TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Authors: Yabo Chen, Yuanzhi Liang, Jiepeng Wang, Tingxi Chen, Junfei Cheng, Zixiao Gu, Yuyang Huang, Zicheng Jiang, Wei Li, Tian Li, Weichen Li, Zuoxin Li, Guangce Liu, Jialun Liu, Junqi Liu, Haoyuan Wang, Qizhen Weng, Xuan'er Wu, Xunzhi Xiang, Xiaoyan Yang, Xin Zhang, Shiwen Zhang, Junyu Zhou, Chengcheng Zhou, Haibin Huang, Chi Zhang, Xuelong Li
Deep-Dive Summary:
TeleWorld:迈向动态多模态合成的4D世界模型
世界模型旨在赋予AI系统连贯且时间一致地表示、生成和交互动态环境的能力。尽管最近的视频生成模型已展示出令人印象深刻的视觉质量,但它们在实时交互、长程一致性和动态场景的持久记忆方面仍存在局限性,阻碍了其向实用世界模型的发展。本文介绍了TeleWorld,一个实时多模态4D世界建模框架,它将视频生成、动态场景重建和长期世界记忆统一在一个闭环系统中。TeleWorld引入了一种新颖的"生成-重建-引导"范式,其中生成的视频流被持续重建为动态4D时空表示,该表示反过来指导后续生成,以保持空间、时间和物理一致性。为支持低延迟的长程生成,我们采用了一种基于自回归扩散的视频模型,并辅以宏观-微观规划(MMPL)------一种分层规划方法,可将误差累积从帧级别降低到片段级别------以及高效的分布匹配蒸馏(DMD),从而在实际计算预算下实现实时合成。我们的方法在统一的4D框架内实现了动态对象建模和静态场景表示的无缝集成,推动世界模型向实用、交互式和计算可访问的系统发展。广泛的实验表明,TeleWorld在静态和动态世界理解、长期一致性以及实时生成效率方面均表现出色,使其成为迈向交互式、记忆增强的多模态生成和具身智能世界模型的重要一步。
通讯作者:Xuelong Li(xuelong.li@ieee.org)
1 引言
人工智能系统对物理世界的理解、模拟和交互能力,推动了世界模型研究的显著进展。世界模型的显式重建和实时生成是互补且相互强化的能力。核心目标是赋予AI系统类似人类的感知和交互能力,使其能够实时观察、表示、预测、生成并有意义地参与动态环境。
世界模型的定义因研究社区而异,它涵盖了视频生成、3D重建、具身AI和自动驾驶等多个相互关联的研究方向。广义上,任何能够自然地表示世界并与之交互的模型都可视为世界模型。其中,视频生成因其高质量输出、强大的下游多任务能力以及对用户更强的可访问性和交互性,已成为世界模型领域更受欢迎的研究方向。
然而,视频生成模型本身存在几个基本缺陷,阻碍了它们发展成为更实用的世界模型:
首先,受视频扩散模型多步去噪流水线的结构限制,视频生成难以满足世界模型的实时生成和交互要求。
其次,长时视频生成在长时间跨度内仍面临时间一致性的重大挑战,世界探索和交互通常会遭受误差累积和质量下降的问题。
第三,世界模型需要保留对生成世界的记忆,这种记忆本质上是四维的------涵盖空间的三维和时间动态维度,如同人类对世界的感知。现有世界模型和视频生成方法通常仅从过去的视频序列或三维表示中捕获记忆,而实现四维记忆仍然是视频生成通向世界模型的重大难题。
最后,高质量视频生成模型通常计算成本高昂,难以以快速、高效和可持续的方式进行实时训练和部署。遵循视频生成途径的世界模型对硬件的需求对于许多研究人员来说仍然过高。
我们总结主要问题如下:
(1)动态4D场景建模:当前主要具备3D建模能力的世界模型,难以有效地建模和记忆具有完整时空连贯性的动态环境。
(2)确保长期一致性:在长时间生成过程中保持高保真度和时间一致性仍然困难,常导致颜色偏移和质量下降等问题。
(3)平衡实时效率与质量:实现实时生成和高效训练是主要挑战,需要兼顾高模型质量和可控的计算成本。
本文提出了TeleWorld,一个实用的实时4D世界模型,通过整合生成、重建和引导的统一框架解决了这些基本挑战。首先,我们提出了一种"生成-重建-引导"闭环范式,利用4D时空场在视频生成过程中记录动态场景。这个重建过程与生成同步运行,随着新内容的合成持续更新世界表示。然后,该4D场的渲染结果被用作指导,以引导后续生成,确保空间一致性、时间连贯性和物理合理性。这种基于重建的方法通过对生成世界的持久、连贯理解实现了长期动态记忆。在生成阶段,我们采用了一个配备规划能力的自回归扩散视频生成模型。借鉴基于规划的生成方法的最新进展,我们的宏观-微观规划(MMPL)框架分层运行:微观规划在短视频片段内预测关键锚帧以建立局部时间一致性,而宏观规划则自回归地连接这些片段,以实现长程的全局一致性。这种方法将误差累积从帧级别降低到片段级别,实现了长时间稳定、高质量的生成。我们的视频生成架构实现了更快的视频合成,同时允许在规划过程中更好地整合来自4D场景的信息。
为了进一步加速视频合成,我们在TeleWorld的基础上采用了分布匹配蒸馏(DMD)。DMD对于实时视频生成至关重要,但将其应用于具有超过100亿参数的自回归模型非常困难,因为它同时引入了大型KV缓存,并需要处理生成器、教师模型和评论家三个超过100亿参数的模型。即使使用完全分片数据并行(FSDP),这种组合内存占用也超过了64块NVIDIA H100 GPU的容量。为了解决这一挑战,我们提出了一种用于大规模分布匹配蒸馏的新颖训练系统。具体来说,我们将生成器、教师模型和评论家分配到不相交的GPU集合中,并使用Ray编排它们的执行。此外,我们采用上下文并行(context parallelism)将生成器的KV缓存分片到各个设备上,从而大幅减少了每GPU的内存消耗。此外,我们精心设计了流水线执行调度,以最小化GPU空闲时间(即流水线气泡)并提高整体训练效率。通过这些优化技术,我们成功地使用仅32块H100 GPU训练了Teleworld-18B的DMD。这些系统级优化共同实现了在实际计算预算下,以适度的训练开销进行实时视频生成。
通过这些创新,TeleWorld在连贯的4D框架内实现了动态对象建模和静态场景表示的无缝集成,推动世界模型向实用、交互式和计算可访问的系统发展,适用于多模态生成和具身智能应用。
我们方法的贡献总结如下:
- 我们提出了一个实时的"生成-重建-引导"闭环框架,以实时速度将世界模型的长期记忆重建为动态点云,同时保持快速的世界更新和时间一致性。
- 我们引入了一个动态四维世界模型,它不仅提供三维空间中的记忆和生成能力,还能够记忆和生成场景中的移动对象,实现真正的时空连贯性。
- 我们提出了一个新颖的训练系统,解开了大规模自回归扩散模型的蒸馏训练,允许在可访问的硬件配置上高效训练,同时在不影响模型质量的情况下实现实时生成能力。
- TeleWorld代表了一种全面的世界建模方法,在一个统一的系统中连接了视频生成、3D重建和持久记忆,为其作为交互式AI系统和具身智能应用的实用基础奠定了基础。
2 相关工作
2.1 世界模型
世界模型的核心是可导航和交互的环境。随着生成模型的兴起,世界模型逐渐分为两大类:基于3D的世界模型和基于视频的世界模型。前者先构建三维世界再渲染给用户,后者通过视频生成来构建世界。
基于3D的世界模型:例如Wonderworld能够从一张2D图像生成交互式3D环境,强调空间一致性、几何解释和低延迟反馈。Matrix-3D利用全景3D重建创建可探索的3D世界。HunyuanWorld 1.0通过语义结构化的3D网格模型提供沉浸式 360 ∘ 360^{\circ} 360∘ 环境。商业产品Marble可从图像、视频或文本提示创建高保真、持久的3D世界。
基于视频的世界模型:例如Cosmos在机器人和自动系统仿真中表现出色。Genie 3引入了实时交互功能,允许用户生成和导航可控的3D世界。Hunyuan-Voyager通过RGB-D视频输出3D点云,Hunyuan-GameCraft2专为游戏视频设计,而Adobe的RELIC则利用紧凑型KV缓存实现长期记忆,它们都优先考虑显式3D一致性和空间重建。基于视频的方法在动态、以用户为中心的应用程序中具有优势:它在运动和时间连贯性方面提供更高的感知质量,支持更直观和响应迅速的交互,并实现快速的"冷启动"场景扩展。
然而,当前的基于视频的世界模型主要局限于处理静态3D环境,并且难以有效建模这些世界中的动态对象。
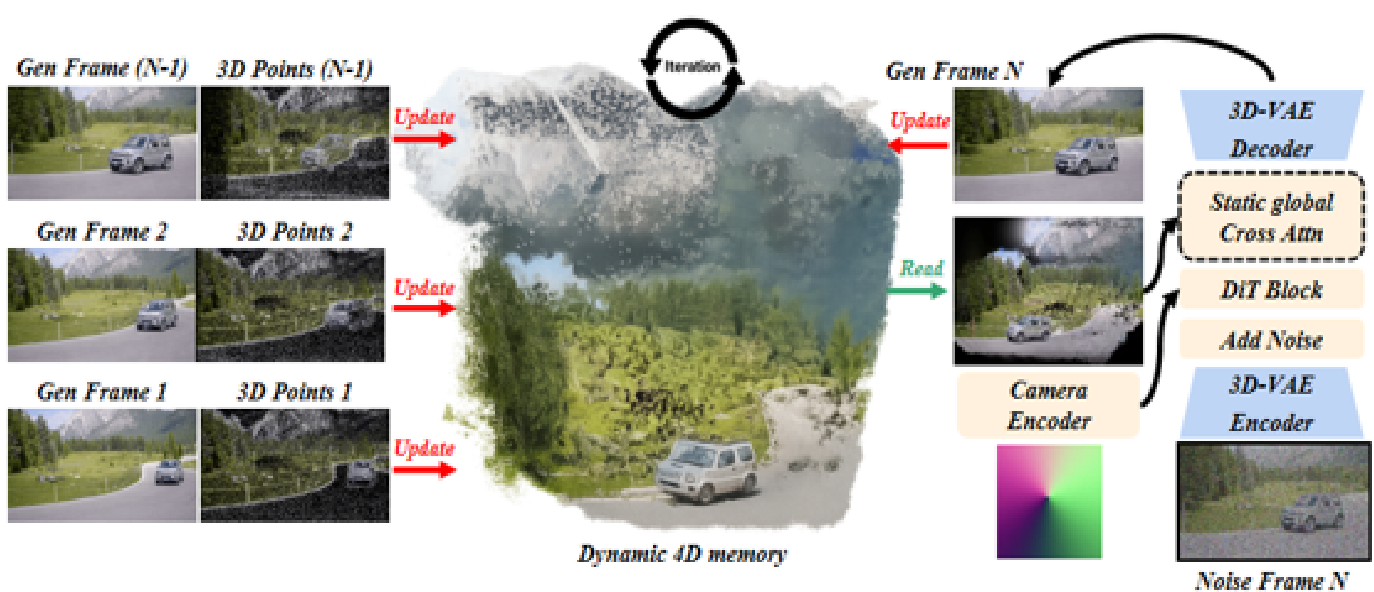
2.2 实时视频生成
长视频生成主要由自回归扩散模型推动,如Causvid和Self-Forcing通过条件化生成来提高训练稳定性和时间连贯性。然而,这些方法在长程生成中易受误差传播影响,且难以维持长期时间一致性,常导致模型"遗忘"早期场景信息。
同时,实时视频生成旨在提供低延迟、交互式合成。但将其扩展到高质量、高分辨率输出,尤其是对于100亿参数以上的模型,存在巨大困难。大型模型的实时蒸馏尤其具有挑战性,需要压缩时空知识而不牺牲保真度,并应对部署时的计算和内存限制。尽管Millon (2025) 通过动态KV缓存管理解决了140亿参数模型的问题,但根本问题仍未解决。
这些挑战(误差累积、长期记忆衰减、大型模型实时蒸馏困难)促成了TeleWorld的设计。TeleWorld不依赖隐式神经表示或循环潜在状态,而是引入一个显式4D时空场,持续记录和重建演变中的世界。这种显式表示随时间保留了几何和外观信息,有效缓解了遗忘和不一致等常见故障模式,同时实现了高效、高保真长视频生成和实时推理。此外,通过使用上下文并行来跨设备分片生成器的KV缓存,TeleWorld-18B只需32块H100 GPU即可进行长视频蒸馏训练。
3 方法
3.1 "生成-重建-引导"闭环
我们引入了一个动态的"生成-重建-引导"闭环框架,用于统一的4D时空建模。该框架构建了一个实时、原生的4D世界表示,随着每个新生成的视频片段持续更新,确保与不断演进的视觉内容完美同步。
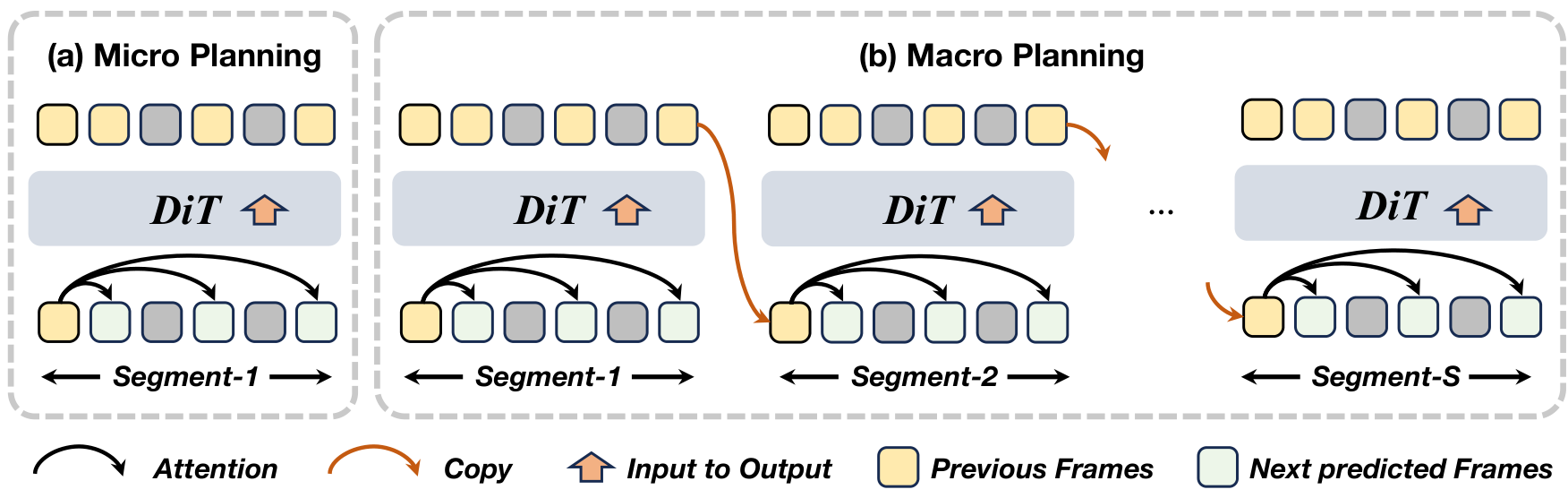
图2 我们的宏观-微观规划框架分为两个级别:(1) 微观规划,在每个局部片段内生成一系列帧以限制误差传播;(2) 宏观规划,通过自回归链连接片段------每一步的输出帧指导下一段的预测,确保长程时间一致性。如图所示,绿色标记的三个预测帧对应于初始预规划帧 P M s = { x s t s , x s t b , x s t c } \mathcal{P}{\mathcal{M}{s}} = \{x_{s}^{t_{s}}, x_{s}^{t_{b}}, x_{s}^{t_{c}}\} PMs={xsts,xstb,xstc},它们作为关键帧,用于在整个视频序列中保持长期记忆和稳定性。
其核心创新在于动态对象建模和静态场景建模之间的无缝对齐,使得它们能在连贯的空间结构中统一集成。在此循环中,"重建"是指从生成帧中恢复一致4D场景表示的过程,而"引导"则表示利用重建的4D场景和用户的键盘命令来指导下一轮视频生成。生成和重建步骤实时进行,指导和生成之间只有极小的延迟。这个循环过程持续更新所构建动态场景的4D时空记忆,允许通过键盘控制进行交互式有效的运动和交互。
3.2 长期记忆自回归视频生成
3.2.1 微观与宏观规划
受MMPL分析启发,我们观察到自回归模型误差累积与传播步数成正比。为利用两种范式的互补优势,TeleWorld引入了宏观-微观规划(MMPL),包含两个关键组件:微观规划和宏观规划。
微观规划(Micro Planning) M s \mathcal{M}{s} Ms 通过从初始帧 x s 1 x{s}^{1} xs1 预测一组稀疏的关键帧 P M s = { x s t s , x s t b , x s t c } \mathcal{P}{\mathcal{M}{s}} = \{x_{s}^{t_{s}}, x_{s}^{t_{b}}, x_{s}^{t_{c}}\} PMs={xsts,xstb,xstc} 来构建第 s s s 个片段的短期叙事。这些预规划帧作为后续合成的稳定锚点,时间戳设为 t a = 2 t_{a} = 2 ta=2(早期邻居)、 t b = N / 2 t_{b} = N / 2 tb=N/2(中点)和 t c = N t_{c} = N tc=N(片段结束)。过程公式如下:
p ( P M s ∣ x s 1 ) = p ( x s t s , x s t b , x s t c ∣ x s 1 ) . ( 1 ) p(\mathcal{P}{\mathcal{M}{s}} \mid x_{s}^{1}) = p(x_{s}^{t_{s}}, x_{s}^{t_{b}}, x_{s}^{t_{c}} \mid x_{s}^{1}). \quad (1) p(PMs∣xs1)=p(xsts,xstb,xstc∣xs1).(1)
所有帧仅以 x s 1 x_{s}^{1} xs1 为条件进行联合优化,相互约束其残余误差并消除累积漂移。这种设计确保了片段内部的连贯性,并为后续内容填充提供了抗漂移基础。
宏观规划(Macro Planning)尽管微观规划提供了片段级的时间线索,但在捕获世界场景整个视频的全局依赖性方面仍有限制。为实现长程连贯性,我们将其扩展为宏观规划,记作 M + \mathcal{M}^{+} M+。它通过顺序地将重叠的微观规划链接起来,构建全局时间线:一个片段的末端预规划帧作为下一个片段的初始化,沿着视频时间线形成片段级的自回归链。
形式上,给定一个长度为 T T T 并划分为 S S S 个片段的完整视频,令 x s 1 x_{s}^{1} xs1 为第 s s s 个片段的初始帧。宏观规划生成的规划帧集合表示为 P M + \mathcal{P}_{\mathcal{M}^{+}} PM+。该过程定义为:
p ( P M + ∣ x 1 1 ) = ∏ s = 1 S p ( P M s ∣ x s 1 ) , x s + 1 1 ≔ x s t c , P M + ≔ ⋃ s = 1 S P M s . ( 2 ) p(\mathcal{P}{\mathcal{M}^{+}}\mid x{1}^{1}) = \prod_{s = 1}^{S}p(\mathcal{P}{\mathcal{M}{s}}\mid x_{s}^{1}),\quad x_{s + 1}^{1}\coloneqq x_{s}^{t_{c}},\quad \mathcal{P}{\mathcal{M}^{+}}\coloneqq \bigcup{s = 1}^{S}\mathcal{P}{\mathcal{M}{s}}. \quad (2) p(PM+∣x11)=s=1∏Sp(PMs∣xs1),xs+11:=xstc,PM+:=s=1⋃SPMs.(2)
其中, M s \mathcal{M}_{s} Ms 是片段 s s s 的微观规划。通过分层链接片段,宏观规划将逐帧自回归依赖转换为稀疏的片段级规划步骤序列。这确保了全局叙事流的一致性,减轻了时间漂移,并将误差累积从 T T T 帧的尺度减少到仅 S S S 个片段的尺度,其中 S ≪ T S \ll T S≪T。
这种分层链接使世界模型能够保留跨片段的长期记忆。随后,我们通过对跨片段锚帧进行在线4D重建来锚定这些记忆,将所有关键帧嵌入连贯的时空场中,进一步明确和稳定段间和段内记忆,确保其精确性和一致性。
然而,当自回归地链接微观规划时,直接使用一个片段的尾部潜在令牌作为下一个片段的前缀,常因初始和时间压缩潜在帧之间的分布不匹配而引入边界闪烁和颜色偏移。
为稳定片段间的过渡,我们采用了抗漂移的重编码和解码策略。具体来说,我们从当前片段连接的初始和末端规划令牌重建一个短视频片段。为确保解码过程中的时间连续性,末端令牌被复制并插入以形成连续的潜在序列。第二个副本的重编码潜在状态则作为下一个片段的初始条件。更多实现细节请参见我们之前的工作MMPL Xiang et al. (2025)。
3.2.2 基于MMPL的内容填充
根据3.2.1节,微观规划 M s \mathcal{M}_{s} Ms 将每个视频片段划分为两个子片段,例如 x s t a , x s t b x_{s}\^{t_{a}},x_{s}\^{t_{b}} xsta,xstb 和 x s t b , x s t c x_{s}\^{t_{b}},x_{s}\^{t_{c}} xstb,xstc,它们由连续的规划帧限定。为了在这些规划锚点的指导下填充剩余帧以合成完整片段,我们引入了基于MMPL的内容填充。
微观规划提供了三种关键帧:早期帧 ( x s t a ) (x_{s}^{t_{a}}) (xsta)、中点帧 ( x s t b ) (x_{s}^{t_{b}}) (xstb) 和末端帧 ( x s t c ) (x_{s}^{t_{c}}) (xstc)。受早期帧条件生成方法的启发,我们分两个顺序阶段进行内容填充:
- 使用初始帧和早期规划帧作为起点,中点规划帧作为终点,填充第一个子片段。
- 将达到中点之前的所有帧作为新起点,末端帧作为终点,扩展序列以生成剩余内容。
该过程可形式化表达为:
p ( C s ∣ P M s ) = p ( x s t a + 1 : t b − 1 ∣ x s 1 : t a , x s t b ) ⋅ p ( x s t b + 1 : t c − 1 ∣ x s 1 : t b , x s t c ) , ( 3 ) p(\mathcal{C}{s}\mid \mathcal{P}{\mathcal{M}{s}}) = p\big(x{s}^{t_{a} + 1:t_{b} - 1}\mid x_{s}^{1:t_{a}},x_{s}^{t_{b}}\big)\cdot p\big(x_{s}^{t_{b} + 1:t_{c} - 1}\mid x_{s}^{1:t_{b}},x_{s}^{t_{c}}\big), \quad (3) p(Cs∣PMs)=p(xsta+1:tb−1∣xs1:ta,xstb)⋅p(xstb+1:tc−1∣xs1:tb,xstc),(3)
其中, C s \mathcal{C}{s} Cs 表示在片段 s s s 中要生成的内容帧, x s t a x{s}^{t_{a}} xsta、 x s t b x_{s}^{t_{b}} xstb 和 x s t c x_{s}^{t_{c}} xstc 分别表示其早期、中点和末端规划帧。符号 x s 1 : t a x_{s}^{1:t_{a}} xs1:ta 和 x s 1 : t b x_{s}^{1:t_{b}} xs1:tb 表示每个子片段的生成除了其边界规划帧外,还以该片段内所有先前的帧为条件。中间帧 x s t a + 1 : t b − 1 x_{s}^{t_{a} + 1:t_{b} - 1} xsta+1:tb−1 和 x s t b + 1 : t c − 1 x_{s}^{t_{b} + 1:t_{c} - 1} xstb+1:tc−1 对应于要填充的内容。
重要的是,方程 (3) 中的因式分解表明,每个子片段内部的内容填充仅依赖于其相应的规划帧。这使得一旦内部规划帧准备就绪,就可以并行优化多个子片段。通过将片段级优化分布到多个GPU上,所提出的基于MMPL的内容填充实现了并发执行,显著加速了长视频的合成。
3.3 实时4D重建
3.3.1 关键帧重建
我们提出了一个实时4D重建模块,以进一步提供场景中移动对象的动态记忆。考虑到MMPL架构中的规划策略,我们的重建过程也与宏观规划同步进行。重建任务随着宏观结构不断向后推进,使重建速度能够紧密跟随生成过程。同时,微观规划使用重建在相应操作下的渲染结果作为指导。
通过这种方式,重建的开销被最小化,重建的输入尽可能保持稀疏,以防止由于长时间世界生成而导致重建任务在长序列上失败。我们将这种方法称为关键帧重建。
具体来说,只有稀疏的预规划帧集合 P M s = { x s t a , x s t b , x s t c } \mathcal{P}{\mathcal{M}{s}} = \{x_{s}^{t_{a}},x_{s}^{t_{b}},x_{s}^{t_{c}}\} PMs={xsta,xstb,xstc} 需要进行4D重建。这些规划帧本质上作为视频中的锚点------它们首先以最小误差和最高质量生成,并决定视频的运动轨迹。使用它们进行4D重建也为世界模型中的长视频生成任务引入了足够丰富的记录。每个视频片段的开头、中间和结尾都将用于在4D时空场中记录信息。在内容填充期间,中间运动将根据这些记录的线索进行填充。
3.3.2 移动对象分割
受4D-VGGT启发,我们利用其动态显著图作为动态掩码。为聚合时间信息,我们采用帧间滑动窗口策略,定义为 W ( t ) = { t − n , ... , t − 1 , t + 1 , ... , t + n } \mathcal{W}(t) = \{t - n,\ldots ,t - 1,t + 1,\ldots ,t + n\} W(t)={t−n,...,t−1,t+1,...,t+n}。在此窗口内,跨三个层集 L L L(包括浅层、中层和深层),浅层 w s h a l l o w w_{\mathrm{shallow}} wshallow 捕获语义显著性,中层 w m i d d l e w_{\mathrm{middle}} wmiddle 反映运动不稳定性,深层 w d e e p w_{\mathrm{deep}} wdeep 提供空间先验以抑制异常值。最后,通过阈值化 M t = D y n \> α M_{t} = \\mathrm{Dyn} \> \\alpha Mt=Dyn\>α 获得逐帧动态掩码,再进行特征聚类细化。
我们的框架还实施了网络级的早期掩码策略,用于4D重建和堆叠。静态场景元素被合并并逐步扩展,而稀疏的动态组件则随时间单独渲染。然而,由于我们的输入仅限于预规划帧 P M s = { x s t a , x s t b , x s t c } \mathcal{P}{\mathcal{M}{s}} = \{x_{s}^{t_{a}},x_{s}^{t_{b}},x_{s}^{t_{c}}\} PMs={xsta,xstb,xstc},渲染的动态内容仍高度稀疏。这要求根据预规划序列中较早的帧来预测后续动态区域------这是我们通过视频生成中的宏观规划来解决的挑战。从宏观角度看,平滑连续的运动被分解为嵌入场景中的类似关键帧的动态片段。
具体来说,遵循4D-VGGT,为减轻动态像素引入的几何不一致性,我们还仅在浅层和中层(层 1 ∼ 5 1\sim 5 1∼5)中通过抑制其键(K)向量来掩盖动态图像令牌。
3.4 引导
3.4.1 键盘控制
鉴于键盘控制在世界模型中的广泛应用,我们也使用WASD键和方向键来模拟移动和视角变化。这些输入被相应地映射到摄像机姿态。
这些信号被条件化以指导模型的生成。我们将这些控制映射为摄像机运动以及输入帧深度尺度。
p e r s p e c t i v e = { → : 摄像机向右转 ( → ) . ← : 摄像机向左转 ( ← ) . ↑ : 摄像机向上转 ( ↑ ) . ↓ : 摄像机向下转 ( ↓ ) . ↑ → : 摄像机向上并向右转 ( ↑ → ) . ↓ → : 摄像机向下并向右转 ( ↓ → ) . ↓ ← : 摄像机向下并向左转 ( ↓ ← ) . ⋅ : 摄像机保持静止 ( ⋅ ) . ( A ) \mathrm{perspective} = \left\{ \begin{array}{l l}{\rightarrow :\mathrm{摄像机向右转}(\rightarrow).}\\ {\leftarrow :\mathrm{摄像机向左转}(\leftarrow).}\\ {\uparrow :\mathrm{摄像机向上转}(\uparrow).}\\ {\downarrow :\mathrm{摄像机向下转}(\downarrow).}\\ {\uparrow \rightarrow :\mathrm{摄像机向上并向右转}(\uparrow \rightarrow).}\\ {\downarrow \rightarrow :\mathrm{摄像机向下并向右转}(\downarrow \rightarrow).}\\ {\downarrow \leftarrow :\mathrm{摄像机向下并向左转}(\downarrow \leftarrow).}\\ {\cdot :\mathrm{摄像机保持静止}(\cdot).} \end{array} \right. \quad (A) perspective=⎩ ⎨ ⎧→:摄像机向右转(→).←:摄像机向左转(←).↑:摄像机向上转(↑).↓:摄像机向下转(↓).↑→:摄像机向上并向右转(↑→).↓→:摄像机向下并向右转(↓→).↓←:摄像机向下并向左转(↓←).⋅:摄像机保持静止(⋅).(A)
此外,为了尽可能增强视频生成的连续性和连贯性,我们力求避免保持静态摄像机位置。因此,即使用户没有提供键盘输入,摄像机姿态也会以非常缓慢的速度向前漂移------我们称之为待机动画功能。
3.4.2 视角条件引导
随后,我们需要为世界模型网络编码处理过的键盘输入。如ReCamMaster中所述,通过帧维度进行条件化是更有效地将目标摄像机姿态集成到DiT网络的方法。遵循这一见解,我们采用类似的结构并将以下机制整合到TeleWorld的DiT网络中:
为了与键盘引导视频实现更好的同步和内容一致性,我们建议沿帧维度将引导视频令牌与目标视频令牌连接起来:其中 x i ∈ R b × 2 f × s × d x_{i}\in \mathbb{R}^{b\times 2f\times s\times d} xi∈Rb×2f×s×d 是扩散Transformer的输入。换句话说,与香草视频生成过程相比,输入令牌数量增加了一倍。此外,由于3D自注意力本身处理所有令牌,因此不需要额外的注意力层进行跨视频聚合。
3.5 分布匹配蒸馏
我们的方法可以与现有的分布匹配蒸馏(DMD)框架无缝集成,无需任何架构修改。具体来说,MMPL视频生成管线在训练和推理过程中都会调整注意力可见范围和预测顺序。在标准自强迫(self-forcing)管线的基础上,DMD可以直接应用于MMPL,并部署在TeleWorld框架内。
结合并行解码,所得系统显著提升了推理速度,在NVIDIA H100 GPU上,TeleWorld-1.3B模型实现超过32 FPS,Teleworld-18B模型实现8 FPS的长时间视频生成。
尽管对于实时视频生成至关重要,但DMD对训练基础设施带来了显著挑战,尤其是在应用于我们的18B模型时。训练设置需要同时协调三个扩散模型------自回归生成器、判别器(critic)和教师模型(teacher)------这使得在单个80GB HBM GPU中托管所有组件变得不可行。为了解决这一限制,我们采用Ray (Moritz et al., 2017) 将模型权重分布到多个GPU上。此外,利用TeleTron1提供的Ulysses序列并行能力,我们将生成器的KV缓存分片到各个GPU上,使其能够适应内存限制。
为了缓解模型并行导致的GPU利用率不足问题,我们设计了一种新颖的管线化训练调度,它重叠了生成器、判别器和教师模型的计算,从而最大限度地减少GPU空闲时间(即管线气泡)。生成器和判别器步骤的执行调度如图3所示。对于生成器步骤,要实现图中所示的重叠程度,需要通过明确的资源分配,使生成器前向和后向阶段的组合执行时间与判别器/教师阶段的执行时间仔细匹配。实践中,我们发现生成器:判别器:教师的GPU比例为4:1:1可以实现近乎完美的重叠。此外,为了简化DMD优化并确保可预测的阶段持续时间,我们在训练期间固定了生成器管线中的去噪步数,而不是随机采样。我们注意到,必须维护两份KV缓存以支持正确的反向传播;然而,由于KV缓存已经使用上下文并行性在设备之间进行了分片,这一开销是可管理的。因此,我们的管线化系统与非管线基线相比,实现了大约50%的端到端训练加速。
综合来看,高效的KV缓存分片、模型并行化和管线化执行使得我们的训练系统能够自然地扩展到未来参数量更大的自回归扩散模型。
3.6 流式和调度生成与在线视频超分辨率
3.6.1 调度生成
尽管不同片段之间的内容填充可以并行化(第3.2.2节),但一个关键限制仍然存在:并行执行无法在所有片段的规划帧完全生成之前开始,这导致
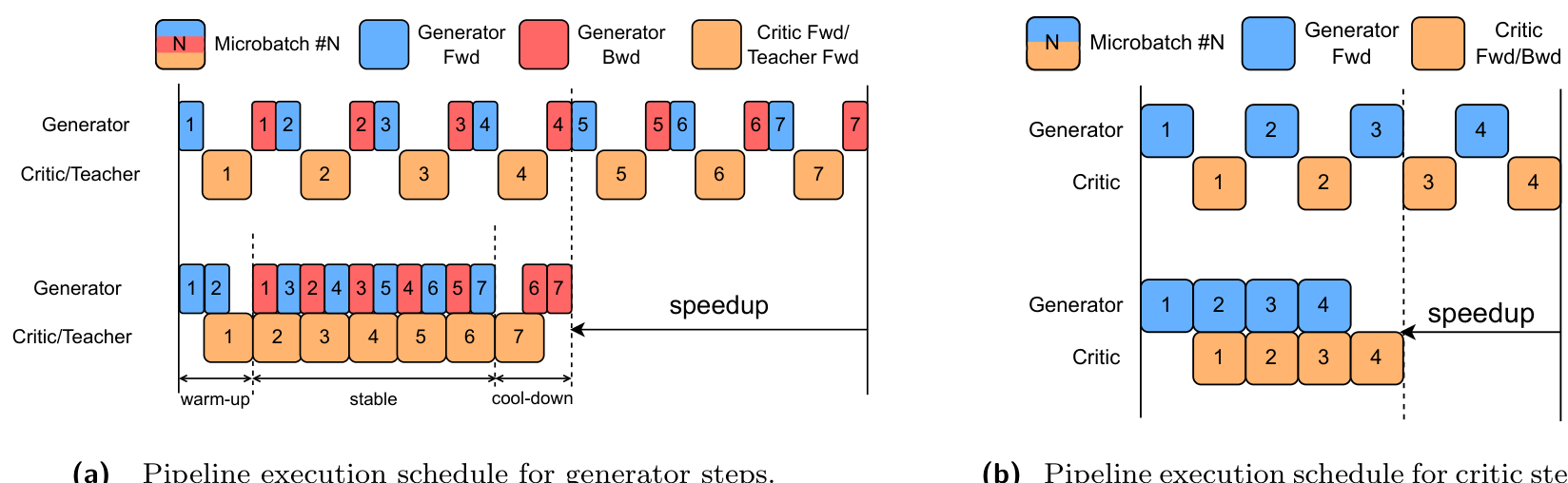
Figure 3 Pipeline execution schedules for Distribution-Matching Distillation. (a) Generator-step pipeline with 7 micro-batches. Cell length denotes execution time. The critic and teacher works in parallel, so their cells are merged together for simplicity, and their cell length denotes the maximum of their execution time. The upper half of the figure is the non-pipelining baseline, which introduces a lot of GPU bubbles (i.e. GPU idle time). The lower half is our proposed pipeline schedule. In the stable phase, the generator backward stage of micro-batch i i i and the generator forward stage of micro-batch i + 2 i + 2 i+2 are executed concurrently with the critic/teacher forward stage of micro-batch i + 1 i + 1 i+1 . The execution time of all stages are carefully balanced by allocating appropriate numbers of GPUs to each component, enabling near-perfect overlap. This method minimizes GPU bubbles and achieves efficient parallelization of generator, teacher, and critic workloads in the proposed system. (b) Critic-step pipeline with 4 micro-batches. Since the generator parameters remain frozen during the critic update, the pipeline follows a simpler producer-consumer execution pattern.
不可避免的前缀延迟,降低了整体吞吐量。
为了解决这个问题,我们引入了一种自适应工作负载调度策略,动态安排微规划(Micro Planning)、宏规划(Macro Planning)和内容填充(Content Populating)的执行顺序,以最大化并行度。由于宏规划是片段级微规划的自回归链,规划帧是按片段顺序生成的。这使得较早片段的内容填充在其自身的规划帧准备好后即可开始,无需等待后续片段。
以 t a = 2 t_{a} = 2 ta=2、 t b = 6 t_{b} = 6 tb=6 和 t c = 10 t_{c} = 10 tc=10 为例,当前片段的规划帧 x s t c x_{s}^{t_{c}} xstc 立即作为下一个片段的初始帧 x s + 1 1 x_{s + 1}^{1} xs+11。因此,当当前片段仍在填充其中间帧(例如 x s t a + 1 : t b − 1 x_{s}^{t_{a} + 1:t_{b} - 1} xsta+1:tb−1)时,下一个片段就可以开始其微规划。这种分阶段的独立性自然地实现了片段并行生成,形式上如公式 (4) 所示:
S e g m e n t s : x s t a + 1 : t b − 1 ∼ p θ ( x ∣ x s 1 , x s t a , x s t b ) , S e g m e n t s + 1 : { x s + 1 t a , x s + 1 t b , x s + 1 t c } ∼ p θ ( x ∣ x s + 1 1 ) , x s + 1 1 ∈ { x s t b , x s t c } . ( 4 ) \begin{array}{r l} & {\mathrm{Segment~s:~}\quad x_{s}^{t_{a} + 1:t_{b} - 1}\sim p_{\theta}(x\mid x_{s}^{1},x_{s}^{t_{a}},x_{s}^{t_{b}}),}\\ & {\mathrm{Segment~s + 1:~}\quad \{x_{s + 1}^{t_{a}},x_{s + 1}^{t_{b}},x_{s + 1}^{t_{c}}\} \sim p_{\theta}(x\mid x_{s + 1}^{1}),\quad x_{s + 1}^{1}\in \{x_{s}^{t_{b}},x_{s}^{t_{c}}\} .} \end{array} \quad (4) Segment s: xsta+1:tb−1∼pθ(x∣xs1,xsta,xstb),Segment s+1: {xs+1ta,xs+1tb,xs+1tc}∼pθ(x∣xs+11),xs+11∈{xstb,xstc}.(4)
在此,下一个片段的初始帧 x s + 1 1 x_{s + 1}^{1} xs+11 可以选择 x s t b x_{s}^{t_{b}} xstb 或 x s t c x_{s}^{t_{c}} xstc。为了保持实时实用生成,我们选择最大吞吐量预测如下:
为了尽可能最小化延迟,我们使用最小内存峰值预测(Minimum Memory Peak Prediction)策略。当 x s t b x_{s}^{t_{b}} xstb 用作 x s + 1 1 x_{s + 1}^{1} xs+11 时,中间帧 x t b + 1 : x t c − 1 x^{t_{b} + 1}: x^{t_{c} - 1} xtb+1:xtc−1 被跳过,绕过了具有最深时间上下文和最高生成延迟的区域。这种模式最小化了峰值内存使用并降低了每个片段的延迟,但引入了片段之间的帧重用,略微降低了总体吞吐量。如图4所示, f 4 0 f_{4}^{0} f40 和 f 6 1 f_{6}^{1} f61 实际上是同步生成的。这意味着任何即时用户输入操作仅在三个潜在块之后渲染,导致大约一秒的反馈延迟。因此,当前观察到的世界输出对应于用户输入前一秒捕获的预缓冲更改。
3.6.2 流式 VAE
为了实现直播流的实时视频生成,我们基于StreamDiffusionV2 (Feng et al., 2025) 的原理设计了一种支持流处理的VAE。在直播环境中,核心挑战是最小化"首帧时间"并确保连续、低延迟的输出,这与离线处理长序列的批处理视频生成有着根本区别。我们的Stream-VAE是一种低延迟的视频-VAE
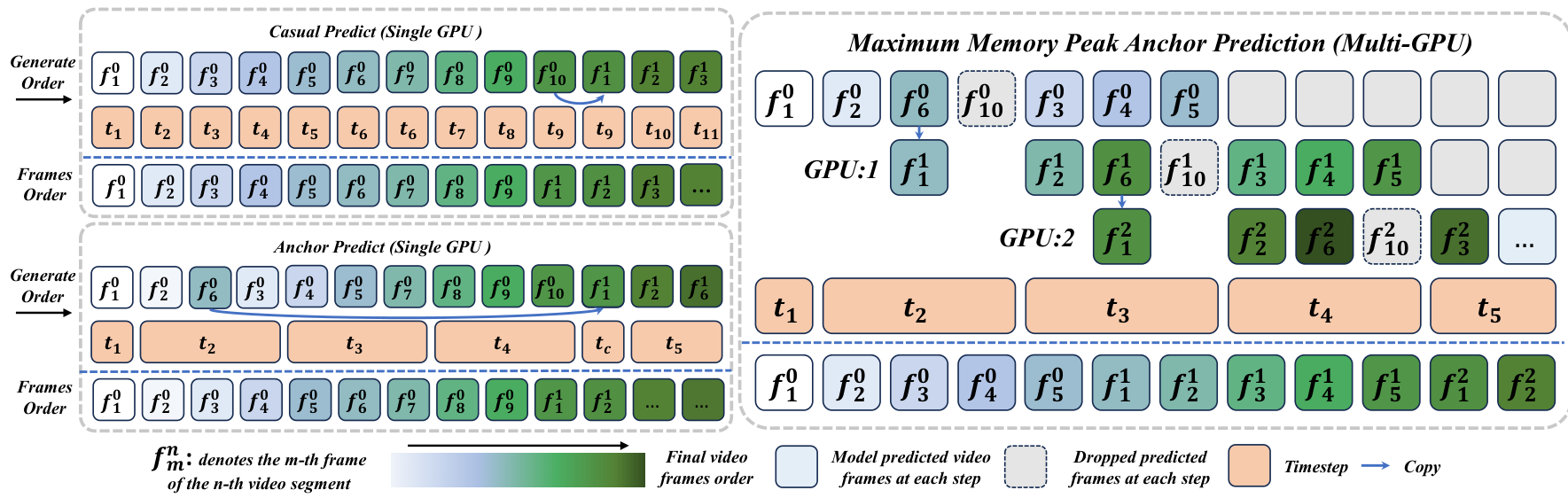
Figure 4 Multi-GPU parallel inference via adaptive workload scheduling. Given the initial frame f 1 0 f_{1}^{0} f10 , segment 0 first generates its planning frames f 2 0 f_{2}^{0} f20 , f 6 0 f_{6}^{0} f60 , and f 10 0 f_{10}^{0} f100 . These planning frames then guide the content population of the intermediate frames f 3 0 f_{3}^{0} f30 , f 4 0 f_{4}^{0} f40 , and f 5 0 f_{5}^{0} f50 . While segment 0 is still populating these frames, segment 1 can immediately start its Micro Planning by taking f 10 0 f_{10}^{0} f100 as the initial frame f 1 1 f_{1}^{1} f11 and generating its own planning frames f 2 1 f_{2}^{1} f21 , f 6 1 f_{6}^{1} f61 , and f 10 1 f_{10}^{1} f101 . This staged execution enables overlapping planning and populating across segments, maximizing multi-GPU parallelism. Here, each t i t_{i} ti denotes an inference step in the diffusion sampling process.
变体,专门针对流式推理进行了优化。它不是一次性编码整个视频序列,而是在短的、连续的视频块(在我们的实现中通常为4帧)上操作。这种块式处理对于保持稳定的输出流至关重要。
Stream-VAE的架构在其3D卷积层中融入了中间特征的策略性缓存。每当新的帧块输入模型时,网络会重用从先前块计算出的相关时间特征,从而在不重新编码长时间历史的情况下,保持了块边界之间的时间连贯性。这种设计显著减少了冗余计算和内存开销,实现了高效的增量编码和解码。通过将此Stream-VAE集成到我们的管线中,我们确保视频的潜在表示能够以最小延迟生成并交付给用户,构成了我们实时流系统的基础阶段。
3.6.3 视频超分辨率
为了后续增强视频质量,我们整合了一个受FlashVSR启发的流式超分辨率模块。该组件负责将Stream-VAE解码后的潜在表示实时上采样为高分辨率视频帧。我们从FlashVSR中采纳的一项关键创新是其局部性约束的稀疏注意力机制。这种机制将自注意力操作限制在局部时空窗口内,从而大幅降低了通常困扰视频超分辨率模型的计算复杂度。它有效地弥合了训练和推理之间经常遇到的分辨率差距,同时不牺牲精细细节的质量。
此外,我们利用FlashVSR的轻量级条件解码器,该解码器专为快速特征重建而设计。解码器根据从Stream-VAE输出中提取的特征进行超分辨率处理,确保高保真结果并保持低计算占用。至关重要的是,该超分辨率模块设计为与我们的Stream-VAE以完全流式方式协同工作。它处理与VAE输出流对齐的短视频块(例如5帧),随着每个块的可用而增量应用超分辨率。这种集成化的块式处理管线使我们的模型能够以大约17 FPS的速度对 960 × 1760 960 \times 1760 960×1760 分辨率视频进行超分辨率解码,使高质量实时视频生成成为可能。
总而言之,通过集成调度生成、流式VAE和视频超分辨率技术,我们的系统使TeleWorld-18B模型能够在四个NVIDIA H100 GPU设置下实现稳定的8 FPS性能,并生成高质量的 960 × 1760 960 \times 1760 960×1760 视频。
Original Abstract: World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
PDF Link: 2601.00051v1
部分平台可能图片显示异常,请以我的博客内容为准
