Week 7: SQL
官方笔记 :https://cs50.harvard.edu/x/notes/7/
本周内容概览
| 主题 | 核心概念 | 重要程度 |
|---|---|---|
| 扁平文件数据库 | CSV 文件、csv 模块 |
⭐⭐ |
| 关系型数据库 | 表、行、列、键 | ⭐⭐⭐⭐ |
| SQL 基础命令 | SELECT, INSERT, DELETE, UPDATE | ⭐⭐⭐⭐⭐ |
| 表间关系 | 主键、外键、JOIN | ⭐⭐⭐⭐ |
| 索引优化 | INDEX, B-Tree | ⭐⭐⭐ |
| Python + SQL | cs50.SQL, 参数化查询 | ⭐⭐⭐⭐ |
| 安全性 | SQL 注入、竞态条件 | ⭐⭐⭐⭐⭐ |
Welcome
在过去几周里,我们向大家介绍了 Python------一种高级编程语言,它采用了与 C 语言相同的构建模块。然而,我们引入这门新语言的目的并非为了学习"又一门语言",而是因为某些工具更适合特定任务,而对其他任务则效果欠佳!
本周我们将:
- 继续学习 Python 的语法知识
- 将这些知识与数据处理相结合
- 探讨 SQL(结构化查询语言)------这种领域特定的语言能让我们与数据进行交互并修改
💡 核心目标 :本课程的核心目标是培养通用编程能力,而非仅仅掌握课程中介绍的特定语言。
Flat-File Database
经过前面的学习,你可能已经注意到,数据通常可以以列和行的模式来描述。
诸如Microsoft Excel和Google Sheets创建的电子表格,均可导出为csv(逗号分隔值)文件。
观察csv文件时你会发现,该文件采用扁平化存储------所有数据都存储在一个由文本文件表示的单一表格中。我们称这种数据形式为扁平文件数据库。
所有数据按行存储。每列之间以逗号或其他分隔符分隔。
Python原生支持csv文件格式。
首先,下载favorites.csv文件并上传至cs50.dev网站内的文件管理器。其次,观察数据结构可发现:首行具有特殊含义,用于定义各列属性。随后每条记录按行依次存储。
在终端创建 favorites.py 如下:
# Prints all favorites in CSV using csv.reader
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create reader
reader = csv.reader(file)
# Skip header row
next(reader)
# Iterate over CSV file, printing each favorite
for row in reader:
print(row[1])注意,代码导入了 csv 库。此外,创建了一个 reader 对象来存储 csv.reader(file) 的结果。 csv.reader 函数从文件中读取每一行,在我们的代码中,我们将结果存储在 reader 中。因此, print(row[1]) 将打印出 favorites.csv 文件中的 language。
提高代码可读性,修改如下
# Stores favorite in a variable
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create reader
reader = csv.reader(file)
# Skip header row
next(reader)
# Iterate over CSV file, printing each favorite
for row in reader:
favorite = row[1]
print(favorite)请注意 favorite 被存储并打印。另外,请注意我们使用 next 函数跳转到我们的读者下一行。
上述方法的一个缺点是,我们假设 row[1] 始终是 favorite 的结果。但如果列的位置被调换了呢?
我们可以修复这个潜在问题。Python 还允许你通过列表的键来索引。按照以下方式修改你的代码:
# Prints all favorites in CSV using csv.DictReader
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Iterate over CSV file, printing each favorite
for row in reader:
favorite = row["language"]
print(favorite)请注意,这个示例在 print 语句中直接使用了 key 为 language的列 。 favorite 被赋值为 row"language" 的 value。
也可以直接使用,
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Iterate over CSV file, printing each favorite
for row in reader:
print(row["language"])要统计在 csv 文件中表达的最喜欢的语言数量,我们可以这样做:
# Counts favorites using variables
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
scratch, c, python = 0, 0, 0
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["language"]
if favorite == "Scratch":
scratch += 1
elif favorite == "C":
c += 1
elif favorite == "Python":
python += 1
# Print counts
print(f"Scratch: {scratch}")
print(f"C: {c}")
print(f"Python: {python}")统计结果
$ python favorites.py
Scratch: 24
C: 58
Python: 190注意,每种语言都是使用 if 语句进行计数的。此外,注意这些 if 语句中使用的 == 操作符,不是 =
Python 还可以使用字典来统计每种语言的 counts 数量。以下是改进后的代码:
# Counts favorites using dictionary
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
counts = {}
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["language"]
if favorite in counts:
counts[favorite] += 1
else:
counts[favorite] = 1
# Print counts
for favorite in counts:
print(f"{favorite}: {counts[favorite]}")注意,当 counts 中的Key favorite 已存在时,其对应的 value 的值会递增。如果不存在,我们定义 counts[favorite] 并将其设置为 1。此外,格式化字符串也同步修改,以正确打印 counts[favorite] 。
进一步优化,可以使用 try 和 except 捕获处理异常
# Uses try/except instead
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
counts = {}
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["language"]
try:
counts[favorite] += 1
except KeyError:
counts[favorite] = 1
# Print counts
for favorite in counts:
print(f"{favorite}: {counts[favorite]}")上述代码使用 try...except 替换了 if ... else
Python 还可以对 counts 排序,继续修改代码如下:
# Sorts favorites by key
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
counts = {}
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["language"]
if favorite in counts:
counts[favorite] += 1
else:
counts[favorite] = 1
# Print counts
for favorite in sorted(counts):
print(f"{favorite}: {counts[favorite]}")打印结果
$ python favorites.py
C: 58
Python: 190
Scratch: 24注意,这里是按 key 进行排序的。
如果你查看 Python 文档中 sorted 函数的参数,你会发现它有很多内置参数。下面的代码是其中一些内置参数的使用:
# Sorts favorites by value using .get
import csv
# Open CSV file
with open("favorites.csv", "r") as file:
# Create DictReader
reader = csv.DictReader(file)
# Counts
counts = {}
# Iterate over CSV file, counting favorites
for row in reader:
favorite = row["language"]
if favorite in counts:
counts[favorite] += 1
else:
counts[favorite] = 1
# Print counts
for favorite in sorted(counts, key=counts.get, reverse=True):
print(f"{favorite}: {counts[favorite]}")注意传递给 sorted 的参数。 key 参数用来告诉 Python 用户希望的排序方法。在本例中, counts.get 指定按 value 排序。 reverse=True 告诉 sorted 从大到小排序。
更多关于 Python 中 sort 用法请查看官方文档。
关系型数据库
Google、X(Twitter)和 Meta 都使用关系型数据库存储大规模信息。
💡 核心特点 :关系型数据库将数据存储在称为**表(Table)的行和列结构中,表之间通过键(Key)**建立关联。
CRUD 操作
SQL 允许四种基本操作,被亲切地称为 CRUD:
| 操作 | SQL 命令 | 含义 |
|---|---|---|
| Create | INSERT |
创建/插入数据 |
| Read | SELECT |
读取/查询数据 |
| Update | UPDATE |
更新数据 |
| Delete | DELETE |
删除数据 |
我们可以使用 SQL 语法 CREATE TABLE table (column type, ...); 创建数据库。但这个命令应该在哪里运行呢? |
||
| sqlite3 是一种 SQL 数据库,具备本课程所需的核心功能。 | ||
我们可以在终端中输入 sqlite3 favorites.db 来创建一个 SQL 数据库。在系统提示时,按 y 键确认创建 favorites.db 文件。 |
||
| 此时会出现不同的提示符,因为我们现在正在使用名为 sqlite 的程序。 | ||
我们可以通过输入 .mode csv 将 sqlite 切换至 csv 模式。随后,输入 .import favorites.csv favorites 即可从 csv 文件导入数据。看起来什么都没发生! |
||
我们可以输入 .schema 来查看数据库的结构。 |
||
你可以使用语法 SELECT columns FROM table 从表中读取数据。 |
||
例如,输入 SELECT * FROM favorites; 将打印 favorites 表中的所有行。 |
||
使用命令 SELECT language FROM favorites; 可获取数据子集。 |
$ sqlite3 favorites.db
Are you sure you want to create favorites.db? [y/N] y
sqlite> .mode csv
sqlite> .import favorites.csv favorites
sqlite> .schema
CREATE TABLE IF NOT EXISTS "favorites"(
"Timestamp" TEXT, "language" TEXT, "problem" TEXT);SQL支持多种用于访问数据的命令,包括:
AVG
COUNT
DISTINCT
LOWER
MAX
MIN
UPPER例如,你可以输入 SELECT COUNT(*) FROM favorites;。此外,输入 SELECT DISTINCT language FROM favorites; 可获取数据库中所有语言的列表。你甚至可以输入 SELECT COUNT(DISTINCT language) FROM favorites; 来统计这些语言的数量。
SQL 提供了可在查询中使用的额外命令:
WHERE -- adding a Boolean expression to filter our data
LIKE -- filtering responses more loosely
ORDER BY -- ordering responses
LIMIT -- limiting the number of responses
GROUP BY -- grouping responses together注意,-- 是 sql 的注释符。
SELECT
-
比如,执行
SELECT COUNT(*) FROM favorites WHERE language = 'C';将会打印出favorites表中 选择 C 语言的人数。-- SELECT COUNT() FROM favorites WHERE language = 'C';
sqlite> SELECT COUNT() FROM favorites WHERE language = 'C';
+----------+
| COUNT(*) |
+----------+
| 58 |
+----------+ -
SELECT COUNT(*) FROM favorites WHERE language = 'C' AND problem = 'Hello, World';
注意,使用 AND 运算符来缩小查询结果范围。sqlite> SELECT COUNT() FROM favorites WHERE language = 'C' AND problem = 'Hello, World';
+----------+
| COUNT() |
+----------+
| 5 |
+----------+ -
SELECT language, COUNT(*) FROM favorites GROUP BY language;
将生成一个临时表,其中包含 language 和其对应统计息。sqlite> SELECT language, COUNT() FROM favorites GROUP BY language;
+----------+----------+
| language | COUNT() |
+----------+----------+
| C | 58 |
| Python | 190 |
| Scratch | 24 |
+----------+----------+ -
SELECT language, COUNT(*) FROM favorites GROUP BY language ORDER BY COUNT(*);
这条语句是对上条语句的改进:。实现按计数对结果表进行排序。sqlite> SELECT language, COUNT() FROM favorites GROUP BY language ORDER BY COUNT();
+----------+----------+
| language | COUNT(*) |
+----------+----------+
| Scratch | 24 |
| C | 58 |
| Python | 190 |
+----------+----------+ -
SELECT COUNT(*) FROM favorites WHERE language = 'C' AND (problem = 'Hello, World' OR problem = 'Hello, It''s Me');
注意这里使用了两个''标记,这样就能在不混淆SQL语义的前提下使用单引号。sqlite> SELECT COUNT() FROM favorites WHERE language = 'C' AND (problem = 'Hello, World' OR problem = 'Hello, It''s Me');
+----------+
| COUNT() |
+----------+
| 5 |
+----------+ -
SELECT COUNT(*) FROM favorites WHERE language = 'C' AND problem LIKE 'Hello, %';
查询所有以Hello开头的problem(包括空格)。sqlite> SELECT COUNT() FROM favorites WHERE language = 'C' AND problem LIKE 'Hello, %';
+----------+
| COUNT() |
+----------+
| 5 |
+----------+ -
SELECT language, COUNT(*) FROM favorites GROUP BY language ORDER BY COUNT(*) DESC;
对方输出结果排序。sqlite> SELECT language, COUNT() FROM favorites GROUP BY language ORDER BY COUNT() DESC;
+----------+----------+
| language | COUNT(*) |
+----------+----------+
| Python | 190 |
| C | 58 |
| Scratch | 24 |
+----------+----------+ -
SELECT language, COUNT(*) AS n FROM favorites GROUP BY language ORDER BY n DESC;
可以在查询中创建别名,就像为变量创建别名一样:sqlite> SELECT language, COUNT(*) AS n FROM favorites GROUP BY language ORDER BY n DESC;
+----------+-----+
| language | n |
+----------+-----+
| Python | 190 |
| C | 58 |
| Scratch | 24 |
+----------+-----+ -
SELECT language, COUNT(*) AS n FROM favorites GROUP BY language ORDER BY n DESC LIMIT 1;
将输出限制为1个或多个值:sqlite> SELECT language, COUNT(*) AS n FROM favorites GROUP BY language ORDER BY n DESC LIMIT 1;
+----------+-----+
| language | n |
+----------+-----+
| Python | 190 |
+----------+-----+
注意,按惯例,SQL 关键字通常采用大写字母书写。
INSERT
可以使用以下格式向SQL数据库插入数据:INSERT INTO table (column...) VALUES(value, ...);
比如 INSERT INTO favorites (language, problem) VALUES ('SQL', 'Fiftyville'); 将会插入一行,其 language, problem 对应的值分别为 'SQL', 'Fiftyville'
通过执行 SELECT * FROM favorites; 可以发现 favorites 表多了一行。
sqlite> INSERT INTO favorites (language, problem) VALUES ('SQL', 'Fiftyville');
sqlite> SELECT * FROM favorites;
+---------------------+----------+-----------------------+
| Timestamp | language | problem |
+---------------------+----------+-----------------------+
| 10/20/2025 9:45:26 | Python | Readability |
| 10/20/2025 10:08:03 | Python | Mario |
| 10/20/2025 11:20:23 | Python | Filter |
| 10/20/2025 13:37:05 | Python | Starting from Scratch |
...
| 10/20/2025 13:38:52 | Python | Speller |
| 10/20/2025 13:38:54 | Python | DNA |
| 10/20/2025 13:38:57 | C | Filter |
| NULL | SQL | Fiftyville |
+---------------------+----------+-----------------------+DELETE
DELETE 允许删除数据的某些部分。例如,执行 DELETE FROM favorites WHERE Timestamp IS NULL;。将删除所有 Timestamp 为 NULL 的记录。
sqlite> INSERT INTO favorites (language, problem) VALUES ('SQL', 'Fiftyville');
sqlite> SELECT * FROM favorites;
+---------------------+----------+-----------------------+
| Timestamp | language | problem |
+---------------------+----------+-----------------------+
| 10/20/2025 9:45:26 | Python | Readability |
...查看,前面我们插入的那条记录已经被删除了。
UPDATE
UPDATE命令用来更新数据。
例如,执行UPDATE favorites SET language = 'SQL', problem = 'Fiftyville';将更新所有记录。
请注意这些查询具有强大威力。因此在实际应用中,务必考虑哪些用户具备执行特定命令的权限,并确保已创建备份 !
如果你再次查询,发现 favorites 表所有的 record 的 (language, problem) 都被更新为 ('SQL', 'Fiftyville')
sqlite> UPDATE favorites SET language = 'SQL', problem = 'Fiftyville';
sqlite> SELECT * FROM favorites;
+---------------------+----------+------------+
| Timestamp | language | problem |
+---------------------+----------+------------+
| 10/20/2025 9:45:26 | SQL | Fiftyville |
| 10/20/2025 10:08:03 | SQL | Fiftyville |
| 10/20/2025 11:20:23 | SQL | Fiftyville |
| 10/20/2025 13:37:05 | SQL | Fiftyville |
...
| 10/20/2025 13:38:54 | SQL | Fiftyville |
| 10/20/2025 13:38:57 | SQL | Fiftyville |
+---------------------+----------+------------+IMDb 案例研究
问题引入
设想一个用于编目电视节目的数据库。如果创建电子表格,列出 title, star, star, star, star 等主演信息:
| title | star1 | star2 | star3 | star4 |
|------------|--------------|-------------|--------|-------|
| The Office | Steve Carell | Rainn Wilson| ... | NULL |
| Friends | Jennifer Aniston | ... | ... | ... |问题:存在大量空间浪费------某些节目可能只有一位主演,而另一些则可能有数十位。
规范化设计
我们可以将数据库拆分为多个表:
| 表名 | 用途 | 主键 |
|---|---|---|
shows |
存储节目信息 | id |
people |
存储演员信息 | id |
stars |
关联节目和演员 | show_id + person_id |
通过"节目ID" show_id 和"演员ID" person_id 建立关联。这种设计称为数据库规范化。
IMDb 数据库结构
IMDb 构建了涵盖演员、节目、编剧、明星、类型及评分的数据库。这些表之间的关系如下:
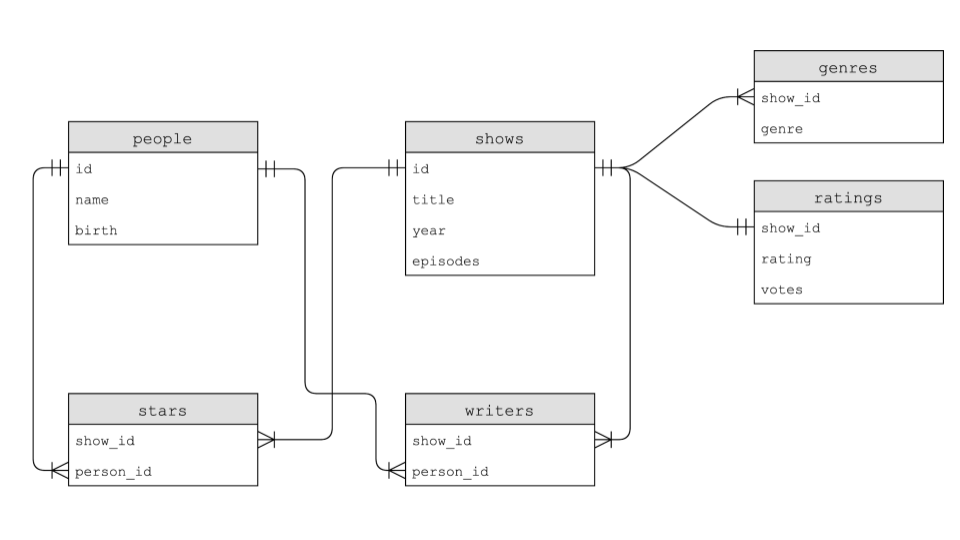
你可以下载 shows.db 后用 sqlite3 shows.db 看下这张表的结构。
sqlite> .tables
genres people ratings shows stars writers
sqlite> SELECT name FROM sqlite_master WHERE type = 'table' ORDER BY name;
+---------+
| name |
+---------+
| genres |
| people |
| ratings |
| shows |
| stars |
| writers |
+---------+我们可以看到有 genres,people,ratings,shows,stars,writers 六张表。
再看下每张表的详细信息。
.schema
CREATE TABLE genres (
show_id INTEGER NOT NULL,
genre TEXT NOT NULL,
FOREIGN KEY(show_id) REFERENCES shows(id)
);
CREATE TABLE people (
id INTEGER,
name TEXT NOT NULL,
birth NUMERIC,
PRIMARY KEY(id)
);
CREATE TABLE ratings (
show_id INTEGER NOT NULL UNIQUE,
rating REAL NOT NULL,
votes INTEGER NOT NULL,
FOREIGN KEY(show_id) REFERENCES shows(id)
);
CREATE TABLE shows (
id INTEGER,
title TEXT NOT NULL,
year NUMERIC,
episodes INTEGER,
PRIMARY KEY(id)
);
CREATE TABLE stars (
show_id INTEGER NOT NULL,
person_id INTEGER NOT NULL,
FOREIGN KEY(show_id) REFERENCES shows(id),
FOREIGN KEY(person_id) REFERENCES people(id)
);
CREATE TABLE writers (
show_id INTEGER NOT NULL,
person_id INTEGER NOT NULL,
FOREIGN KEY(show_id) REFERENCES shows(id),
FOREIGN KEY(person_id) REFERENCES people(id)
);让我们聚焦于数据库中名为shows和ratings的两个表之间的关系。这两张表之间的关系可通过以下方式说明:
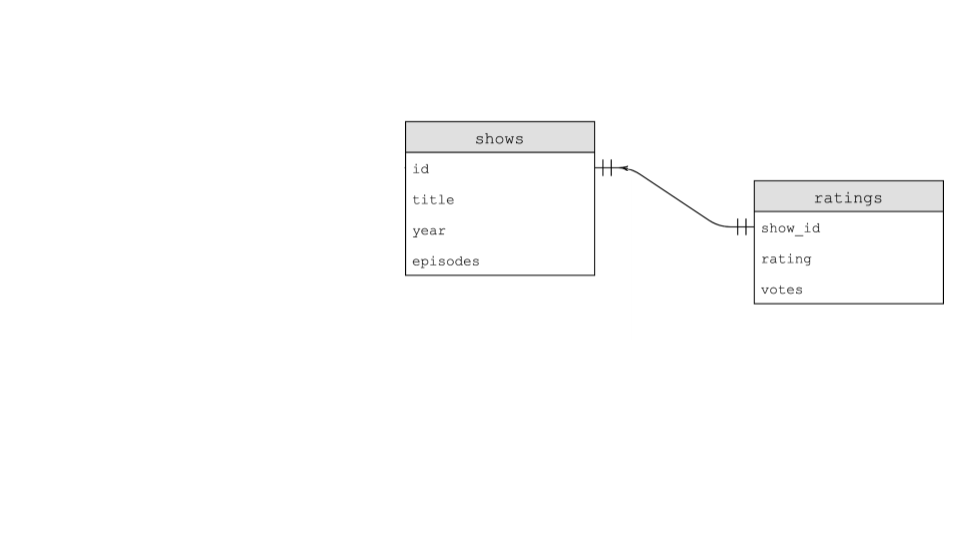
为说明这些表之间的关联关系,我们可以执行以下命令:SELECT * FROM ratings LIMIT 10;。通过分析输出结果,我们可执行SELECT * FROM shows LIMIT 10;。
sqlite> SELECT * FROM ratings LIMIT 10;
+---------+--------+-------+
| show_id | rating | votes |
+---------+--------+-------+
| 62614 | 6.7 | 392 |
| 63881 | 7.9 | 1224 |
| 63962 | 7.9 | 4518 |
| 65269 | 7.5 | 141 |
| 65270 | 7.5 | 33 |
| 65271 | 5.4 | 11 |
| 65272 | 6.8 | 3548 |
| 65273 | 6.8 | 219 |
| 65274 | 7.0 | 149 |
| 65276 | 6.6 | 80 |
+---------+--------+-------+
sqlite> SELECT * FROM shows LIMIT 10;
+-------+-----------------------------+------+----------+
| id | title | year | episodes |
+-------+-----------------------------+------+----------+
| 62614 | Zeg 'ns Aaa | 1981 | 227 |
| 63881 | Catweazle | 1970 | 26 |
| 63962 | UFO | 1970 | 26 |
| 65269 | Ace of Wands | 1970 | 46 |
| 65270 | The Adventures of Don Quick | 1970 | 6 |
| 65271 | Albert and Victoria | 1970 | 12 |
| 65272 | All My Children | 1970 | 9699 |
| 65273 | Archie's Funhouse | 1970 | 23 |
| 65274 | Arnie | 1970 | 48 |
| 65276 | Barefoot in the Park | 1970 | 12 |
+-------+-----------------------------+------+----------+通过分析shows与ratings 两张表,我们发现它们之间存在一对一的关系:每部节目对应一个评分。
要理解数据库,执行 .schema 命令后,不仅能看到每个表,还能看到这些表中各自的字段,上面我们已经执行并查看过了。也可以只查看某张表,比如执行 .schema shows 命令来了解 shows 中的字段。也可以执行 .schema ratings 命令来查看 ratings 中的字段。
所有表中都存在对节目ID的引用。在 shows 表中,该字段直接命名为 id 。这种在所有表中共享的字段称为键。主键用于标识表中唯一的记录。外键通过指向另一张表的主键来建立表间关系。在 ratings 表的结构中,可见show_id是一个外键,它引用了节目表中的id字段。
通过将数据存储在关系数据库中(如上所述),数据可以更高效地存储。
在sqlite中,我们有五种数据类型,包括:
BLOB -- binary large objects that are groups of ones and zeros
INTEGER -- an integer
NUMERIC -- for numbers that are formatted specially like dates
REAL -- like a float
TEXT -- for strings and the like此外,列可设置为添加特殊约束:
NOT NULL
UNIQUE我们可以进一步分析这些数据来理解这些关系。执行 SELECT * FROM ratings;。这里有大量评分数据!
这里就不执行了,上面我们通过 LIMIT 关键字限制显示 10 条 recoed。
我们可通过执行 SELECT show_id FROM ratings WHERE rating >= 6.0 LIMIT 10; 进一步筛选数据。
sqlite> SELECT show_id FROM ratings WHERE rating >= 6.0 LIMIT 10;
+---------+
| show_id |
+---------+
| 62614 |
| 63881 |
| 63962 |
| 65269 |
| 65270 |
| 65272 |
| 65273 |
| 65274 |
| 65276 |
| 65277 |
+---------+由查询结果可知,系统给出了 10部 评分大于 6.0 节目。但我们无法得知每个 show_id 对应的具体节目名称。
你可以通过执行 SELECT * FROM shows WHERE id = 62614; 来查询 id = 62614 的节目是什么。
sqlite> SELECT * FROM shows WHERE id = 62614;
+-------+-------------+------+----------+
| id | title | year | episodes |
+-------+-------------+------+----------+
| 62614 | Zeg 'ns Aaa | 1981 | 227 |
+-------+-------------+------+----------+我们可通过执行以下操作优化查询以提升效率:
SELECT title
FROM shows
WHERE id IN (
SELECT show_id
FROM ratings
WHERE rating >= 6.0
LIMIT 10
);查询结果
sqlite> SELECT title
...> FROM shows
...> WHERE id IN (
...> SELECT show_id
...> FROM ratings
...> WHERE rating >= 6.0
...> LIMIT 10
...> );
+-----------------------------+
| title |
+-----------------------------+
| Zeg 'ns Aaa |
| Catweazle |
| UFO |
| Ace of Wands |
| The Adventures of Don Quick |
| All My Children |
| Archie's Funhouse |
| Arnie |
| Barefoot in the Park |
| The Best of Everything |
+-----------------------------+请注意,此查询将两个查询嵌套在一起。外部查询使用内部查询。
JOINs
现在我们从 shows 和 ratings 中提取数据。注意 shows 和 ratings 都有一个共同的字段 id 。
如何临时合并这些表?可使用JOIN命令将表进行连接。
可以执行下面的指令
SELECT * FROM shows
JOIN ratings ON shows.id = ratings.show_id
WHERE rating >= 6.0
LIMIT 10;组合后得到一张更大的表。
sqlite> SELECT * FROM shows
...> JOIN ratings ON shows.id = ratings.show_id
...> WHERE rating >= 6.0
...> LIMIT 10;
+-------+-----------------------------+------+----------+---------+--------+-------+
| id | title | year | episodes | show_id | rating | votes |
+-------+-----------------------------+------+----------+---------+--------+-------+
| 62614 | Zeg 'ns Aaa | 1981 | 227 | 62614 | 6.7 | 392 |
| 63881 | Catweazle | 1970 | 26 | 63881 | 7.9 | 1224 |
| 63962 | UFO | 1970 | 26 | 63962 | 7.9 | 4518 |
| 65269 | Ace of Wands | 1970 | 46 | 65269 | 7.5 | 141 |
| 65270 | The Adventures of Don Quick | 1970 | 6 | 65270 | 7.5 | 33 |
| 65272 | All My Children | 1970 | 9699 | 65272 | 6.8 | 3548 |
| 65273 | Archie's Funhouse | 1970 | 23 | 65273 | 6.8 | 219 |
| 65274 | Arnie | 1970 | 48 | 65274 | 7.0 | 149 |
| 65276 | Barefoot in the Park | 1970 | 12 | 65276 | 6.6 | 80 |
| 65277 | The Best of Everything | 1970 | 115 | 65277 | 8.0 | 35 |
+-------+-----------------------------+------+----------+---------+--------+-------+-
先前查询已展示了这些键之间的一对一关系,现在让我们考察一些一对多关系。聚焦于
genres表,执行以下操作:SELECT * FROM genres
LIMIT 10;
genres表前10条结果
sqlite> SELECT * FROM genres
...> LIMIT 10;
+---------+-----------+
| show_id | genre |
+---------+-----------+
| 62614 | Comedy |
| 63881 | Adventure |
| 63881 | Comedy |
| 63881 | Family |
| 63962 | Action |
| 63962 | Sci-Fi |
| 65269 | Family |
| 65269 | Fantasy |
| 65270 | Comedy |
| 65270 | Sci-Fi |
+---------+-----------+我们对原始数据有了初步了解。你可能会发现某个节目有三个数值,这体现了一对多关系。
-
现在执行 .schema genres 了解更多
genres表的信息sqlite> .schema genres
CREATE TABLE genres (
show_id INTEGER NOT NULL,
genre TEXT NOT NULL,
FOREIGN KEY(show_id) REFERENCES shows(id)
); -
执行以下命令以了解数据库中各种喜剧的详细信息:
SELECT title FROM shows
WHERE id IN (
SELECT show_id FROM genres
WHERE genre = 'Comedy'
LIMIT 10
);
查询结果:
sqlite> SELECT title FROM shows
...> WHERE id IN (
...> SELECT show_id FROM genres
...> WHERE genre = 'Comedy'
...> LIMIT 10
...> );
+-----------------------------+
| title |
+-----------------------------+
| Zeg 'ns Aaa |
| Catweazle |
| The Adventures of Don Quick |
| Albert and Victoria |
| Archie's Funhouse |
| Arnie |
| Barefoot in the Park |
| Comedy Tonight |
| The Culture Vultures |
| Make Room for Granddaddy |
+-----------------------------+-
我们可以通过joining多个表来了解更多关于 Catweazle 的信息:
SELECT * FROM shows
JOIN genres
ON shows.id = genres.show_id
WHERE id = 63881;
查询结果
sqlite> SELECT * FROM shows
...> JOIN genres
...> ON shows.id = genres.show_id
...> WHERE id = 63881;
+-------+-----------+------+----------+---------+-----------+
| id | title | year | episodes | show_id | genre |
+-------+-----------+------+----------+---------+-----------+
| 63881 | Catweazle | 1970 | 26 | 63881 | Adventure |
| 63881 | Catweazle | 1970 | 26 | 63881 | Comedy |
| 63881 | Catweazle | 1970 | 26 | 63881 | Family |
+-------+-----------+------+----------+---------+-----------+请注意这会生成一个临时表。允许重复表存在。此外,请注意《 Catweazle》(一部作品)被分配了多种类型,包括冒险、喜剧和家庭。
与一对一和一对多关系相对应的,还有多对多关系。例如,许多演员可能出现在多部剧集中!
通过执行以下命令,我们可以进一步了解《Office》这部剧及其演员阵容:
SELECT name FROM people WHERE id IN
(SELECT person_id FROM stars WHERE show_id =
(SELECT id FROM shows WHERE title = 'The Office' AND year = 2005));该查询会得到一个出演 2005年的 The Office 的演员表
sqlite> SELECT name FROM people WHERE id IN
...> (SELECT person_id FROM stars WHERE show_id =
...> (SELECT id FROM shows WHERE title = 'The Office' AND year = 2005));
+--------------------+
| name |
+--------------------+
| Creed Bratton |
| Steve Carell |
| Jenna Fischer |
| Kate Flannery |
| Phyllis Smith |
| Rainn Wilson |
| John Krasinski |
| Angela Kinsey |
| Leslie David Baker |
| Brian Baumgartner |
+--------------------+执行下面的命令可以找到所有Steve Carell 参演的节目
SELECT title FROM shows WHERE id IN
(SELECT show_id FROM stars WHERE person_id =
(SELECT id FROM people WHERE name = 'Steve Carell'));
sqlite> SELECT title FROM shows WHERE id IN
...> (SELECT show_id FROM stars WHERE person_id =
...> (SELECT id FROM people WHERE name = 'Steve Carell'));
+------------------------------------+
| title |
+------------------------------------+
| The Dana Carvey Show |
| Over the Top |
| Watching Ellie |
| Come to Papa |
| The Office |
| Entertainers with Byron Allen |
| The Naked Trucker and T-Bones Show |
| ES.TV HD |
| Mark at the Movies |
| Inside Comedy |
| Rove LA |
| Metacafe Unfiltered |
| Fabrice Fabrice Interviews |
| Riot |
| Séries express |
| Hollywood Sessions |
| IMDb First Credit |
| First Impressions with Dana Carvey |
| Space Force |
| Some Good News |
| The Four Seasons |
| The Envelope: Oscar Roundtables |
+------------------------------------+上述查询也可以使用 JOIN 实现
SELECT title FROM shows
JOIN stars ON shows.id = stars.show_id
JOIN people ON stars.person_id = people.id
WHERE name = 'Steve Carell';结果与上面相同
sqlite> SELECT title FROM shows
...> JOIN stars ON shows.id = stars.show_id
...> JOIN people ON stars.person_id = people.id
...> WHERE name = 'Steve Carell';
+------------------------------------+
| title |
+------------------------------------+
| The Dana Carvey Show |
| The Dana Carvey Show |
| Over the Top |
| Watching Ellie |
| Come to Papa |
| The Office |
| Entertainers with Byron Allen |
| The Naked Trucker and T-Bones Show |
| Some Good News |
| Some Good News |
| Some Good News |
| ES.TV HD |
| Mark at the Movies |
| Inside Comedy |
| Rove LA |
| Metacafe Unfiltered |
| Fabrice Fabrice Interviews |
| The Four Seasons |
| The Envelope: Oscar Roundtables |
| Riot |
| Séries express |
| Hollywood Sessions |
| IMDb First Credit |
| First Impressions with Dana Carvey |
| Space Force |
+------------------------------------+还可以使用下面的查询语句实现,结果也是一样的。
SELECT title FROM shows, stars, people
WHERE shows.id = stars.show_id
AND people.id = stars.person_id
AND name = 'Steve Carell';通配符 % 运算符可用于查找所有姓名以 Steve C 开头的人员,使用以下语法:SELECT * FROM people WHERE name LIKE 'Steve C%';。
sqlite> SELECT * FROM people WHERE name LIKE 'Steve C%';
+----------+-------------------+-------+
| id | name | birth |
+----------+-------------------+-------+
| 34335 | Steve Cassling | NULL |
| 127472 | Steve Caballero | 1964 |
| 131409 | Steve Comisar | 1961 |
...
| 16955805 | Steve Cassingham | NULL |
+----------+-------------------+-------+Indexes(索引)
关系型数据库虽比 CSV 文件更快速、更强大,但通过索引可进一步优化查询性能。
为什么需要索引?
| 场景 | 无索引 | 有索引 |
|---|---|---|
| 查找方式 | 逐行扫描(全表扫描) | 直接定位(B-Tree 查找) |
| 时间复杂度 | O(n) | O(log n) |
| 适用数据量 | 小型数据 | 大型数据 |
测量查询速度
执行 sqlite3 中的 .timer on 可追踪查询速度。
为理解索引如何提升查询速度,请执行:
SELECT * FROM shows WHERE title = 'The Office';注意查询执行后显示的时间。
创建索引
CREATE INDEX title_index ON shows (title);这会告诉 sqlite3 创建一个索引,并执行一些与该列 title 相关的底层优化。
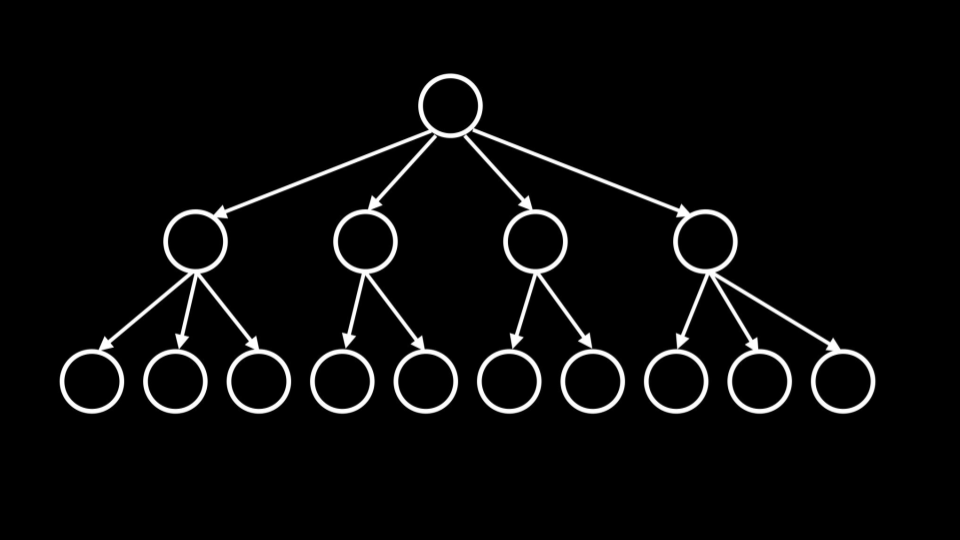
B-Tree 数据结构
索引使用名为 **B-Tree(B 树)**的数据结构,形态类似于二叉树,但不同之处在于:B 树的子节点数量可超过两个 。
此外,还可以使用下面的命令创建索引
CREATE INDEX name_index ON people (name);
CREATE INDEX person_index ON stars (person_id);再执行查询,会发现查询速度快了很多。
sqlite> CREATE INDEX name_index ON people (name);
NDEX person_index ON stars (person_id);sqlite> CREATE INDEX person_index ON stars (person_id);
sqlite> SELECT title FROM shows WHERE id IN
...> (SELECT show_id FROM stars WHERE person_id =
...> (SELECT id FROM people WHERE name = 'Steve Carell'));
+------------------------------------+
| title |
+------------------------------------+
| The Dana Carvey Show |
| Over the Top |
| Watching Ellie |
| Come to Papa |
| The Office |
| Entertainers with Byron Allen |
| The Naked Trucker and T-Bones Show |
| ES.TV HD |
| Mark at the Movies |
| Inside Comedy |
| Rove LA |
| Metacafe Unfiltered |
| Fabrice Fabrice Interviews |
| Riot |
| Séries express |
| Hollywood Sessions |
| IMDb First Credit |
| First Impressions with Dana Carvey |
| Space Force |
| Some Good News |
| The Four Seasons |
| The Envelope: Oscar Roundtables |
+------------------------------------+⚠️ 权衡 :对所有列进行索引会导致占用更多存储空间。因此,我们需要在查询效率 和存储空间 之间做权衡。通常只对经常查询的列创建索引。
Python 中使用 SQL
CS50 SQL 库
本课程可以通过 from cs50 import SQL 导入 SQL 功能。
与之前使用 CS50 库的方式类似,该库将协助处理在 Python 代码中使用 SQL 的复杂步骤。
📖 文档 :CS50 SQL 库官方文档
基本用法
运用新掌握的知识,我们可以同时利用 Python 和 SQL 进行开发。
按如下修改 favorites.py:
# Searches database for popularity of a problem
from cs50 import SQL
# Open database
db = SQL("sqlite:///favorites.db")
# Prompt user for favorite
favorite = input("Favorite: ")
# Search for title
rows = db.execute("SELECT COUNT(*) AS n FROM favorites WHERE problem = ?", favorite)
# Get first (and only) row
row = rows[0]
# Print popularity
print(row["n"])请注意,db = SQL("sqlite:///favorites.db") 为 Python 提供了数据库文件的位置。随后,以 rows 开头的代码行通过 db.execute 执行 SQL 命令。实际上,该命令将引号内的语法传递给 db.execute 函数。我们可通过此语法执行任意SQL命令。此外请注意,rows被返回为字典列表。本例中仅返回一条结果,即一行数据,以字典形式存入rows列表。
Race Conditions(竞态条件)
使用 SQL 有时会引发竞态条件问题。
问题场景
试想:多个用户同时访问同一数据库并执行命令。
用户 A: SELECT balance FROM accounts WHERE id = 1; -- 读取余额 100
用户 B: SELECT balance FROM accounts WHERE id = 1; -- 同时读取余额 100
用户 A: UPDATE accounts SET balance = 90 WHERE id = 1; -- 扣款 10
用户 B: UPDATE accounts SET balance = 80 WHERE id = 1; -- 扣款 20(预期应该是 70!)这可能导致代码因他人操作而中断,进而造成数据丢失 或数据不一致。
解决方案:事务
内置的 SQL 特性可帮助规避竞态条件:
| 命令 | 用途 |
|---|---|
BEGIN TRANSACTION |
开始一个事务 |
COMMIT |
提交事务,使更改永久生效 |
ROLLBACK |
回滚事务,撤销所有更改 |
SQL 注入攻击
现在,继续思考上面的代码,你可能在想那些问号(?)的作用。在 SQL 的实际应用中,可能会遇到一种称为注入攻击的问题。注入攻击是指恶意行为者可能输入恶意 SQL 代码的情况。
例如,考虑如下登录界面:
如果我们的代码中缺乏适当的保护措施,恶意行为者就能运行恶意代码。请考虑以下情况:
rows = db.execute("SELECT COUNT(*) FROM users WHERE username = ? AND password = ?", username, password)请注意,由于存在问号(?),在查询盲目接受用户名和密码之前,可以对其进行验证。
🔴 安全警告 :永远不要盲目信任用户的输入!
防护措施
| 方法 | 说明 |
|---|---|
| 参数化查询 | 使用 ? 占位符,让库处理转义 |
| 输入验证 | 检查输入格式是否合法 |
| 使用 ORM | 通过对象关系映射避免直接写 SQL |
通过使用 CS50 库,该库将对输入进行**清理(Sanitize)**并移除任何潜在的恶意字符。
# ❌ 危险:字符串拼接(容易被注入)
db.execute(f"SELECT * FROM users WHERE username = '{username}'")
# ✅ 安全:参数化查询
db.execute("SELECT * FROM users WHERE username = ?", username)总结
在本节课中,你学习了更多与 Python 相关的语法知识。此外,你掌握了如何将这些知识与平面文件和关系型数据库形式的数据相结合。最后,你了解了 SQL。
本周知识点清单
| 类别 | 知识点 | 掌握程度 |
|---|---|---|
| 数据存储 | 扁平文件数据库(CSV) | ☐ |
| 数据存储 | 关系型数据库 | ☐ |
| SQL 命令 | SELECT(查询) | ☐ |
| SQL 命令 | INSERT(插入) | ☐ |
| SQL 命令 | UPDATE(更新) | ☐ |
| SQL 命令 | DELETE(删除) | ☐ |
| 表设计 | 主键(PRIMARY KEY) | ☐ |
| 表设计 | 外键(FOREIGN KEY) | ☐ |
| 查询技巧 | JOIN(连接操作) | ☐ |
| 性能优化 | INDEX(索引) | ☐ |
| Python 集成 | cs50.SQL 库 | ☐ |
| 安全性 | 竞态条件(Race Conditions) | ☐ |
| 安全性 | SQL 注入攻击 | ☐ |
SQL 命令速查表
-- 查询数据
SELECT column FROM table WHERE condition;
SELECT * FROM table ORDER BY column DESC LIMIT 10;
SELECT column, COUNT(*) FROM table GROUP BY column;
-- 插入数据
INSERT INTO table (column1, column2) VALUES (value1, value2);
-- 更新数据
UPDATE table SET column = value WHERE condition;
-- 删除数据
DELETE FROM table WHERE condition;
-- 创建索引
CREATE INDEX index_name ON table (column);
-- 连接表
SELECT * FROM table1 JOIN table2 ON table1.id = table2.foreign_id;常见函数
| 函数 | 用途 | 示例 |
|---|---|---|
COUNT(*) |
计数 | SELECT COUNT(*) FROM users; |
AVG(column) |
平均值 | SELECT AVG(rating) FROM ratings; |
MAX(column) |
最大值 | SELECT MAX(votes) FROM ratings; |
MIN(column) |
最小值 | SELECT MIN(year) FROM shows; |
SUM(column) |
求和 | SELECT SUM(episodes) FROM shows; |
DISTINCT |
去重 | SELECT DISTINCT language FROM favorites; |
LIKE |
模糊匹配 | WHERE name LIKE 'Steve%' |
关键概念对比
| 概念 | 扁平文件数据库 | 关系型数据库 |
|---|---|---|
| 存储方式 | 单一 CSV 文件 | 多个相关联的表 |
| 查询能力 | 需要编程遍历 | SQL 语句直接查询 |
| 数据冗余 | 高(重复存储) | 低(规范化设计) |
| 扩展性 | 差 | 好 |
| 适用场景 | 小型简单数据 | 大型复杂数据 |
延伸学习
参考资料:
下周我们将进入 HTML, CSS, JavaScript 的世界,开始 Web 开发之旅!🚀