目录
[1. 核心机制更正与说明](#1. 核心机制更正与说明)
[2. 三种方式详细对比](#2. 三种方式详细对比)
[2.1 方式一:Gateway 本地直传模式 (Client-Side Staging)](#2.1 方式一:Gateway 本地直传模式 (Client-Side Staging))
[2.1.1 核心命令参数](#2.1.1 核心命令参数)
[2.1.2 执行原理与流程图](#2.1.2 执行原理与流程图)
[2.2 方式二:HDFS 静态引用模式 (Server-Side Reference)](#2.2 方式二:HDFS 静态引用模式 (Server-Side Reference))
[2.2.1 核心命令参数](#2.2.1 核心命令参数)
[2.2.2 执行原理与流程图](#2.2.2 执行原理与流程图)
[2.3 方式三:流式注入极简模式 (Script-Only)](#2.3 方式三:流式注入极简模式 (Script-Only))
[2.3.1 核心命令参数](#2.3.1 核心命令参数)
[2.3.2 执行原理](#2.3.2 执行原理)
[4. 推荐优先级与最佳实践路线图](#4. 推荐优先级与最佳实践路线图)
[4.1 开发与调试(推荐使用 方式一)](#4.1 开发与调试(推荐使用 方式一))
[4.2 测试与准生产(过渡到 方式二)](#4.2 测试与准生产(过渡到 方式二))
[4.3 生产环境(必须使用 方式二)](#4.3 生产环境(必须使用 方式二))
[5. 总结](#5. 总结)
1. 核心机制更正与说明
在对比之前,先明确 submit_job240.py(方式一)和 submit_job.py(方式二)在资源分发上的本质区别:
-
Spark 的 Staging 机制 :当
spark-submit的参数(如--archives,--jars,--files)指向 本地文件系统(file://) 时,Spark 客户端会在任务启动前,先将这些文件 Upload 到 HDFS 的.sparkStaging/application_id/目录下。 -
方式一:利用了 Spark 的自动 Upload 机制。
-
方式二:跳过了 Upload 步骤,直接引用 HDFS 上已存在的文件。
2. 三种方式详细对比
2.1 方式一:Gateway 本地直传模式 (Client-Side Staging)
核心特征:依赖提交机(Gateway)本地文件,利用 Spark Client 自动分发。
2.1.1 核心命令参数
在 Python 脚本中构建的 spark-submit 核心参数如下:
python
# 关键点:路径指向 Gateway 本地文件系统 (无 hdfs:// 前缀)
spark-submit \
--master yarn \
--deploy-mode client \
# 1. 自动上传:Spark Client 会自动将此本地包上传到 HDFS 临时目录
--archives "/root/pyspark_test/pyspark_env.tar.gz#python37_dir" \
# 2. 陷阱:extraClassPath 仅仅是追加 classpath 字符串,不会触发上传
# 必须配合 --jars 或确保所有节点本地都有该文件
--conf "spark.driver.extraClassPath=/root/jul-to-slf4j-1.7.25.jar" \
--conf "spark.executor.extraClassPath=/root/jul-to-slf4j-1.7.25.jar" \
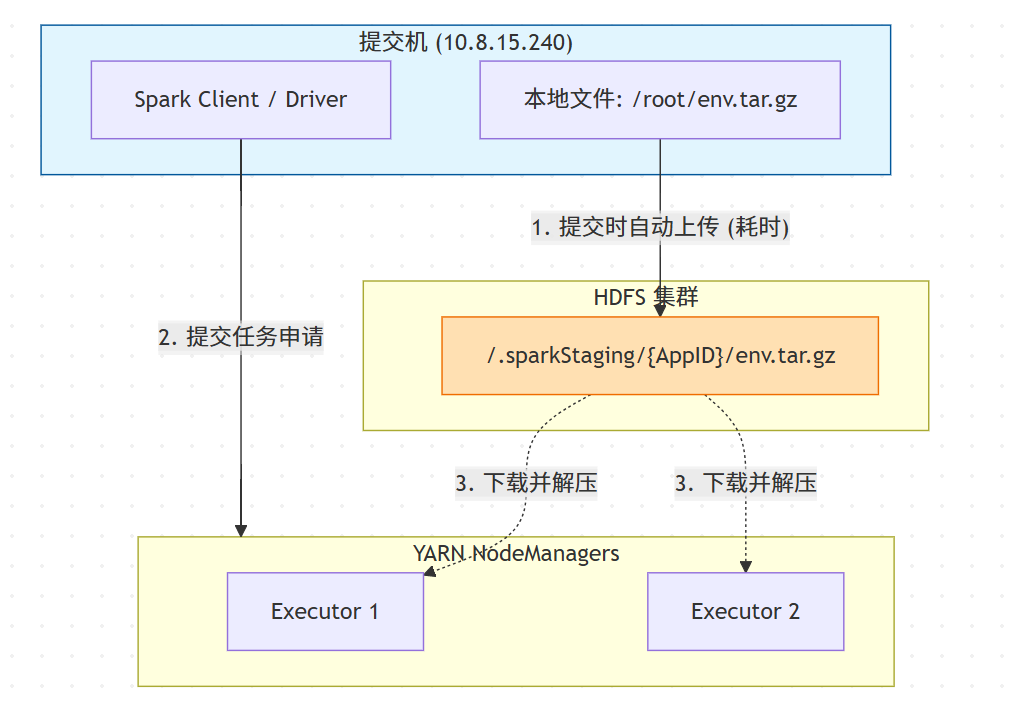
...2.1.2 执行原理与流程图
此模式利用了 Spark 的 Distributed Cache (Staging) 机制。
-
原理 :当检测到路径为本地路径(
file://或无前缀)时,Spark 客户端会在任务启动前,先将文件 Upload 到 HDFS 的.sparkStaging目录。 -
适用场景 :开发调试阶段。环境包/Jar包变动频繁,无需手动维护 HDFS 文件,脚本改完即跑,最为灵活。
2.2 方式二:HDFS 静态引用模式 (Server-Side Reference)
核心特征:依赖 HDFS 预存文件,跳过上传步骤,生产环境标准。
2.2.1 核心命令参数
python
# 关键点:路径指向 HDFS (hdfs:// 前缀)
spark-submit \
--master yarn \
--deploy-mode client \
# 1. 静态引用:直接告诉 YARN 去哪里下载,Client 不执行上传动作
--archives "hdfs:///user/bigdata/env/pyspark_env.tar.gz#python37_dir" \
...2.2.2 执行原理与流程图
此模式跳过了 Client 到 HDFS 的上传阶段,实现了 一次上传,多次分发。
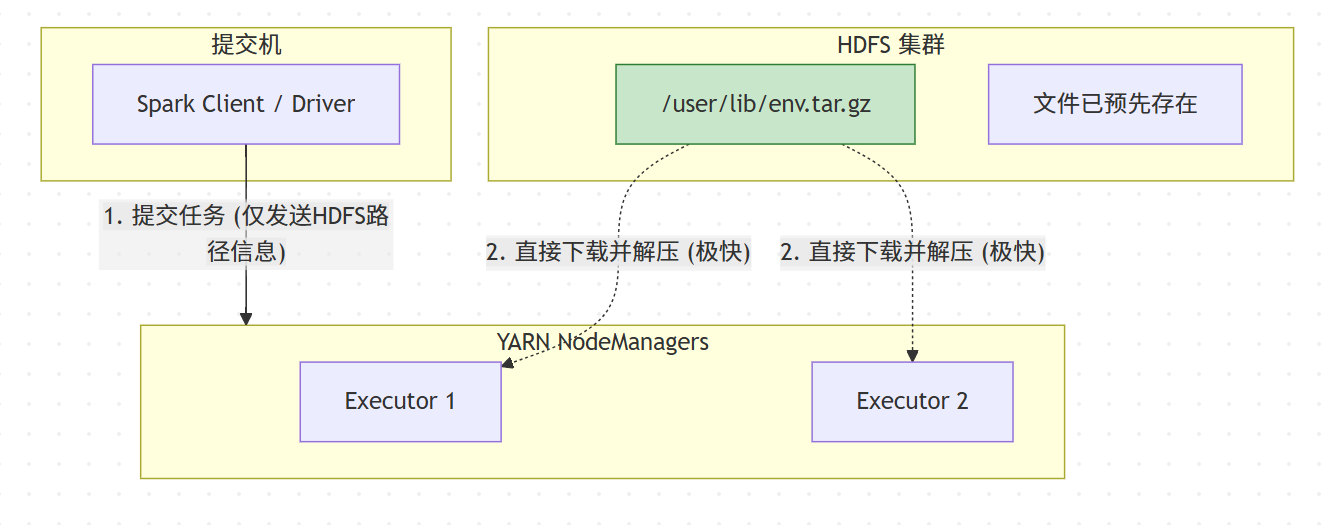
详细流程图如下:

-
原理:Spark Client 仅将 HDFS 路径传递给 ApplicationMaster,Executor 启动时直接从 HDFS 公共目录拉取资源。
-
适用场景 :生产调度阶段 。避免了每次调度运行都重复上传 500MB+ 的环境包,减轻 HDFS NameNode 压力,且具有幂等性(任何机器提交效果一致)。
2.3 方式三:流式注入极简模式 (Script-Only)
核心特征:无外部依赖,代码动态生成,仅依赖集群系统环境。
2.3.1 核心命令参数
python
# 关键点:没有任何 --archives 或环境依赖参数
spark-submit \
--master yarn \
--deploy-mode client \
# 仅依赖集群节点上 /usr/bin/python2.7 (默认)
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=/usr/bin/python \
/tmp/temp_script_generated_by_ssh.py2.3.2 执行原理
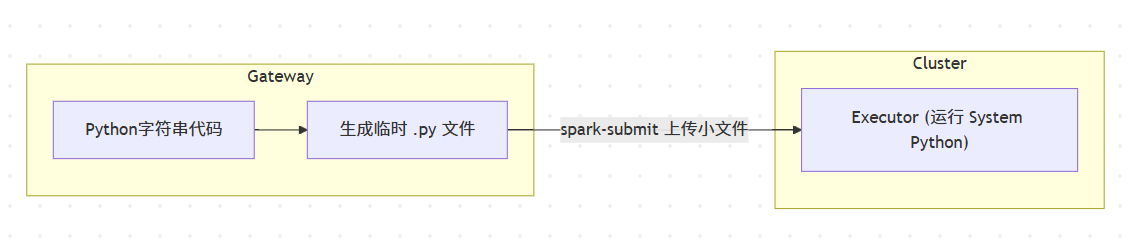
-
原理:不分发 Python 虚拟环境,直接使用 YARN NodeManager 所在机器的操作系统自带 Python。
-
适用场景 :冒烟测试 / 连通性检查。验证集群是否存活,不涉及复杂业务库(Pandas/Numpy 等)。
| 特性 | 方式一:Gateway 本地直传模式 (submit_job240.py) |
方式二:HDFS 静态引用模式 (submit_job.py) |
方式三:流式注入模式 (test_spark2.py) |
|---|---|---|---|
| 资源位置 | Linux 提交机(Gateway)本地磁盘 | HDFS 分布式文件系统 | 代码字符串内嵌 |
| 分发机制 | 自动上传:Spark Client 启动时将本地文件传至 HDFS Staging 目录,再由 YARN 分发。 | 直接下载:Spark Client 仅传递 HDFS 路径,Executor 直接从 HDFS 下载。 | 即时生成:脚本在提交机临时生成,仅分发主程序文件。 |
| 灵活性 | ⭐⭐⭐ (高) 修改依赖(如 Jar 或 Env)后,直接提交即可,无需手动执行 hdfs dfs -put。 |
⭐⭐ (中) 依赖若有更新,必须先手动上传覆盖 HDFS 文件,再提交任务。 | ⭐ (低) 环境依赖由于受限于集群预装,无法灵活变更。 |
| 提交耗时 | 较慢 每次提交都需要等待文件上传(尤其是几百 MB 的 Env 包)。 | 极快 无上传过程,毫秒级响应提交请求。 | 快 文件极小。 |
| 适用场景 | 开发/调试/频变依赖 适合依赖包频繁迭代的阶段。 | 生产/定版/大文件 适合依赖包稳定、版本固定的生产调度。 | 冒烟测试/连通性检查 验证集群基础状态。 |
| 潜在风险 | 提交机(Gateway)若网络上行带宽不足,会阻塞任务启动。 | 若 HDFS 文件被误删或覆盖,会影响所有引用该文件的任务。 | 功能受限,难以维护复杂逻辑。 |
4. 推荐优先级与最佳实践路线图
根据"灵活性"与"稳定性"的权衡,推荐的优先级如下:
4.1 开发与调试(推荐使用 方式一)
场景:业务逻辑在变,依赖包也在变(比如在测试不同的 Python 库版本)。
-
做法:
-
在提交机(240)上维护一套 Python 环境和 Jar 包。
-
使用指向本地路径的脚本提交。
-
理由 :避免了每次修改环境都要手动
hdfs dfs -put的繁琐操作,极大提高了迭代效率。
-
4.2 测试与准生产(过渡到 方式二)
场景:环境依赖已经确定,不再频繁变更,开始进行每日定时调度测试。
-
做法:
-
将确认好的
pyspark_env.tar.gz和.jar上传到 HDFS 的公共库目录(如/user/lib/)。 -
修改提交脚本,指向 HDFS 路径。
-
理由:避免每次调度都重复上传 500MB+ 的环境包,减轻 HDFS NameNode 和网络带宽的压力,缩短任务启动时间。
-
4.3 生产环境(必须使用 方式二)
场景:正式上线,SLA 要求高。
-
做法:
-
严格禁止依赖本地文件(防止提交机故障导致任务无法由其他机器接管)。
-
使用 HDFS 路径,并做好权限控制(Read-Only)。
-
理由 :幂等性 与高可用。无论从哪台机器提交任务,只要指向同一个 HDFS 路径,任务运行结果都是一致的。
-
5. 总结
-
submit_job240.py (方式一) :最灵活 。本质是 "Client-Side Staging" 。它利用 Spark 帮你把本地文件搬运到 HDFS 临时目录。适合开发迭代,但要注意
extraClassPath不会自动搬运 Jar 的陷阱。 -
submit_job.py (方式二) :最规范 。本质是 "Server-Side Reference"。它假设资源已就位,效率最高,适合生产。
-
test_spark2.py (方式三) :最快验证。适合非业务的连通性测试。
结论 :在你的当前场景(可能是在调试环境或代码),方式一(240脚本)确实是最好用的,只要修正 Jar 包的分发参数,它既能保证环境随改随用,又能利用 YARN 进行分发。