在大语言模型(LLM)技术爆发后,AI Agent已成为连接模型能力与实际业务场景的核心载体。它能模拟人类思考与行动逻辑,自主调用工具、管理上下文、编排任务流程,实现从"被动响应"到"主动解决问题"的跨越。本文将基于AI框架设计核心知识,从技术底层到主流框架选型,再到实操案例,全方位拆解AI Agent框架的设计逻辑与落地路径,为开发者提供系统的学习指南。一、AI Agent框架的核心技术支柱
一个成熟的AI Agent框架,本质是一套"大脑-双手-记忆-中枢"的协同系统。四大核心模块相互支撑,决定了Agent的智能化水平与适用场景,这也是框架设计的核心命题。
1.大脑:LLM适配层与Prompt****工程化
LLM作为Agent的"大脑",负责逻辑推理与决策生成,但不同厂商的模型(如OpenAI、Qwen、DeepSeek)存在API接口、参数格式、输出规范的差异。框架的首要任务的是通过"适配层"抹平差异,实现对多模型的统一调用。
适配器模式的核心价值:采用设计模式中的"适配器模式",为不同LLM封装统一接口,开发者无需关注底层模型的调用细节,仅通过标准方法(如invoke)即可触发模型响应。该模式不仅降低了模型切换成本,还实现了参数配置(temperature、top_p)与输出格式(统一转为Message对象)的标准化。
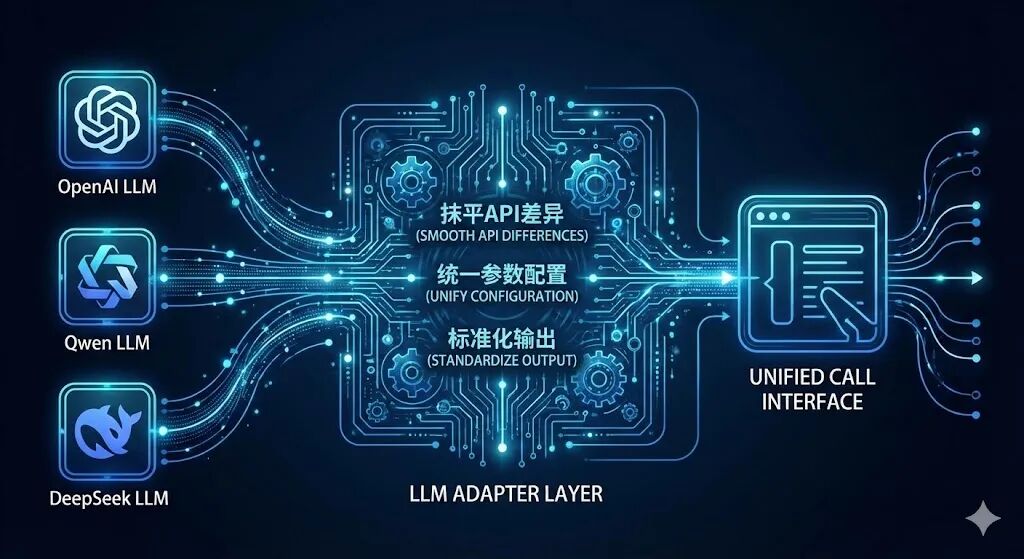
三大主流框架的LLM封装实现:
•LangChain:通过ChatTongyi、ChatOpenAI等专属类封装模型,支持100+主流LLM,生态覆盖最广,适配层可灵活扩展自定义模型。
•Qwen-Agent:采用字典配置(llm_cfg)模式,支持自定义模型服务地址(model_server),对阿里生态模型(Qwen系列)有深度优化,配置简洁高效。
•LlamaIndex:将LLM封装与全局Settings结合,支持DashScope、OpenAI等类实例化调用,与向量索引模块联动更紧密,适合数据驱动场景。
Prompt****工程化:人设与流程解耦:除了模型适配,Prompt的工程化设计直接影响Agent的决策质量。框架通过"动态注入System Message"机制,将Agent人设(角色定义)与任务流程(上下文指令)分离,实现Prompt的复用与维护。例如LangChain的ChatPromptTemplate支持通过MessagesPlaceholder自动注入对话历史,Qwen-Agent的system_instruction可直接定义工具调用流程,大幅提升Prompt的灵活性。
**2.**双手:工具注册与调度机制
LLM的原生能力局限于文本生成,工具注册与调度模块为Agent赋予了"动手能力",使其能调用Python函数、API接口、外部服务等,完成文本之外的复杂任务(如网络诊断、数据分析、图像生成)。
工具调用的核心逻辑 :框架会将Python函数的名称、文档字符串(功能描述)、类型注解(参数类型)转换为LLM可理解的JSON Schema,让模型明确"能调用哪些工具""如何传递参数"。调用后,工具返回结果会作为上下文反馈给LLM,形成"思考-调用-观察"的闭环。

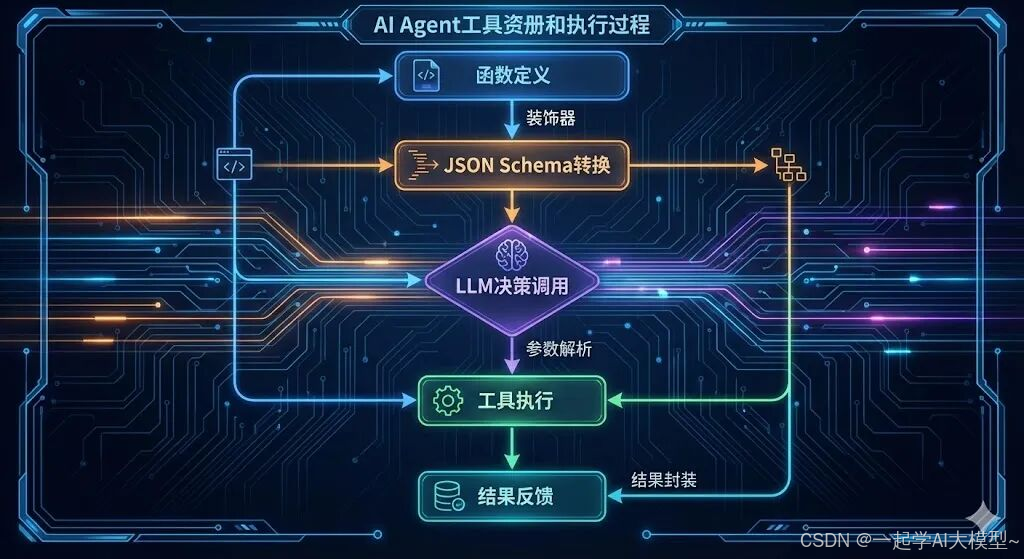
三大框架工具注册方式对比:
| 框架 | 注册方式 | 核心特点 | 适用场景 |
| LangChain | @tool装饰器 | 自动解析docstring与类型注解,零配置上手,贴合Python原生开发习惯 | 快速开发、简单工具封装 |
| Qwen-Agent | @register_tool+类继承 | 显式定义参数约束(必填项、类型),结构清晰,支持复杂参数配置 | 复杂工具链、强约束场景 |
| LlamaIndex | FunctionTool封装 | 强类型校验,可与查询引擎深度集成,适合数据检索类工具 | RAG场景、结构化工具调用 |
**3.**记忆:Context管理机制
LLM本身是无状态的,无法记忆对话历史或过往任务信息。Context管理模块为Agent构建"短期记忆"与"长期记忆",实现上下文感知与历史信息复用,同时避免Token爆炸问题。
短期记忆:会话级上下文管理:聚焦于当前对话会话,通过滑动窗口策略保留最近N轮对话,截断早期无关内容,控制Token消耗。核心依赖Session ID机制,支持多用户并发会话,每个用户的对话历史独立存储。例如LangChain的RunnableWithMessageHistory、Qwen-Agent的messages列表,均通过会话标识实现记忆隔离。
长期记忆:基于RAG的知识存储:针对私有文档、历史任务数据等长效信息,通过RAG(检索增强生成)技术构建向量索引,实现基于语义的相似度检索。LlamaIndex在这一领域表现突出,其VectorStoreIndex支持文档加载、分块、向量化、索引持久化全流程,可对接FAISS、Chroma等向量数据库,检索精度与效率更优。
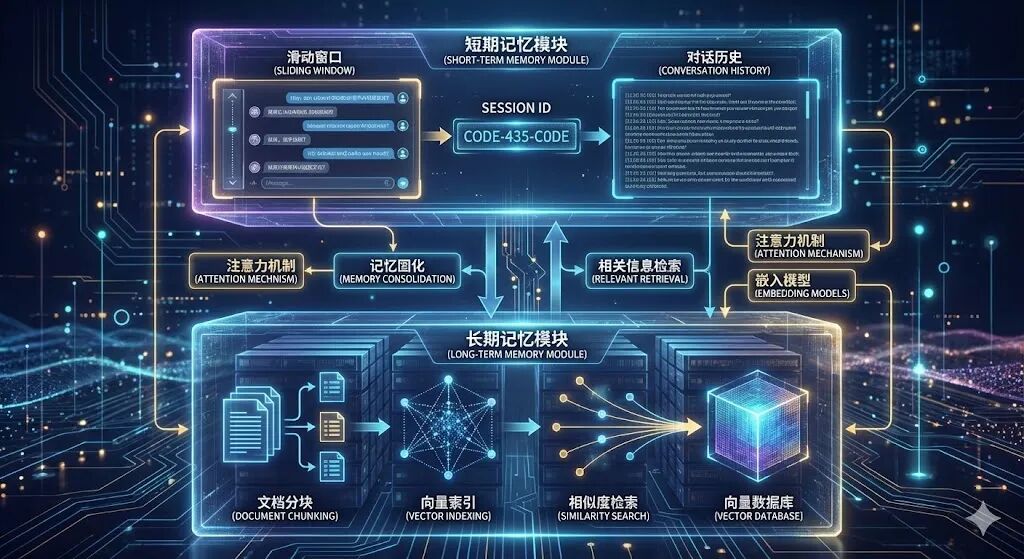
**4.**中枢:控制流编排策略
复杂任务(如投资决策、多文件问答)需要拆解为多个子步骤,控制流编排模块作为Agent的"中枢神经",定义任务执行顺序与协作逻辑,主流分为四种模式:
•管道模式(Pipeline):线性执行流程,如"Prompt→LLM→输出解析",适合简单任务处理。LangChain的LCEL(LangChain Expression Language)通过管道符"|"实现组件链式调用,支持流式输出、批处理、异步调用,灵活性极高。
•循环模式(Loop):基于ReAct框架的"思考-行动-观察"循环,Agent自主判断是否需要调用工具、是否完成任务,直至达成目标。适用于单Agent复杂任务,如网络诊断、代码调试。
•DAG****模式:有向无环图结构,明确子任务依赖关系,类似"接力赛",适合流程化任务(如报表生成、合同审查)。
•群聊模式(Chat):多Agent协同对话,通过角色分工完成复杂任务,如AutoGen的GroupChat,支持多Agent自由讨论或按顺序协作。
二、四大主流AI Agent框架深度选型
目前开源社区的AI Agent框架各有侧重,需结合业务场景、技术栈、开发效率综合选型。以下针对LangChain、LlamaIndex、Qwen-Agent、AutoGen四大框架,从核心定位、技术优势、适用场景展开分析。
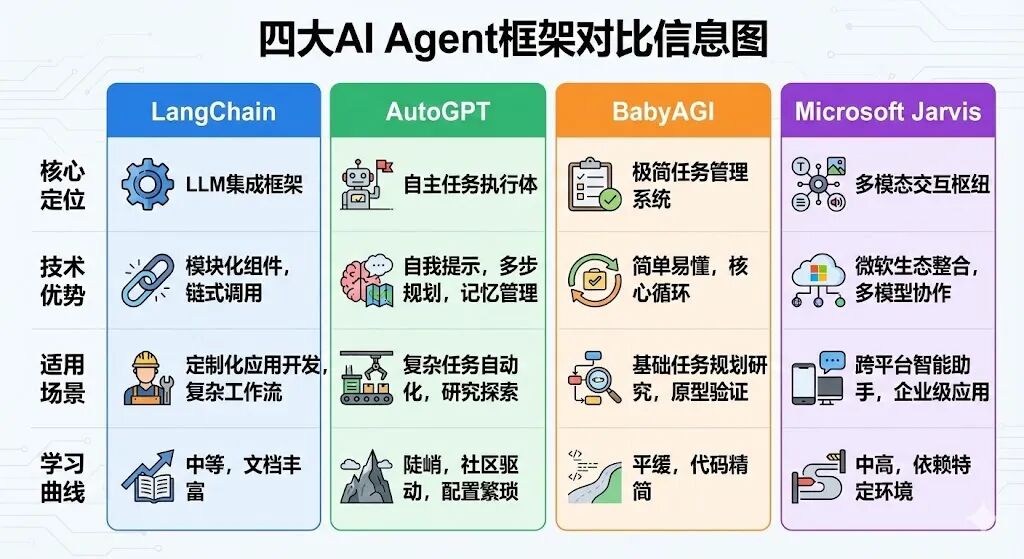
1. LangChain **:全能型LLM应用框架**
核心定位:以"组件化"为核心,提供覆盖Prompt、Model、Memory、Tool、Chain的全栈工具集,生态最丰富,适合构建通用型AI应用。
核心优势:LCEL表达式语言是其标志性创新,支持组件自由组合与复杂流程编排;@tool装饰器简化工具注册;支持100+模型与50+向量数据库,兼容性极强;完善的记忆管理机制,支持多用户并发会话。
适用场景:工具调用型Agent(网络诊断、API调用)、多轮对话系统(客服机器人)、复杂流程编排、快速原型开发(POC)。
2. LlamaIndex **:数据驱动的RAG专家**
核心定位:聚焦"LLM+私有数据"场景,以Index为核心,提供文档加载、分块、向量化、检索、问答全流程能力,是RAG场景的首选框架。
核心优势:Index-First设计哲学,优化数据处理链路;支持向量检索、关键词检索、混合检索等多种策略;索引持久化避免重复计算,启动速度快;与Agent无缝集成,可快速构建文档问答系统。
适用场景:企业知识库、合同审查助手、学术论文分析、基于私有文档的客服机器人。
3. Qwen-Agent**:轻量级全能选手**
核心定位:阿里生态开源框架,专为Qwen模型优化,轻量灵活,开箱即用,聚焦工具调用与代码执行场景。
核心优势:内置Code Interpreter沙箱,支持Python代码生成、执行、错误修正全流程,适合数据分析与可视化;配置式模型调用,上手成本低;内置WebUI,一行代码启动可视化界面,无需前端开发;支持超长上下文(1M Token),适配长文档处理。
适用场景:数据分析与报表生成、图像处理、复杂工具调用链、快速Demo演示。
4. AutoGen**:多智能体协作框架**
核心定位:微软开源框架,以"多Agent对话协作"为核心,通过角色分工与自然语言对话完成复杂任务,2025年10月起进入维护模式,新项目建议迁移至Agent Framework。
核心优势:原生支持GroupChat群聊机制,可自定义发言者选择策略(轮询、随机、LLM自动选择);Agent类型丰富(ConversableAgent、UserProxyAgent),支持工具注册与代码执行;适合多角色协作场景,无需硬编码任务流程。
适用场景:投资决策、复杂文案创作、多领域专家协作任务、需要分工拆解的复杂任务。
三、实操案例:多文件智能问答Agent搭建
以"保险产品智能问答"场景为例,分别基于LangChain、LlamaIndex、Qwen-Agent实现多文件问答Agent,加载雇主责任险、平安商业综合责任险等7类保险文档,支持用户自然语言查询与信息检索。
**1.**技术方案核心:RAG检索增强生成
核心流程:用户问题→向量检索召回相关文档片段→将文档内容与问题结合作为Prompt→LLM生成回答。该方案可解决LLM私有知识缺失问题,避免模型幻觉,同时回答可追溯至具体文档来源。
2. LangChain****实现方案
| python # 1. LLM配置 from langchain_community.chat_models import ChatTongyi llm = ChatTongyi( model_name="deepseek-v3", dashscope_api_key=DASHSCOPE_API_KEY ) # 2. 文档加载与分块 from langchain_community.document_loaders import DirectoryLoader, TextLoader from langchain.text_splitter import RecursiveCharacterTextSplitter loader = DirectoryLoader( "./docs", glob="/*.txt", loader_cls=TextLoader, loader_kwargs={"encoding": "utf-8"} ) documents = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(documents) # 3. 向量索引构建 from langchain_community.vectorstores import FAISS from langchain_community.embeddings import DashScopeEmbeddings embeddings = DashScopeEmbeddings(model_name="text-embedding-v2", api_key=DASHSCOPE_API_KEY) vector_store = FAISS.from_documents(chunks, embeddings) vector_store.save_local("./langchain_storage") # 4. 问答链构建(LCEL语法) from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough qa_prompt = ChatPromptTemplate.from_messages( ("system", "严格根据以下上下文回答问题,不要编造信息:\\n{context}"), ("human", "{question}") ) retriever = vector_store.as_retriever(search_kwargs={"k": 3}) qa_chain = ( {"context": retriever |
3. LlamaIndex****实现方案
| python # 1. 全局配置(LLM与Embedding) from llama_index.core import Settings from llama_index.llms.dashscope import DashScope from llama_index.embeddings.dashscope import DashScopeEmbedding Settings.llm = DashScope(model="deepseek-v3", api_key=DASHSCOPE_API_KEY) Settings.embed_model = DashScopeEmbedding(model_name="text-embedding-v2", api_key=DASHSCOPE_API_KEY) # 2. 文档加载与索引构建 from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, load_index_from_storage from llama_index.core.storage import StorageContext import os persist_dir = "./storage" if os.path.exists(persist_dir): # 从持久化存储加载索引 storage_context = StorageContext.from_defaults(persist_dir=persist_dir) index = load_index_from_storage(storage_context) else: # 新建索引并持久化 reader = SimpleDirectoryReader("./docs") documents = reader.load_data() index = VectorStoreIndex.from_documents(documents) index.storage_context.persist(persist_dir=persist_dir) # 3. 构建检索工具与Agent from llama_index.core.agent import ReActAgent from llama_index.core.tools import FunctionTool query_engine = index.as_query_engine(similarity_top_k=3) # 定义检索工具 def retrieve_documents(query: str) -> str: """从保险文档中检索相关信息""" response = query_engine.query(query) return str(response) retrieve_tool = FunctionTool.from_defaults(fn=retrieve_documents) # 创建ReAct Agent agent = ReActAgent.from_tools( tools=retrieve_tool, llm=Settings.llm, verbose=True, system_prompt="你是保险知识问答助手,仅通过检索工具获取信息回答问题,不编造内容。" ) # 4. 对话交互 response = agent.chat("雇主责任险与团体意外险的区别是什么?") print(response) |
4. Qwen-Agent****实现方案
| python # 1. 环境配置与工具定义 import os import json5 import urllib.parse from qwen_agent.agents import Assistant from qwen_agent.tools.base import BaseTool, register_tool # 配置LLM参数 llm_cfg = { 'model': 'deepseek-v3', 'model_server': 'https://dashscope.aliyuncs.com/compatible-mode/v1', 'api_key': os.getenv('DASHSCOPE_API_KEY'), 'generate_cfg': {'top_p': 0.8, 'temperature': 0.7} } # 自定义工具(可选,此处无需额外工具,依赖内置文档处理) @register_tool('my_image_gen') class MyImageGen(BaseTool): description = 'AI绘画服务,输入文本描述生成图像URL' parameters = { 'name': 'prompt', 'type': 'string', 'description': '图像内容的详细描述', 'required': True } def call(self, params: str, **kwargs) -> str: prompt = json5.loads(params)'prompt' prompt = urllib.parse.quote(prompt) return json5.dumps({'image_url': f'https://image.pollinations.ai/prompt/{prompt}'}, ensure_ascii=False) # 2. 加载文档并创建Assistant def get_doc_files(): """获取文档文件列表""" doc_dir = "./docs" return os.path.join(doc_dir, f) for f in os.listdir(doc_dir) if f.endswith('.txt') files = get_doc_files() system_instruction = """你是保险知识问答助手,需从提供的保险文档中提取信息回答用户问题,严格遵循以下规则: 1. 仅基于文档内容回答,不编造任何信息; 2. 清晰区分不同保险产品的特点,避免混淆; 3. 回答结构清晰,分点说明核心内容。""" # 创建Agent(传入文档列表) bot = Assistant( llm=llm_cfg, system_message=system_instruction, function_list='my_image_gen', 'code_interpreter', # 加载工具 files=files ) # 3. 流式对话交互 messages = \[\] query = "财产一切险的保障范围是什么?" messages.append({'role': 'user', 'content': query}) current_index = 0 for response in bot.run(messages=messages): if response: current_response = response0'content'current_index: current_index = len(response0'content') print(current_response, end='') # 4. 启动内置WebUI(可选) # from qwen_agent.gui import WebUI # WebUI(bot).run() |
四、框架选型决策指南
结合业务场景与技术需求,可按以下维度快速选择框架:
1.企业知识库 **/**文档问答:优先选LlamaIndex,其专业的RAG能力与文档处理链路,能大幅降低开发成本,检索精度更优。
2.快速Demo/POC开发:优先选Qwen-Agent,内置WebUI与Code Interpreter,配置简单,无需前端与额外工具集成,开箱即用。
3.复杂流程编排 **/**多模型适配:优先选LangChain,LCEL语法与丰富的生态组件,支持灵活的流程设计与多模型切换,扩展性极强。
4.多角色协作 **/**复杂任务拆解:优先选AutoGen(存量项目)或Agent Framework(新项目),原生多Agent协作机制,适合分工明确的复杂任务。
五、总结与展望
AI Agent框架的核心价值,在于将LLM的通用能力转化为可落地的业务解决方案,通过"大脑-双手-记忆-中枢"的协同设计,打破模型原生局限。LangChain、LlamaIndex、Qwen-Agent、AutoGen四大框架各有侧重,开发者需立足业务场景,平衡开发效率、性能与扩展性选型。
未来,AI Agent框架将朝着"轻量化、低代码、多模态"方向演进,同时多框架融合(如LangChain集成LlamaIndex的RAG能力)将成为主流。掌握框架的核心设计原理与实操方法,是开发者抓住LLM应用落地机遇的关键。
后续可尝试基于本文案例扩展功能,如添加权限管理、文档格式适配(PDF/Word)、问答结果溯源等,进一步提升Agent的实用性与生产级能力。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

大模型全套学习资料展示
自我们与MoPaaS魔泊云 合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现"AI+行业"跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要) 

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中...
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】