.3 -
检查MDI分布:
print(f"MI: {len(T_MI)/len(T_all)*100:.1f}%") print(f"MS: {len(T_MS)/len(T_all)*100:.1f}%") print(f"UN: {len(T_UN)/len(T_all)*100:.1f}%") # 期望: MI最多,MS和UN各占一定比例 -
检查MaE权重:
print(f"测试时权重w*: {w_star:.3f}") # 期望: 0.2 - 0.8之间,不应极端(0或1) -
可视化特征:
- 使用t-SNE检查VAC和LAC是否真正分离
- 检查主动样本是否在决策边界附近
总结
UniMoS++代表了VLM域适应研究的重要进展。它的核心洞察是:模态间隙不是敌人,而是可以利用的资源。
关键创新:
- 模态分离框架: 保护和利用模态特定信息
- MaE算法: 自动确定最优集成权重
- MDI度量: 实例级模态特性评估
- 统一范式: 兼容多种适应设置
实际价值:
- 高效: 9倍计算效率提升
- 有效: 最高9%性能提升
- 灵活: 兼容各种提示调优和PEFT方法
- 实用: 支持UDA、ADA、MSDA、SFADA等多种场景
这项工作不仅提供了一个强大的工具,更重要的是为VLM适应研究开辟了新方向:如何在尊重模态差异的前提下,最大化利用多模态预训练知识。
本文详细解析了UniMoS++的技术原理和实验结果。如果您对特定部分有疑问,欢迎在评论区讨论!