练习最大的收获就是先进行模仿,在发现问题,解决问题,最后掌握!
**上一篇文章题目:**Python基础(10):Python函数基础详解
链接: https://blog.csdn.net/2501_94250394/article/details/156517202?spm=1001.2014.3001.5501
前言
前面给小伙伴们分享了Python函数基础知识,今天和大家一起学习一下进阶模式,一起来探索一下,看看都有哪些神奇的知识点。旅程开始:
偷瞄一眼今天的内容:
一、函数的参数进阶
1.1 函数的参数
在函数定义与调用时,我们可以根据自己的需求来实现参数的传递。在Python中,函数的参数一共有两种形式:
① 形参 ② 实参(昨天文章的拓展内容里面也进行了解释)
形参:在函数定义时,所编写的参数就称之为形式参数,也就是定义函数时括号内声明的参数,仅作为接收数据的占位符,无具体实际值,比如add_num(a, b)里面的a和b。
实参:在函数调用时,所传递的参数就称之为实际参数,也就是调用函数时括号内传入的具体数据或变量,用于给对应形参赋值,比如add_num(3, 5)里面的3和5。
案例:
python
def greet(name): # name:形参(局部变量)
return name + ',您好'
# 调用函数
name = '张三' # name:全局变量(存储实参值)
result = greet(name) # 传递实参值'张三'给形参name
print(result) # 输出:张三,您好1.2 函数的参数类型(调用)
我们在传参的时候有一下几种方式,大家可以选择自己喜欢的方式。
1.2.1 位置参数
理论上,在函数定义时,我们可以为其定义多个参数,这是 Python 函数参数的基础形式。位置参数的核心是按照参数定义的先后位置,进行一一对应的传递 ,即在函数调用时,传递的实参数量必须与函数定义的位置参数数量完全一致(不能多也不能少),且实参的顺序必须和形参的定义顺序严格匹配。
案例:
python
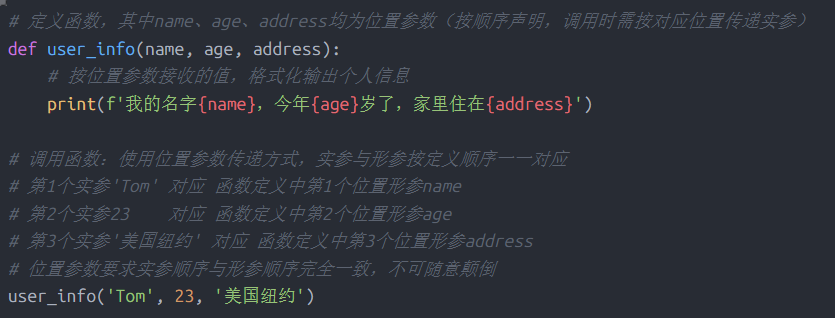
# 定义函数,其中name、age、address均为位置参数(按顺序声明,调用时需按对应位置传递实参)
def user_info(name, age, address):
# 按位置参数接收的值,格式化输出个人信息
print(f'我的名字{name},今年{age}岁了,家里住在{address}')
# 调用函数:使用位置参数传递方式,实参与形参按定义顺序一一对应
# 第1个实参'Tom' 对应 函数定义中第1个位置形参name
# 第2个实参23 对应 函数定义中第2个位置形参age
# 第3个实参'美国纽约' 对应 函数定义中第3个位置形参address
# 位置参数要求实参顺序与形参顺序完全一致,不可随意颠倒
user_info('Tom', 23, '美国纽约')1.2.2 关键词参数(Python特有)
关键词参数是 Python 中灵活便捷的参数传递形式,其核心是通过 "键 = 值" 的形式明确指定实参对应的形参,其中 "键" 必须是函数定义时声明的形参名称,"值" 是要传递给该形参的具体数据。这种传递方式可以让函数调用的语义更加清晰、容易理解,使用者无需记忆形参的定义顺序,同时也彻底清除了参数传递的顺序限制。
案例:
python
# 定义函数,声明三个形参:name、age、address(用于接收后续调用时传递的参数值)
def user_info(name, age, address):
# 格式化输出接收的参数值,展示个人信息
print(f'我的名字{name},今年{age}岁了,家里住在{address}')
# 调用函数:采用Python关键词参数(键=值)的传递方式
# 关键词参数通过"形参名=实参值"的形式明确指定对应关系,无需依赖形参定义顺序
# name='Tom':明确将实参'Tom'传递给形参name
# age=23:明确将实参23传递给形参age
# address='美国纽约':明确将实参'美国纽约'传递给形参address
# 该传参方式语义清晰,可读性更强,即使打乱参数顺序也能正确赋值
user_info(name='Tom', age=23, address='美国纽约')
#关键词传参不需要遵照形参的顺序,比如下面的形式也成立
user_info(age=23, address='美国纽约',name='Tom')1.2.3 函数定义时缺省参数(参数默认值)
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
**注意:所有位置参数必须出现在默认参数前,包括函数定义和调用,**我们在定义缺省参数时,一定要把其写在参数列表的最后侧。
案例:
python
# 定义函数:name、age是位置参数,gender是缺省参数(默认值为'男')
def user_info(name, age, gender='男'):
# 格式化输出个人信息
print(f'我的名字{name},今年{age}岁了,我的性别为{gender}')
# 调用函数:未传gender,使用默认值'男'
user_info('李林', 25)
# 调用函数:未传gender,使用默认值'男'
user_info('振华', 28)
# 调用函数:传递gender='女',覆盖默认值
user_info('婉儿', 18, '女')1.3 不定长参数
不定长参数(又称可变参数)是 Python 为解决函数调用时参数数量不确定 (可传递 0 个、1 个或多个参数,甚至不传参)的场景设计的参数类型,核心通过包裹(packing)机制 ,将多个零散参数打包成一个聚合数据类型进行处理,主要分为两种形式 :包裹位置参数(*args) 和包裹关键字参数(**kwargs),二者分工明确,覆盖不同的传参场景。
光看文字可能有点枯燥和不懂,我们来看看具体的案例,加深一下印象和理解。
案例:
不定长元组(位置)参数
python
# 定义一个接收可变数量位置参数的函数,用于输出用户基础信息
def user_info(*args):
#打印args参数,用于查看其存储格式
print(args) # 元组类型数据,对传递参数有顺序要求,参数会按传入顺序打包进元组
# 格式化输出用户信息,通过元组索引获取对应位置的参数值
# args[0]:获取传入的第1个参数(姓名)
# args[1]:获取传入的第2个参数(年龄)
# args[2]:获取传入的第3个参数(居住地)
print(f'我的名字{args[0]},今年{args[1]}岁了,住在{args[2]}')
# 调用函数,传递参数
# 按「姓名、年龄、居住地」的顺序传递3个位置参数,参数会被自动打包成元组传入args
user_info('Tom', 23, '美国纽约')不定长字典(关键字)参数
python
def user_info(**kwargs):
# print(kwargs) # 字典类型数据,对传递参数没有顺序要求,格式要求key = value值
print(f'我的名字{kwargs["name"]},今年{kwargs["age"]}岁了,住在{kwargs["address"]}')
# 调用函数,传递参数
user_info(name='Tom', address='美国纽约', age=23)**注意:**kw = keyword + args;无论是包裹位置传递还是包裹关键字传递,都是一个组包的过程。
Python组包:就是把多个数据组成元组或者字典的过程。
二、lambda函数
2.1 普通函数与匿名函数的区别
Python 普通函数(def定义,有名)支持复杂逻辑、灵活返回值,适用于重复调用和维护扩展;匿名函数(lambda定义,无名)仅单行表达式、自动返回结果,适用于临时简单功能或高阶函数参数。
注意:如果一个函数有一个返回值,并且只有一句代码,可以使用 lambda简化。
2.2 lambda表达式基本语法
基本语法:
python
变量 = lambda 函数参数:表达式(函数代码 + return返回值)
# 调用变量
变量()案例:编写表达式
定义一个函数,经过一系列操作,最终返回100
python
def fn1():
return 100
# 调用fn1函数
print(fn1) # 返回fn1函数在内存中的地址
print(fn1()) # 代表找到fn1函数的地址并立即执行lambda表达式进行简化:
python
fn2 = lambda : 100
print(fn2) # 返回fn2在内存中的地址
print(fn2())2.3 lambda表达式
2.3.1 带参数的lambda表达式:
比如编写一个函数求两个数的和:
python
def fn1(num1, num2):
return num1 + num2
print(fn1(10, 20))lambda表达式进行简化:
python
fn2 = lambda num1, num2:num1 + num2
print(fn2(10, 20))2.3.2 带默认参数的lambda表达式
python
fn = lambda a, b, c=100 : a + b + c
print(fn(10, 20))2.3.3 带if判断(三目运算符)的lambda表达式
python
fn = lambda a, b : a if a > b else b
print(fn(10, 20))2.4 列表数据+字典数据排序(重点)
知识点:列表.sort(key=排序的key索引, reverse=True)
注意具体案例,稍微字典和元组稍微有点区别
案例:
python
# 元素是元组,格式:(姓名, 年龄),索引0=姓名,索引1=年龄
student_tuples = [('Tom', 20), ('Rose', 19), ('Jack', 22)]
# key=lambda x: x[0] 就是指定"元组索引0"作为排序key,对应"排序的key索引"
student_tuples.sort(key=lambda x: x[0]) # 按索引0(姓名)排序案例:
注意:在字典里面,key 后面并不是真正的 "列表索引",而是指定字典的键作为排序依据
python
# 定义一个存储学生信息的字典列表,每个元素是包含name和age的字典
students = [
{'name': 'Tom', 'age': 20},
{'name': 'Rose', 'age': 19},
{'name': 'Jack', 'age': 22}
]
# 按学生name对应的值进行升序排列(默认reverse=False,无需显式指定)
# key=lambda x: x['name']:lambda接收列表中的每个字典元素x,返回x的'name'值作为排序关键字
# 排序后姓名顺序:Jack → Rose → Tom
students.sort(key=lambda x: x['name']) # Jack/Rose/Tom
# 打印按姓名升序排序后的学生列表
print(students)
# 按学生name对应的值进行降序排列
# reverse=True:开启降序排序,覆盖默认的升序规则
# 排序后姓名顺序:Tom → Rose → Jack
students.sort(key=lambda x: x['name'], reverse=True)
# 打印按姓名降序排序后的学生列表
print(students)
# 按学生年龄age对应的值进行升序排列
# key=lambda x: x['age']:lambda接收列表中的每个字典元素x,返回x的'age'值作为排序关键字
# 排序后年龄顺序:19(Rose)→ 20(Tom)→ 22(Jack)
students.sort(key=lambda x: x['age'])
# 打印按年龄升序排序后的学生列表
print(students)三、总结
转眼Python基础知识分享就快要结束了,不知道我分享的内容对于小伙伴来说通俗易懂不?我最近也抽空看了一下,感觉文字内容写太多吧,又害怕小伙伴们抓不住重点,写太少吧,也害怕大家不好理解,最近稍微有点矛盾,希望小伙伴们也在评论区发表一下建议,我后期进行修改。
今天突然发现Coze扣子首页竟然进行了更新,变得更加简单容易操作了,之前搭建智能体和工作流都需要手动一个一个操作,现在直接可以和ai交流,ai直接就可以一步完成了,操作确实简化了好多。
所以我准备在Python基础知识分享完毕之后,给大家分享一期实用的工具集,之后开始分享如何利用Coze平台搭建属于自己的智能体和业务工作流!!!
上述内容会根据大家的评论和实际情况进行实时更新和改进。
麻烦小伙伴们动一动发财的小手,给小弟点个赞和收藏,如果能获得小伙伴的关注将是我无上的荣耀和前进的动力。
小伙伴们,我是AI大佬的小弟,希望大家喜欢!!!
晚安,兄弟们。