大家好,我是 Ai 学习的老章
2025 年最后一天,腾讯开源了 HY-MT1.5 翻译大模型!
简介
HY-MT1.5(Hunyuan Translation Model Version 1.5)是腾讯混元团队推出的专业翻译大模型,包含两个版本:
- HY-MT1.5-1.8B:18 亿参数的轻量级版本
- HY-MT1.5-7B:70 亿参数的完整版
这两款模型主打一个 "又快又准" :支持 33 种语言 的互译,还额外覆盖了 5 种民族语言和方言。最牛的是,1.8B 的小模型翻译质量居然能逼近 7B 大模型,"小钢炮"属性拉满。
外链图片转存中...(img-WTJUiCxq-1767539031275)
核心亮点
1.8B 轻量模型的逆袭:
- 🏆 同尺寸行业第一:1.8B 模型在同参数规模中遥遥领先,甚至超越大多数商业翻译 API
- ⚡ 边缘设备友好:量化后可部署在端侧设备,支持实时翻译场景
- 📊 性价比爆棚:参数量不到 7B 模型的三分之一,效果却几乎持平
7B 完整模型的全面升级:
- 🎯 WMT25 冠军血统:基于世界机器翻译大赛冠军模型优化
- 📝 混合场景增强:针对解释性翻译、中外混杂文本做了专门优化
- 🔧 专业功能三件套:术语干预、上下文翻译、格式化翻译全支持

模型文件
腾讯提供了多种量化版本,满足不同场景需求:
| 模型名称 | 描述 |
|---|---|
| HY-MT1.5-1.8B | 混元 18 亿参数翻译模型 |
| HY-MT1.5-1.8B-FP8 | 混元 18 亿参数翻译模型,fp8 量化 |
| HY-MT1.5-1.8B-GPTQ-Int4 | 混元 18 亿参数翻译模型,int4 量化 |
| HY-MT1.5-7B | 混元 70 亿参数翻译模型 |
| HY-MT1.5-7B-FP8 | 混元 70 亿参数翻译模型,fp8 量化 |
| HY-MT1.5-7B-GPTQ-Int4 | 混元 70 亿参数翻译模型,int4 量化 |
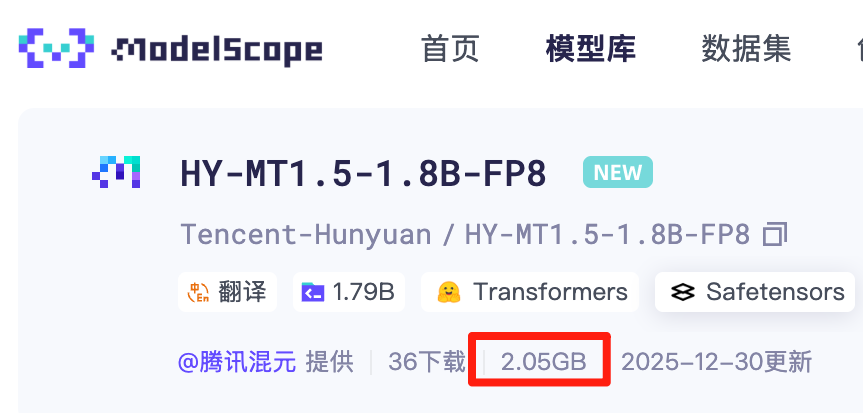
FP8 原版只有 2.05GB,GPTQ-Int4 只有 1.34GB
快速上手
安装依赖
SHELL
pip install transformers==4.56.0使用 Transformers 推理
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
model_name_or_path = "tencent/HY-MT1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "Translate the following segment into Chinese, without additional explanation.\n\nIt's on the house."},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt"
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])Prompt 模板
HY-MT1.5 提供了多种专业翻译场景的 Prompt 模板:
1. 中外互译(ZH <=> XX):
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释: {source_text}2. 非中文互译(XX <=> XX):
Translate the following segment into {target_language}, without additional explanation. {source_text}3. 术语干预(专业领域必备):
参考下面的翻译: {source_term} 翻译成 {target_term} 将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释: {source_text}4. 上下文翻译(保持语境一致):
{context} 参考上面的信息,把下面的文本翻译成{target_language},注意不需要翻译上文,也不要额外解释: {source_text}5. 格式化翻译(保留标签信息):
将以下<source></source>之间的文本翻译为中文,注意只需要输出翻译后的结果,不要额外解释,原文中的<sn></sn>标签表示标签内文本包含格式信息,需要在译文中相应的位置尽量保留该标签。输出格式为:<target>str</target> <source>{src_text_with_format}</source>本地部署
主流推理引擎都支持(TensorRT-LLM、SGLang),这里只介绍我喜欢的 vLLM
vLLM 部署(推荐 v0.10.0+)
shell
# 安装特定版本 transformers
pip install git+https://github.com/huggingface/transformers@4970b23cedaf745f963779b4eae68da281e8c6ca
# 启动服务
# export MODEL_PATH=tencent/Hunyuan-7B-MT
# export MODEL_PATH=/root/.cache/modelscope/hub/models/Tencent-Hunyuan/Hunyuan-7B-MT/
python3 -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--model tencent/HY-MT1.5-1.8B \
--tensor-parallel-size 1 \
--dtype bfloat16 \
--served-model-name hunyuan \
2>&1 | tee log_server.txt在线体验 - 实测
不想本地部署,只想体验的话,可以直接在这里试试
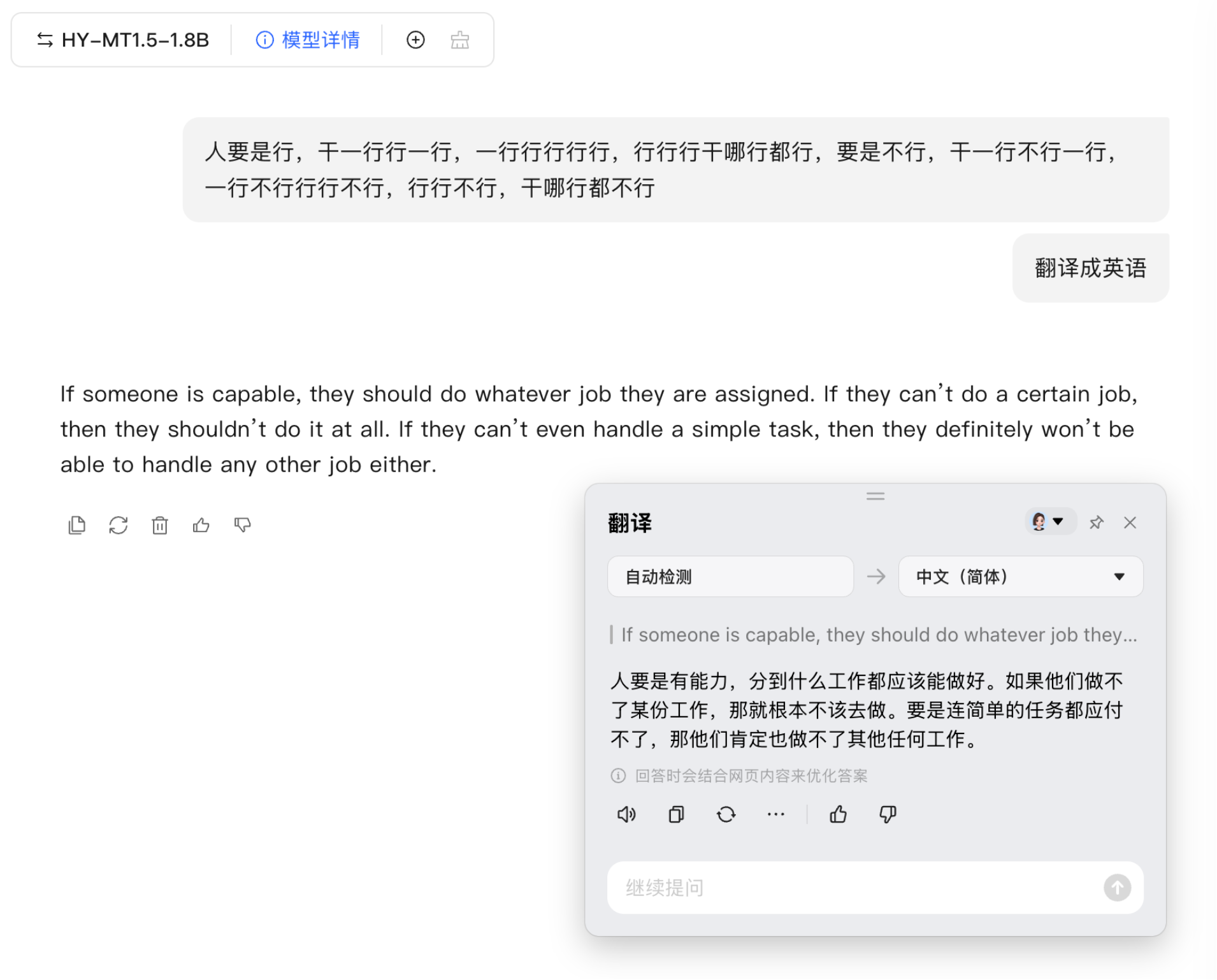
我测试了一下,直接放大招
1.5B 版本感觉去挑战这种难度非常吃力,翻译的很差
7B 也不咋地
外链图片转存中...(img-f8C3NqGl-1767539031278)
这是我之前我写好但是没有发布的一篇文章中的翻译挑战题,感觉纯翻译大模型在这种难度的题目中,还是不如通用、推理大模型

它最大的价值:量化后的 1.8B 模型可以轻松部署在消费级显卡甚至边缘设备上,实时翻译场景完全 hold 住。