一张图真能抵得上千言万语?DeepSeek-OCR给出了一个令人兴奋的答案。
最近,DeepSeek-AI 团队发布了一项名为 DeepSeek-OCR 的新技术,它不仅在 OCR(光学字符识别)任务上表现出色,更提出了一种全新的思路:用图像作为文本的高效压缩媒介。这项技术看似只是"读图识字",实则可能撬动大模型处理长上下文、构建记忆机制、甚至实现"无限上下文"的关键一步。
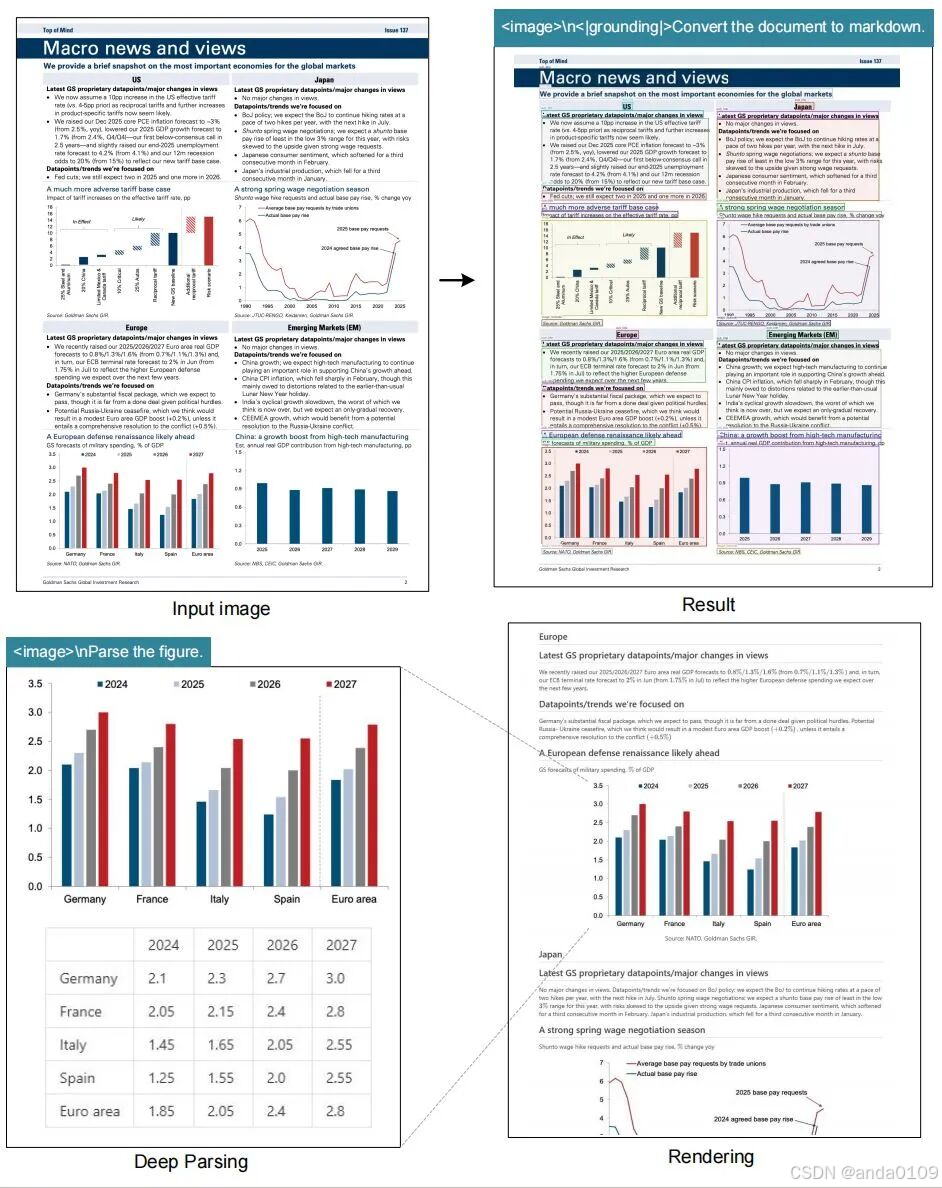
如图,左侧是图片,右侧是通过DeepSeek-OCR解析出来内容,几乎可以完美还原原始图片的内容。而传统的OCR,只能提取出图片中的文本,而文字之间的相互关系则一概不知。
大模型"记不住"长文本
当前基于Transformer架构的大语言模型(LLM)在处理超长文本时面临巨大挑战。原因很简单:计算开销随文本长度呈平方级增长。比如,处理一篇 10 万字的文档,模型不仅要耗费大量显存,推理速度也会急剧下降。
于是,研究人员开始思考:有没有办法把长文本"压缩"一下,让模型用更少的资源记住更多内容?
有趣的是,人类早就这么做了------我们用一张图表总结一页报告,用一张照片记录一段旅程。那么,大模型能不能也"看图说话",从一张图里还原出大量文字?
这就是 DeepSeek-OCR 要探索的核心问题。
DeepSeek-OCR 是什么?
DeepSeek-OCR 是一个端到端的视觉语言模型(VLM),专门用于将文档图像"翻译"回原始文本。但它不只是传统 OCR 的升级版,而是把 OCR 当作一个"压缩-解压"实验:
压缩端:把一段文字渲染成一张图像(比如 PDF 转图片)。
解压端:模型从这张图像中尽可能准确地还原出原始文字。
这个过程,论文称之为 "Contexts Optical Compression"(上下文光学压缩)。
核心组件:
DeepEncoder:一个新型视觉编码器,能在高分辨率下保持低显存占用,并将图像压缩成极少的"视觉 token"(比如 100 个)。
DeepSeek-3B-MoE 解码器:一个稀疏激活的 30 亿参数语言模型,负责从压缩后的视觉 token 中"解码"出原始文本。
惊人效果:100 个 token 还原 1000 字
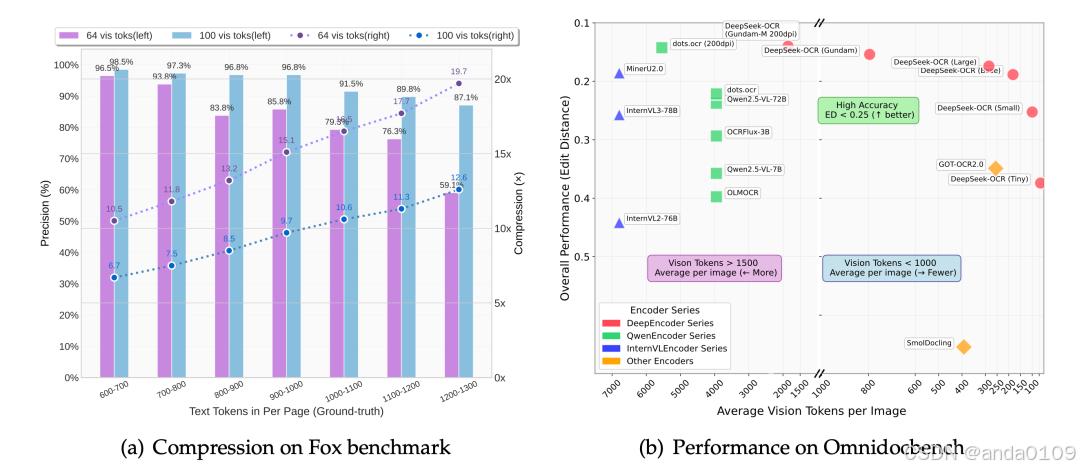
实验结果显示:
当压缩比 ≤ 10 倍(即 1000 字文本用 100 个视觉 token 表示),OCR 精度高达 97%;
即使压缩到 20 倍(2000 字 → 100 token),准确率仍有 60%。
这意味着:一张 640×640 的图片,就能承载近 1000 字的文本信息,且几乎无损还原。
在权威 OCR 基准 OmniDocBench 上,DeepSeek-OCR 仅用 100 个视觉 token,就超过了 GOT-OCR2.0(需 256 token);用不到 800 token,就打败了需要 7000+ token 的 MinerU2.0。
更厉害的是,它还能处理:
多语言文档(支持近 100 种语言)
化学公式(转 SMILES 格式)
图表(转 HTML 表格)
几何图形(解析线段与坐标)
自然图像描述(保留通用视觉理解能力)
不只是 OCR:为大模型"造记忆"
DeepSeek-OCR 的真正野心,不在 OCR 本身,而在于为大模型提供一种模拟人类记忆遗忘机制的新范式。
想象一下:
最近的对话 → 用高分辨率图像保存(细节清晰,token 多)
一周前的记录 → 缩小成中等图(信息略模糊,token 少)
一年前的历史 → 压缩成极小缩略图(仅保留关键信息,token 极少)
这就像人类记忆:越久远的事,记得越模糊。而 DeepSeek-OCR 通过"图像分辨率 + token 数量"的双重控制,天然实现了这种渐进式遗忘。
论文甚至画了一张图(Figure 13)来类比:
时间 → 图像尺寸 → token 数量 → 信息保真度
越久远,图越小,token 越少,文字越模糊------但依然"记得一点"。
这为构建超长上下文、低成本记忆系统提供了全新可能。
实际价值:每天处理 20 万页文档
DeepSeek-OCR 不只是实验室玩具。据论文披露:
在单台 A100-40G GPU 上,每天可处理 20 万+ 页文档;
若用 20 节点集群(160 张 A100),日处理量达 3300 万页!
这意味着它可以:
为 LLM/VLM 大规模生成高质量训练数据;
自动解析历史档案、学术论文、财报、教材等;
构建企业级文档智能系统,替代传统 OCR 流水线。
未来展望:光学压缩,或是大模型的"第二大脑"
DeepSeek-OCR 的提出,让我们重新思考视觉与语言的关系:
视觉不仅是"看图问答"的辅助模态,更可能是文本信息的高效载体。
未来,我们或许会看到:
混合上下文系统:近期用文本 token,远期用图像 token;
光学记忆库:将历史对话自动渲染为图像存档,按需调用;
无限上下文 LLM:通过"光学压缩 + 分级存储",突破上下文长度限制。
正如论文所说:"A picture is worth a thousand words" 不再是比喻,而是一种可计算、可优化的技术路径。
结语
DeepSeek-OCR 不仅是一个强大的 OCR 工具,它可以用于处理复杂的文档、公式、图表解析等。
更是一次对大模型记忆与压缩机制的深刻探索。它告诉我们:有时候,让模型"看一眼",比让它"读万字"更高效。
随着多模态大模型的发展,"视觉即压缩"或许将成为下一代 AI 系统的核心能力之一。也期待视觉压缩技术在LLM中尽早应用起来,以解决超长上下文带来种种问题。