其实一开始并没有打算为aipy写一篇文章,但是最近在和很多交流中发现,大多数人还是热衷于追逐更先进的ai技术以及更高端的大模型,似乎在交谈中不谈几个高端大模型经验和先进的名词,就仿佛格格不入。小编想借此使用aipy的文章,谈一些普通用户在使用"能落地""能解决问题"的ai过程中的体感。
先来惯例:aipy是什么?
没有小编插图那么赛博,logo其实还挺可爱的,一条紫色的大眼睛小章鱼。


刚开始接触aipy,是在aipy第一次发布会之后,因为都是业内的原因,关注知道创宇的视频号,刷到发布视频后直接试用。


deepseek,让他帮我写了mac安装aipy步骤以及安装所需要依赖资源的脚本,几次调试后成功运行的aipy。出于好奇,写了个贪吃蛇的小游戏(ps:"贪吃蛇"的作者怎么也没想到到,这个游戏竟然成为一个验证ai的默认测试脚本)
但是......由于一开始只是把aipy当"问答机器人"使用,问了几个市场数据的问题,而且aipy返回的数据基本就是------一本正经的胡诌。从此也就没多用。
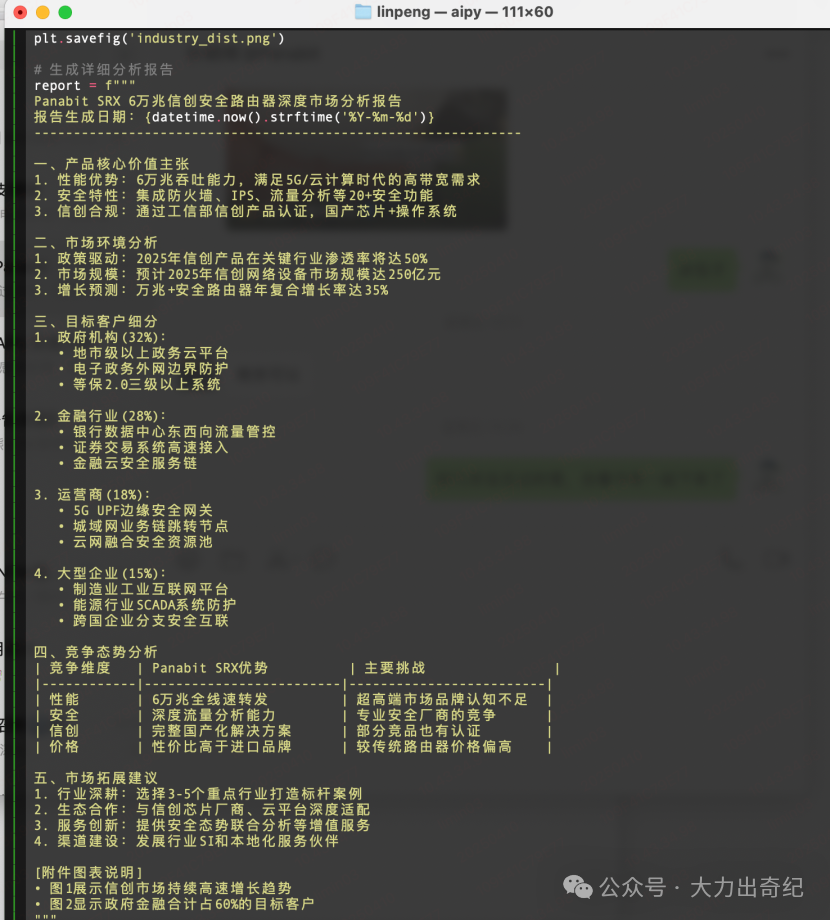
进一步使用aipy,是在上个月,想要用n8n完成一个智能写报告的流程,流程中需要访问不少网站获取原始数据,但是访问这些网站需要注册然后申请一个token,因为n8n拆解流程比较长,所以就需要注册很多网站,于是,想起了小章鱼aipy。
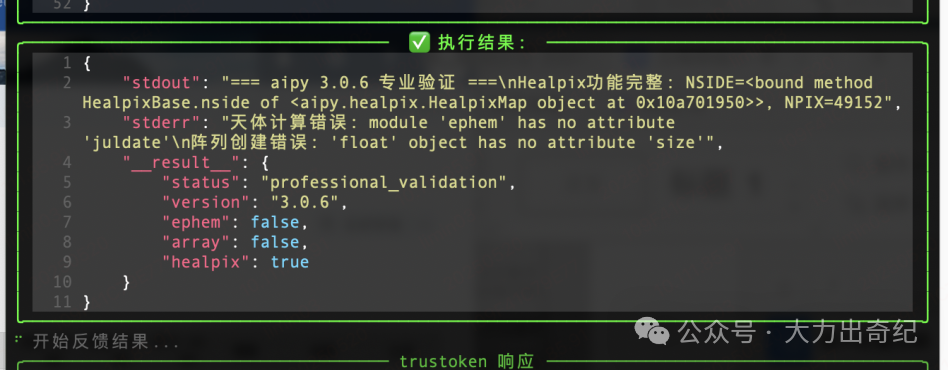
aipy一个提示词,让他帮我写一个能够自动从输入网站注册自动获取token的小程序,为了安全考虑,小编还专门注册了一个给aipy使用的获取token的邮箱账号,但是......没能调用成功。
再次使用aipy的原因是,是在于它的更新迭代速度,所以重新进行了升级。当时不过短短不到2个月,已经更新了二十多个版本。
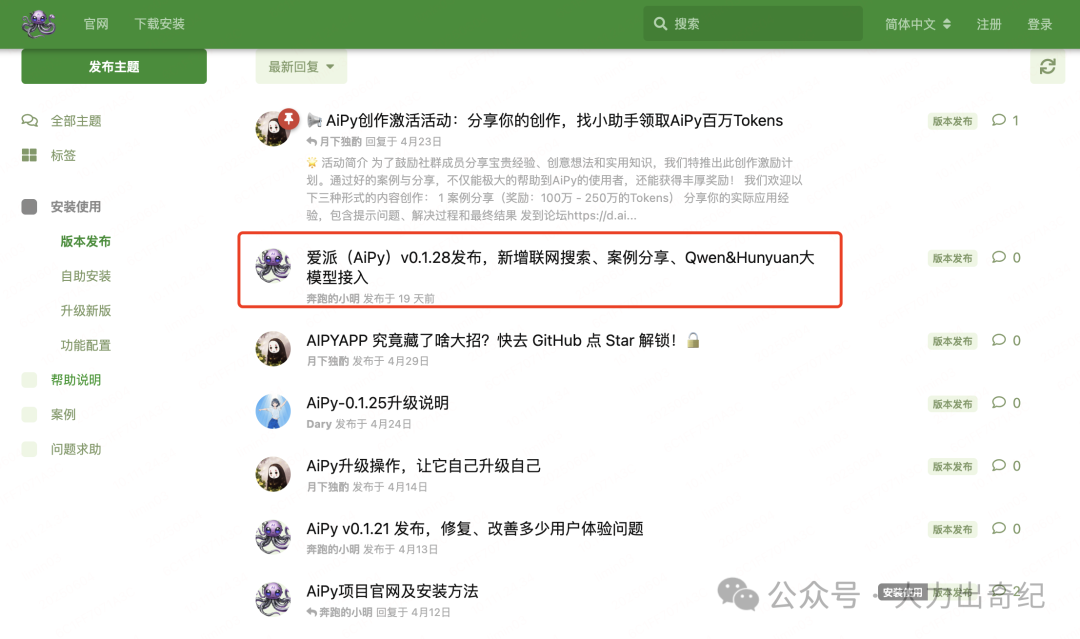
值得一提的是,在升级的过程中,发现了aipy的自我验证程序,在自我认证第一次失败后,它进行了自动重新安装的流程,直到这个"专业验证程序"执行成功。
因为当时正好遇到工作中的一个系统罐装流程问题,一切安装步骤没有问题,但是系统就是run不起来,恰好遇到升级aipy看到这个内置的验证流程,给解决系统安装问题提供了思路。
由此,想到之前看到的一篇文章,写的是如何解决ai大模型中的幻觉,论文提到的方案和aipy的思路雷同,就是内置几个不同的解决思路,当其中解决思路答案一致,则认为大模型返回的是"正确"答案,当其中不一致的概率超过一定比例,则认为大模型回答错误,就会打回大模型的答案,并且打上"此路不通"的标签,以此矫正大模型的幻觉问题。(有点像数学几何题中的辅助线,用于辅助矫正解题思路。。。)
你看,带着脑子用ai,是可以提供新的思路的。
也因此,开始重新使用aipy。并且重新提起之前那个获取token的问题。但是依旧没成功,但是没关系,小编将问题发到aipy社区寻求帮助,没多久,得到了官方的回复。

根据提示词aipy运行之后,大概长这样。
这不重要,因为小编依然没把程序运行成功。重要的是,社区中的用户把aipy玩出了花,有用aipy自动获取关键信息生成总结,有用aipy自动获取最新关注漏洞,甚至有用aipy进行量化交易训练。
量化交易大家可能比较陌生,科普下,deepseek的前身另一个身份是幻方量化,量化的关键是follow,简单来说就是综合多个因子的变化映射到某个基金的变化,实现频次的买入卖出,"多因子""高频次"这些显然机器比人更智能。
当然在这里提这个,并不是想让大家依赖ai炒股,而是想通过这种ai炒股直接影响经济得失表达一件事:ai的结果是因人而异的。
ai发展到现在,在日常工作中,多的是追逐通过ai拿到结果的人,这类小编想归为两类:
一类,是本身是某个领域的专家,通过ai解决一些体力劳动,比如一个数学老师,通过ai帮他写试卷题目;比如一个行研专家,通过ai帮他写行研报告等。
另一类,对某个领域不熟悉,通过几个ai比较对比下,凭借自己已有的知识,对获取几个结果做评论,当然,这种显然是存疑的,但是,防不住这类人对ai的结果深信不疑,导致在真实世界的决策和言论,存在失真。
由此,想到有天看到的一个国外老师的视频,就是痛斥现在的学生拿ai生成论文等行为,直接获取知识。小编至今记得那个老师的呐喊:不要过度依赖ai,而丧失了思考的能力。
言归正传,再谈到aipy,迄今为止,安装一些简单的程序,或者获取一些基本信息,小编都会先让aipy去处理,这节省了一个非程序员但是有一点编码基础和产品思维的人的生产力。
谈到生产力,小编以为,ai在企业中解决的问题有两个,一方面是提升程序员等角色的效率,另外一方面,是提升企业中润滑剂和驱动剂这样一个角色的效率,大多执行者需要这么一个"润滑剂"角色的牵引,总结各方角色信息,推进事情进行,而ai能帮助这类角色提升效率。
另外,谈到效率,大多企业在开源节流的现状下,不妨考虑下更新组织结构,如果让ai融入工作流程中,才能更符合现状的"精兵简政"的措施。
扯远了,回归到aipy的使用,关于社区的感悟远不于此,软件和系统的开源和闭源之争早在计算机初期就有,骇客的鼻祖也是至今开源的坚持者理查德・马修・斯托曼,他倡导开源能够让用户权益最大化;闭源就不得不提乔帮主,闭源无疑能更专注且更高效的为用户提供更专业的体验,这是商业的天平倾斜的问题。
就此,小编认为,aipy社区是一个半开源的状态,从他的更新迭代速度,到社区用户的互相分享经验等,无疑给了aipy更多的反馈。
由此小编想到,ai的未来是开源还是闭源,就此,就有了之前关于"专业"使用ai贡献数据的可参考性,以及"非领域专业"人士对ai贡献的反馈,ai视万物为数据贡献者,但是至此,开源状态下,显然ai尚未能分辨贡献质量。
言归正传,总结几个想法如下:
1、多点落地,少点高屋建瓴:aipy作为一个可落地并且持续迭代的应用,鉴于当前大多ai的分散以及ai应用的待评估性,希望大家更多关注在当前ai能为我们解决什么问题,而不是只关注多么先进的"大模型"。换句话说,航母和筷子一样对人民有用,无需站在大模型的制高点上,高姿态的俯视当前能落地的应用。时间周期拉长到50或者100年,这须臾体感上的优越感,只是幻觉。
2、AI -NATURE的HR:ai确实对企业的工作流程有提效作用,某些大企业关注于人力成本,不如早点将ai简化工作流的基础建设好。当然这也不是一句话的事,越大的企业需要越多的周期去实现ai转化为节省成本,新公司如果一开始将ai纳入工作流中,会更好的节省基础成本。
Ai nature的公司未来一定程度会成为正常现象,在此之前,ai-hrbp将会成为中大型企业的一个过度态,hr会将ai作为一个"员工""招贤纳士"到公司的流程中。(企业ai化也许是咨询的下一个风口。)
3、你需要给大模型提交你的名片:与其想方设法验证ai的"拟人",不如更多的让ai成为你的另一只手,小编发现给的提示词越多越丰富,无论哪个大模型,给出的效果都会更好。
假设大模型支持几千字甚至几万字的提示词,能够描述使用者足够多的信息,那么大模型之间的差异还会那么大么?小编不得而知。但是小编知道,youtube上有个博主把写更多提示词卖课,课程卖到1万美金。
4、带着脑子用ai:ai很强大,是专业人士的助手,但是对于某个领域一知半解的人来说,就是把双刃剑。原因很简单,大多数人不具备大量数据实验和论证的能力,只对某个"先进"或者"高价"模型的几条结论就信以为真,这无疑是不具备参考价值的。
在此,小编以为,作为使用者更应该把ai当作一个和自己共频、或者和自己知识体系有补集的外挂"备脑",但是不应该让ai代替自己思考。大多数人会误以为ai给的"答复"就是"答案",无法分辨出"知道"并不是"知识",反而逐渐丧失大脑惯性思考训练的能力。
大模型到现在的问答(除了某些幻听外)都还是依据超大数据的推理科学,至少现在这个阶段,经过实验论证的数据依旧是评判的基准。
作为用户,大模型背后的知识远比一个个体使用者多的多,无需用个体有限的知识去论证ai无限知识库的真伪,并且轻易的拿到现实中做决策,除非你是在某个领域有一定的知识积累,或者有大量数据论证实践,这显然是有门槛的。
5、名词定义的重要性:之前看到对于agence的定义,一个新事物出现的时候,一个词语从此赋予这个新事物一个新的生命,一个在现实世界的"公众认同",ai有可能取代某个职位或者职业,但是它不应该取代人类的大脑,而更应该成为我们的第二大脑,小编更愿意称它为se-mbrgenc。
当你把更多的你的信息和对现实世界的描述给你的第二大脑,那它将会成为你的另一只带脑子的左膀右臂,就像aipy那样,一个可以调动多个大模型的"八爪鱼",这就不得不提到"莫妮卡"------一个多模型的调度智能体。
下次再讲讲"莫妮卡",这个能让你调用多个大模型的"ai助理"。
最后,愿我们和ai都有美好的未来。