import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import os
import matplotlib.pyplot as plt
import numpy as np
import time
# ============================
# 设置中文字体和预训练模型下载路径
# ============================
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
os.environ['TORCH_HOME'] = r'E:\PyStudy'
print(f"预训练模型将下载到: {os.environ['TORCH_HOME']}")
# 如果目录不存在,则创建
if not os.path.exists(os.environ['TORCH_HOME']):
os.makedirs(os.environ['TORCH_HOME'])
print(f"已创建目录: {os.environ['TORCH_HOME']}")
# ============================
# CBAM模块定义
# ============================
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, in_channels // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels // ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.conv(out)
return self.sigmoid(out)
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attention = ChannelAttention(in_channels, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.channel_attention(x)
out = out * self.spatial_attention(out)
return out
# ============================
# VGG16 + CBAM 模型
# ============================
class VGG16_CBAM(nn.Module):
def __init__(self, num_classes=10, pretrained=True, cbam_ratio=16, cbam_kernel=7):
super().__init__()
# 打印预训练模型下载信息
if pretrained:
print(f"正在下载VGG16预训练权重到: {os.environ['TORCH_HOME']}")
print("文件大小约528MB,请耐心等待...")
# 加载预训练的VGG16(现在会下载到E:\PyStudy)
vgg = models.vgg16(pretrained=pretrained)
# 获取VGG16的特征提取部分(去除最后的分类层)
self.features = vgg.features
# 在VGG的特定层后添加CBAM模块
self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel)
self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel)
self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel)
self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)
self.cbam_layer5 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel)
# 自适应池化层
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 修改分类头
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
# 根据输入尺寸调整
self._modify_for_small_input()
def _modify_for_small_input(self):
"""修改VGG以更好地适应小尺寸输入(如32x32)"""
self.features[0] = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if hasattr(self.features, 'stride'):
for i, layer in enumerate(self.features):
if isinstance(layer, nn.MaxPool2d):
self.features[i] = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
def forward(self, x):
x = self.features[0:4](x)
x = self.features[4](x)
x = self.cbam_layer1(x)
x = self.features[5:9](x)
x = self.features[9](x)
x = self.cbam_layer2(x)
x = self.features[10:16](x)
x = self.features[16](x)
x = self.cbam_layer3(x)
x = self.features[17:23](x)
x = self.features[23](x)
x = self.cbam_layer4(x)
x = self.features[24:30](x)
x = self.features[30](x)
x = self.cbam_layer5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# ============================
# 简化版VGG16_CBAM
# ============================
class VGG16_CBAM_Simple(nn.Module):
def __init__(self, num_classes=10, pretrained=True):
super().__init__()
if pretrained:
print(f"正在下载VGG16预训练权重到: {os.environ['TORCH_HOME']}")
vgg = models.vgg16(pretrained=pretrained)
self.features = nn.Sequential(*list(vgg.features.children())[:10])
self.cbam = CBAM(in_channels=128)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(128, 256),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.cbam(x)
x = self.classifier(x)
return x
# ============================
# 训练函数(更新版,无需tqdm)
# ============================
def train_epoch(model, dataloader, criterion, optimizer, device):
"""训练一个epoch"""
model.train()
running_loss = 0.0
correct = 0
total = 0
iteration_losses = [] # 记录每个iteration的损失
iteration_indices = [] # 记录iteration序号
print(f"训练中... (共{len(dataloader)}个batch)")
for batch_idx, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 记录每个iteration的损失
iteration_losses.append(loss.item())
iteration_indices.append(batch_idx + 1)
# 每10个batch打印一次进度
if (batch_idx + 1) % 10 == 0 or (batch_idx + 1) == len(dataloader):
current_acc = 100. * correct / total
avg_loss = running_loss / (batch_idx + 1)
print(f" Batch [{batch_idx+1}/{len(dataloader)}] - "
f"Loss: {loss.item():.4f} | "
f"Avg Loss: {avg_loss:.4f} | "
f"Acc: {current_acc:.2f}%")
epoch_loss = running_loss / len(dataloader)
epoch_acc = 100. * correct / total
return epoch_loss, epoch_acc, iteration_losses, iteration_indices
def validate(model, dataloader, criterion, device):
"""验证函数"""
model.eval()
running_loss = 0.0
correct = 0
total = 0
print(f"验证中... (共{len(dataloader)}个batch)")
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 每5个batch打印一次进度
if (batch_idx + 1) % 5 == 0 or (batch_idx + 1) == len(dataloader):
current_acc = 100. * correct / total
print(f" Batch [{batch_idx+1}/{len(dataloader)}] - "
f"Acc: {current_acc:.2f}%")
epoch_loss = running_loss / len(dataloader)
epoch_acc = 100. * correct / total
return epoch_loss, epoch_acc
# ============================
# 微调函数(更新版,50个epoch,无需tqdm)
# ============================
def fine_tune_vgg16_cbam(model, train_loader, val_loader, num_epochs=50, lr=0.001, device='cuda'):
"""微调VGG16+CBAM模型"""
model = model.to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 优化器:不同层使用不同学习率
optimizer = optim.SGD([
{'params': model.features.parameters(), 'lr': lr * 0.1},
{'params': model.cbam_layer1.parameters()},
{'params': model.cbam_layer2.parameters()},
{'params': model.cbam_layer3.parameters()},
{'params': model.cbam_layer4.parameters()},
{'params': model.cbam_layer5.parameters()},
{'params': model.classifier.parameters(), 'lr': lr}
], lr=lr, momentum=0.9, weight_decay=5e-4)
# 学习率调度器(注意:移除了verbose参数)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', patience=5, factor=0.5
)
# 训练历史记录
history = {
'train_loss': [], 'train_acc': [],
'val_loss': [], 'val_acc': [],
'iteration_losses': [], 'iteration_indices': [],
'learning_rates': []
}
best_acc = 0.0
start_time = time.time()
print(f"开始训练,共 {num_epochs} 个epoch...")
print("=" * 70)
for epoch in range(num_epochs):
epoch_start_time = time.time()
print(f"\nEpoch {epoch+1}/{num_epochs}")
print("-" * 50)
# 训练
train_loss, train_acc, iter_losses, iter_indices = train_epoch(
model, train_loader, criterion, optimizer, device
)
# 验证
val_loss, val_acc = validate(model, val_loader, criterion, device)
# 更新学习率
scheduler.step(val_loss)
# 记录学习率
current_lr = optimizer.param_groups[0]['lr']
history['learning_rates'].append(current_lr)
# 保存历史
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
history['iteration_losses'].extend(iter_losses)
history['iteration_indices'].extend([epoch+1] * len(iter_losses))
# 计算epoch耗时
epoch_time = time.time() - epoch_start_time
# 打印结果
print(f"\nEpoch {epoch+1} 结果:")
print(f" ├── 训练损失: {train_loss:.4f}")
print(f" ├── 训练准确率: {train_acc:.2f}%")
print(f" ├── 验证损失: {val_loss:.4f}")
print(f" ├── 验证准确率: {val_acc:.2f}%")
print(f" ├── 学习率: {current_lr:.6f}")
print(f" └── 耗时: {epoch_time:.1f}秒")
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
save_path = os.path.join(os.environ['TORCH_HOME'], 'vgg16_cbam_best.pth')
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'train_acc': train_acc,
'val_acc': val_acc,
'history': history
}, save_path)
print(f" ✓ 最佳模型已保存到: {save_path}")
print("=" * 70)
total_time = time.time() - start_time
print(f"\n训练完成!")
print(f"总耗时: {total_time:.1f}秒 ({total_time/60:.1f}分钟)")
print(f"平均每个epoch耗时: {total_time/num_epochs:.1f}秒")
print(f"最佳验证准确率: {best_acc:.2f}%")
return history
# ============================
# 绘图函数定义
# ============================
def plot_iter_losses(losses, indices):
"""绘制每个iteration的训练损失"""
plt.figure(figsize=(12, 5))
# 计算移动平均(窗口大小为50)
window_size = 50
if len(losses) > window_size:
moving_avg = np.convolve(losses, np.ones(window_size)/window_size, mode='valid')
moving_indices = indices[window_size-1:]
plt.subplot(1, 2, 1)
plt.plot(indices, losses, 'b-', alpha=0.3, label='原始损失', linewidth=0.5)
plt.plot(moving_indices, moving_avg, 'r-', label=f'{window_size}步移动平均', linewidth=2)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个Iteration的训练损失')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(moving_indices, moving_avg, 'r-', linewidth=2)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('损失移动平均')
plt.grid(True, alpha=0.3)
else:
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个Iteration的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
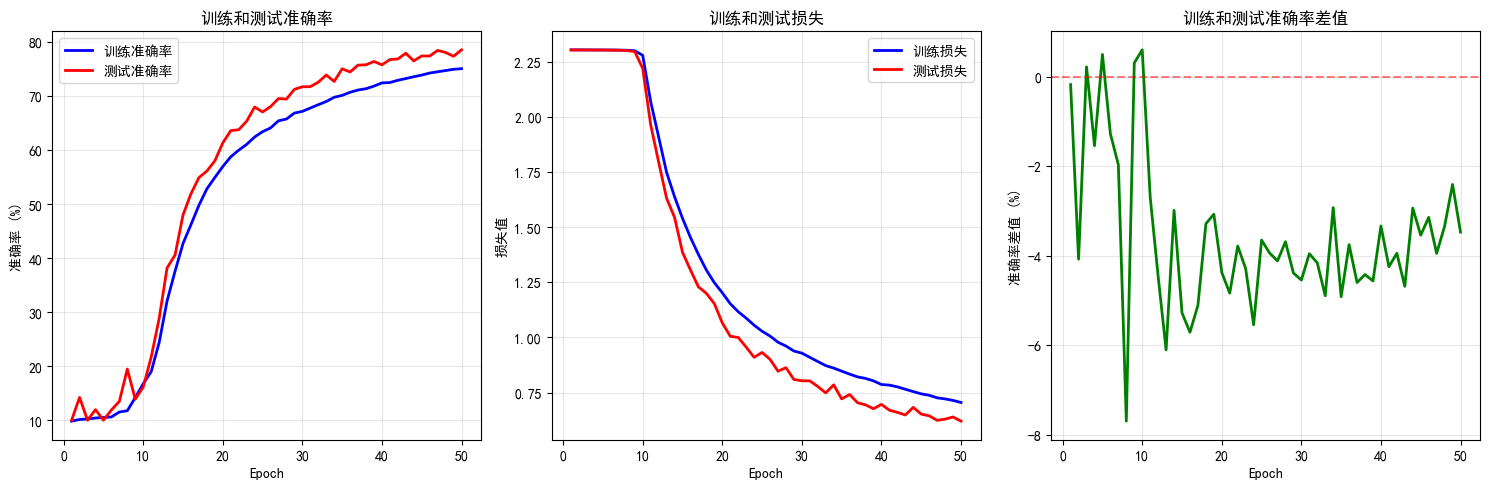
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
"""绘制每个epoch的训练和测试指标"""
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(15, 5))
# 准确率子图
plt.subplot(1, 3, 1)
plt.plot(epochs, train_acc, 'b-', linewidth=2, label='训练准确率')
plt.plot(epochs, test_acc, 'r-', linewidth=2, label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('训练和测试准确率')
plt.legend()
plt.grid(True, alpha=0.3)
# 损失子图
plt.subplot(1, 3, 2)
plt.plot(epochs, train_loss, 'b-', linewidth=2, label='训练损失')
plt.plot(epochs, test_loss, 'r-', linewidth=2, label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('训练和测试损失')
plt.legend()
plt.grid(True, alpha=0.3)
# 训练/测试准确率差值
plt.subplot(1, 3, 3)
accuracy_gap = [train - test for train, test in zip(train_acc, test_acc)]
plt.plot(epochs, accuracy_gap, 'g-', linewidth=2)
plt.axhline(y=0, color='r', linestyle='--', alpha=0.5)
plt.xlabel('Epoch')
plt.ylabel('准确率差值 (%)')
plt.title('训练和测试准确率差值')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
def plot_learning_rate(learning_rates):
"""绘制学习率变化"""
plt.figure(figsize=(10, 4))
epochs = range(1, len(learning_rates) + 1)
plt.plot(epochs, learning_rates, 'b-o', linewidth=2, markersize=6)
plt.xlabel('Epoch')
plt.ylabel('学习率')
plt.title('学习率变化')
plt.yscale('log') # 对数坐标,更清晰显示变化
plt.grid(True, alpha=0.3)
# 添加标注
for i, (epoch, lr) in enumerate(zip(epochs, learning_rates)):
if i == 0 or i == len(learning_rates) - 1 or lr != learning_rates[i-1]:
plt.annotate(f'{lr:.2e}', xy=(epoch, lr), xytext=(5, 5),
textcoords='offset points', fontsize=9)
plt.tight_layout()
plt.show()
def plot_training_summary(history):
"""绘制完整的训练摘要"""
# 1. 绘制epoch级别的指标
plot_epoch_metrics(
history['train_acc'],
history['val_acc'],
history['train_loss'],
history['val_loss']
)
# 2. 绘制iteration级别的损失
plot_iter_losses(history['iteration_losses'], history['iteration_indices'])
# 3. 绘制学习率变化
if 'learning_rates' in history and len(history['learning_rates']) > 0:
plot_learning_rate(history['learning_rates'])
# 4. 打印最终统计信息
print("\n" + "="*60)
print("训练摘要:")
print("="*60)
print(f"最终训练准确率: {history['train_acc'][-1]:.2f}%")
print(f"最终验证准确率: {history['val_acc'][-1]:.2f}%")
print(f"最佳验证准确率: {max(history['val_acc']):.2f}% (第{history['val_acc'].index(max(history['val_acc']))+1}轮)")
print(f"最终训练损失: {history['train_loss'][-1]:.4f}")
print(f"最终验证损失: {history['val_loss'][-1]:.4f}")
# ============================
# 主程序:完整的训练流程
# ============================
if __name__ == "__main__":
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# ============================
# 数据预处理和加载(使用您提供的数据加载器)
# ============================
print("\n准备数据加载器...")
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
print(f"训练集大小: {len(train_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
print(f"训练batch数: {len(train_loader)}")
print(f"测试batch数: {len(test_loader)}")
# ============================
# 创建模型
# ============================
print("\n创建VGG16_CBAM模型...")
use_simple_model = False # 设置为True使用简化版,False使用完整版
if use_simple_model:
model = VGG16_CBAM_Simple(num_classes=10, pretrained=True)
else:
model = VGG16_CBAM(num_classes=10, pretrained=True)
# 统计参数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
# ============================
# 开始训练
# ============================
print("\n" + "="*60)
print("开始VGG16+CBAM模型训练")
print("="*60)
history = fine_tune_vgg16_cbam(
model=model,
train_loader=train_loader,
val_loader=test_loader, # 使用test_loader作为验证集
num_epochs=50,
lr=0.001,
device=device
)
# ============================
# 绘制训练结果
# ============================
print("\n绘制训练结果...")
plot_training_summary(history)
# # ============================
# # 保存最终模型
# # ============================
# final_model_path = os.path.join(os.environ['TORCH_HOME'], 'vgg16_cbam_final.pth')
# torch.save({
# 'model_state_dict': model.state_dict(),
# 'history': history,
# 'config': {
# 'num_classes': 10,
# 'pretrained': True,
# 'simple_version': use_simple_model
# }
# }, final_model_path)
# print(f"\n最终模型已保存到: {final_model_path}")