概念介绍
什么是大模型
大模型,一般也称为"大语言模型",是一种基于深度学习技术训练出来的人工智能系统,主要用于处理和生成人类语言。


大模型工作原理: 通过学习大量文本,掌握了语言的规律和知识,然后根据输入的提示(prompt)生成相应的输出。
什么是大模型
深度学习就是用层数较多(深)的人工神经网络从数据中学习输入与输出之间映射关系的算法,而人工神经网络是受生物神经网络的结构和功能启发下设计的计算模型。
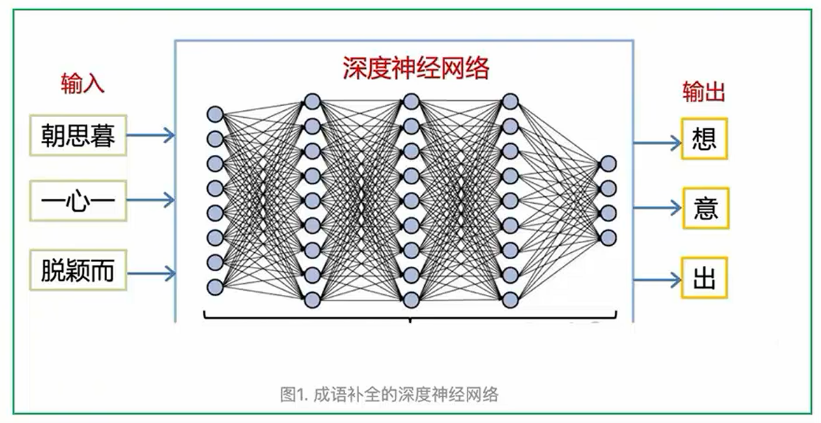
- 深度学习训练得到的网络就叫深度神经网络,它可以简单的看成一个函数,能够完成任何输入到输出的转换。
- 比如: 我们可以用它玩成语补全的游戏,输入成语的前三个字,让网络输出最后一个字(见图1)。
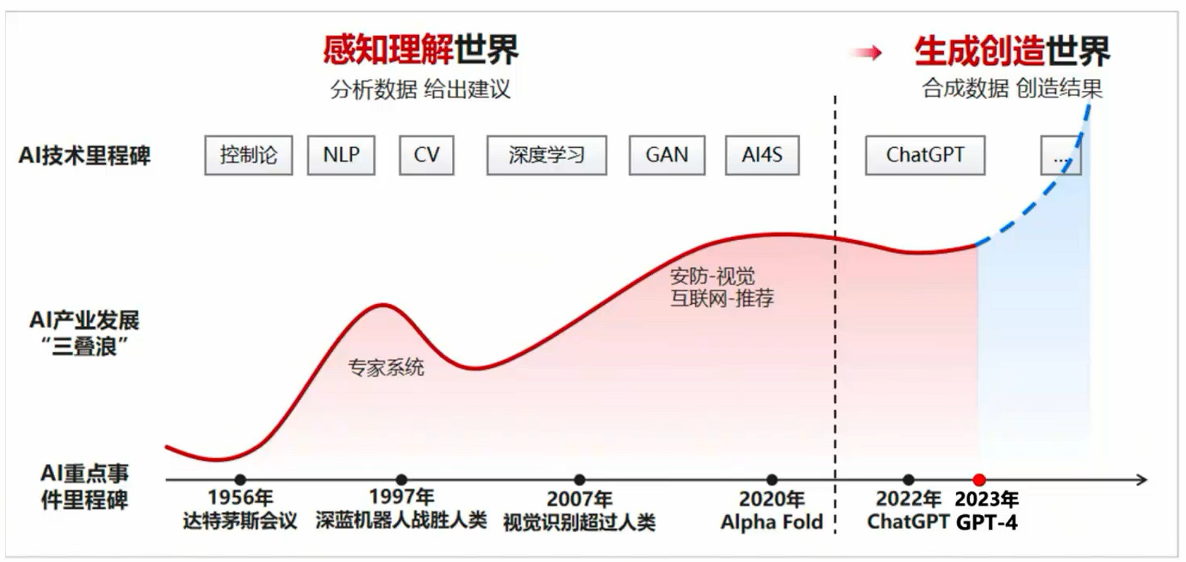
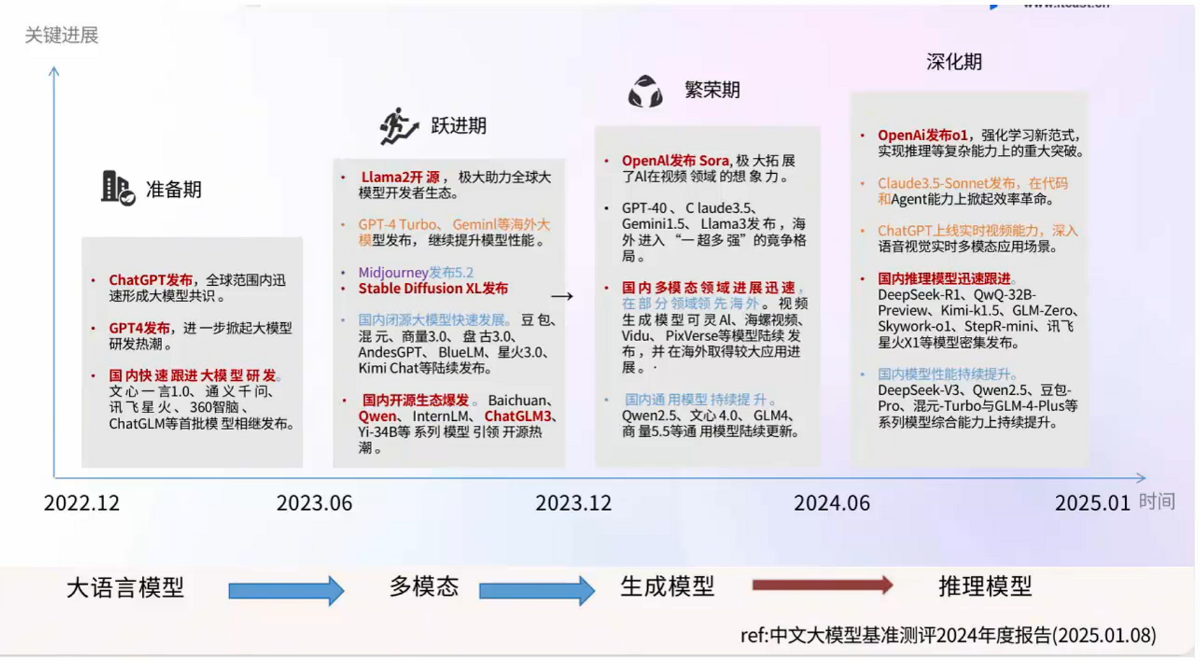
大模型的发展
大模型分类
大模型核心运行机制
预训练大(语言)模型主要是基于深度学习技术所研发,其核心开发的过程比较深奥,我们以简化的视角去理解大模型是如何训练出来的。
- 大模型的实现原理可以简单归纳为: 三步走

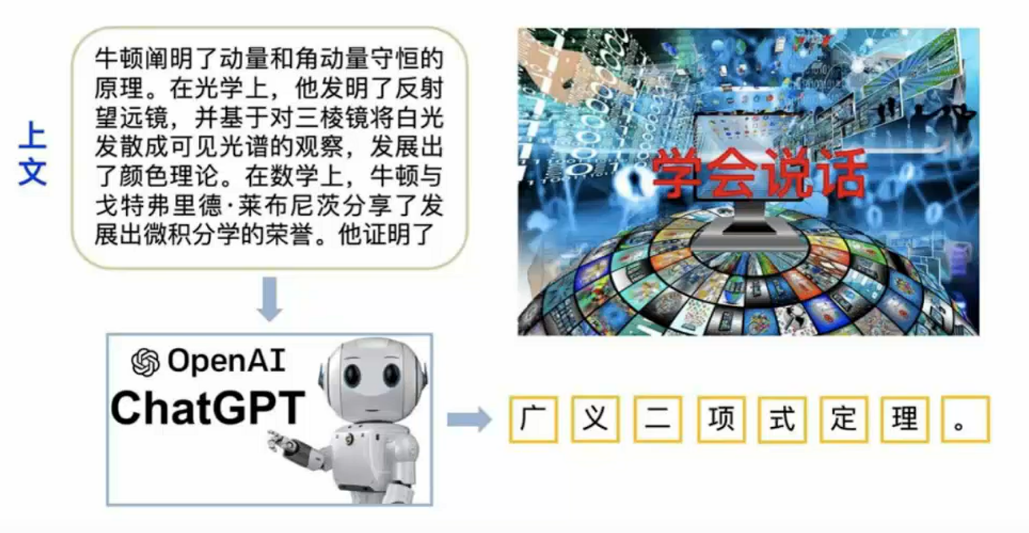
- 学会说话
- 利用深度神经网络来训练语言模型,先收集尽可能多的文本,每次随机抽一段上文,让模型学会接着往下"背诵"
- 由于看过和背过的文字实在是太多了(实际训练使用了几乎所有能从各种渠道获得的文字和图书资源)模型就可以像模像样地说话了。
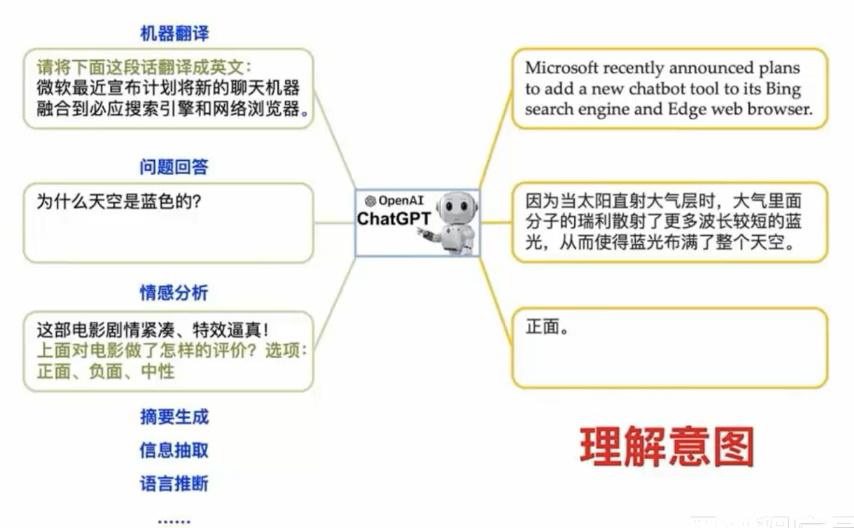
- 理解意图
- 简单的说就是理解用户的需求是什么。
- 自然语音(人类语音)是非结构化的,以中文为例,同样的含义可以有不同的说法。
- 通过训练,让大模型可以准确的识别用户的意图。并基于"给上文、补下文"的形式完成回答
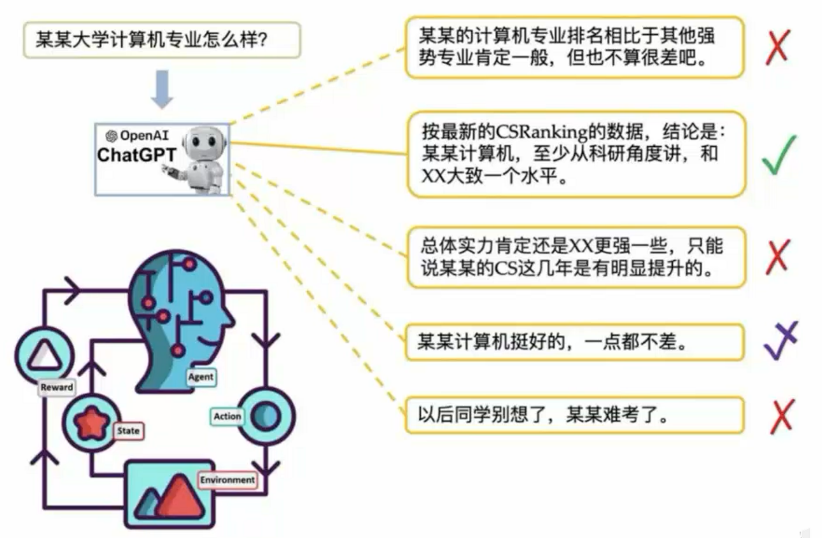
- 反馈择优
- 对于某些问题,模型可能会生成带有偏见、歧视或者令人不适的回答。另外,之前提到过,对于同一个问题,模型能够生成多个不同的回答。
- 这一步中我们让人们对同一问题的不同回答进行排序,然后采用强化学习算法进一步调整模型,使输出回答更符合人们的期望。
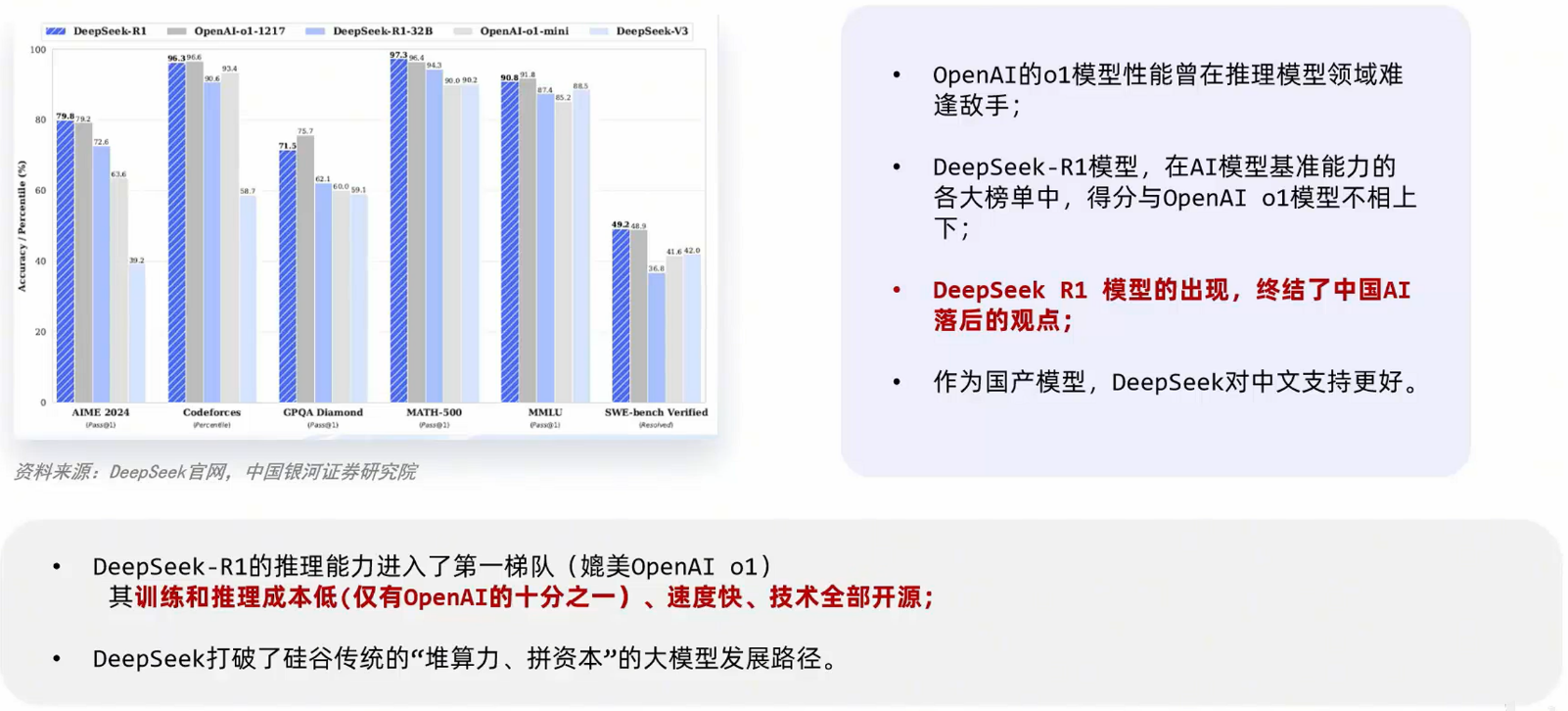
deepseek介绍

如何得到模型
很多的大模型是开源的,以deepseek为例,其r1模型就是开源的,任何人都可以下载得到它的模型。https://github.com/deepseek-ai/DeepSeek-R1
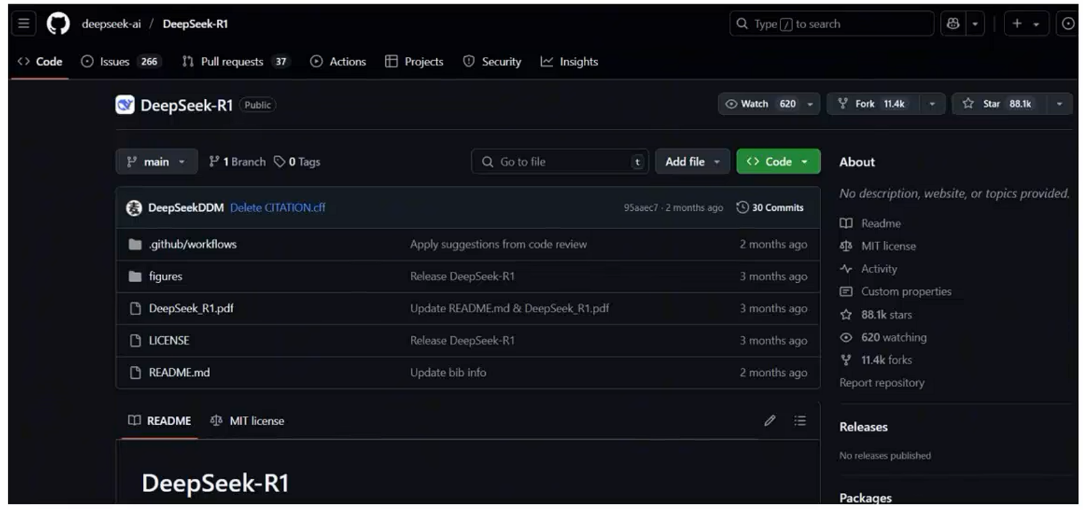
- 我们可以直接下载,得到deepseek-r1模型,
- 如1.5b参数的蒸馏模型下载地址:
- https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main

大模型的蒸馏
大模型的运行需要极高的硬件资源,通常都是服务器集群并挂载数量众多的GPU(显卡)。
- 为了满足低性能设备的运行,可以对大模型进行蒸馏。

什么是聊天机器人
聊天机器人特点
- 自然语言理解(NLP): 能够理解用户输入自然语言,并从中提取意图和关键信息。
- 对话管理: 通过对话引擎维持对话的连贯性,根据上下文生成合适的回答。
- 个性化交互: 可以根据用户的历史记录和偏好提供定制化的回答。
- 多功能性: 除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等。
应用场景:
- 客户服务: 在电商、金融等领域,自动解答用户问题,提供24*7的客户支持。
- 娱乐:一些聊天机器人可以与用户进行趣味对话,提供娱乐体验。
- 教育:用于语言学习、知识问答等教育场景。
- 智能家居:控制家电设备,如灯光、空调等。
- 医疗健康:提供健康咨询、预约挂号等服务。
常见聊天机器人:
- DeepSeek
由杭州深度求索人工智能基础技术研究有限公司研发,其核心优势在于性能卓越、低成本开发和开源策略
- Kimi智能助手
由月之暗面科技有限公司开发,支持超长上下文(最高200万汉字),适合长文本处理和复杂对话。
- 通义千问
阿里云推出的人工智能助手,适合办公场景,提供高效的信息处理能力。
- 讯飞星火
科大讯飞出品,支持语音输入和语音朗读回复,适合语音交互场景。
- 豆包
字节跳动推出,支持抖音和今日头条的内容信息获取,适合内容创作和信息检索。
项目介绍
黑马智能聊天机器人效果展示:
- 本次课我们会带领大家完成从0-1的聊天机器人搭建。


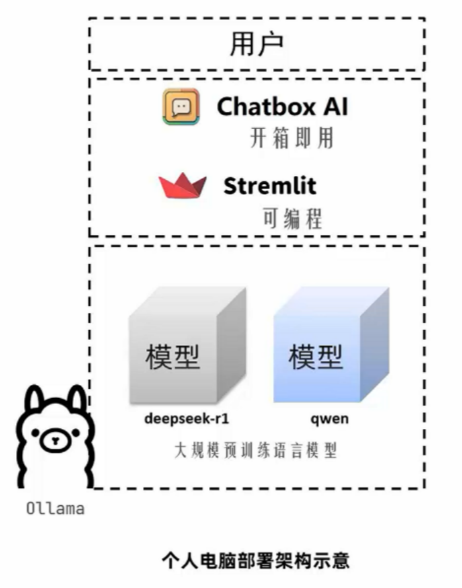
个人电脑黑马智聊机器人技术架构
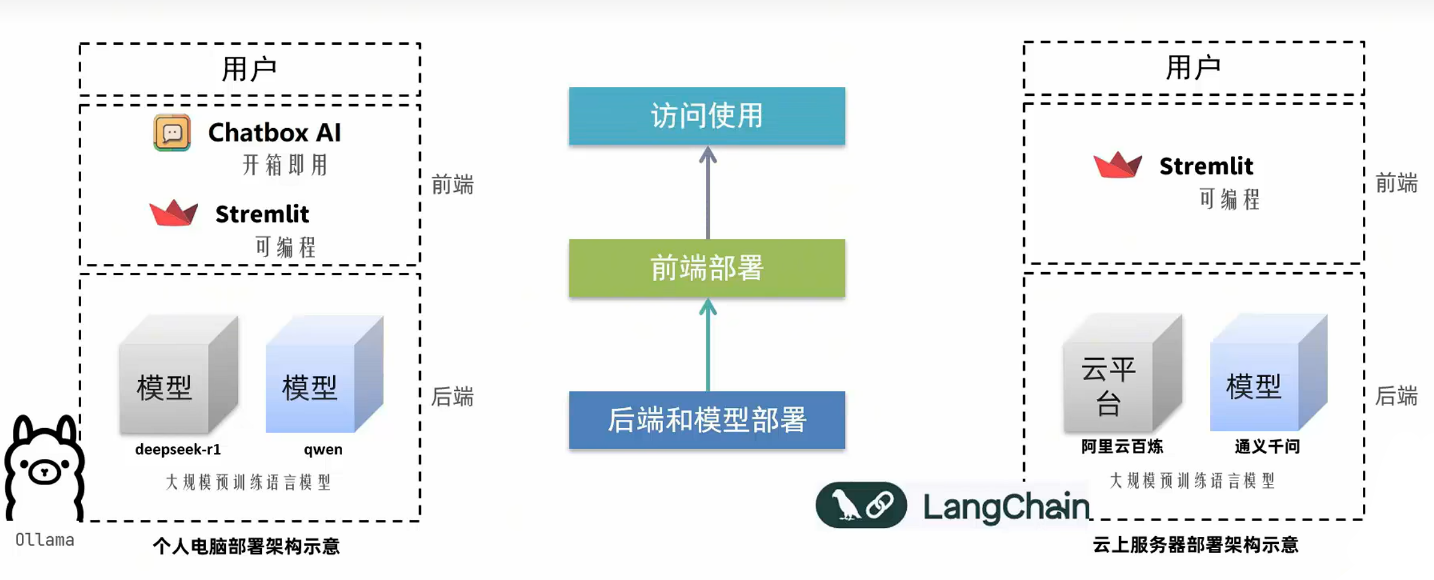
Ollama
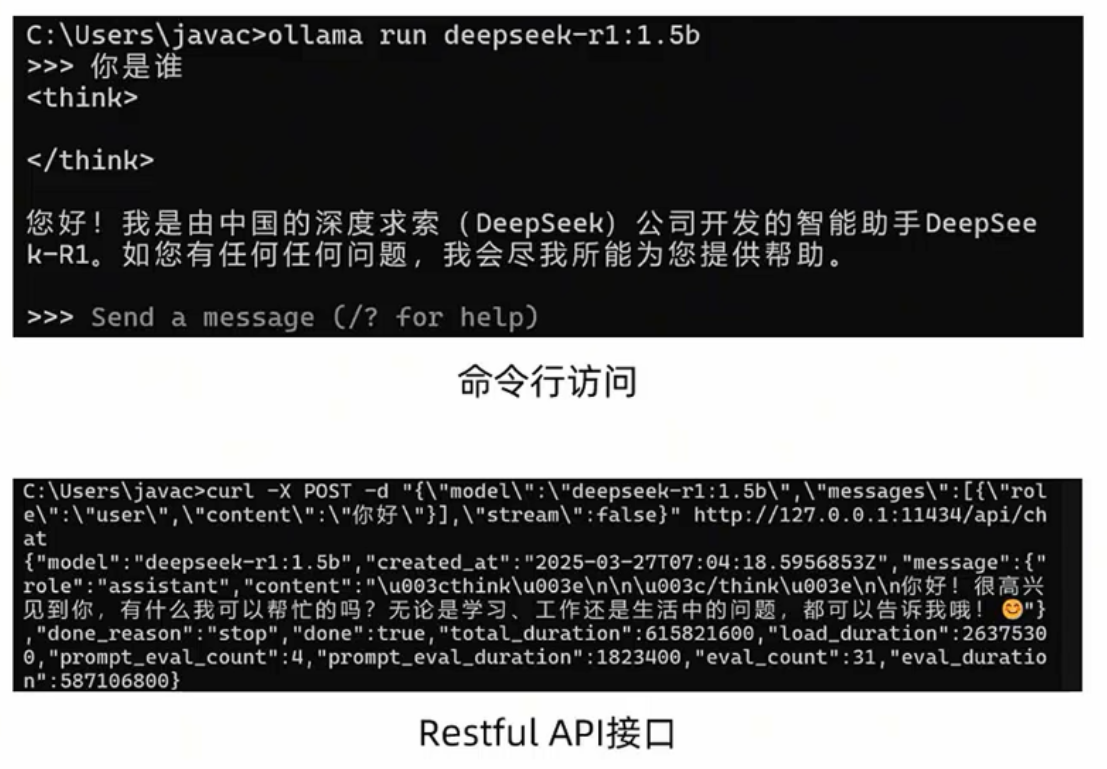
ollama介绍
ollama: 是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
- ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)
- 通过ollama,开发者可以导入和定制自己的模型,无需关注复杂的底层实现细节。
- 网址: https://ollama.com
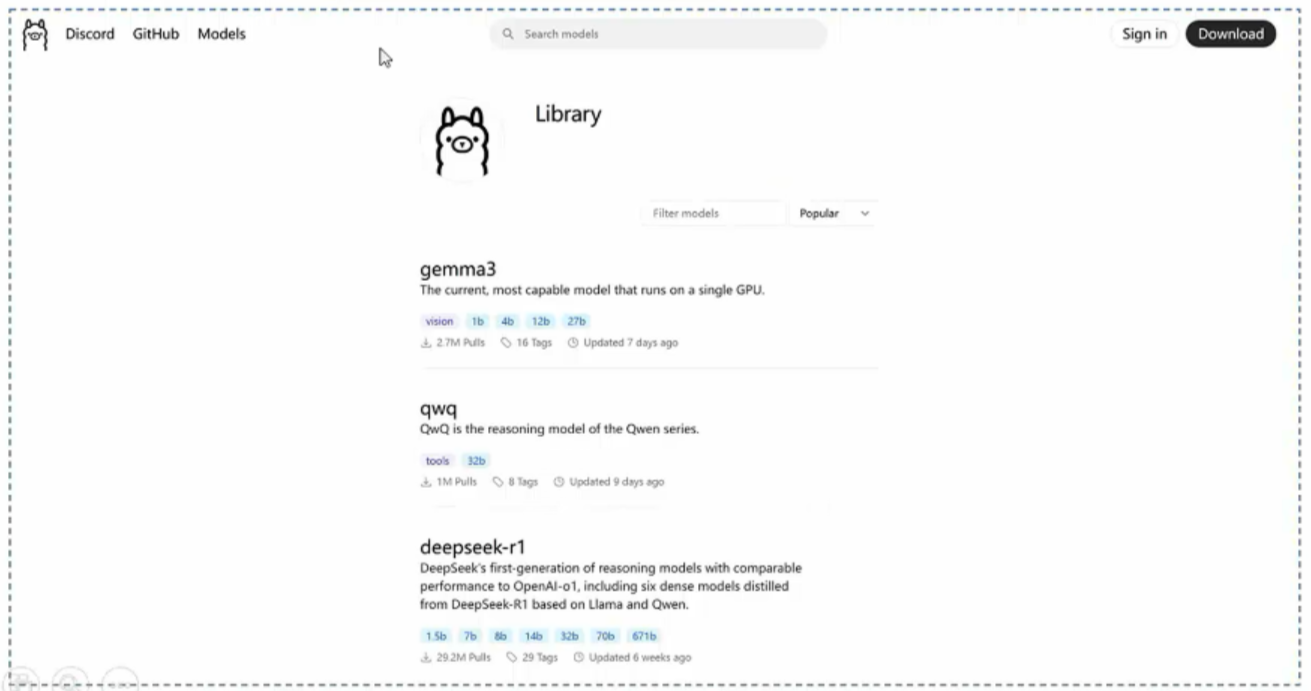
ollama模型库
ollama支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。
ollama 官方模型库: https://ollama.com/library
Windows系统安装Ollama
- 下载Ollama,Windows系统安装包:https://ollama.com/download
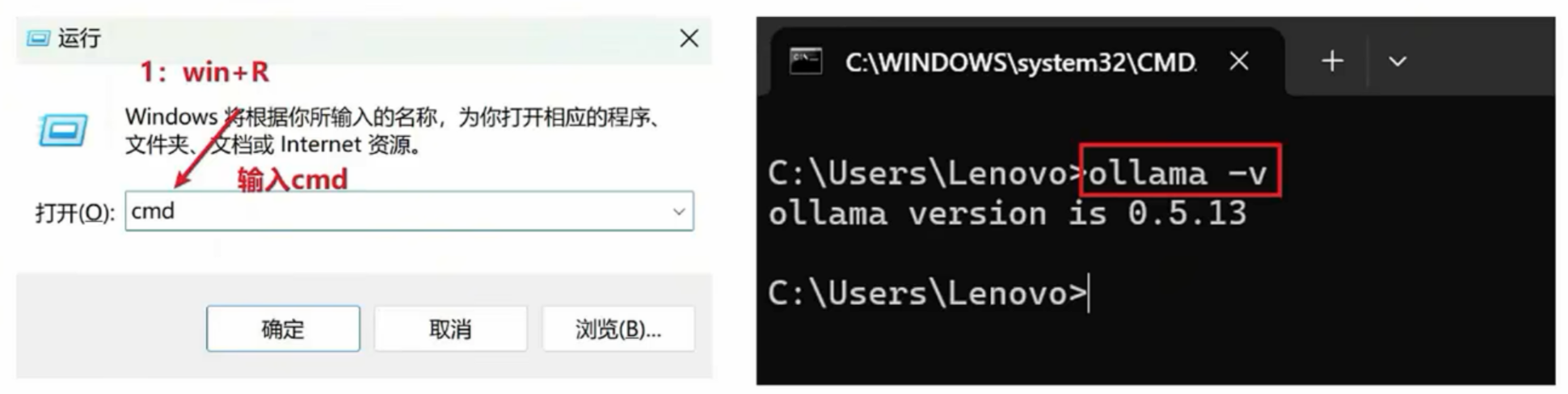
- 双击提前下载好的OllamaSetup.exe安装包,选择install,然后一直默认安装即可

- win+R打开终端,输入ollama -v命令查看是否安装成功
基于window中ollama部署私有大模型
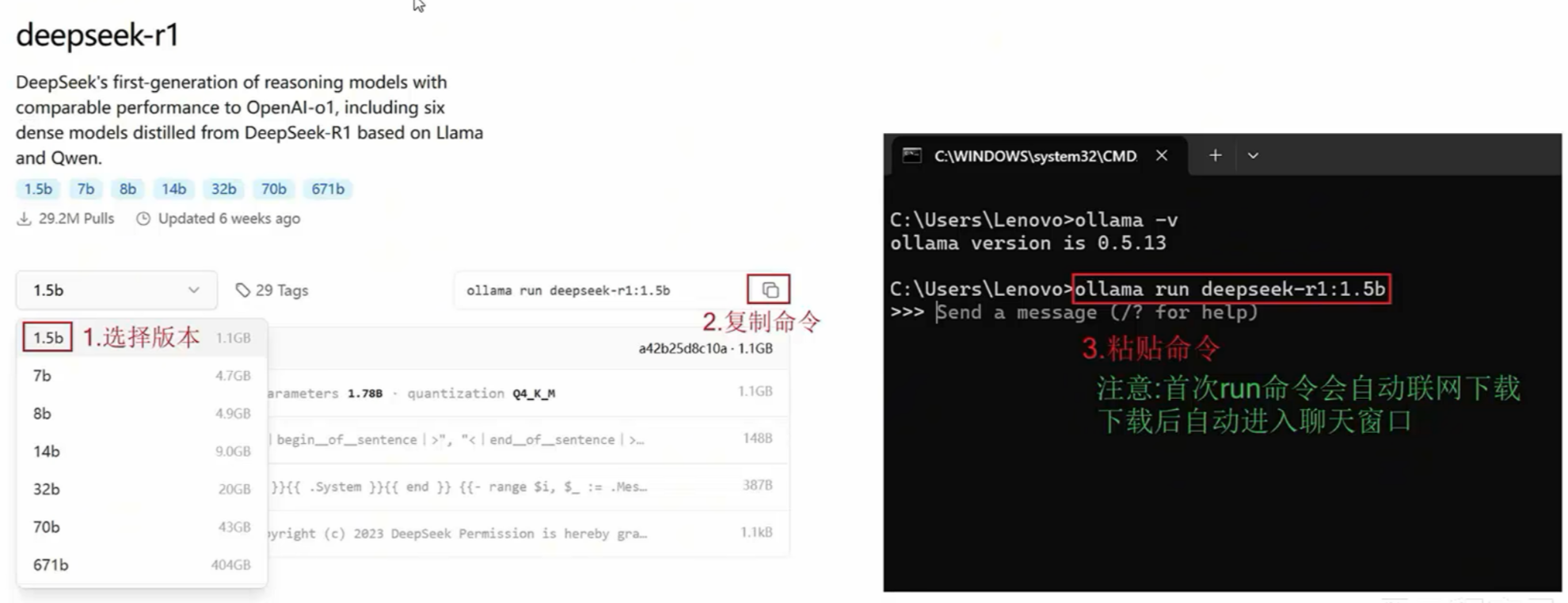
- 示例1: 部署deepseek大模型
- 通过https://ollama.com/library查找要使用的模型
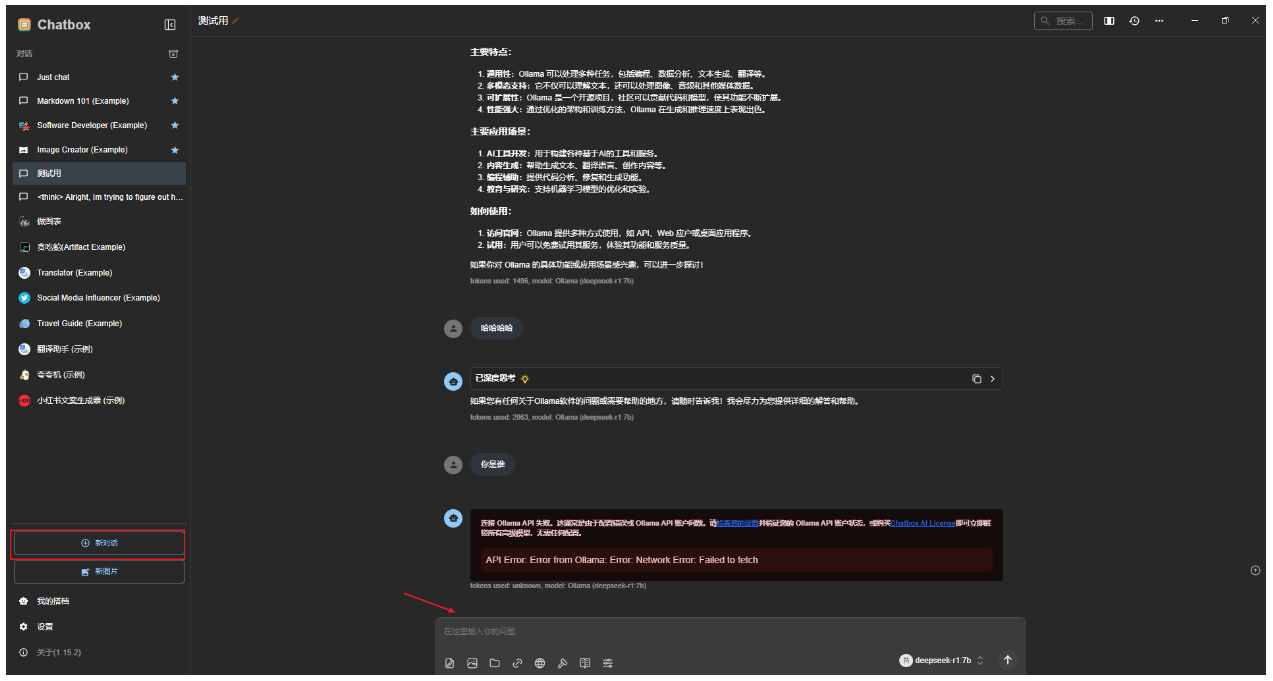
Chatbox
后端Ollama已经完成,现在需要一个前端方便使用。
基于Chatbox软件,开箱即用,立刻即可构建出私有化聊天机器人
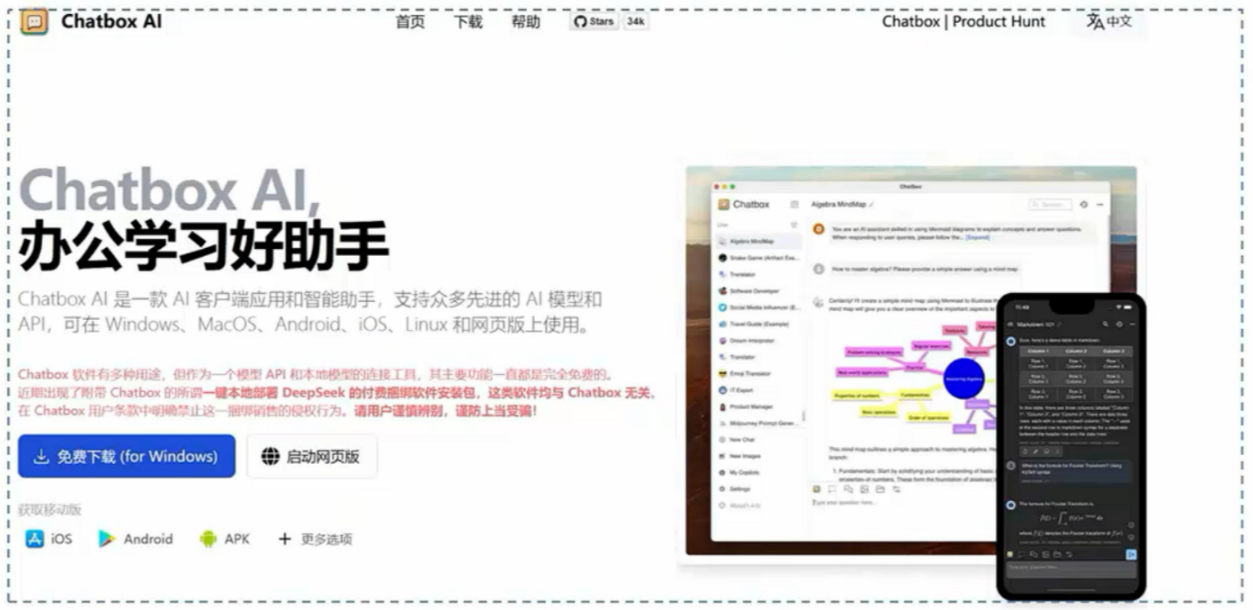
Chatbox是一款基于OpenAI API的开源跨平台智能对话工具,支持Windows、macOS和Linux系统。
- 它旨在为用户提供便捷的AI对话体验,同时具备强大的功能扩展性和灵活性。
- 官网: https://chatboxai.app/zh
Chatbox工具介绍
Chatbox是一款功能强大、易于使用的开源AI工具,适合开发者、学生、办公人员等多种用户群体。
- 下载安装
- 访问Chatbox官网,下载并安装适合您操作系统的安装包(Windows、macOS或Linux)。
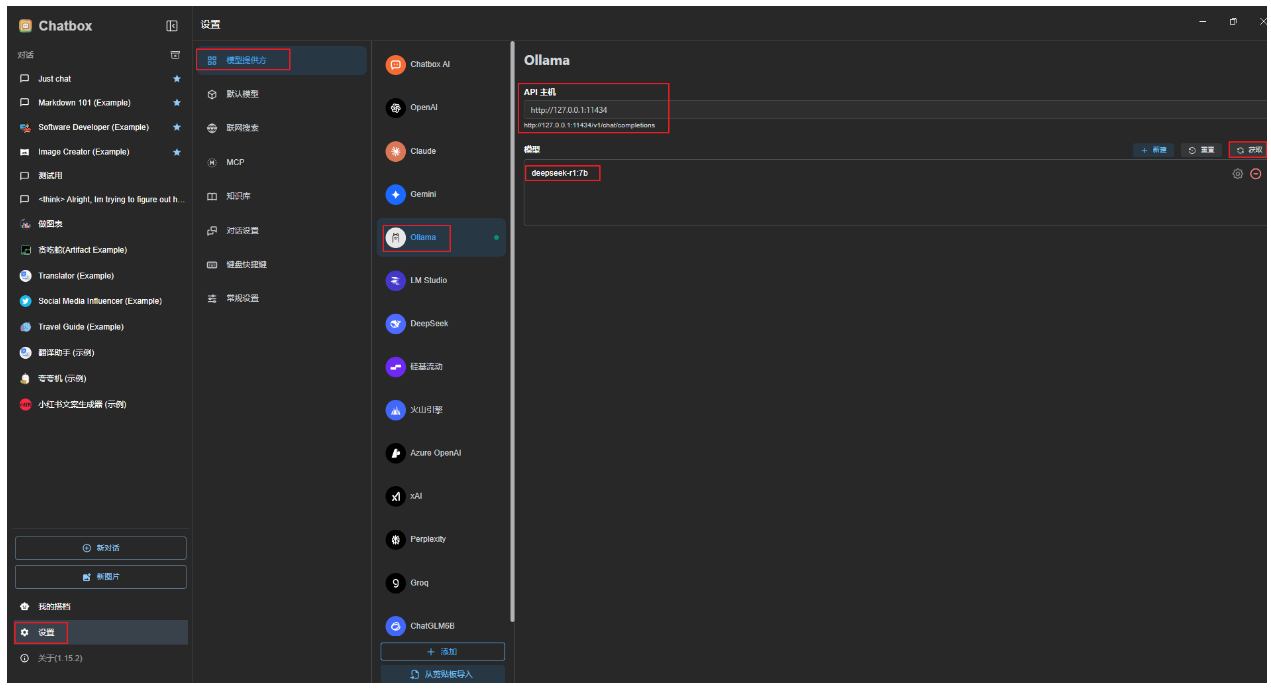
- 配置API
- 打开Chatbox,进入设置菜单。
- 选择ollama中本地部署的模型,并保存配置。
- 开始对话
- 主界面,创建对话窗口,在输入框中输入问题或指令。
- 保存和退出
- 聊天记录会自动保存到本地。
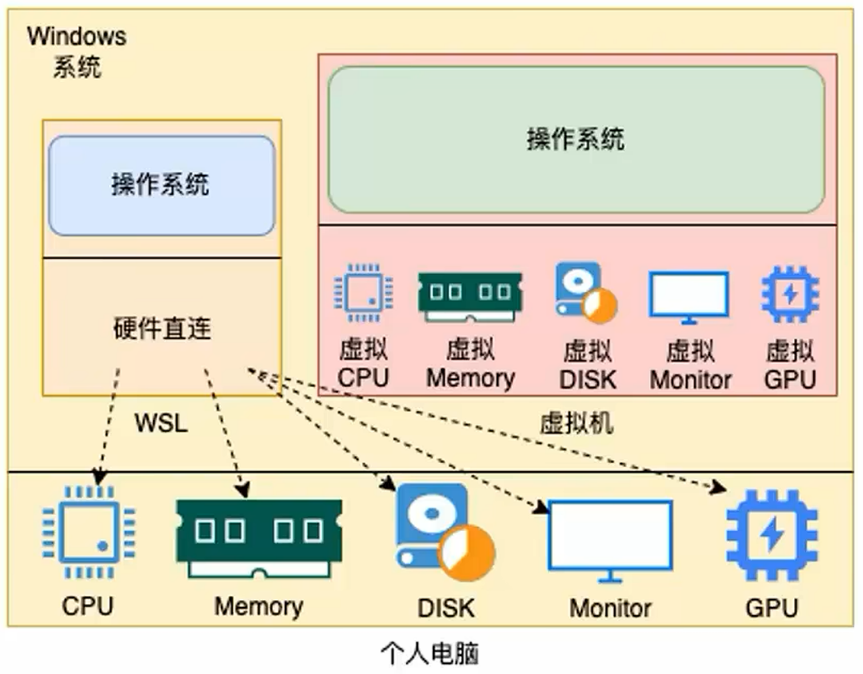
WSL
WSL作为Windows10系统带来的全新特性,正在逐步颠覆开发人员既有的选择。
- 传统方式获取Linux操作系统环境,是安装完整的虚拟机,如VMware
- 使用WSL,可以以非常轻量化的方式,得到Linux系统环境
目前,开发者正在逐步抛弃以虚拟机的形式获取Linux系统环境,而在逐步拥抱WSL环境。
所以,课程也紧跟当下趋势,为同学们讲解如何使用WSL,简单、快捷的获得Linux系统环境。
所以,为什么要用WSL,其实很简单:
- 开发人员都在用,大家都用的,我们也要学习
- 实在是太方便了,简单、好用、轻量化、省内存
WSL: Windows Subsystemfor Linux, 是用于Windows系统之上的Linux子系统。
- 作用很简单,可以在Windows系统中获得Linux系统环境,并完全直连计算机硬件,无需通过虚拟机虚拟硬件。
- 简而言之:
- Windows10的WSL功能,可以无需单独虚拟一套硬件设备
- 就可以直接使用主机的物理硬件,构建Linux操作系统
- 并不会影响Windows系统本身的运行
WSL部署
- WSL是Windows10自带功能,需要开启,无需下载
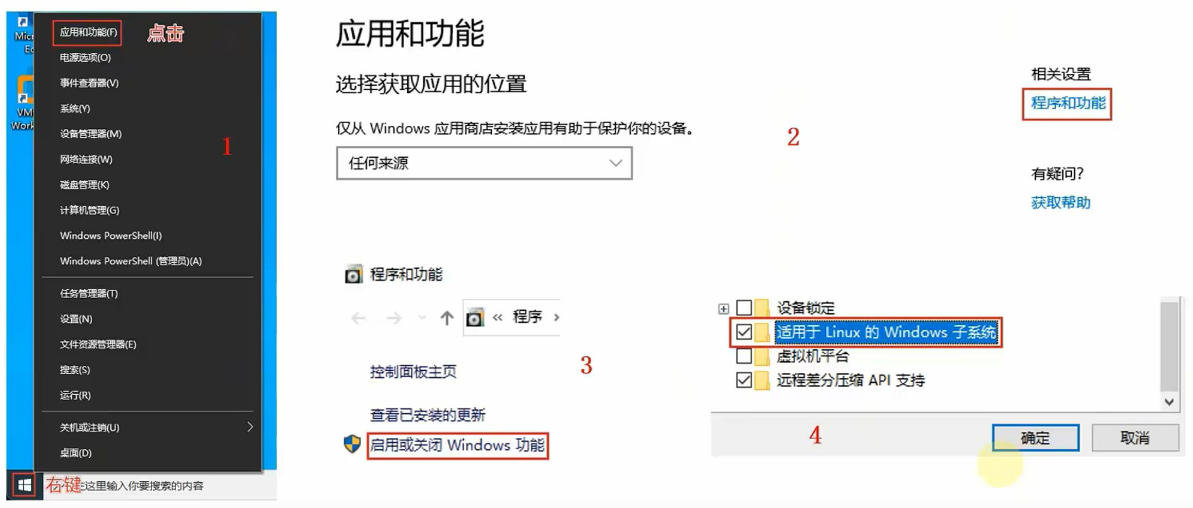
- 打开Windows应用商店

- 搜索Ubuntu
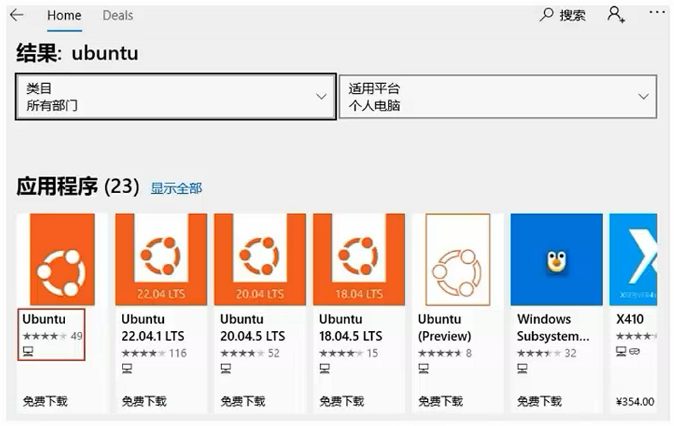
- 点击获取并安装

- 点击启动 (启动后默认打开)
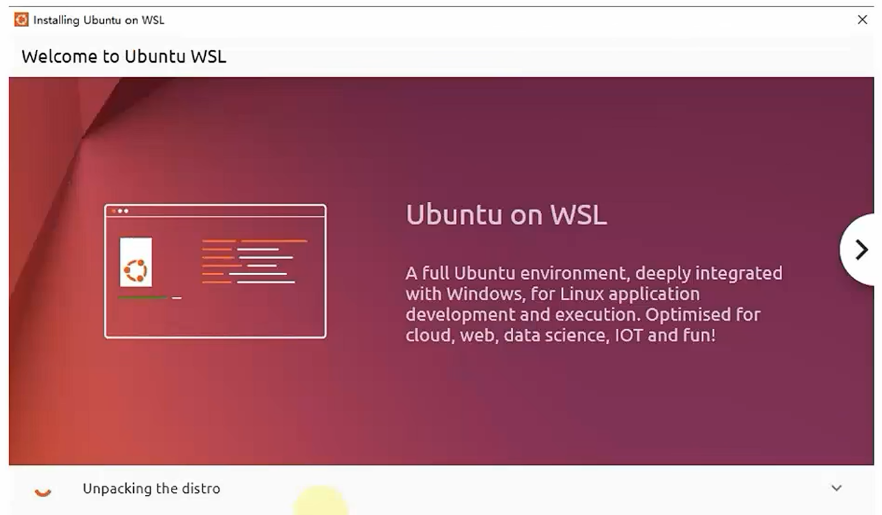
- 输入用户名用以创建一个用户

- 输入两次密码确认(注意,输入密码没有反馈,不用理会,正常输入即可)

- 至此,得到了一个可用的Ubuntu操作系统环境
安装Windows Terminal软件
Ubuntu自带的终端窗口软件不太好用,我们可以使用微软推出的: Windows Terminal软件
- 在应用商店中搜索terminal关键字,找到Windows Terminal软件下载并安装
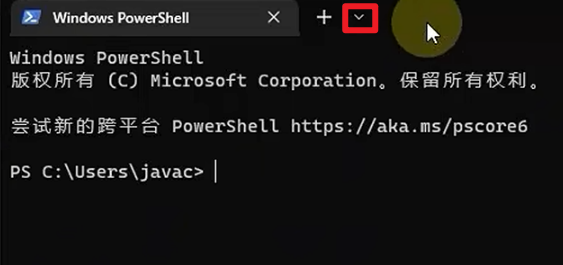
- 打开后默认打开powerShell窗口, 需要切换一下
Linux安装Ollama
Linux系统安装ollama
下载Ollama Linux系统安装包: https://ollama.com/download/ollama-linux-amd64.tgz
在课程资料中,已经为大家提供好了,大家可以从课程资料中得到安装包
CUDA简介
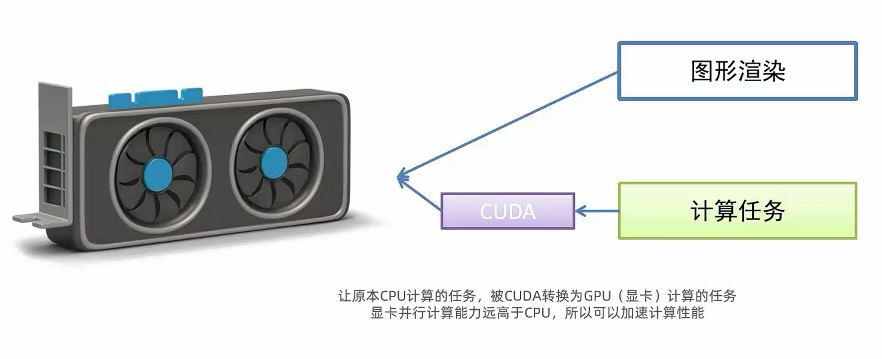
CUDA是英伟达(NVIDIA)推出的一种并行计算平台和编程模型。
它允许开发者利用英伟达GPU(图形处理单元)的强大计算能力来加速计算密集型任务,而不仅仅是用于图形渲染。
验证CUDA是否可用
WSL在安装好Ubuntu后,自动安装了显卡驱动以及CUDA,可以通过命令: nvidia-smi 验证
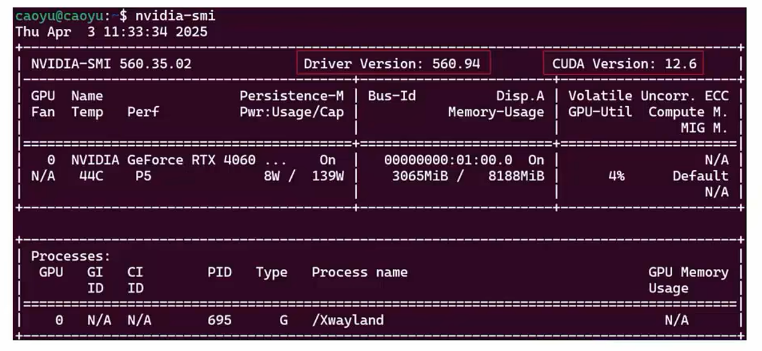
如图等信息均正确识别,可以直接使用
- 驱动版本560.94
- CUDA版本12.6
- 显存8G
Linux系统安装一键部署ollama
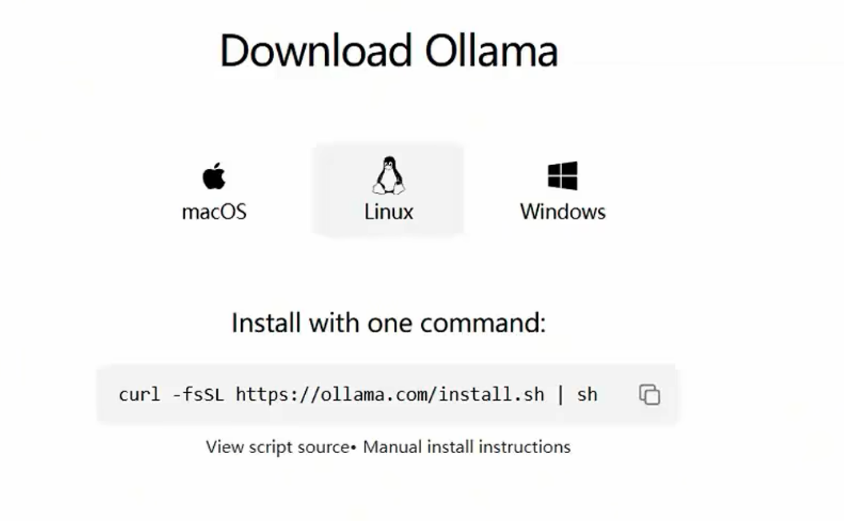
打开Ollama官网,https://ollama.com/download/linux
- 可以看到,只需要一行命令,即可在Linux系统中部署Ollama
启动ollama并运行大模型
一键直接安装很容易失败(网络), 采用手动安装的模式
- 下载好安装包后,进入安装流程:
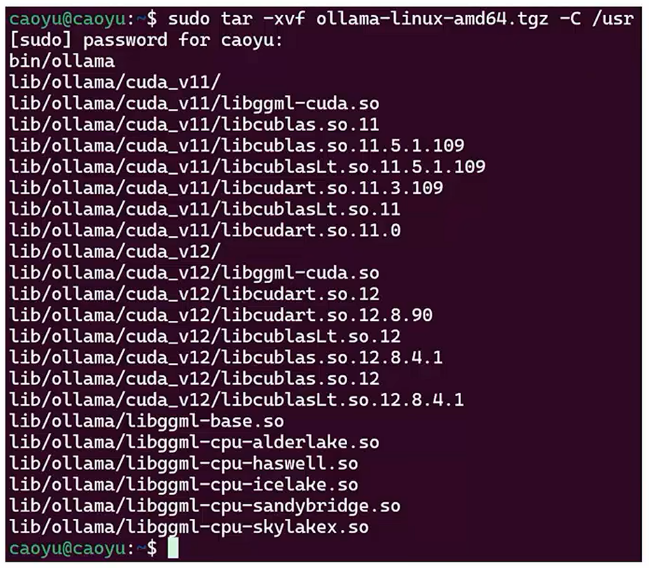
- 解压Ollama到/usr文件夹
- sudo tar -xvf ollama-linux-amd64.tgz -C /usr

- 启动ollama,执行命令
- ollama serve
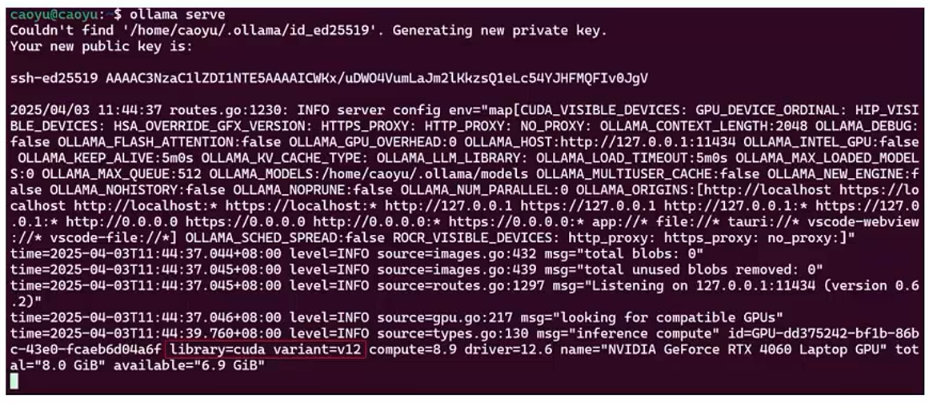
- cuda也可以使用
- 一切OK后,按ctrl+c退出ollama运行
- 创建0llama运行所用用户
- sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
- sudo usermod -a -G ollama $(whoami)
- 配置OLlama为系统服务,方便启动、停止
- 创建新文件:
- sudo touch /etc/systemd/system/ollama.service
- 将右侧内容保存到上述文件内
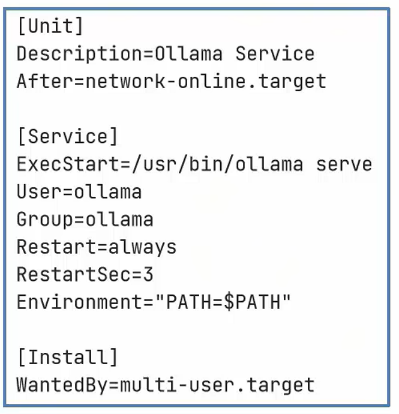
- 执行如下命令生效
- sudo systemctl daemon-reload
- 命令使用
- 开启ollama开机自启: sudo systemctl enable ollama
- 关闭oLlama开机自启: sudo systemctl disable ollama
- 启动ollma: sudo systemctl start ollama
- 查看oLlama运行状态: sudo systemctl status ollama
- 停止oLlama: sudo systemctl stop ollama
- 启动ollama查看运行状态
- sudo systemctl start ollama
- sudo systemctl status ollama
- 下载模型文件(或第一次启动模型的时候,也会自动下载)
- ollama pull deepseek-r1:7b
- ollama pull qwen2:7b
- 在命令启动模型使用
- ollama run deepseek-r1:7b
Linux安装开发环境
Python所需库的安装
WSL(Ubuntu) 内置了Python(版本3.8),所以无需部署Python,但如果需要编写代码调用Ollama,需要安装Ollama库。
- 安装pip工具
sudo apt install python3-pip
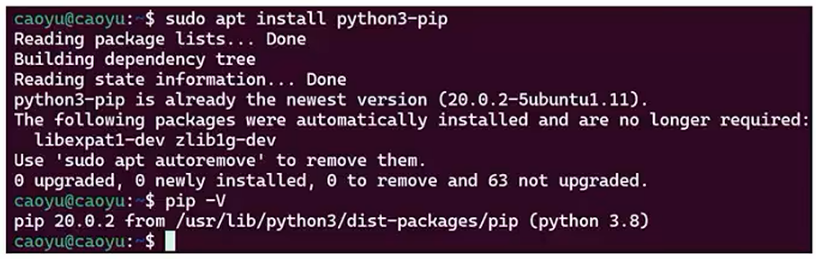
- 验证pip的使用
pip -V 注意V是大写字母
- 安装ollama库 (用于Python调用Ollama)
pip install ollama
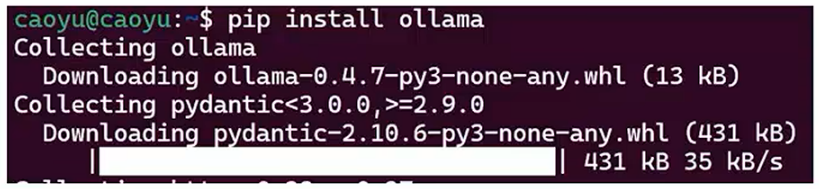

- 安装Streamlit库 (用于Python开发对话页面)
pip install streamlit
PyCharm连接wsL(Ubuntu)
IDE PyCharm内置WSL的支持,可以将Python解释器程序直接连接到WSL内。
实现: 用Windows的PyCharm,在Linux上写代码,并在Linux上运行。
- 创建一个基于WSL的PyCharm工程
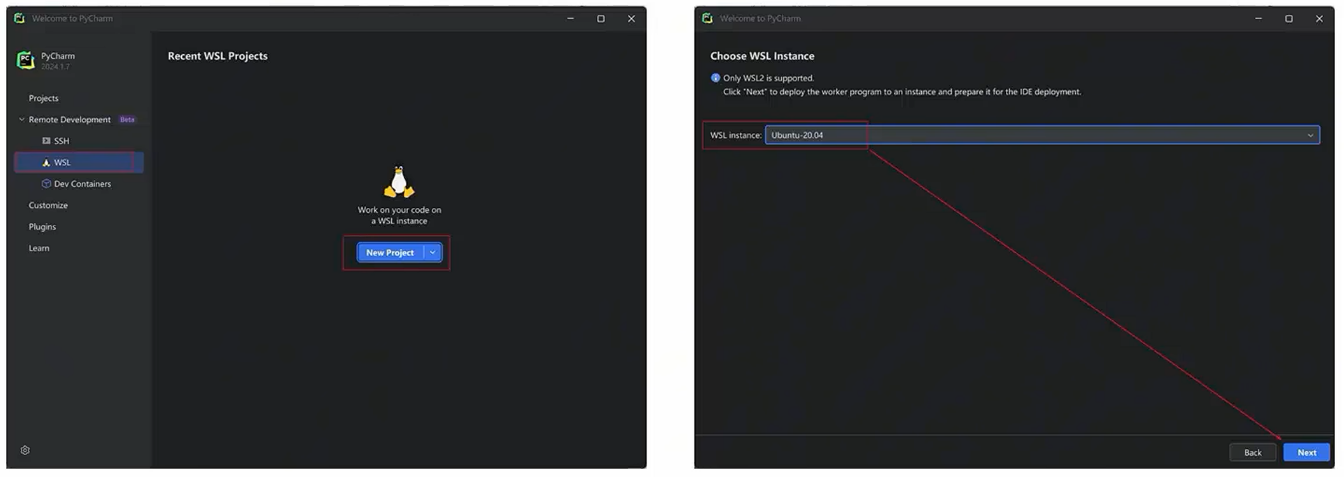
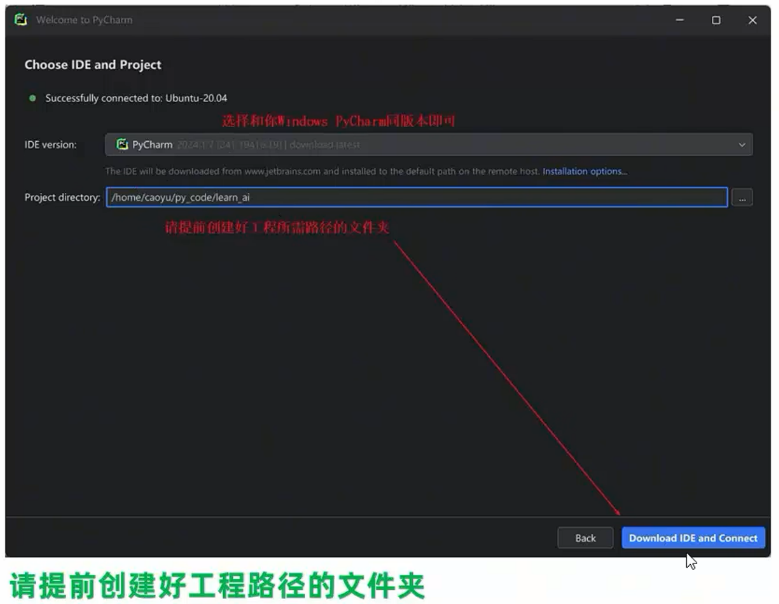
- 选择在WSL部署的PyCharm版本,以及选择工程路径
- 点击右下角的Python解释器,进入Interpreter Settings,确认解释器是Linux路径
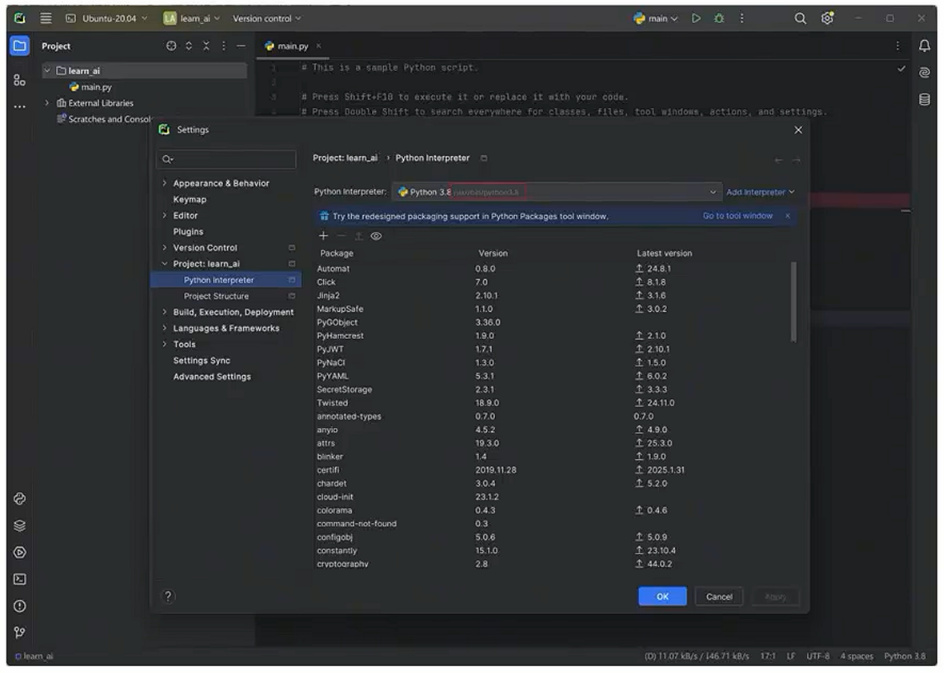
- 创建Python代码文件,执行如下代码, 如未报错则ollama和streamlit库可用。
请先启动Ollama服务(sudo systemctl start ollama)
import ollama
import streamlit
print(f"Ollama当前可用模型:{ollama.list()}")print(f"streamlit版本:{streamlit.__version__}")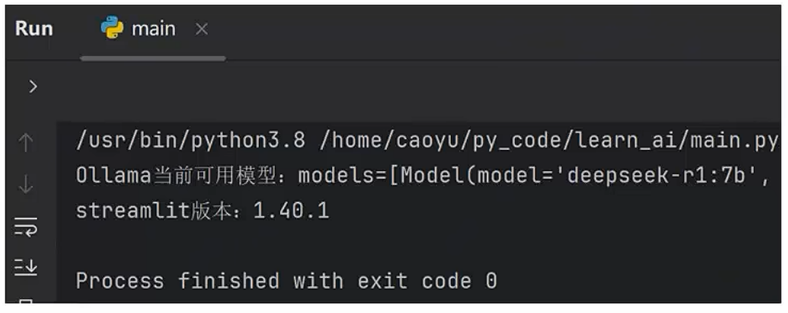
Ollama Python库基础APl
- 首先确认Ollama已经启动(sudo systemctl start ollama)
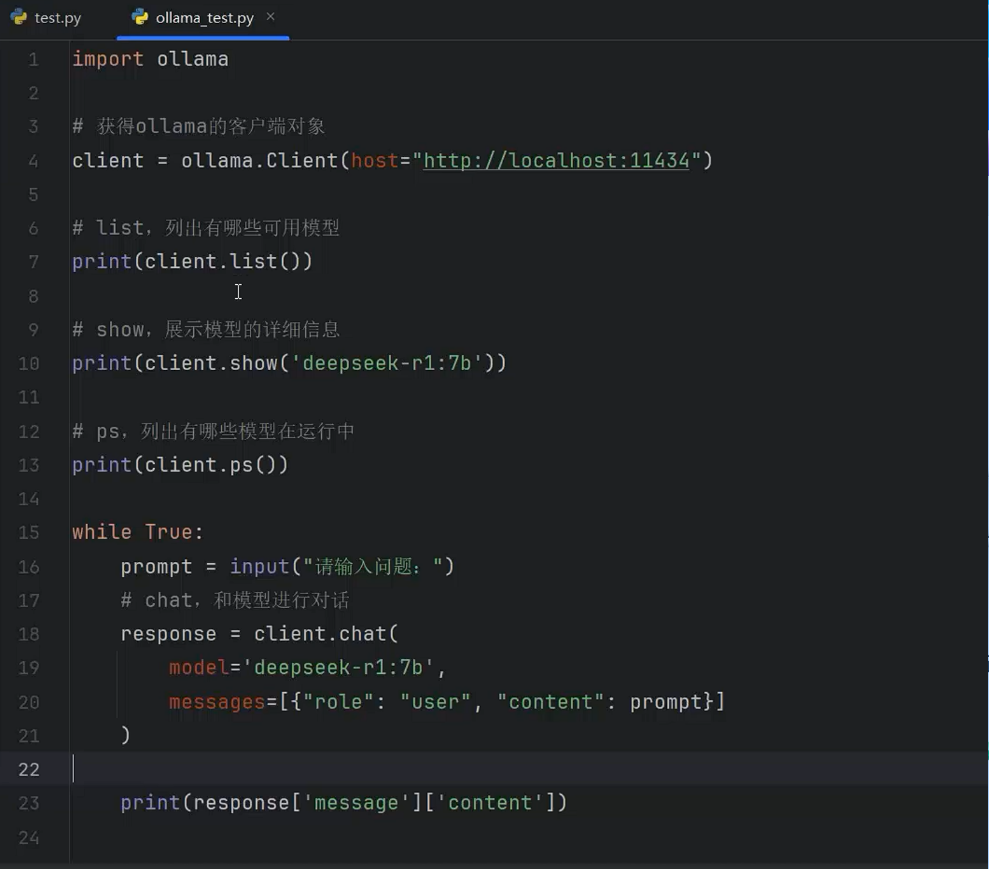
- 使用Python操作Ollama,最主要的一步是获得Ollama客户端对象,使用如下代码

-
当有了client对象后,可以使用client对象提供的方法,完成对Ollama的操作
client对象提供的操作API有
1.list方法,列出可用模型
clent.list()
2.show方法,显示指定模型的详细信息
client.show('deepseek-r1:7b')
3.ps方法,显示当前正在运行的模型
4.chat方法,与模型进行对话,示例代码
response = client.chat(model='deepseek-r1:7b', messages=[{'role':'user', 'content':'你是谁'})
print(response[ 'message']['content'])
Streamlit介绍
现在我们已经有了Ollama后端,同时也掌握了其Python的编程接下来就是提供一个前端界面。
- 从可定制的角度分析,我们选择Streamlit框架用以实现所需前端界面。
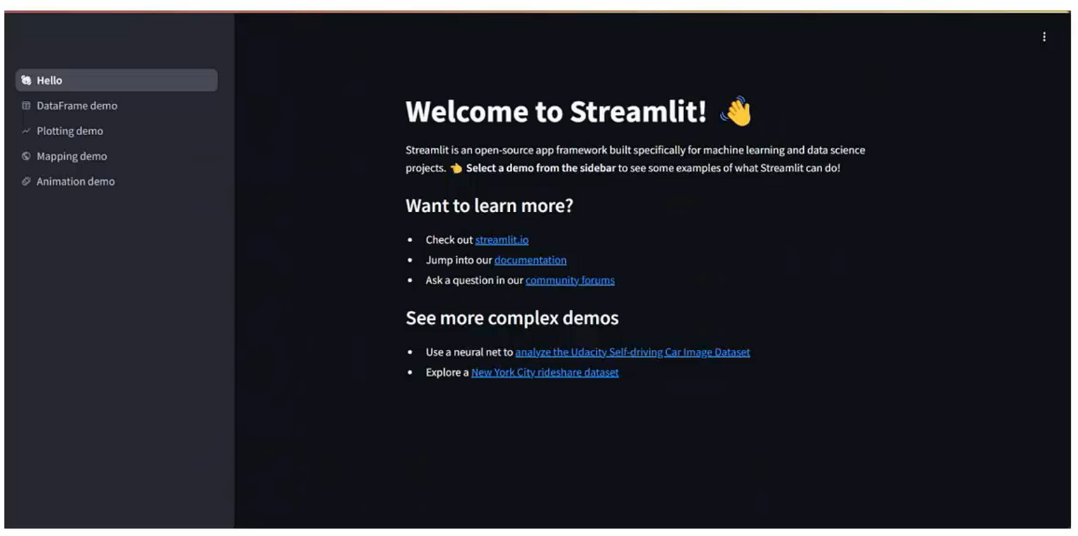
- Streamlit自带了一个示例程序,我们可以执行: streamlit hello
- 启动执行后输入一个Email地址即可,会自动打开浏览器,如下:
- Stremlit APl入门
我们使用少量的Streamlit API即可开发出聊天WEB页面。
导包: import streamlit as st





Stremlit开发对话网页
掌握了基础API后,现在可以开发一个基础的对话网页了
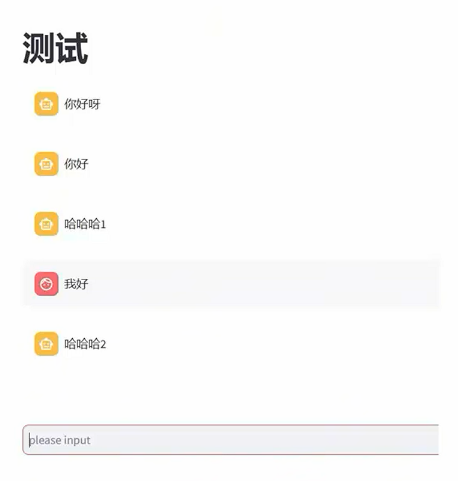
- 如图所示,可以完成多轮对话
- 用户可以提问
- 也可以输出回答(固定回答,后续替换为大模型回答)
- Streamlit session_state的使用
Streamlit本质是无限循环执行用户代码,可以看到上述代码的count永远是1,同时历史会话被清除。
如果要保存上下文状态,可以使用Streamlit的session_state
session_state是一个字典, 基于Key-Value形式,可以保存任意用户所需的内容

-
工程代码
"""
通过Streamlit完成聊天机器人页面开发
"""
import streamlit as st
import ollama_utils as utils添加标题
st.title("黑马聊天机器人")
添加分割线
st.divider()
输出第一条消息 机器人欢迎语
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好我是人工智能机器人,有什么可以帮到您!"}]
# st.session_state["message"].append({"role": "assistant", "content": "你好我是人工智能机器人,有什么可以帮到您!"})list.append({"role": "user", "content": "内容"})
state["message"] = [ {"role": "user", "content": "内容"} , {"role": "user", "content": "内容"}]
每一个消息的对话分为2部分: 角色,内容
机器人 角色:assistant 内容:说的话
人 角色:user 内容:说的话
for message in st.session_state["message"]:
st.chat_message(message["role"]).write(message["content"])用户输入 在页面下方添加用户输入栏
prompt = st.chat_input()
if prompt: # 如果prompt有内容 表示用户提问
# 首先将用户的提问在页面输出 st.chat_message("user").write(prompt) # 把用户提问这个对话保存到session_state内 st.session_state["message"].append({"role": "user", "content": prompt}) # 调用AI回答 with st.spinner("正在思考中..."): # 转圈圈的加载框 res = utils.get_response(prompt) # 将AI回答信息写到屏幕上 st.chat_message("assistant").write(res) # 将AI回答的消息记录到session_state内 st.session_state["message"].append({"role": "assistant", "content": res})