openJiuwen 0 基础入门:工作流编排从零到一及深度踩坑指南、

前言:什么是工作流?
在接触 openJiuwen 之前,我对"工作流"(Workflow)这个概念几乎一无所知。听起来像是企业级系统里的高深术语,但其实它的本质非常简单:
工作流 = 一系列按顺序执行的任务流程
在 AI 智能体(Agent)场景中,工作流就是:
用户提问 → 系统处理 → 返回答案 的完整链条。
而 openJiuwen 工作流 正是该平台的核心执行引擎。官方定义如下:
openJiuwen 工作流是 openJiuwen Agent 平台的核心执行引擎,通过可视化编排帮助用户快速构建和管理流程型 Agent,实现业务流程自动化。平台支持零代码用户通过拖拽式界面完成流程搭建,同时为低代码用户提供代码执行、插件调用和条件分支等功能,满足复杂场景需求。
简单说:你不用写一行代码,就能搭出一个会思考、会回答、会调用工具的 AI 助手!
本文将带你从 完全零基础 出发,一步步搭建你的第一个工作流,并记录我踩过的所有坑------帮你少走弯路!
第一步:部署与进入工作流编辑器
1.1 部署 openJiuwen
我选择在 Ubuntu 24.04 上通过 Docker 部署 openJiuwen。如果你尚未部署,可参考我的上一篇文章:
👉 《DeepSeek-V3.2 模型在 OpenJiuWen 中的部署实践》
部署完成后,访问 http://<your-ip>:port,即可看到主界面。
1.2 进入工作流模块
登录后,在左侧导航栏找到 「工作流」 并点击:
你会看到一个空白的工作流列表页面。
第二步:创建工作流项目
点击 「创建工作流」 按钮:
填写基本信息:
| 字段 | 说明 |
|---|---|
| 名称 | 如 智能客服Demo |
| 标识符(ID) | 只能包含字母、数字、下划线 (如 smart_customer_service)⚠️ |
| 描述 | 可选,用于说明用途 |
❗ 重要提醒 :标识符(ID)一旦创建无法修改,且必须符合命名规范。不要使用中文、空格、横线(
-)等!
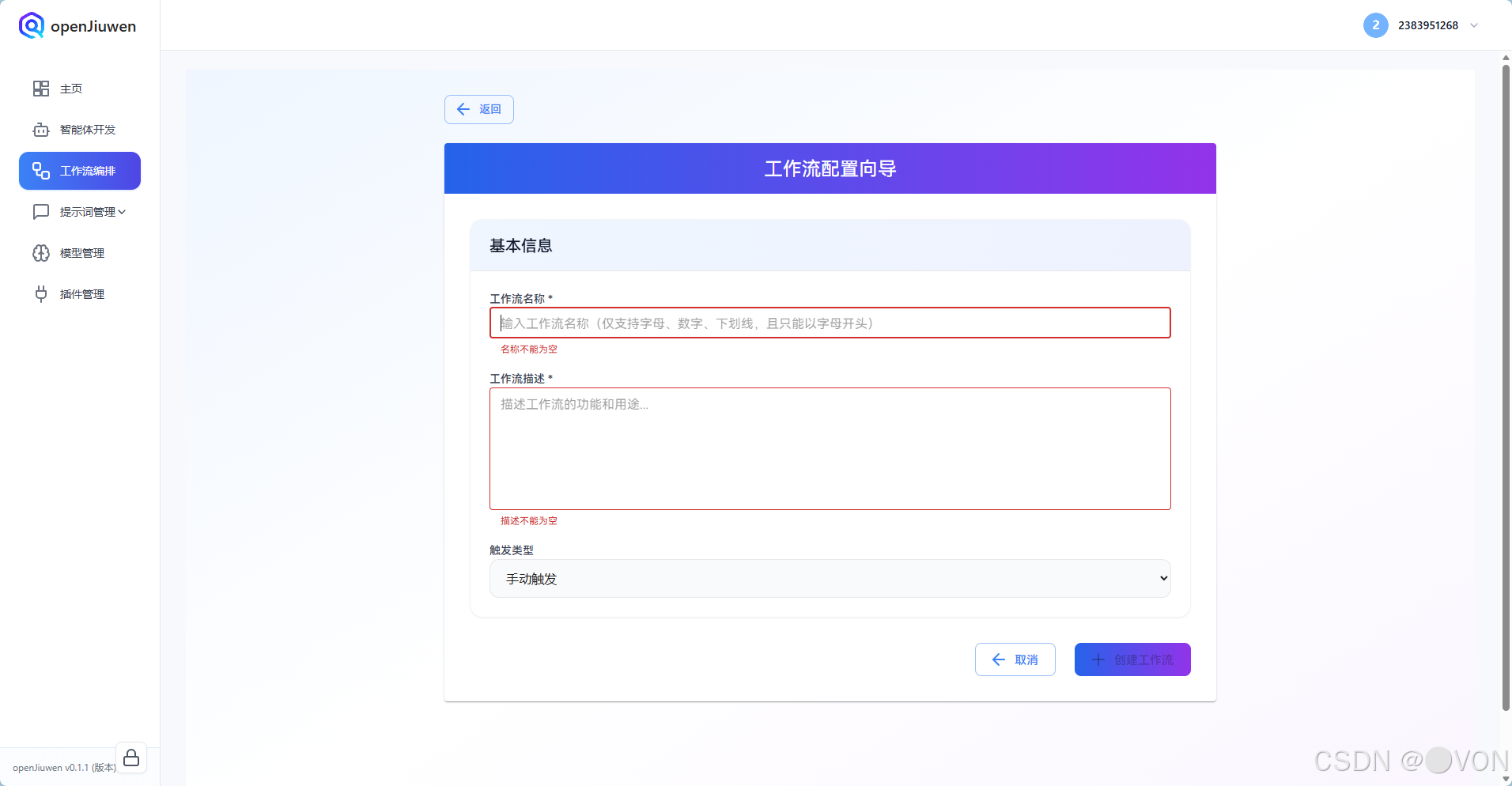
点击「确定」后,进入可视化编辑界面。
第三步:理解三大核心节点
创建工作流后,默认会包含两个节点:
- 🟢 开始(Start)
- 🟣 结束(End)
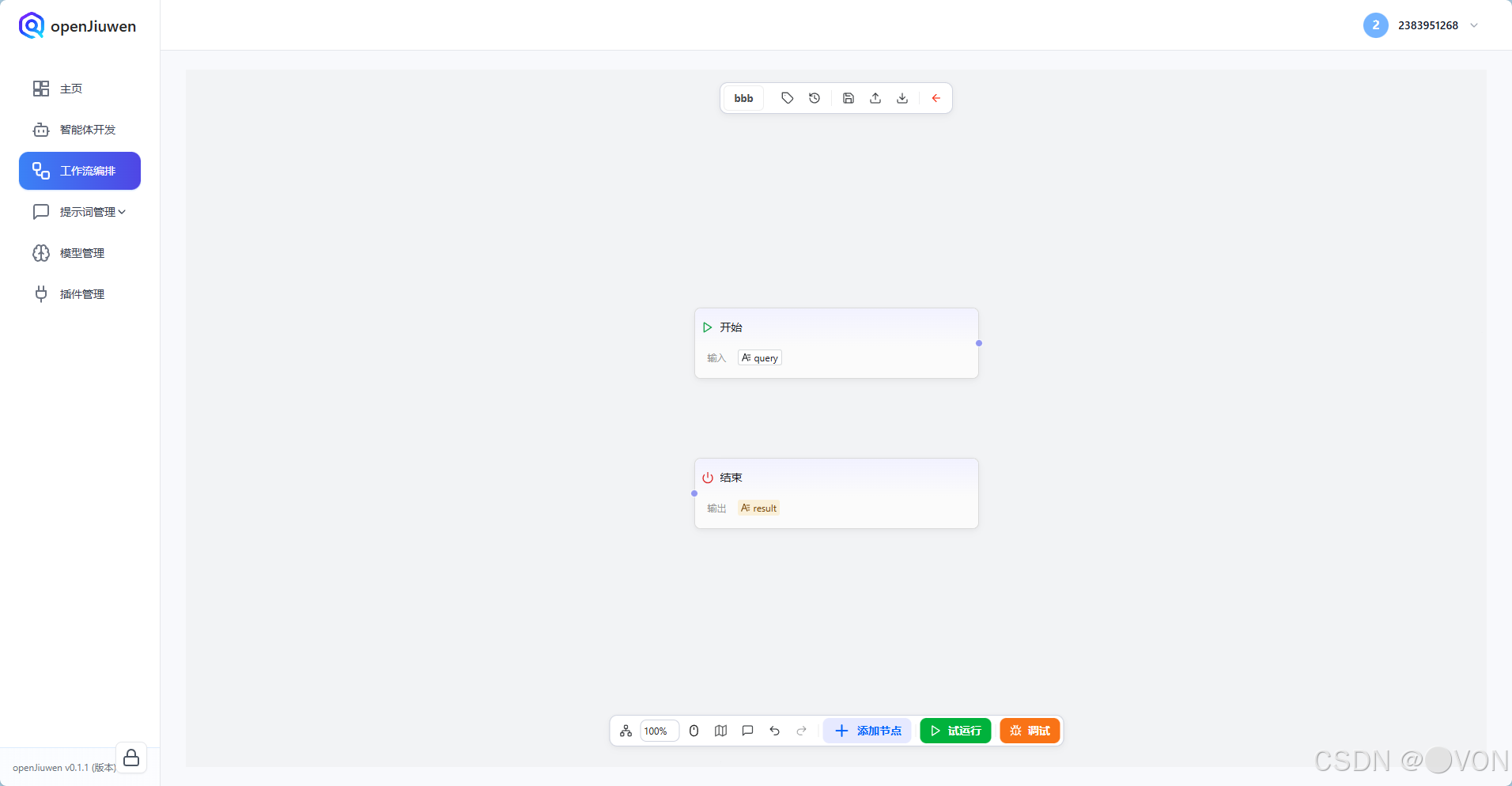
此时的流程是断开的,你需要添加中间的"处理逻辑"。
3.1 节点类型简介
openJiuwen 支持多种节点类型,初学者只需掌握以下三种:
| 节点 | 作用 | 是否必需 |
|---|---|---|
| 开始 | 接收外部输入(如用户问题) | ✅ 是 |
| 大模型(LLM) | AI 思考与生成回答 | ✅ 核心 |
| 结束 | 返回最终结果 | ✅ 是 |
其他高级节点(插件、条件判断、代码工具等)可在后续扩展时使用。
3.2 添加大模型节点
- 将「开始」和「结束」节点水平对齐
- 在中间空白处 双击 或点击 「+」
- 选择 「大模型」 节点
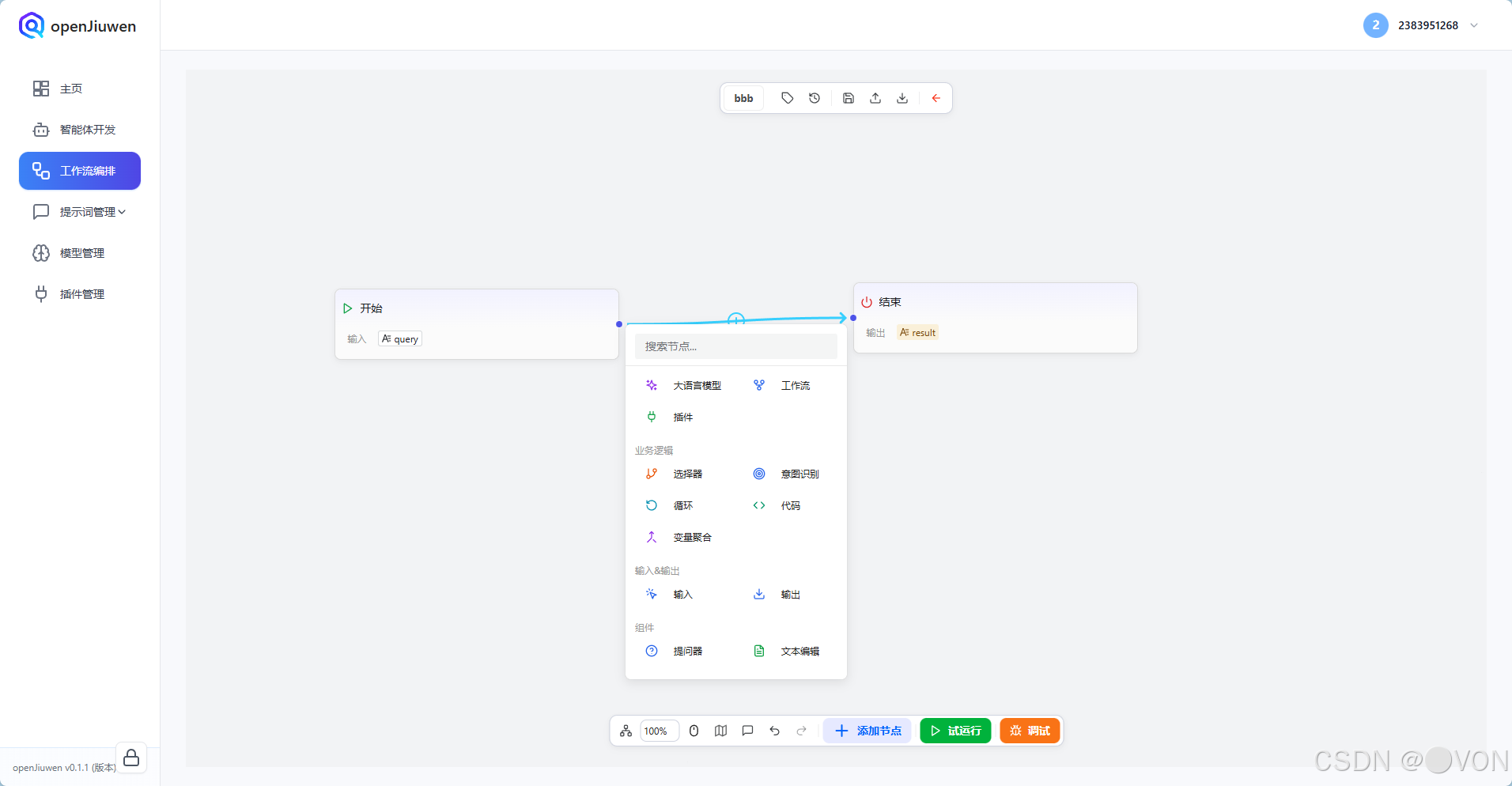
拖入后,连接成:
[开始] → [大模型] → [结束]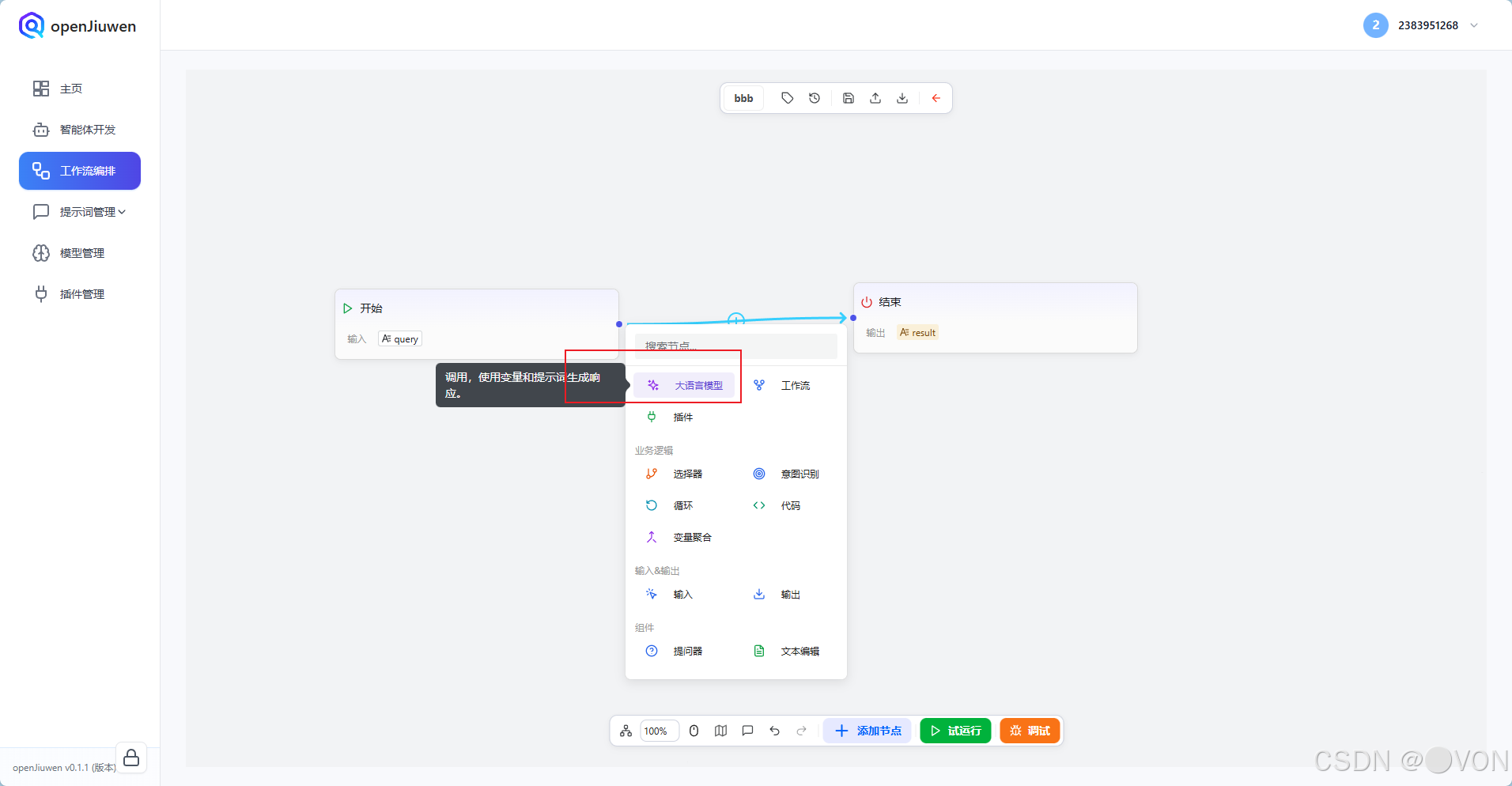
第四步:配置大模型节点(关键!)
这是整个工作流成败的核心!很多人卡在这里,包括我。
点击「大模型」节点,右侧弹出配置面板:
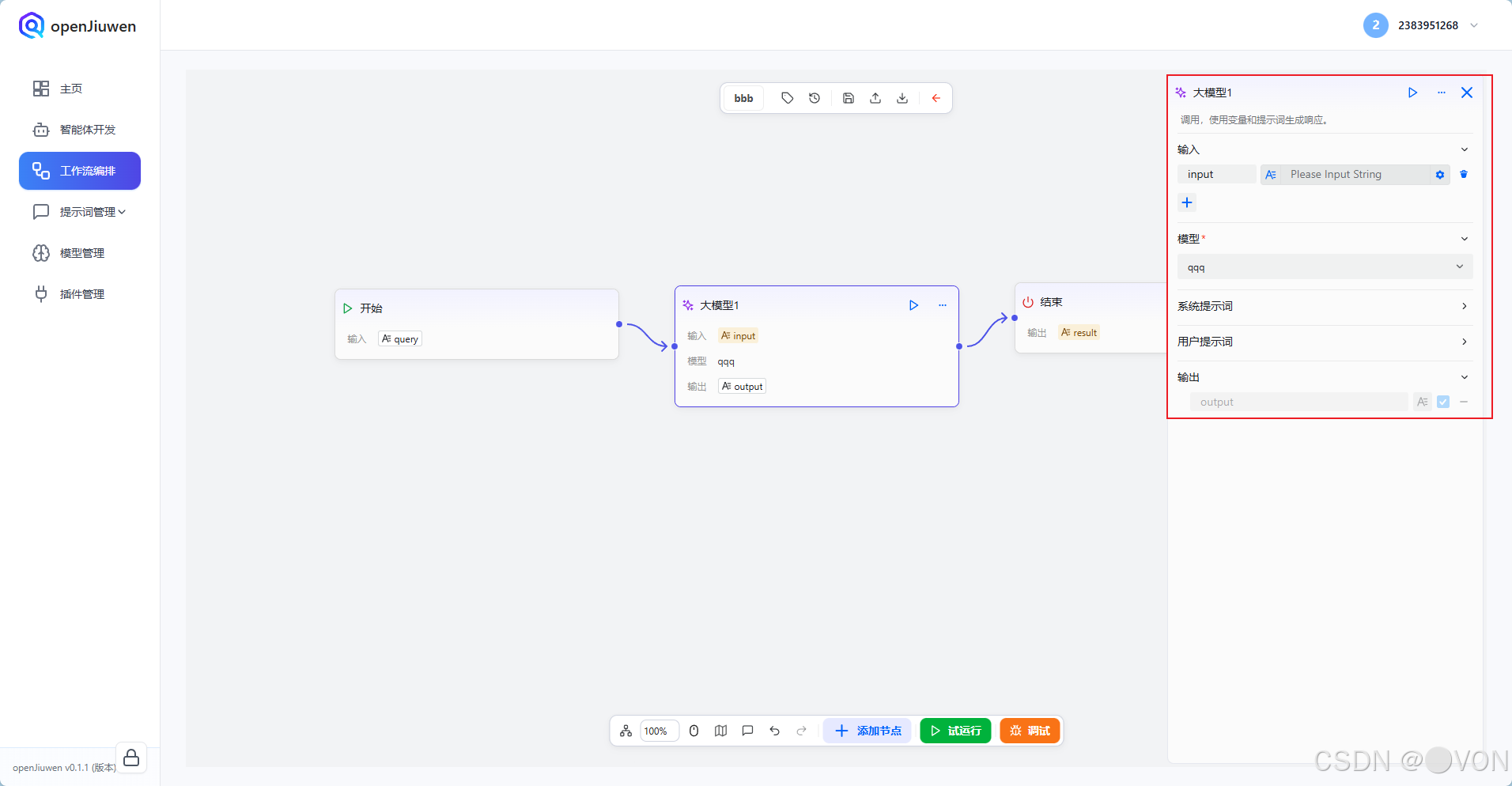
4.1 配置输入绑定(Input Binding)
在「输入」区域,你会看到一个字段 input。
错误做法(我最初的做法):
- 什么都不填
- 或者手动输入
{input}
正确做法 :
点击 input 字段右侧的 变量选择器
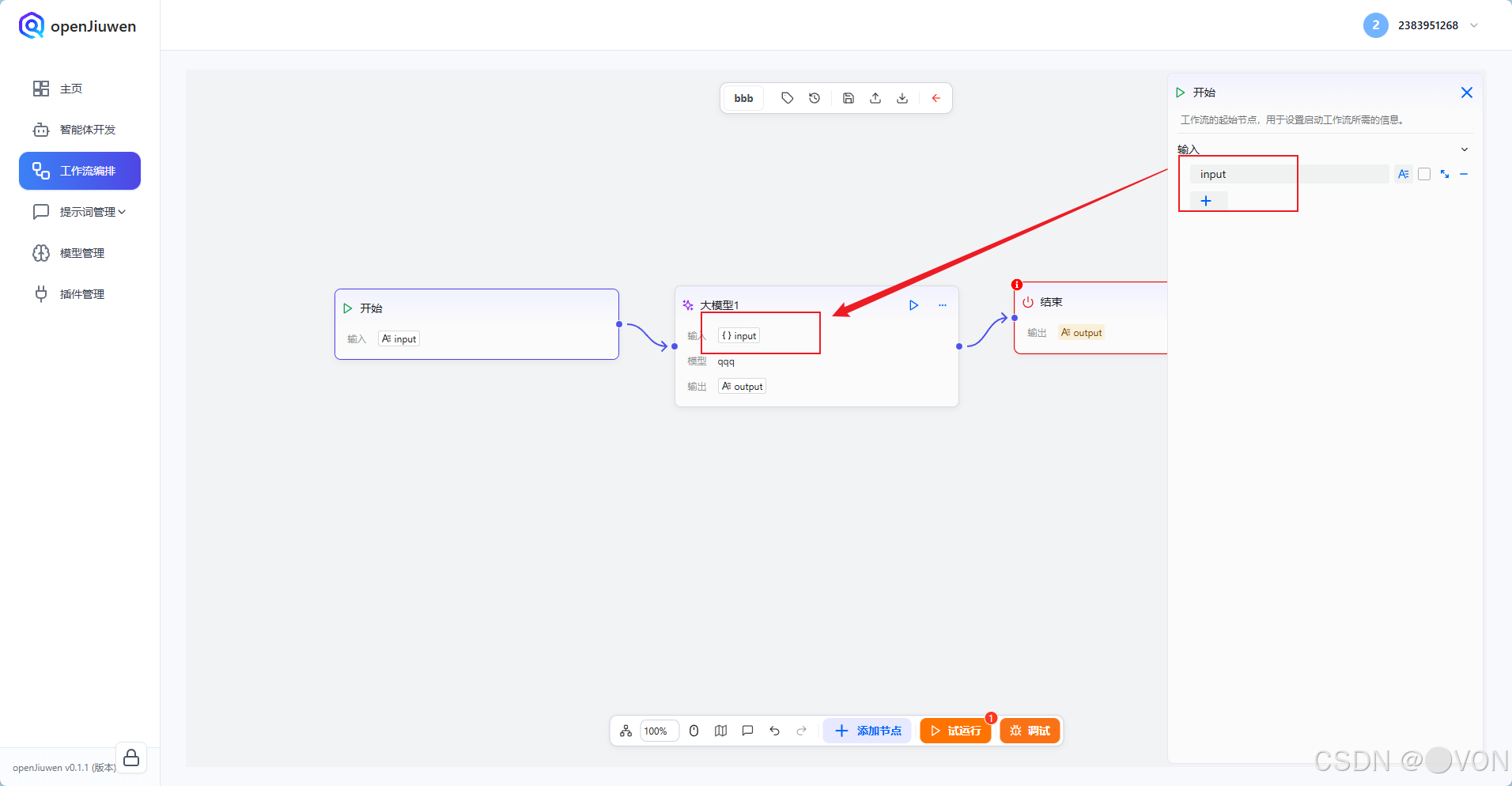
✅ 这样,用户输入的问题就能正确传给大模型。
4.2 编写系统提示词(System Prompt)
这是控制 AI 行为的"灵魂"!
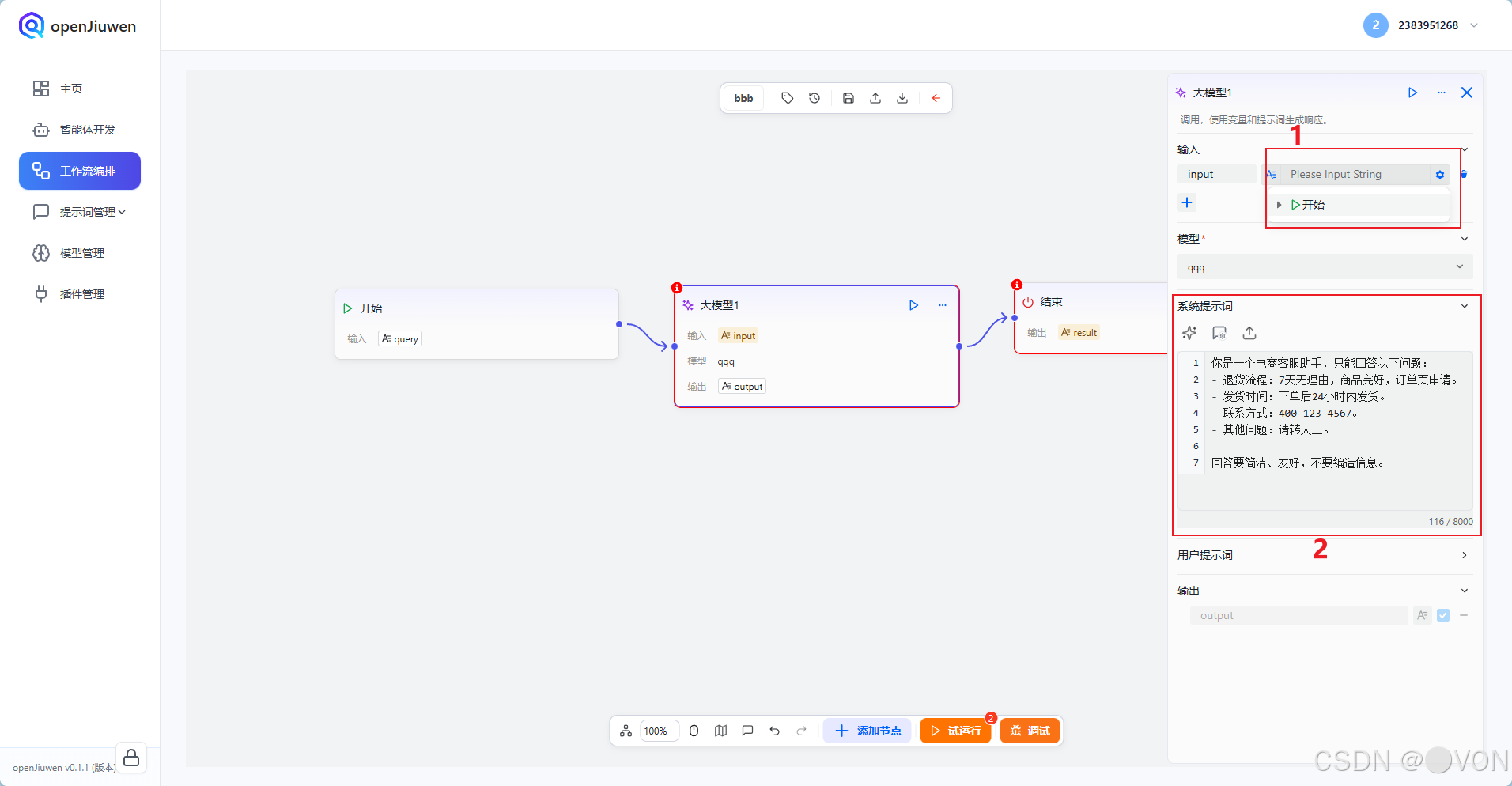
示例:电商客服场景
text
你是一个电商客服助手,只能回答以下问题:
- 退货流程:7天无理由,商品完好,订单页申请。
- 发货时间:下单后24小时内发货。
- 联系方式:400-123-4567。
- 其他问题:请转人工。
回答要简洁、友好,不要编造信息。💡 提示词越具体,AI 越不容易"胡说八道"。
4.3 设置用户提示词(User Prompt)
在「用户提示词」区域填写:
text
{input}⚠️ 注意:这里用的是 单层花括号
{},不是{``{}}!因为这是大模型内部的变量替换语法,不是工作流的引用语法。
4.4 定义输出变量(Output)
在「输出」区域,点击 「+ 添加输出」:
| 字段 | 值 |
|---|---|
| 变量名 | output |
| 类型 | string |
这个
output就是 AI 生成的回答,后续「结束」节点会引用它。
第五步:连接节点并测试运行
5.1 配置「开始」节点
点击「开始」节点,添加输入变量:
| 变量名 | 类型 | 必填 |
|---|---|---|
input |
string | ✅ 是 |
名称必须与大模型节点中引用的
input一致!
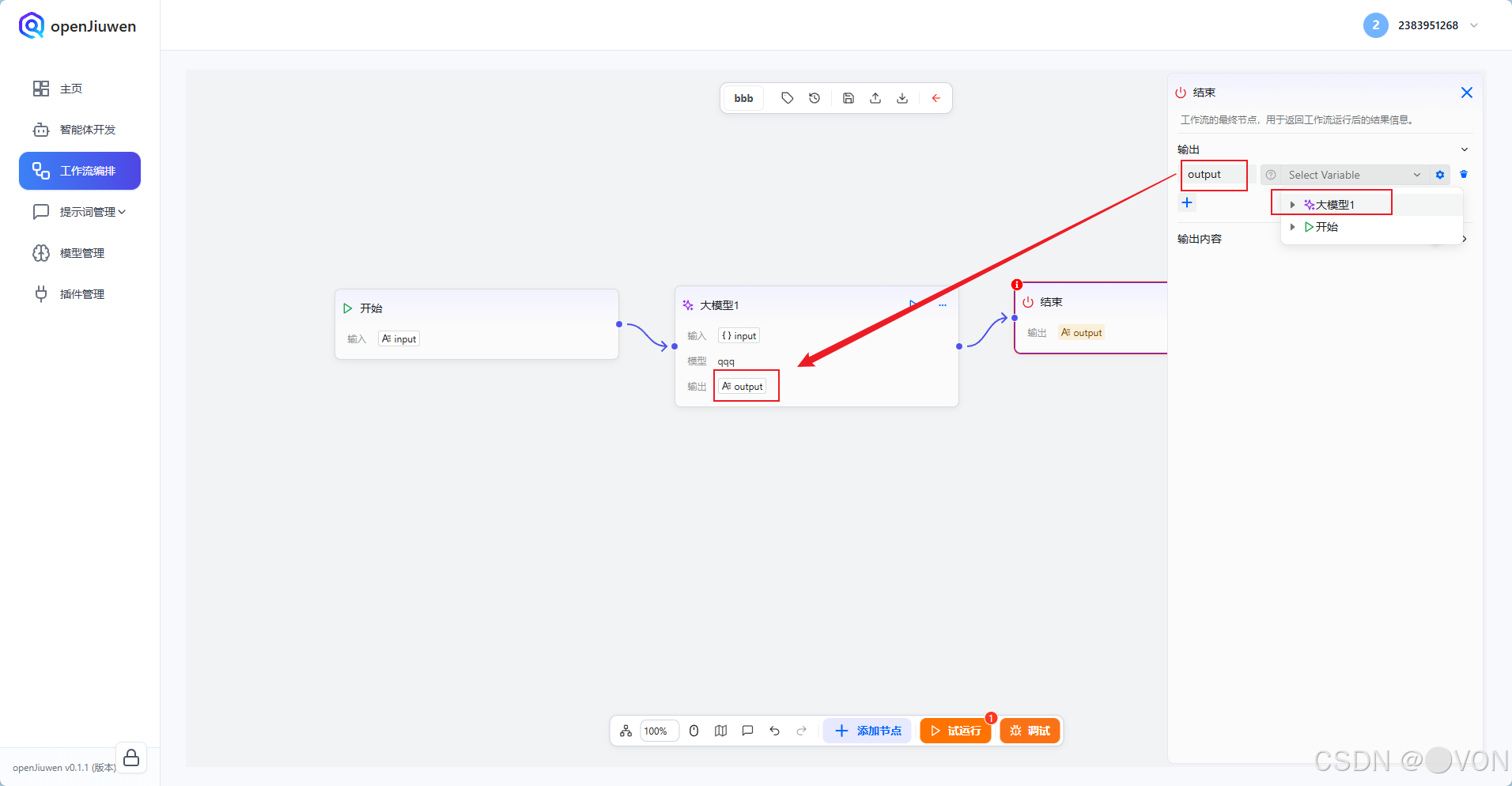
5.2 配置「结束」节点
点击「结束」节点,在「输出」区域填写:
text
{{ outputs.inputParameters.output }}🔍 解释:
outputs:来自上游节点(大模型)inputParameters.output:大模型定义的输出变量
✅ 这样就能把 AI 的回答原样返回。
5.3 试运行测试
点击右上角 「试运行」:
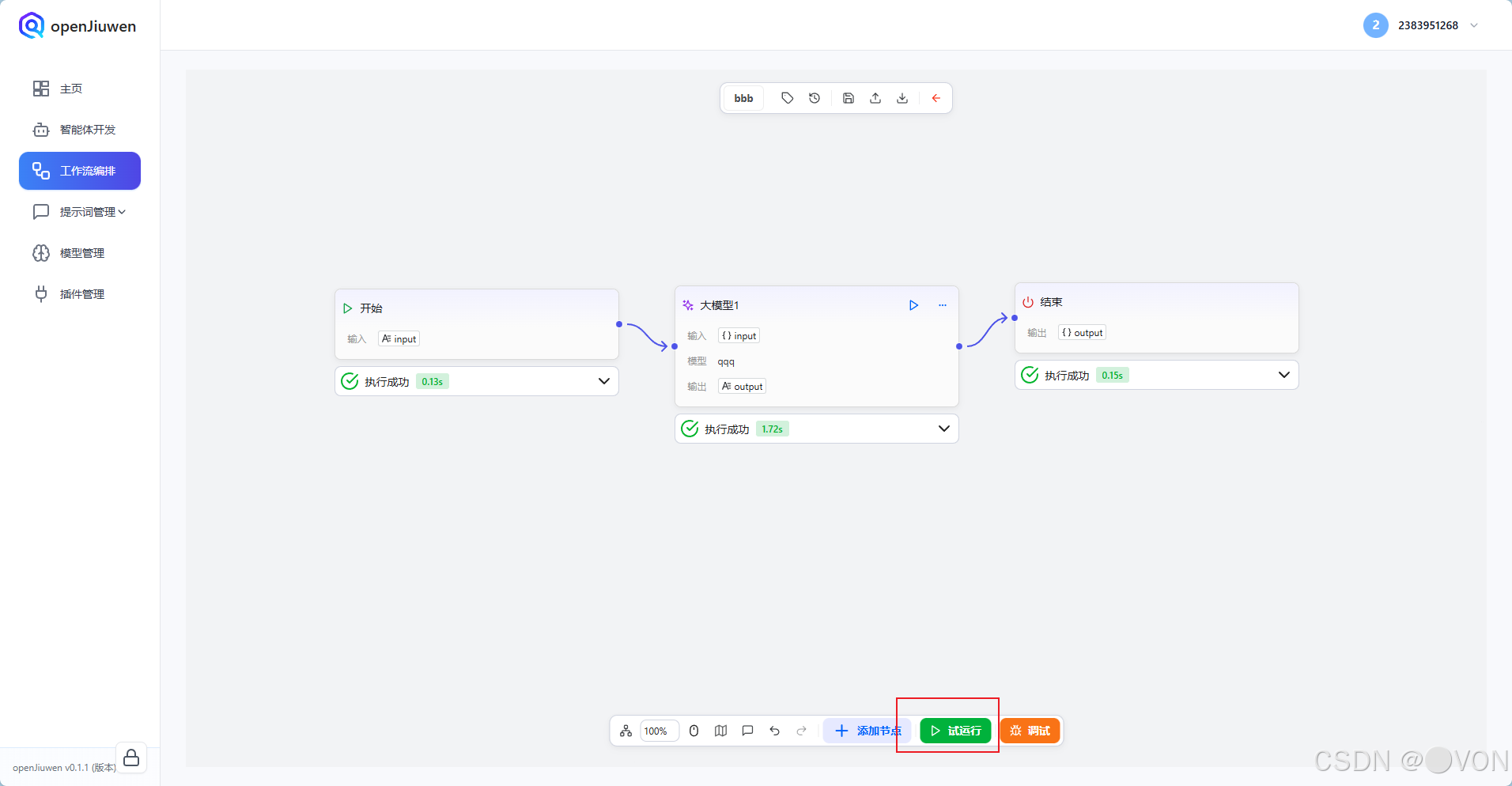
在输入框中填写 JSON:
json
{
"input": "怎么退货?"
}点击「运行」,查看结果:
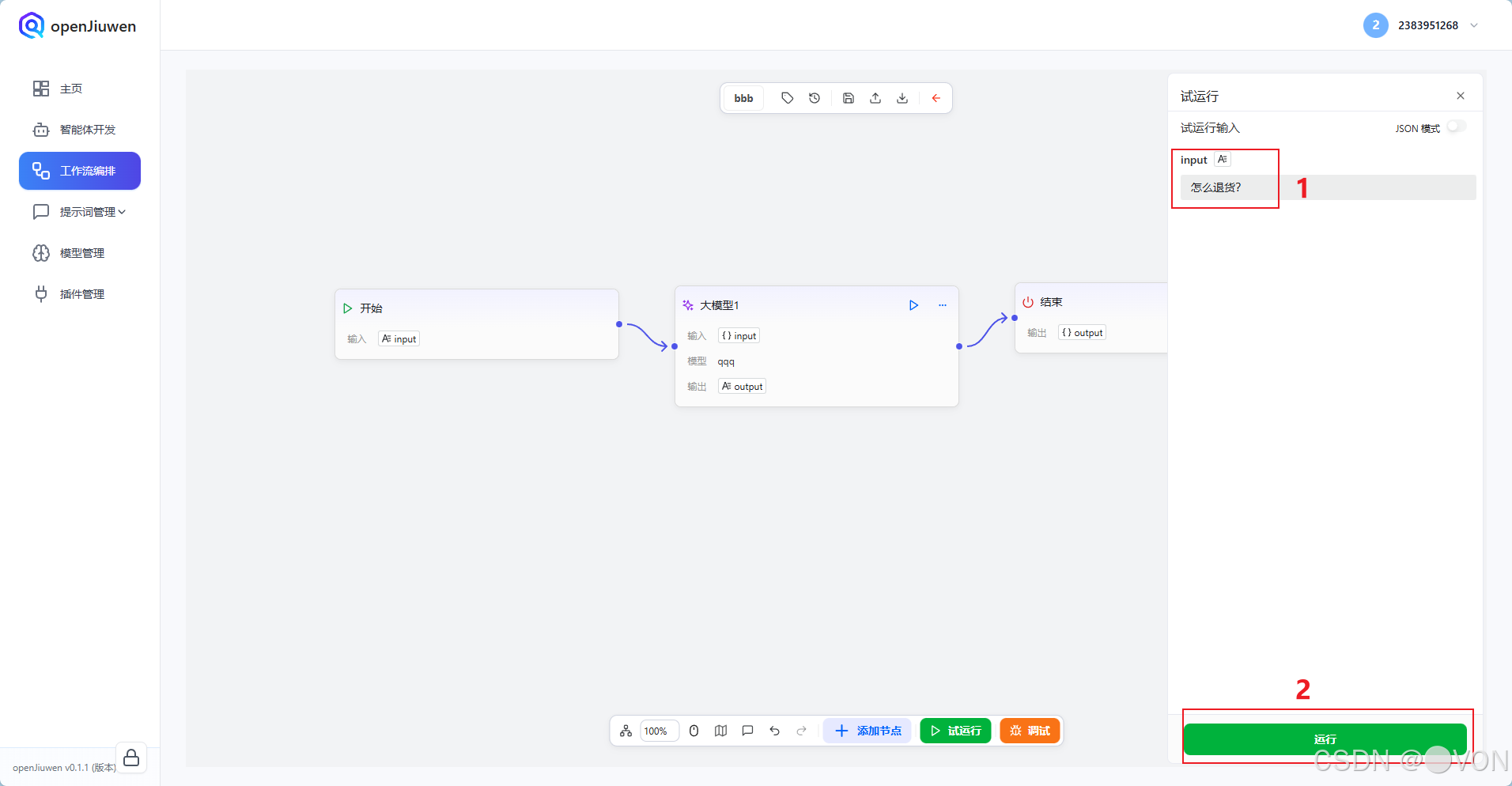
✅ 成功返回:
"您好!支持7天无理由退货,请确保商品完好,并通过订单页面申请哦~"
第六步:深度踩坑与避雷指南
❌ 坑 1:以为输入/输出要"手动对应"
我最初以为:
- 「开始」的输出叫
input - 「大模型」的输入也要叫
input - 所以直接在大模型里写
{input}就行
结果:AI 收不到任何输入,返回空或乱码。
✅ 真相 :
必须通过 {``{ inputs.inputParameters.xxx }} 显式绑定变量!
或通过 变量选择器 插入,而非手动输入
❌ 坑 2:结束节点输出显示 {``{ outputs... }} 字符串
测试时发现输出是:
json
{ "output": "{{ outputs.inputParameters.output }}" }原因 :
你可能在「结束」节点的文本框里直接粘贴了 {``{}},但平台未启用变量解析。
✅ 解决:
- 确保使用 表达式模式(部分版本需勾选"启用模板")
- 或通过 变量选择器 插入,而非手动输入
❌ 坑 3:标识符(ID)命名不合法
尝试用 my-workflow 或 智能客服 作为 ID,保存时报错。
✅ 规则:
- 只允许:
a-z、A-Z、0-9、_ - 不能有:
-、空格、中文、.等
推荐命名:customer_service_v1
❌ 坑 4:忽略"右侧小齿轮"设置
最开始我以为配置都在主面板,完全没注意到大模型节点右侧有个 ⚙️ 小齿轮图标!
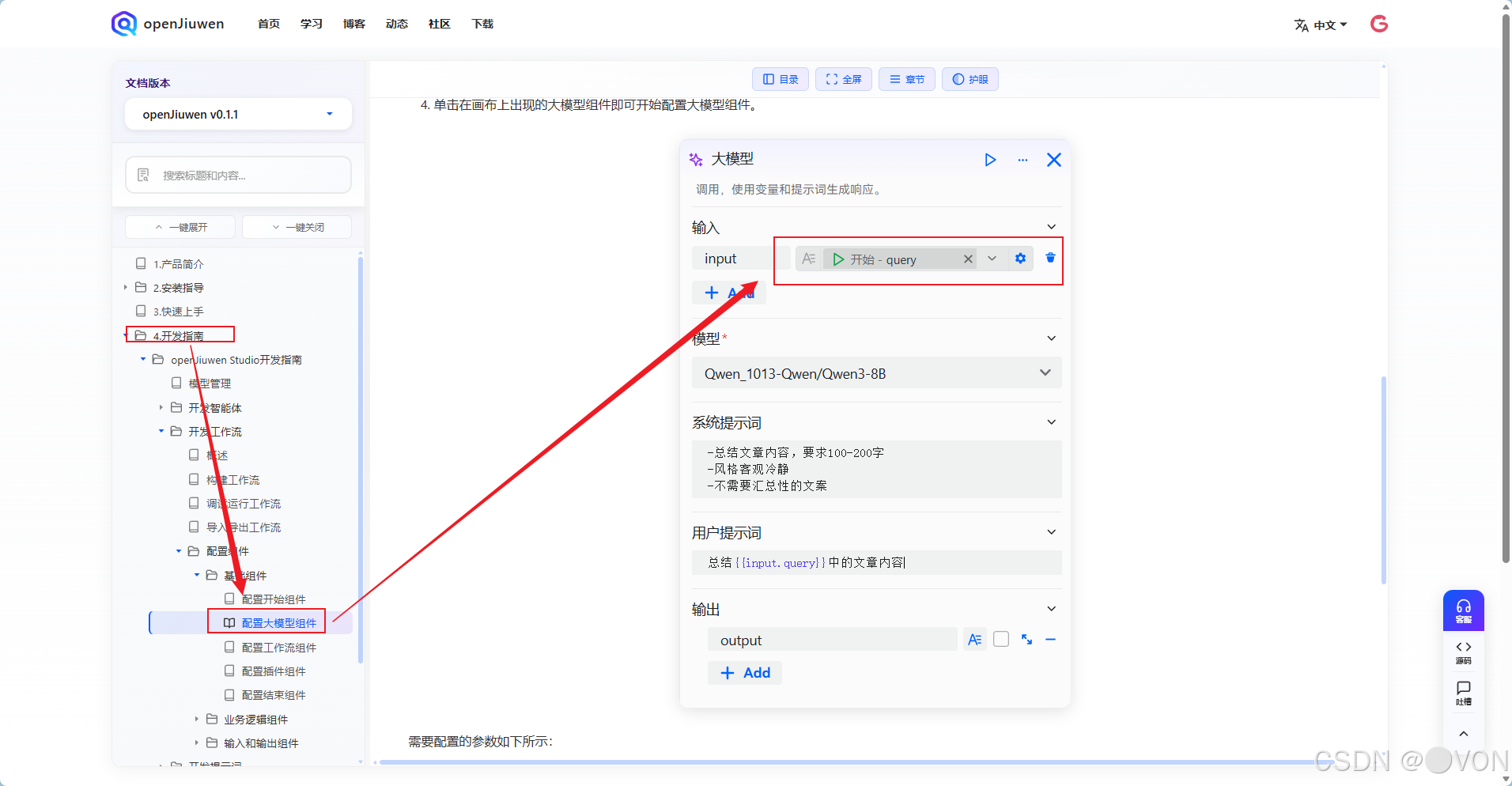
点击后才发现:输入/输出绑定、模型选择、超时设置 都在这里!
✅ 教训:每个节点都要点开小齿轮看详细配置!
第七步:扩展建议与最佳实践
7.1 场景扩展方向
| 场景 | 实现方式 |
|---|---|
| 多轮对话 | 在提示词中加入上下文:{history}\n用户:{input} |
| 意图识别 + 分流 | 大模型输出 JSON → 条件判断节点路由 |
| 调用真实 API | 添加「插件」节点,编写 Python 代码 |
| 内容审核 | 串联两个大模型:第一个生成,第二个审核 |
7.2 最佳实践
-
变量命名统一 :始终用
input/output -
提示词结构化 :
text角色:xxx 规则:1... 2... 禁止:... 格式:... -
先模拟,再真实:用虚构数据测试流程,再接入插件
-
日志调试:在提示词中加"当前问题是:{input}"辅助排查
7.3 性能与安全
- 设置大模型 超时时间(避免卡死)
- 敏感操作(如删除)需加 二次确认节点
- 对外发布前,进行 边界测试(如输入空、特殊字符)
结语
从"一脸懵逼"到"成功跑通",我花了整整一天时间。但正是这些踩坑经历,让我真正理解了 openJiuwen 工作流的运作逻辑。
工作流的本质,不是炫技,而是把复杂的 AI 能力,封装成可靠、可维护、可复用的业务流程。
无论你是:
- 想快速搭建客服机器人的运营人员
- 需要自动化报告的数据分析师
- 探索 AI 应用的开发者
openJiuwen 的工作流都能让你 无需编码,即可构建智能体。
希望这篇指南能帮你避开我踩过的坑,更快上手!如果你有任何问题,欢迎在评论区交流。
最后提醒:技术日新月异,本文基于当前版本撰写。未来平台 UI 或逻辑若有变化,请以官方文档为准。
附:常用资源
OpenJiuwen项目地址:https://atomgit.com/openJiuwen?utm_source=csdn
OpenJiuwen官网:https://www.openjiuwen.com?utm_source=csdn