1. 写在最前面
趁着假期前,继续学习一下之前没有深入理解的 ReActAgent 的工作原理。果然假期马上就可以出去玩的想法会让人心猿意马。(ps : 但是今天晚上还是要继续去锻炼的......
2. ReActAgent 浅析
2.1 什么是 ReAct
ReAct 这个名字很有意思,它其实是 Reasoning(推理) 和 Acting(行动) 两个词的组合。这个命名本身就揭示了 ReActAgent 的核心思想:通过推理来决定行动,通过行动的结果来指导下一步推理。
具体代码示例:
ini
from beeai_framework.agents.react import ReActAgent
from beeai_framework.backend import ChatModel
from beeai_framework.memory import UnconstrainedMemory
from beeai_framework.tools.code import PythonTool, SandboxTool
# ReActAgent 的创建非常简单
agent = ReActAgent(
llm=ChatModel.from_name("ollama:granite3.3:8b"),
tools=[python_tool, sandbox_tool],
memory=UnconstrainedMemory()
)从代码来看,ReActAgent 的 API 非常简洁,只需要提供 LLM、工具列表和内存管理即可。但简洁的背后,隐藏着强大的自主决策能力。
注:思考一下理论上 LLM 都需要提供特定的 prompt 才能够让 LLM 按照预期返回,但是上面的 ReActAgent 木有要求设置
2.2 为什么无需设置 prompt
答案是因为,ReActAgent 需要 LLM 严格按照 ReAct 格式输出:
- Thought: → 思考过程
- Action: → 选择的工具
- Action Input: → 工具输入
- Observation: → 工具执行结果
- Final Answer: → 最终答案
这个格式是固定的,必须由框架内置的 Prompt 模板来保证。
3. ReActAgent 的核心机制
3.1 ReAct 循环:推理与行动的交替
ReActAgent 的核心是一个循环过程,每次循环都包含以下几个步骤:
- Thought(思考) :Agent 分析当前情况,思考下一步应该做什么
- Action(行动) :根据思考结果,选择并调用合适的工具
- Action Input(行动输入) :为选定的工具提供输入参数
- Observation(观察) :观察工具执行的结果
- Final Answer(最终答案) :如果任务完成,提供最终答案;否则继续下一轮循环
这个循环过程可以用下面的流程图表示:
css
用户问题
↓
[Thought] → 分析问题,决定需要什么工具
↓
[Action] → 选择工具(如 PythonTool)
↓
[Action Input] → 提供工具输入(如 Python 代码)
↓
[Observation] → 观察执行结果
↓
[Thought] → 分析结果,决定下一步
↓
├─→ 如果任务完成 → [Final Answer]
└─→ 如果未完成 → 继续循环举例本地的调用如下:
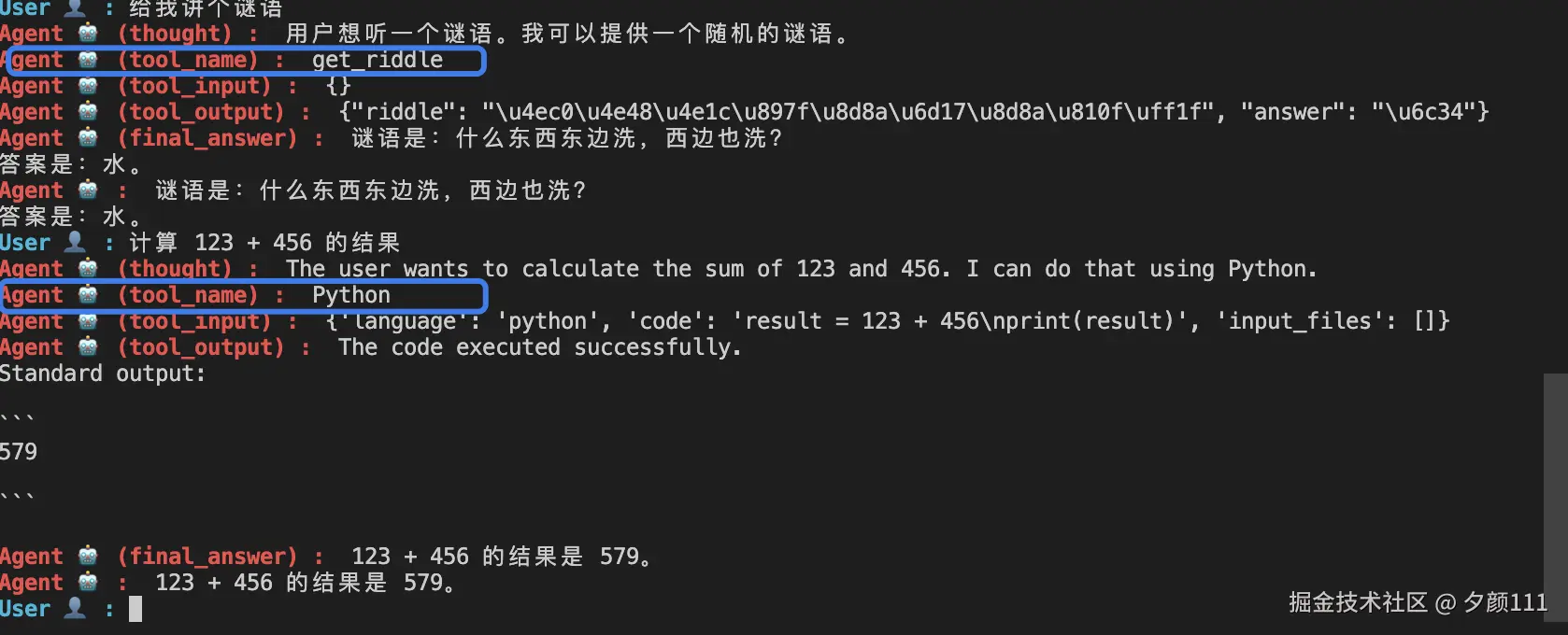
3.2 为什么需要多轮推理?
很多复杂任务无法一次性完成,需要多轮推理。举个例子:
用户问题:"计算 1 到 100 的平方和,然后找出所有大于 1000 的平方数"
这个任务需要:
- 第一轮:计算 1 到 100 的平方和
- 第二轮:根据第一轮的结果,找出所有大于 1000 的平方数
如果使用 RequirementAgent,开发者需要预先定义这两步的执行顺序。但如果使用 ReActAgent,Agent 可以自主决定:
- 先执行第一步
- 观察结果
- 根据结果决定是否需要执行第二步
- 如果第一步的结果已经足够,可能直接给出答案
这种灵活性在处理复杂、动态的任务时特别有用。
3.3 错误处理与自我修正
ReActAgent 的另一个强大之处在于它的错误处理能力。当工具执行失败时,Agent 可以:
- 分析错误原因:通过 Observation 观察错误信息
- 推理修复方案:在下一轮 Thought 中分析如何修复
- 尝试修复:调用工具进行修复或重试
ini
# 示例:Agent 执行代码时遇到错误
# Round 1:
# Thought: 需要计算 10/0
# Action: PythonTool
# Action Input: result = 10 / 0
# Observation: ZeroDivisionError: division by zero
# Round 2:
# Thought: 出现了除零错误,需要添加错误处理
# Action: PythonTool
# Action Input:
# try:
# result = 10 / 0
# except ZeroDivisionError:
# result = "Cannot divide by zero"
# Observation: 代码执行成功,result = "Cannot divide by zero"这种自我修正的能力,让 ReActAgent 能够处理一些不可预见的错误情况。
4. ReActAgent 的使用场景
4.1 适合场景
-
代码执行和计算
- 动态生成和执行代码
- 代码解释器(Code Interpreter)
- 数学计算和数据分析
-
复杂问题求解
- 需要多步推理的任务
- 步骤间有依赖关系的任务
- 例如:分析 CSV → 找出最高销售额类别 → 计算平均利润率
-
交互式任务
- 需要根据结果调整策略
- 需要多轮迭代和修正
- 例如:写代码 → 测试 → 修复错误 → 再测试
-
错误恢复
- 需要处理不确定性和错误
- 能够自我修正和重试
- 动态错误处理
4.2 不适合的场景
- 严格流程控制:需要精确控制每一步执行
- 简单工具调用:只需一次或少量工具调用
- LLM 不支持:LLM 输出格式不符合 ReAct 要求
5. 碎碎念
发现关于 AI 的很多不理解,其实是因为同一个意思有多种的表达方式,比如下面这几个,其实是类似同义词来着。
| 人类 | 大模型 |
|---|---|
| 大脑:思考、推理、决策 | LLM 推理能力:理解、分析、决策 |
| 小脑:协调动作、执行操作 | 工具调用能力:调用工具、执行操作 |
| 记忆:存储知识、经验 | RAG:检索知识库、增强回答 |
所以说,再讨论问题之前还是得先统一概念。
你有没有想过,从公元前 221 年秦朝建立到如今,这看似漫长的 2245 年,其实也不过是麦子熟了 2245 回。
其实 1978 年宣布改革开放时,距离清朝灭亡也才过去66年。
如果一个人的生命有 70 年,那么 2245 年,也只是 32 个人生死相接的一生。
我们总是被一些大词裹挟,沉迷于一些宏大叙事、空洞概念,其实不如实在一点,想想这短暂的一生,到底要为什么而活。
注:参考 普通人的一生应该是怎样的?