"多模态"中的"模态"(modality),即指各类数据形式或信息来源。在多模态大模型中,典型模态涵盖以下类别:
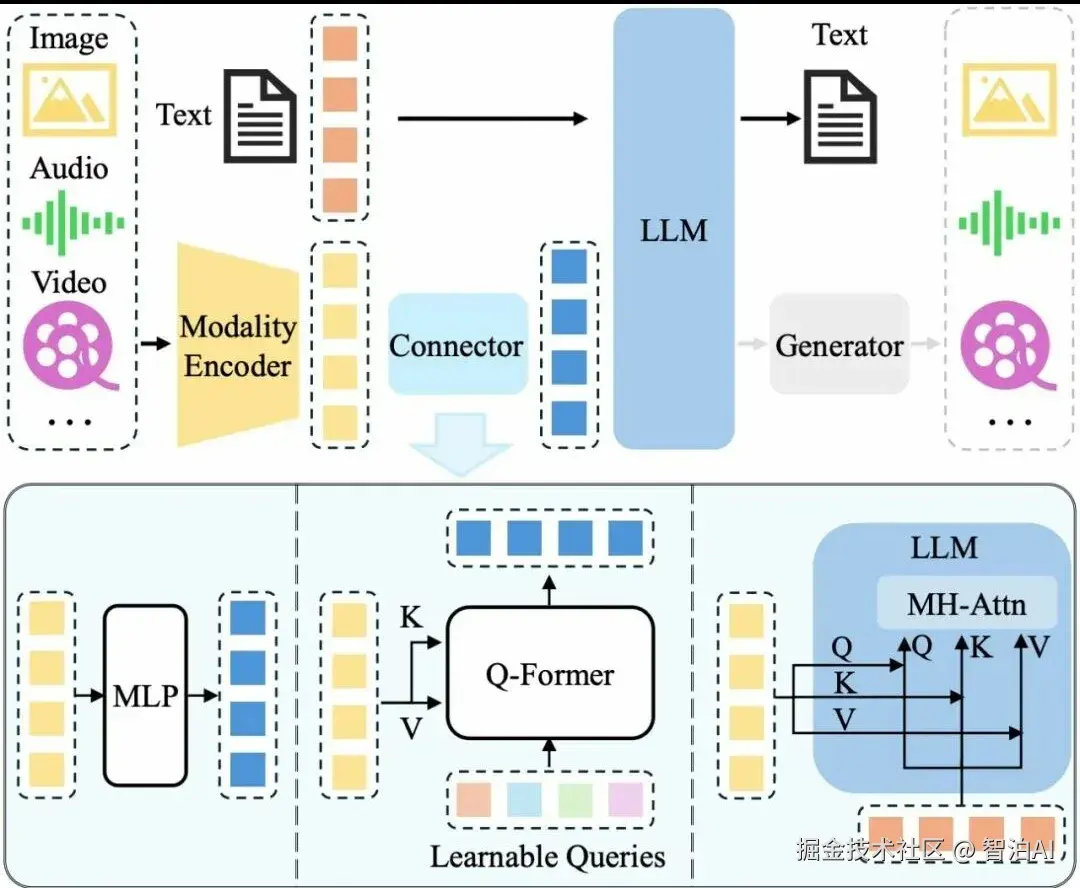
文本模态:
涵盖自然语言文本、经语音识别转换的文本内容等。
图像模态:
指视觉图像数据,例如照片、插画、艺术作品等。
视频模态:
包含动态影像序列,如短视频、影视片段、监控录像等。
音频模态:
指声学信号数据,如人声、音乐、环境音效等。
其他模态:
还包括如环境传感器读数、生理信号、指纹、虹膜等非传统信息形式。
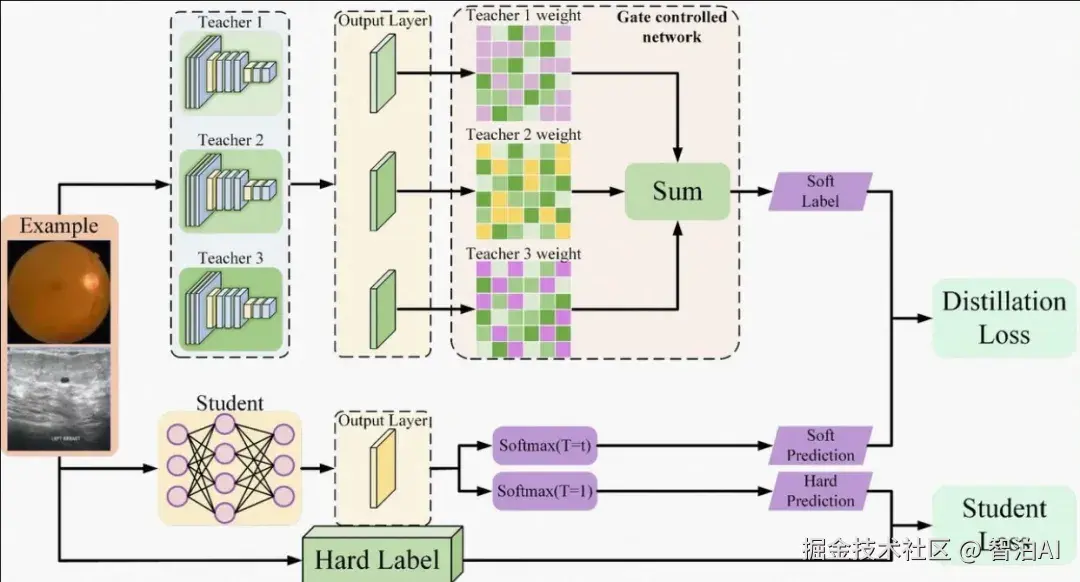
多模态模型的核心目标,在于融合上述异构模态的信息,以增强模型对输入数据的语义理解、任务执行与预测能力。
通过协同利用多源信息,模型得以构建更立体、更精准的认知框架。整合多元模态数据,使系统能够实现更丰富、更灵活的信息解析,从而为复杂智能任务提供坚实支撑。
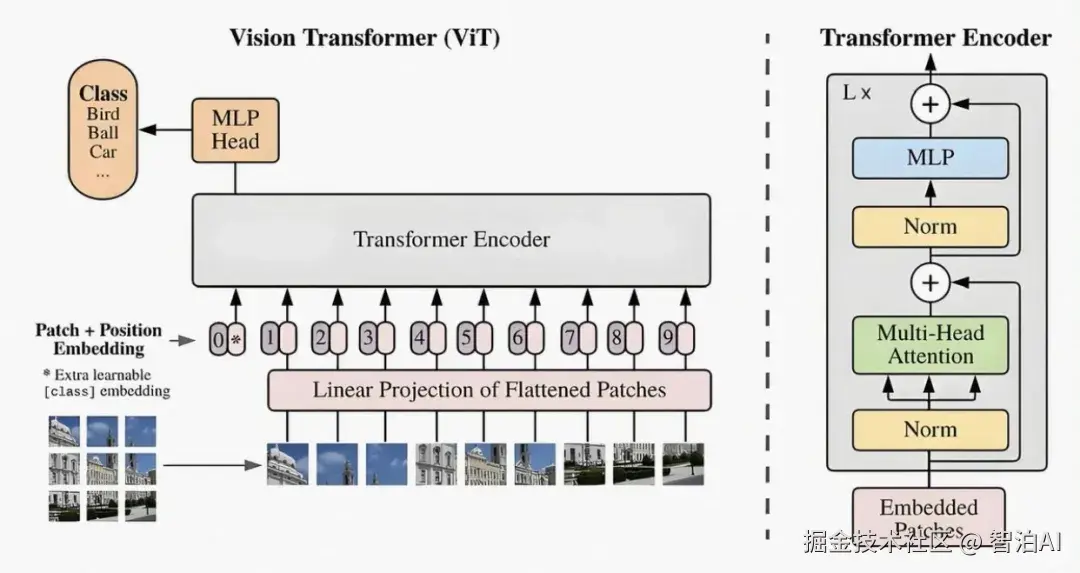
多模态大模型具备以下核心特征:
处理多种数据类型:可同步接收并处理文本、图像、视频、音频等多种输入,实现跨模态语义对齐与联合表征。
综合不同信息源:有效整合来自不同感知通道的数据,提升整体信息处理的完整性与准确性。
提升模型性能:借助多模态互补性,增强模型的泛化性与鲁棒性,拓展其在多样化任务中的适用边界。
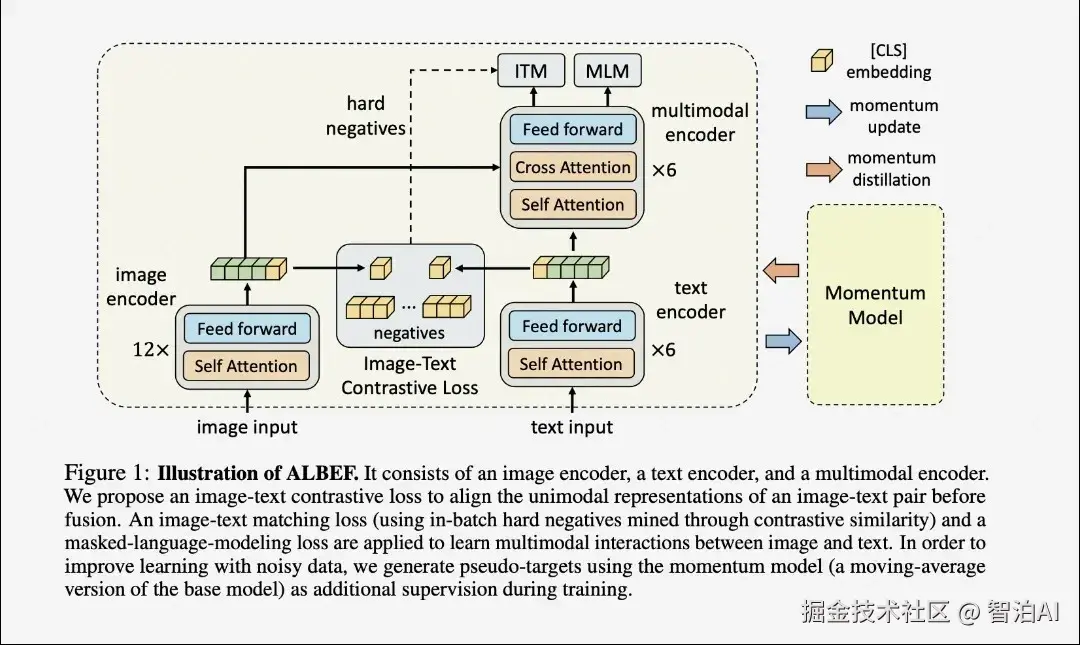
丰富的应用场景:广泛应用于图像字幕生成、视频内容分析、多模态人机交互、跨模态语义推理等前沿领域。